


目录
引言:AI时代重构网络基础设施
从云计算到AI工厂的范式转变
800G的技术驱动因素与时间线
技术标准与物理层架构
双轨制:IEEE 802.3df 与 802.3dj
SerDes演进:从112G到224G
调制格式与前向纠错(FEC)
核心硅芯片格局:51.2T芯片之争
Broadcom:Tomahawk 5 与 Jericho3-AI 的双重驱动
NVIDIA:Spectrum-4 的垂直整合逻辑
Marvell:Teralynx 10 的可编程性与超低延迟
Cisco:Silicon One G100 的统一架构
芯片参数对比
系统厂商产品与解决方案
Arista Networks:AI网络领导者
Cisco Systems:Nexus的演进
华为:智算网络全面布局
H3C:CPO与LPO的双重押注
锐捷网络与中兴通讯
Juniper Networks QFX5240系列
光互联革命:可插拔、LPO、LRO 与 CPO 的角逐
传统可插拔光模块
线性驱动可插拔光模块(LPO)
线性接收光模块(LRO)
共封装光学(CPO)
经济性分析:800G的TCO优势
热管理与机械工程挑战
风冷的局限性
液冷的引入
市场经济学与未来展望
市场规模与预测
厂商市场份额分析(全球格局)
通往1.6T之路
结论
▶ 引言:AI时代重构网络基础设施
从云计算到AI工厂的范式转变
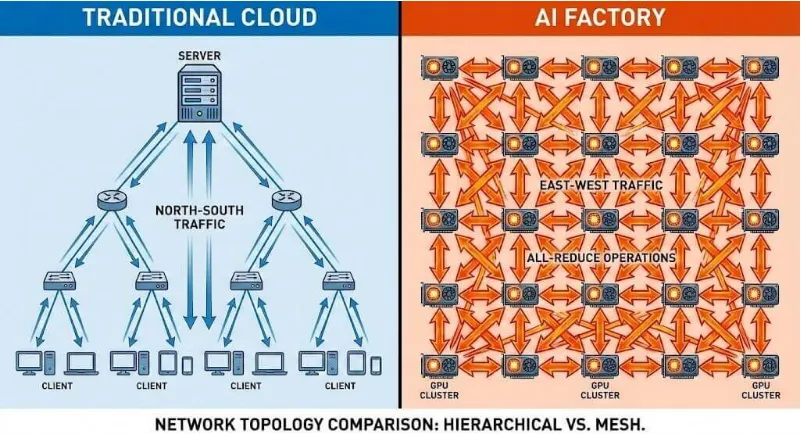
全球数据中心网络正在经历过去十年中最深刻的变革。此前,网络架构主要围绕云计算和互联网应用流量模式设计,以“南北向”的客户端-服务器模型为主导。然而,随着以GPT-4为代表的生成式AI和大语言模型(LLM)的爆发,数据中心内部的流量特征发生了根本性的逆转。在AI训练集群中,成千上万个GPU执行All-Reduce操作,生成了海量的“东西向”流量。这些流量呈现出高突发性、极高带宽需求和极度延迟敏感的特性。网络不再仅仅是连接计算单元的管道,它已成为决定整体计算效率的关键组成部分。在百万级GPU的集群中,即使是微小的网络性能抖动,也可能导致昂贵的GPU计算资源闲置。
为应对这一挑战,数据中心网络必须从传统的400G架构加速向800G乃至未来的1.6T迈进。800G以太网不仅仅是带宽的翻倍,更是对网络拓扑、拥塞控制机制和物理层信号完整性的全面重新设计。分析显示,AI和机器学习工作负载正推动800G端口出货量在2025年创下历史新高,这一趋势将在未来五年重塑整个以太网交换机市场。
800G的技术驱动因素与时间线
从技术演进的角度看,800G的商业部署比预期来得更早——这主要是由AI算力的迫切需求驱动的。在摩尔定律放缓的背景下,通过并行化来扩展算力已成为唯一可行的路径,而并行化的效率从根本上受到互连带宽的限制。
带宽需求:AI模型参数数量呈指数级增长,导致通信带宽需求每两年翻数倍,其增长速度远超摩尔定律。800G端口能够实现更高密度的互连,使得单层交换架构能够支持更大的GPU集群,从而减少跳数和延迟。
成本与能效:尽管单端口绝对成本有所增加,但相较于400G,800G在每比特成本和每比特功耗方面具有显著优势。研究表明,800G解决方案可以通过减少所需光纤数量和提升频谱效率,有效降低总体拥有成本(TCO)。
本报告将深入分析800G交换机的技术标准、核心硅光芯片格局、系统厂商的解决方案、光互联技术(LPO/CPO)的革命性变革,以及对1.6T演进的展望。
双轨制:IEEE 802.3df 与 802.3dj
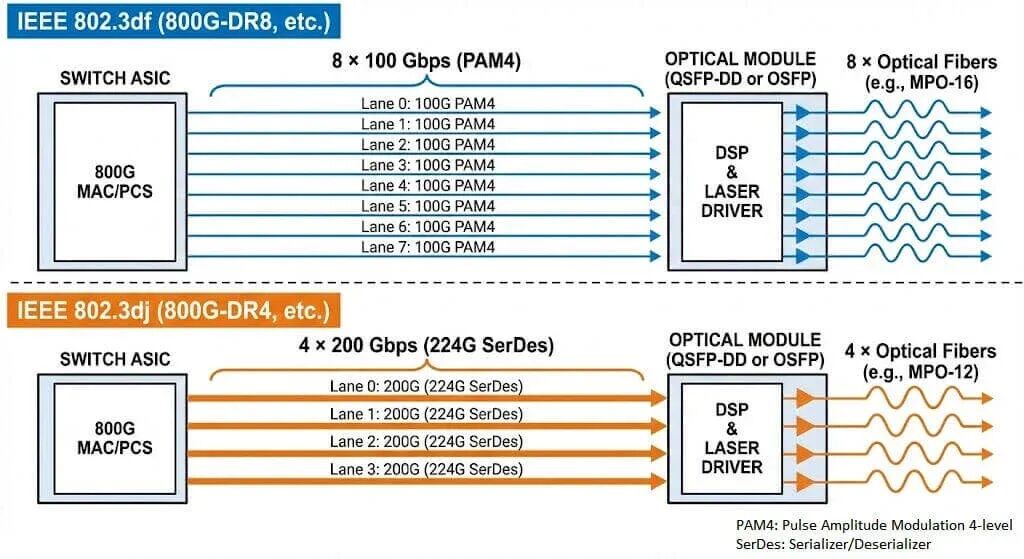
IEEE 802.3工作组在制定下一代以太网标准时,采取了务实的阶段性策略。最初的P802.3df项目旨在同时涵盖800G和1.6G速率。然而,由于单通道技术成熟度的差异,该项目于2022年11月被拆分为两个独立的工作组:IEEE 802.3df 和 IEEE 802.3dj。
IEEE 802.3df:是当前800G部署的基石。它规定使用8个并行通道,每个通道运行在100 Gbps(实际使用PAM4调制时为106.25 Gbps或112 Gbps),以实现800G的聚合带宽。该标准通过利用成熟的100G/通道光电器件,使800G产品能够快速商业化。
IEEE 802.3dj:面向未来。随着交换芯片容量向102.4 Tbps迈进,单通道200G(224G SerDes)将变得至关重要。该标准不仅涵盖1.6T,还涵盖了基于4通道200G的“第二代800G”。这一演进将进一步降低光纤布线复杂度和功耗,同时也会带来巨大的信号完整性挑战。
SerDes演进:从112G到224G
SerDes是交换芯片与外部世界的关键接口。当前主流的51.2T交换芯片都使用112G PAM4 SerDes。
112G的挑战:在112 Gbps速率下通过PCB走线传输信号会导致严重的中介损耗和串扰。这迫使系统设计采用超低损耗材料(如 Megtron 7/8)或采用飞线电缆技术,直接从芯片连接到前面板接口以绕过PCB损耗。
224G的展望:下一代102.4T芯片将采用224G SerDes。在此速率下,传统的铜互连(DAC)距离将缩短至无法使用,这将强力推动有源电缆(AEC)、线性驱动可插拔光模块(LPO)以及最终的共封装光学(CPO)的采用。
调制格式与前向纠错(FEC)
为了在有限的带宽内传输更多数据,800G普遍采用PAM4(四电平脉冲幅度调制)技术。与传统的NRZ编码相比,PAM4在每个符号周期内传输2比特,频谱效率翻倍,但信噪比(SNR)会降低约9.5 dB。
为了补偿SNR的损失,强大的FEC机制是必需的。IEEE标准定义了RS(544,514) Reed-Solomon码作为基准。然而,FEC不可避免地会引入延迟。对于要求超低延迟的AI网络,一些厂商(例如NVIDIA和Marvell)在其芯片设计中对FEC进行了深度优化,并正在探索针对特定短距离链路的低延迟FEC模式,以最大限度地减少端到端传输延迟。
▶ 核心硅芯片格局:51.2T芯片之争
800G交换机的核心引擎是51.2 Tbps的交换ASIC。这一代芯片不仅仅是带宽的提升,更是架构上的分水岭。市场已经形成了Broadcom、NVIDIA和Marvell三方角逐的格局,各家公司芯片架构的差异直接决定了下游系统厂商产品的特性。
Broadcom:Tomahawk 5 与 Jericho3-AI 的双重驱动
Broadcom继续通过细分产品线来覆盖不同的市场需求,其策略是在超大规模云和AI智算网络中实现“全面覆盖”。
Tomahawk 5 (StrataXGS系列):
定位:面向超大规模数据中心Spine/Leaf层的高吞吐量芯片。
规格:单芯片51.2 Tbps,支持64个800G端口或256个200G端口。
架构亮点:基于5nm工艺,集成了512个100G PAM4 SerDes。除了带宽之外,Tomahawk 5还引入了“Scale-Up Ethernet”功能,包括认知路由、动态负载均衡(DLB)和全局流控。这些功能解决了AI流量中的哈希冲突问题,显著降低了尾部延迟。
延迟:实现了约250纳秒的超低转发延迟,这对于构建基于以太网的高性能AI集群至关重要。
Jericho3-AI (DNX系列):
定位:面向需要深度缓冲和更复杂流量调度的AI后端网络的核心层交换机。
差异化:与Tomahawk的片上共享缓冲区不同,Jericho架构依赖模块化的VoQ和外部HBM内存,提供毫秒级的缓冲能力,以处理极端的Incast突发流量,并确保在数万个GPU的集群中实现零丢包。
NVIDIA:Spectrum-4 的垂直整合逻辑
NVIDIA不仅仅是销售芯片,它销售的是整个“AI工厂”的互连架构。Spectrum-4是其以太网战略的核心,旨在通过Spectrum-X平台挑战InfiniBand在AI领域的主导地位。
Spectrum-4 ASIC:
规格:采用定制的4N工艺(优化的5nm),集成1000亿个晶体管,提供51.2 Tbps带宽。
核心优势:单芯片共享缓存。与竞争对手可能采用的多片缓存架构不同,Spectrum-4使用完全共享的单芯片数据包缓冲区。这使得所有端口能够动态共享整个缓存池,极大地提高了吸收微突发流量的能力,并确保了跨端口的公平性和确定性低延迟。
RoCE优化:作为Spectrum-X平台的一部分,Spectrum-4与NVIDIA BlueField-3 DPU紧密配合,实现了端到端的拥塞控制和遥测。这种软硬件协同工作方式,在AI工作负载下将有效带宽利用率提高了1.6倍。
Marvell:Teralynx 10 的可编程性与超低延迟
通过收购Innovium,Marvell的Teralynx产品线已成为Broadcom最强劲的竞争对手,尤其是在云服务提供商市场。
Teralynx 10:
规格:51.2 Tbps带宽,支持512个112G SerDes通道,可配置为64个800G端口。
低延迟特性:Marvell宣称其业界领先的转发延迟低至500纳秒,且在不同数据包大小下性能保持确定性。
高基数:支持多达512个逻辑端口,能够构建更扁平的网络拓扑,从而减少跳数、端到端延迟和功耗。
可编程性:具有可编程的转发流水线,允许客户在不更改硬件的情况下支持新的路由协议或遥测标准,提供了更好的投资保护。
Cisco:Silicon One G100 的统一架构
Cisco的Silicon One G100芯片虽然主要用于25.6T设备(如Nexus 9232E),但它体现了覆盖路由和交换两个市场的“统一架构”理念。G100采用7nm工艺,支持32个800G端口,强调高能效和统一的P4可编程性。
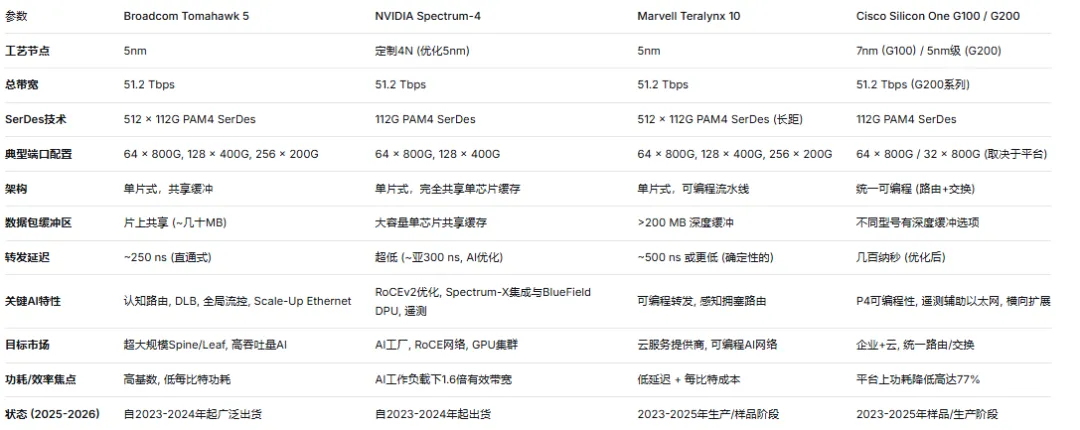
芯片参数对比:
▶ 系统厂商产品与解决方案
随着51.2T芯片的成熟,各大网络设备制造商纷纷推出了各自的800G交换机产品。这些产品超越了简单的芯片封装,展现了它们在散热设计、电源管理、网络操作系统和光模块兼容性方面的工程实力。
Arista Networks:AI网络领导者
Arista凭借其EOS操作系统的优势,在AI网络领域占据强势地位。
7060X6系列:基于Broadcom Tomahawk 5的旗舰800G产品线。
7060X6-64PE:2U固定配置交换机,提供64个800G OSFP端口,针对AI后端网络进行了优化,配备165 MB系统缓存以有效处理拥塞。
7060X6-32PE:1U设备,提供32个800G OSFP端口,总容量25.6T,适用于较小集群或叶脊架构中的叶节点。
LPO支持:Arista是线性驱动可插拔光模块(LPO)的有力倡导者。7060X6系列明确支持LPO模块,通过去除模块中的DSP来降低功耗和延迟,这对于大规模AI集群的能效至关重要。
Cisco Systems:Nexus的演进
Cisco通过Nexus系列继续巩固其在企业和云市场的地位,并积极拥抱800G。
Nexus 9232E:Cisco首款1RU 800G交换机。
配置:32个QSFP-DD800端口,总容量25.6 Tbps,基于自研Silicon One G100芯片。
能效:Cisco声称,与等效的模块化解决方案相比,其功耗降低77%,节省83%的空间。支持扇出模式,可作为高密度Spine交换机。
Cisco 8100/8800系列:面向服务提供商和超大规模数据中心,同样基于Silicon One架构,支持800G扩展。
华为:智算网络全面布局
作为中国市场的领导者,华为拥有从芯片到系统的全栈自研能力。
CloudEngine 16800系列:面向AI时代的旗舰核心交换机。
架构创新:正交CLOS架构(无背板设计)极大地提高了散热效率和信号完整性。CE16800-X系列支持高密度800GE线卡,单机箱最多支持288个800GE端口,业界领先。
iLossless智能无损算法:华为的核心竞争力。iLossless能够实时学习和训练全网流量模型,动态调整队列拥塞窗口,实现“零丢包”以太网传输,这对于AI训练中的RoCEv2至关重要。
全液冷设计:解决800G散热问题,采用先进的液冷+风冷混合方式为核心部件和光模块散热。
H3C(新华三):CPO与LPO的双重押注
新华三在新一代光封装方面尤为激进,旨在通过技术创新实现超越。
S9827系列:涵盖了800G交换机的多种技术路径。
S9827-64EO(CPO版本):全球首款发布的51.2T CPO硅光交换机。将光引擎与交换芯片共封装,大幅缩短电信号路径,以降低功耗和延迟。新华三声称每个集群的TCO可降低高达30%。
S9827-64E/EP(LPO/标准版本):支持QSFP-DD800和OSFP800接口。LPO版本采用线性驱动技术,结合AI ECN和动态负载均衡,专为AIGC智能计算场景量身定制。
锐捷网络与中兴通讯
锐捷网络:发布了RG-S6990-64OC2XS,一款64端口800G OSFP交换机,定位于AI数据中心的Spine层。强调其在“智速”网络中的低延迟和无损特性,并提供LPO光模块解决方案。其核心交换机RG-N18000-X已支持向800G线卡演进。
中兴通讯:ZXR10 9900X系列数据中心交换机支持高密度400GE,并可平滑演进至800GE,采用无背板正交架构,最大交换容量可达198 Tbps。中兴通讯在长距800G传输(OTN)方面也取得了突破,完成了1200公里的800G传输测试。
Juniper Networks QFX5240系列
基于Broadcom Tomahawk 5。
规格:2U设备,支持64个800G端口(OSFP或QSFP-DD)。
管理:结合Apstra软件,实现基于意图的网络(IBN),简化AI Fabric的部署和运维。
▶ 光互联革命:可插拔、LPO、LRO 与 CPO 的角逐
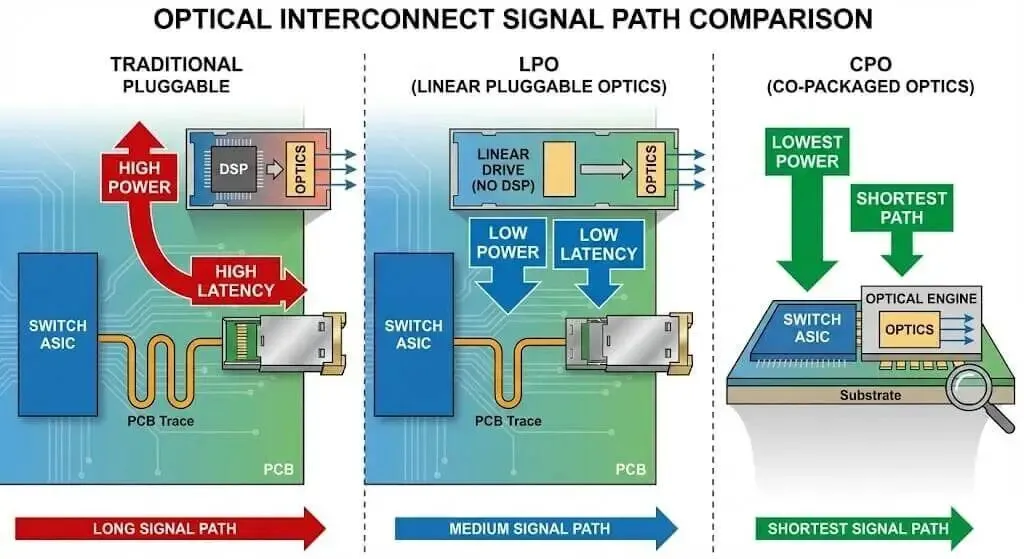
800G时代最大的技术变量不在于电层,而在于光层。随着速率提升,光模块中的DSP功耗飙升,成为系统能效的瓶颈。这引发了关于光互联形态的激烈争论。
传统可插拔光模块
当前主流标准(QSFP-DD800, OSFP)。模块内部集成DSP,用于重定时和均衡。
优点:生态系统成熟,互联互通性好,易于故障隔离和更换。
缺点:功耗高(每个800G模块16-20W,其中约50%来自DSP)。在满载的64端口交换机中,仅模块功耗就可能超过1000W,造成巨大的散热压力。
线性驱动可插拔光模块(LPO)
LPO被视为解决“功耗墙”的最有效短期方案,尤其是在AI集群内部。
原理:去除DSP,仅保留TIA和Driver;均衡和重定时功能由交换芯片ASIC的SerDes完成。
优点:每模块功耗降低约50%(节省约7W),延迟降低纳秒级,BOM成本更低。
挑战:对主机端的信号完整性要求极高;传输距离有限(约500米)。缺乏DSP隔离,因此互操作性需要系统和模块厂商深度耦合。
线性接收光模块(LRO/半重定时)
介于LPO和全重定时模块之间的折中方案。
原理:仅在接收(Rx)端去除DSP,发送(Tx)端保留DSP以保证信号质量。
优点:相比纯LPO,能提供更好的信号一致性和互操作性(模块DSP保证了Tx质量),同时仍能比全DSP模块提供更低的功耗/成本。
定位:适用于希望降低功耗但又担心纯LPO风险的客户。
共封装光学(CPO)
被视为摩尔定律下光互连的最终形态。
原理:光引擎直接与交换芯片ASIC共封装在基板上,消除前面板可插拔接口。
优点:最小化电信号路径,从而实现最低功耗和最高密度。
挑战:可维护性差(故障可能需更换整个交换机);颠覆了传统的解耦供应链。
现状:新华三和Broadcom已发布原型/产品,但大规模商业应用仍仅限于特定的超大规模场景或作为未来储备。
▶ 经济性分析:800G的TCO优势
尽管单端口价格高于400G,但系统级的TCO极具吸引力。
价格交叉:市场数据显示,到2025年,一个800G端口的成本已低于两个400G端口的成本总和,实现了“每比特成本”的交叉。
运营节省:对于大型数据中心而言,基于LPO的800G解决方案每年可节省数百万美元的电力与散热费用。
▶ 热管理与机械工程挑战
当单芯片功耗接近1000W(Tomahawk 5满负荷下)且光模块密度持续增加时,传统的风冷正在逼近其物理极限。
风冷的局限性
将51.2T交换机的热负荷(通常超过2000-3000W)散发在2U的机箱内,这对风冷系统而言是极限挑战。根据风扇定律,风扇功率与转速的立方成正比。为维持可接受的温度,风扇转速必须显著提高,导致风扇本身的功耗在系统总功耗中占比过高(通常>20%),这种状况难以为继。
液冷的引入
800G交换机正成为数据中心引入液冷的先行者。
冷板式液冷:主要针对高功耗的ASIC芯片进行直接液体冷却,而光模块则仍采用风冷。这是目前最实用、应用最广泛的集成方式。
浸没式液冷:将整个系统浸入不导电的冷却液中。这要求光模块必须完全密封且与冷却液兼容。已有厂商开发出适用于浸没式环境的800G光模块。

系统设计创新,新华三的S9827系列和华为的CE16800系列都强调了先进的散热工程设计——采用正交架构优化气流、提供风液混合冷却选项,以及全面降低PUE(电能利用效率)。
▶市场经济学与未来展望
市场规模与预测
800G交换机市场正处于爆发式增长的初期。
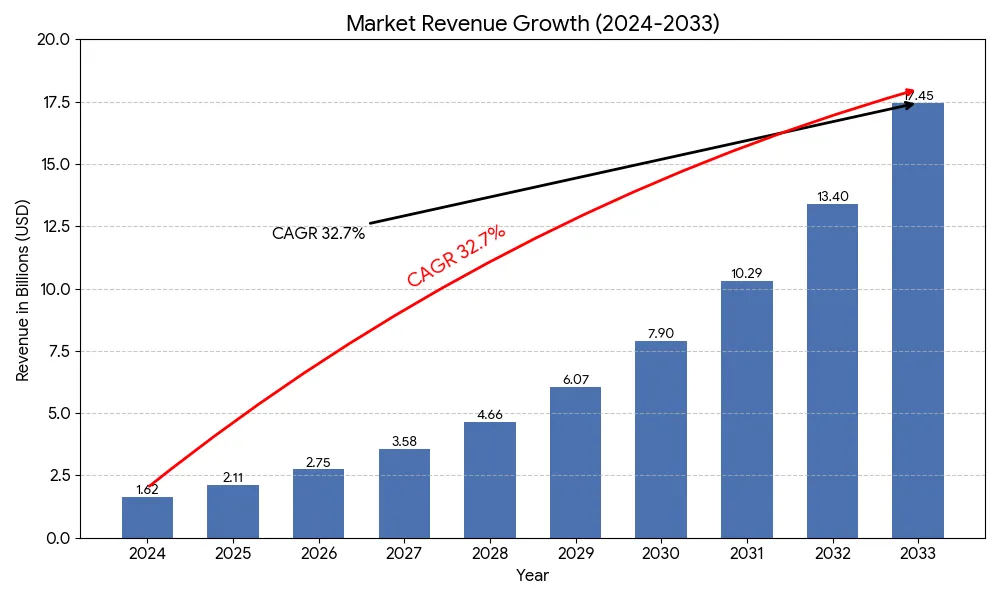
根据Dell'Oro和Dataintelo的报告,2024年全球800G交换机市场规模约为16.2亿美元,预计到2033年将达到174.5亿美元,复合年增长率(CAGR)高达32.7%。
2025年被普遍视为"800G元年",端口出货量预计将创下历史新高——尤其是在AI后端网络中——800G端口正在快速取代400G和200G端口。
市场收入增长趋势图
厂商市场份额分析(全球格局)
海外市场:Arista、NVIDIA和Cisco占据主导地位。Arista在超大规模客户中份额极高;NVIDIA在交钥匙AI Fabric解决方案中近乎垄断。
国内市场:华为和新华三(H3C)形成双寡头格局。华为受益于自研芯片和庞大的装机基础;新华三在采用CPO等新一代技术方面更为激进。锐捷网络是活跃的挑战者,尤其在白盒/ODM合作方面与大型互联网公司合作紧密。
通往1.6T之路
业界已在展望1.6T以太网。
芯片就绪:Broadcom的Tomahawk 6(102.4T)和Marvell的下一代芯片已在规划中,预计2025-2026年出样片。
技术障碍:1.6T将全面采用224G SerDes。这将事实上终结铜互连(DAC/AEC)的实用时代,推动LPO(极短距离)乃至CPO走向主流。
时间线:随着IEEE 802.3dj标准预计在2026年完成,首批1.6T部署预计在2026-2027年,主要用于支持下一代万亿参数模型的训练。
▶ 结论
800G交换机不仅仅是带宽的升级,它是AI时代数据中心的基础设施重构。物理层的极端挑战、光互联形态(从传统可插拔 → LPO → CPO)的戏剧性转变,以及为AI量身定制的网络功能(Spectrum-X、Tomahawk 5 AI增强、iLossless等)的兴起,共同定义了这一技术周期。
对于企业和数据中心运营商而言,选择800G解决方案已不再仅仅是比较端口价格。如今的决策必须综合考虑:
随着2025年价格交叉点的到来,800G的大规模部署已势在必行。在这场竞赛中,谁能最有效地解决"功耗墙"和"延迟墙"的双重挑战,谁就将成为最大的赢家。
