Codex CLI 记忆系统设计调研报告
基于
/Users/wufan/workspace/codex源码分析(主要为 codex-rs/ Rust 实现)调研日期:2026-04-10
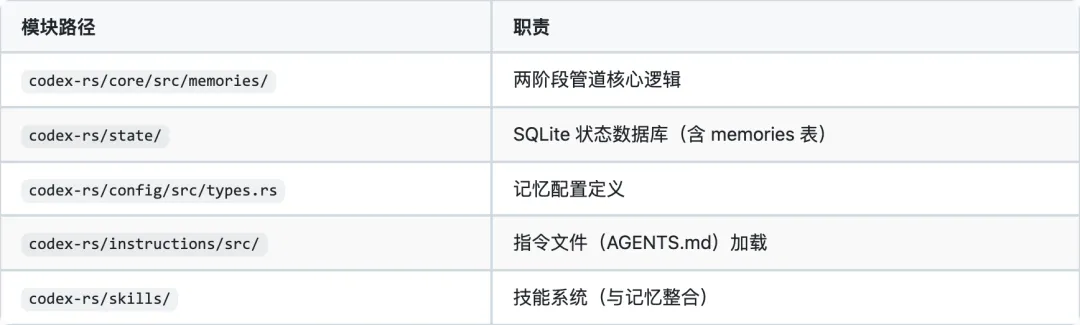
1. 架构概览
Codex 采用 两阶段管道架构(Two-Phase Pipeline),将记忆的提取和整合分为两个独立阶段。存储层使用 SQLite 数据库 + 文件系统 的混合方案,SQLite 负责结构化数据和任务调度,文件系统负责最终的知识文件输出。
核心模块
整体数据流
Rollout (对话会话) ↓Phase 1: 提取(gpt-5.4-mini, 并发 8 个) ↓ 产出 raw_memory + rollout_summarySQLite stage1_outputs 表 ↓Phase 2: 整合(gpt-5.3-codex, 全局锁) ↓ 产出结构化文件文件系统: memory_summary.md / MEMORY.md / skills/2. 存储架构
2.1 文件系统层
$CODEX_HOME/memories/├── memory_summary.md # 高级摘要,自动注入系统提示(5000 token 上限)├── MEMORY.md # 可搜索的索引和手册条目├── raw_memories.md # Phase 1 原始记忆(Phase 2 的输入)├── rollout_summaries/│ └── {rollout_slug}.md # 单个 rollout 的汇总└── skills/ └── {skill-name}/ ├── SKILL.md # 技能入口文档 ├── scripts/ # 可执行脚本 ├── examples/ # 示例输出 └── templates/ # 模板文件三层渐进式披露: 1. memory_summary.md — 总是加载到系统提示,高级导航和决策触发器 1. MEMORY.md — 可搜索的注册表,包含工作流知识、重复模式、失败防护 1. rollout_summaries/ — 按需检索的详细历史
2.2 SQLite 数据库层
核心表结构 (state/migrations/0006_memories.sql, 0016_memory_usage.sql):
-- Phase 1 输出存储CREATE TABLE stage1_outputs ( thread_id TEXT PRIMARY KEY, source_updated_at INTEGER NOT NULL, raw_memory TEXT NOT NULL, rollout_summary TEXT NOT NULL, generated_at INTEGER NOT NULL, usage_count INTEGER, -- 使用频率追踪 last_usage INTEGER, -- 最后使用时间 selected_for_phase2_source_updated_at INTEGER -- Phase 2 选择标记);-- 任务调度CREATE TABLE jobs ( kind TEXT NOT NULL, -- 'stage1' | 'phase2' job_key TEXT NOT NULL, status TEXT NOT NULL, -- pending | running | succeeded | failed worker_id TEXT, ownership_token TEXT, lease_until INTEGER, retry_remaining INTEGER NOT NULL, last_error TEXT, PRIMARY KEY (kind, job_key));2.3 线程级记忆模式
每个对话线程(thread)有独立的记忆模式:
threads.memory_mode:├── 'enabled' — 默认,参与记忆生成├── 'disabled' — 如果 generate_memories=false└── 'polluted' — MCP 工具或 web 搜索调用后标记污染机制:当线程中使用了 MCP 工具或 web 搜索时,标记为 polluted,防止不可信来源的信息污染记忆库。
3. 两阶段管道
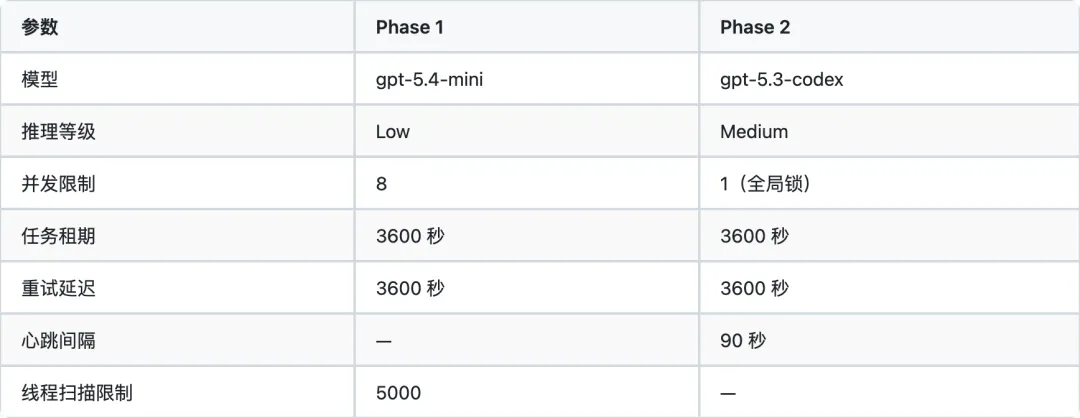
3.1 Phase 1:提取(Extraction)
文件:codex-rs/core/src/memories/phase1.rs
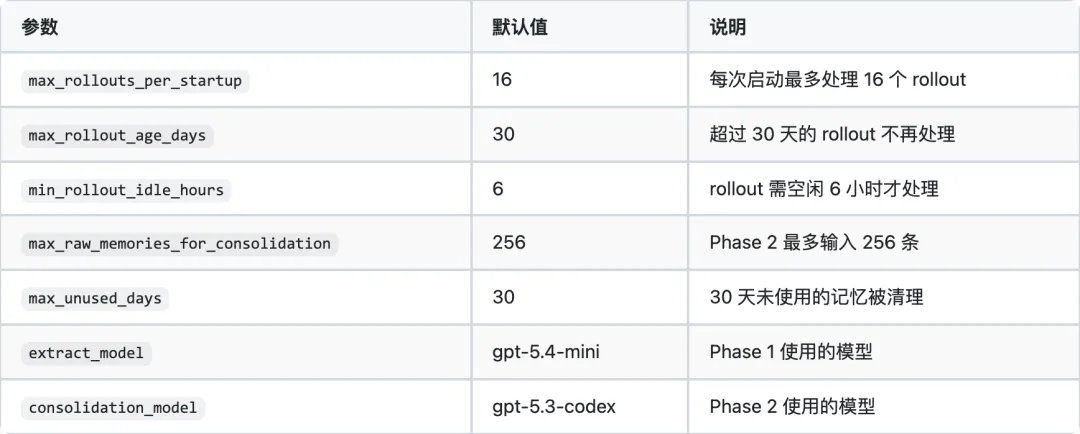
启动条件:├── 非临时会话(!config.ephemeral)├── Feature::MemoryTool 启用├── 非子代理会话└── 状态数据库可用执行流程:1. Prune → 清理超过 max_unused_days(默认 30 天)的旧记忆2. Claim → 扫描最多 5000 个线程,认领可处理的任务3. Build Context → 读取 rollout JSONL,构建输入消息4. Run Jobs → 并发 8 个,调用 gpt-5.4-mini(推理等级 Low)5. Save → 将 Stage1Output 写入 SQLitePhase 1 输入截断: - 模型有效上下文窗口的 70%(CONTEXT_WINDOW_PERCENT = 70) - 默认回退:150,000 tokensPhase 1 输出结构:
{ "raw_memory": "详细的 markdown 记忆,包含任务分析、偏好信号、失败防护", "rollout_summary": "简洁摘要,供未来参考", "rollout_slug": "filesystem-safe 的标识符(可选)"}任务分类(Triage): - outcome = success — 任务完成 - outcome = partial — 有进展但不完整 - outcome = uncertain — 无明确信号 - outcome = fail — 失败或卡住
3.2 Phase 2:整合(Consolidation)
文件:codex-rs/core/src/memories/phase2.rs
执行流程:1. Claim → 全局锁(同一时间只有一个 Phase 2 运行)2. Select → 获取最常用的 N 条 Stage1Output(默认 256) ├── 按 usage_count DESC 排序 ├── 按 last_usage DESC 排序 └── 按 source_updated_at DESC 排序3. Sync → 将 rollout summaries 同步到文件系统4. Rebuild → 重建 raw_memories.md5. Spawn Agent → 启动整合代理(gpt-5.3-codex, 推理等级 Medium)6. Monitor → 监控完成,更新 MEMORY.md 和 memory_summary.mdPhase 2 输出: - memory_summary.md — 高级导航(最高权重) - MEMORY.md — 可搜索索引 - skills/{name}/ — 从反复出现的模式中提取的可复用程序
3.3 Phase 1 提示词的核心原则
从 stage_one_system.md 模板: 1. 证据驱动:不虚构事实,只从实际对话中提取 1. 最小信号门槛:无意义的学习返回空结果 1. 高信号优先:用户偏好 > 程序事实 1. 安全防护:秘密替换为 [REDACTED_SECRET]
4. 配置系统
4.1 配置结构
文件:codex-rs/config/src/types.rs
pub struct MemoriesConfig { pub no_memories_if_mcp_or_web_search: bool, // MCP/Web 搜索是否污染 pub generate_memories: bool, // 是否生成新记忆 pub use_memories: bool, // 是否注入记忆 pub max_raw_memories_for_consolidation: usize,// Phase 2 最大输入数 pub max_unused_days: i64, // 过期天数 pub max_rollout_age_days: i64, // rollout 最大年龄 pub max_rollouts_per_startup: usize, // 每次启动处理数 pub min_rollout_idle_hours: i64, // 最小空闲时间 pub extract_model: Option<String>, // Phase 1 模型 pub consolidation_model: Option<String>, // Phase 2 模型}4.2 默认参数
4.3 TOML 配置示例
[memories]no_memories_if_mcp_or_web_search = falsegenerate_memories = trueuse_memories = truemax_raw_memories_for_consolidation = 256max_unused_days = 30extract_model = "gpt-5.4-mini"consolidation_model = "gpt-5.3-codex"5. 上下文注入
5.1 System Instructions 注入
memory_summary.md 的注入:
pub(crate) async fn build_memory_tool_developer_instructions( codex_home: &Path) -> Option<String> { let memory_summary = fs::read_to_string(&memory_summary_path).await.ok()?; let memory_summary = truncate_text( &memory_summary, TruncationPolicy::Tokens(5000), // 硬截断 ); MEMORY_TOOL_DEVELOPER_INSTRUCTIONS_TEMPLATE.render([ ("base_path", base_path.as_str()), ("memory_summary", memory_summary.as_str()), ]).ok()}5.2 记忆引用格式
Agent 使用记忆时通过特殊标记引用:
<oai-mem-citation><citation_entries>MEMORY.md:234-236|note=[说明文本]rollout_summaries/foo.md:10-12|note=[说明文本]</citation_entries><rollout_ids>019c6e27-e55b-73d1-87d8-4e01f1f75043</rollout_ids></oai-mem-citation>引用由 citations.rs 中的 parse_memory_citation() 解析,用于追踪记忆使用情况。
5.3 搜索预算
记忆工具指令(read_path.md 模板)定义了使用决策边界:应跳过记忆的场景: - 自包含请求、简单翻译、查询当前日期应使用记忆的场景: - 提及工作区/repo、请求先前上下文、任务不明确搜索预算: - 理想:≤4-6 个搜索步骤 - 避免:广泛扫描所有 rollout summaries
6. 使用追踪与过期
6.1 使用追踪
数据库字段(0016_memory_usage.sql):
ALTER TABLE stage1_outputs ADD COLUMN usage_count INTEGER;ALTER TABLE stage1_outputs ADD COLUMN last_usage INTEGER;文件访问追踪种类(usage.rs): - memory_md — MEMORY.md - memory_summary — memory_summary.md - raw_memories — raw_memories.md - rollout_summaries — rollout_summaries/ - skills — skills/
6.2 过期策略
Pruning 机制:
pub async fn prune(session: &Arc<Session>, config: &Config) { let max_unused_days = config.memories.max_unused_days; db.prune_stage1_outputs_for_retention(max_unused_days, PRUNE_BATCH_SIZE).await}6.3 Phase 2 选择策略
基于使用频率的优先级排序:
SELECT * FROM stage1_outputsWHERE last_usage > (now - max_unused_days)ORDER BY usage_count DESC, -- 最常用的优先 last_usage DESC, -- 最近用的优先 source_updated_at DESC -- 最新的优先LIMIT 2567. 并发与调度
7.1 任务调度系统
pub struct Stage1JobClaimOutcome { Claimed { ownership_token: String }, // 成功认领 SkippedUpToDate, // 已是最新 SkippedRunning, // 正在处理 SkippedRetryBackoff, // 重试退避中 SkippedRetryExhausted, // 重试已耗尽}7.2 关键运行时参数
7.3 污染追踪
async fn maybe_mark_thread_memory_mode_polluted( sess: &Session, turn_context: &TurnContext) { state_db::mark_thread_memory_mode_polluted(...)}触发条件: - MCP 工具调用 - Web 搜索调用
8. 指令系统(AGENTS.md)
8.1 结构
pub struct UserInstructions { pub directory: String, pub text: String,}pub struct SkillInstructions { pub name: String, pub path: String, pub contents: String,}8.2 注入格式
## AGENTS.md instructions for <directory><INSTRUCTIONS>{内容}</INSTRUCTIONS><skill><name>skill-name</name><path>/path/to/skill</path><contents>{SKILL.md 内容}</contents></skill>9. 度量与监控
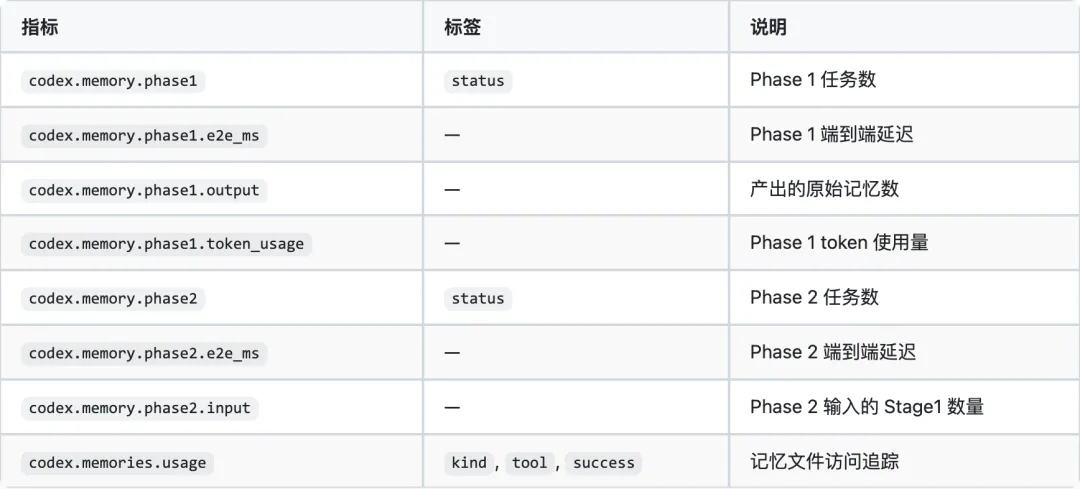
10. 设计亮点与权衡
亮点
usage_count 和 last_usage 的选择策略,确保最有价值的记忆优先保留和整合。越常用的记忆越不容易被清理。polluted 状态标记线程,防止这些信息污染记忆库。权衡
11. 关键文件索引