OCR技术行业应用案例深度解析:PaddleOCR 与 DeepSeek-OCR 的架构演进与业务价值实践 (2025-2026)
1. 视觉语言模型 (VLM) 引领的文档智能范式转移
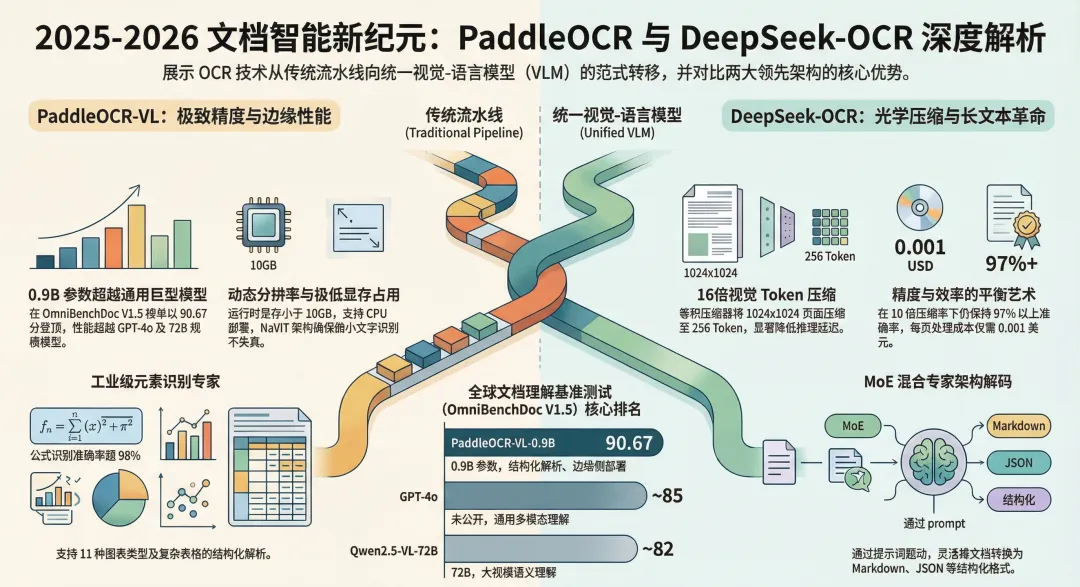
在 2025 年至 2026 年初,文档智能(Document Intelligence)领域完成了一次决定性的架构跃迁:从传统的、依赖布局分析、文本检测、文字识别等多个独立模块的“多阶段流水线”,转向了统一的视觉语言模型 (VLM)架构。这种范式转移的核心在于通过“统一前向传播”(Unified Forward Pass)在单一网络中同步完成感知与认知任务。作为架构师,我们需要关注两大互补的技术路线:PaddleOCR 范式:侧重于“高精度结构化解析”。通过 PP-OCRv5 等模块,将视觉信息精准还原为机器可读的结构化数据,确保在金融、合规等场景下的绝对保真。DeepSeek-OCR 范式:提出了“上下文光学压缩”(Contexts Optical Compression)。它不再单纯追求将图片转为文本,而是将视觉特征作为一种压缩基元,解决大语言模型(LLM)处理长文档时的计算成本瓶颈。这种统一架构解决了传统系统在面对多栏学术论文、复杂无框表格或混排版式时的失效痛点,实现了从单纯的“OCR 识别”到“端到端文档理解”的战略升级。2. 模型性能基准与核心竞争力评估
在 2025 年的选型逻辑中,企业不再仅仅关注 OCR 的单字识别率,而是更看重其在OmniBenchDoc V1.5等标准基准测试下的综合解析能力。这些基准能够量化模型在处理复杂版式、阅读顺序及公式识别等维度的工业化水平。核心模型性能对比
根据 2025 年末的权威评测,PaddleOCR-VL 在小参数规模下表现出了卓越的能效比:| 模型名称 | 综合得分 (OmniBenchDoc V1.5) | 公式识别 | 表格结构 | 阅读顺序 | 参数规模 | 核心组件 || ------ | ------ | ------ | ------ | ------ | ------ | ------ ||PaddleOCR-VL-0.9B|90.67|~85|~88|~90|0.9B| NaViT / ERNIE-4.5-0.3B || GPT-4o | ~85 | ~80 | ~82 | ~85 | 未公开 | 通用 VLM || Gemini 2.5 Pro | ~83 | ~78 | ~80 | ~83 | 未公开 | 通用 VLM || Qwen2.5-VL-72B | ~82 | ~77 | ~79 | ~82 | 72B | 通用 VLM || MinerU 2.5 | ~80 | ~75 | ~78 | ~80 | 未公开 | 专用解析 || InternVL 1.5 | ~78 | ~73 | ~76 | ~78 | 26B | 通用 VLM |架构深度解析
NaViT 与 Native Resolution 策略:PaddleOCR-VL-0.9B 采用了动态分辨率视觉 Transformer (NaViT),能够根据输入文档的视觉复杂度实时调整精度。配合轻量化的ERNIE-4.5-0.3B 语言模型解码器,该架构避免了固定分辨率缩放导致的细小字符或复杂公式丢失,在极低的计算负载下实现了超越 72B 规模通用模型的精度。Mixture-of-Experts (MoE) 与 16 倍压缩:DeepSeek-OCR 引入了混合专家模型 (MoE) 解码器和 16x 卷积压缩器。该设计允许系统将 1024x1024 的高分辨率页面(理论需 4,096 Token)压缩至仅 256 个“视觉 Token”。这种**“Token Economics”**的革新,使企业能够以 1/16 的成本将长文档馈入下游 RAG 系统,显著优化了推理的 TCO(总拥有成本)。3. 物流自动化:边缘侧的实时感知实践
在物流分拣等对时延极端敏感的场景中,架构师的选择往往偏向于轻量化且高并发的方案。
实时感知指标 (2025 年 8 月案例)
基于 PaddleOCR 引擎的智能分拣系统在边缘侧部署中表现出了工业级稳定性:
平均识别耗时:18.4 秒(显著优于 30 秒的行业 benchmark)硬件兼容性优势
PaddleOCR 的核心竞争力在于其CPU 兼容性。由于其 0.9B 的极小内存占用,该方案可在不依赖高昂 GPU 的情况下,在普通服务器 CPU 或 16GB RAM 的工业网关上流畅运行。这降低了分拣线边缘设备的准入门槛,解决了大规模部署时的成本压力。4. 财务与法律领域:高保真提取与长文本 Token 经济学
金融与法律行业对 OCR 的需求呈现出两个极端:极高的信息保真度与极大的存量数据吞吐。
财务场景:防伪与细粒度提取
PaddleOCR-VL 在处理发票核验及金融 KYC 时,展现了提取二维码、官方印章及微小防伪特征的独特能力。这种细粒度捕捉能力为自动化欺诈检测提供了关键证据链,将原本 10 分钟的人工复核流程压缩至数秒。
法律场景:Gundam 模式与 Token 经济学
法律行业涉及海量存量文档数字化。DeepSeek-OCR 利用"Gundam" 瓦片模式(Tiling Mode),通过局部高分辨率处理与全局上下文合并,确保了在 200,000+ 页级别任务中的准确性。吞吐表现:在单个 A100-40G 集群下,利用 vLLM 推理框架可实现700-1,800 份文档/小时的处理能力。压缩比与精度权衡:为了管理风险,架构师必须理解其“精度-压缩”曲线:| 视觉压缩倍率 | 识别精度 (Precision) | 典型应用场景 || ------ | ------ | ------ ||< 10x|> 97.3%|高保真法律/金融合同提取|| 10x - 12x | ~90% | 通用文档检索与管理 || 20x | ~60% | 向量化语义搜索与内存模拟 |通过 7x-20x 的 Token 缩减,数字化百万页档案的成本降至约$0.001/页,使大规模 RAG(检索增强生成)在预算上变得可行。5. 复杂元素识别:公式、表格与图表的结构化攻坚
工业级文档的价值往往隐藏在非文本元素中。
公式与化学式:PaddleOCR-VL 在打印公式识别上达到了95%+的精度。DeepSeek-OCR 2 则凭借 MoE 解码器的任务分配能力,支持高效的SMILES 符号输出,直接赋能生物制药与科研文档的自动化解析。表格解析与 DeepEncoder V2:传统的 VLM 常因处理顺序问题产生“内容重复”或“列漂移”。DeepSeek-OCR 2 引入了DeepEncoder V2,模拟人类“从左至右、从上至下”的顺序扫描逻辑,极大地修正了阅读顺序。而 PaddleOCR 3.0 的 PP-StructureV3 则通过优化布局分区算法,在无框表格场景中保持了 94.5% 的高识别率。视觉问答 (VQA):模型目前已支持对饼图、散点图等 11 种图表进行数据反向推导。这意味着系统不再只是“提取文本”,而是能通过 VQA 接口直接回答“根据图表,第三季度的增长趋势如何?”等深度理解问题。6. 技术局限性应对方案:幻觉、失效与微调策略
在工程落地过程中,生成式架构与批处理系统仍面临显著的局限性。
局限性识别:
生成式幻觉:DeepSeek-OCR 在解释极端复杂的图形时,可能出现虚构数据或内容循环。瞬时失效 (Transient Failures):PaddleOCR 在高并发批处理任务中,存在约20%的概率出现瞬时失效(如仅输出单字符)。工程对策:
强制重试逻辑:生产环境的推理脚本必须嵌入自动重试机制,以对冲 VLM 的偶发不稳定性。Unsloth 高效微调:针对波斯语、阿拉伯语等长尾小语种,利用Unsloth框架进行单轮 (1 Epoch) 微调,可将特定语言的理解能力提升86%-88%。vLLM 架构集成:推荐在 A100/H100 集群上采用 Docker 化的 vLLM 推理方案,以最大化吞吐并降低内存碎片。7. 结论与 2026 战略建议
步入 2026 年,文档智能已不再是单一的技术竞争,而是工程适配与 Token 经济学的博弈。
选型决策建议:
PaddleOCR 3.0 系列:推荐作为生产环境的默认选型。其在边缘侧的灵活性(CPU 友好)以及对公章、二维码、高精度表格的结构化支持,使其成为金融、医疗及工业视觉任务的首选。DeepSeek-OCR 2 系列:推荐作为LLM 原生/RAG 优化选型。对于需要处理数百万页存量档案、追求极低 Token 消耗以及深度语义问答的企业,该架构提供了无可比拟的成本优势。未来展望:视觉-语言-音频统一架构将是下一波浪潮。随着开源模型在 NaViT 动态分辨率与 MoE 压缩技术上的突破,企业应优先考虑能够民主化高保真解析的开源资产,构建具备自主掌控力的智能文档中台。