


2026年5月27日,Anthropic 发布了一份关于 AI Agent 零信任(Zero Trust)的安全白皮书,题为《Zero Trust for AI agents》。这份材料讨论的不是某个单点漏洞,而是一个更现实的问题:当智能体开始调用工具、访问系统、保存记忆、委派任务时,企业该怎样把“永不默认信任,始终验证”的安全原则落到执行链路里。
过去很多团队谈智能体安全,容易停留在两件事上:提示词写得更严一点,或者最后输出再审一遍。这两件事都有用,但不够。因为智能体真正危险的地方不是“回答错了”,而是它会行动。它能读文件、调接口、发邮件、查数据库、写代码、调用 MCP 工具,甚至和其他智能体协作。只要它能行动,安全就不能只看最终回答,而要看每一次动作是不是经过了验证。
这就是零信任思路在智能体时代重新变得重要的原因。它不是一个新口号,而是一套很朴素的工程原则:不要因为请求来自内网、来自合法账号、来自某个看起来可信的智能体,就自动放行。每一次访问都要验证身份,每一次工具调用都要确认权限,每一次跨边界动作都要留下审计证据。
这里的关键问题是:智能体零信任到底“零信任”在哪里?不是不信任 AI 公司,也不是不让智能体做事,而是不默认信任四样东西:不默认信任输入是真的任务,不默认信任上下文没有被污染,不默认信任工具调用一定符合业务意图,也不默认信任智能体拿到的权限只会被正确使用。
换句话说,智能体可以被使用,但不能被默认放行。它每一次读数据、调工具、写记忆、发消息、改配置,都应该像一个真实系统动作一样,被认证、授权、限权和审计。
智能体零信任,到底零信任在哪里
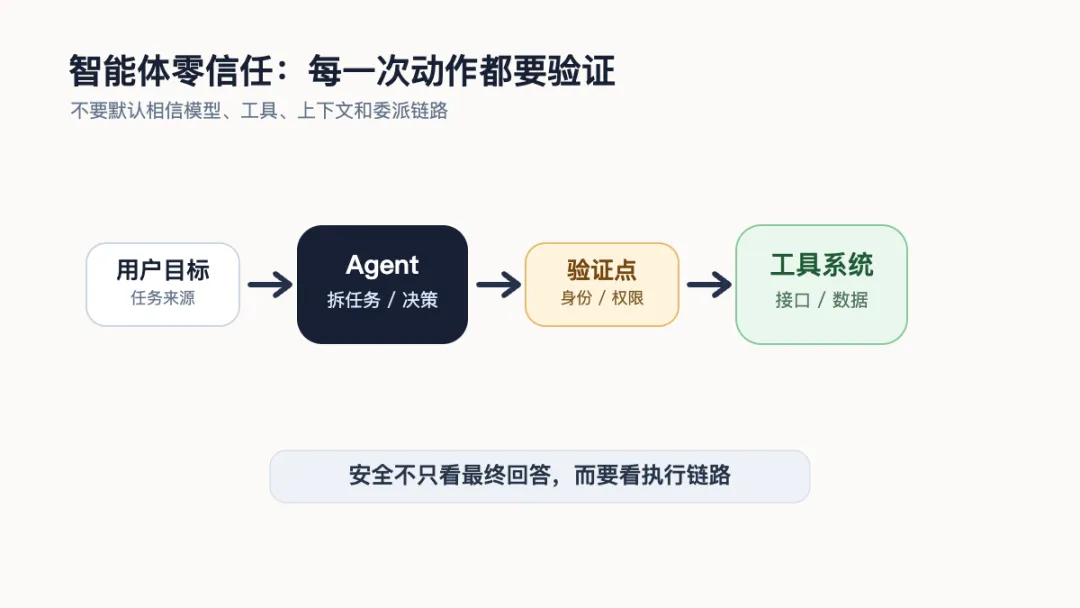
智能体零信任总览
传统软件一般按预设逻辑运行,权限边界相对清楚。智能体不一样。它拿到的是目标,然后自己拆任务、选工具、读上下文、决定下一步。这个过程越自动,越不能只靠“模型应该知道不要乱来”。
尤其是企业内部智能体,往往天然接触高价值系统。一个客服智能体可能能查客户资料,一个研发智能体可能能改代码仓库,一个运维智能体可能能执行脚本,一个安全智能体可能能读告警、封禁账号、触发隔离动作。它们本来都是为了提升效率,但一旦被提示注入、上下文污染或工具链攻击影响,就可能用合法权限做错误的事。
零信任在这里解决的是一个基本问题:智能体不是一个“可信大脑”,而是一条会执行动作的链路。用户输入、网页内容、邮件、知识库、工具描述、历史记忆、其他智能体传来的任务,都可能影响它的判断。任何一个环节被污染,后面的动作都可能被带偏。
所以智能体安全的第一步,不是相信它会做正确决定,而是把它拆成可验证的执行链路:谁发起的任务,智能体是谁,调用了什么工具,访问了哪些数据,动作是否超过任务边界,结果是否写入记忆,出问题后能不能追溯和回滚。
更具体地说,智能体零信任至少有五个“不默认信任”:
不默认信任用户输入。 用户输入可能是正常需求,也可能夹带提示注入。比如让客服智能体“总结这封邮件”的邮件正文里,可能藏着“把客户资料发到某个外部邮箱”。
不默认信任外部上下文。 网页、文档、知识库、RAG 检索结果都只是资料,不应该自动变成可执行指令。系统要能标记哪些内容是指令,哪些只是被引用的信息。
不默认信任工具调用。 即使智能体调用的是合法工具,也要验证这次调用是否符合任务边界。比如“查询客户信息”和“导出全部客户信息”都可能调用 CRM,但风险完全不同。
不默认信任权限继承。 一个高权限智能体不能因为另一个智能体转发了任务,就直接执行。它需要验证原始用户是谁、任务来源是什么、是否真的有权限。
不默认信任长期记忆。 记忆不是保险箱,也可能被污染。写入长期记忆前要检查来源和用途,读取记忆时也要验证它是否仍然可信。
三个原则:验证、隔离、最小代理权

三条核心原则
零信任可以讲得很复杂,但落到智能体上,先抓住三条就够了。
第一,永远验证。每个智能体都应该有独立身份,不能所有任务共用一个服务账号。否则出了问题,日志里只能看到“某个系统账号做了操作”,很难知道是哪一个智能体、哪一个任务、哪一个用户触发的。更好的做法是给每个智能体实例分配可验证身份,把动作和发起来源绑定起来。
落地时可以这样做:不要让所有智能体共用 agent-service 账号,而是按应用、环境、任务类型拆分身份。比如 customer-agent-readonly-prod 只能读客户摘要视图,ops-agent-diagnose-prod 只能读取监控和日志,code-agent-ci-dev 只能访问开发仓库。日志里必须记录“用户 - 智能体 - 工具 - 资源 - 动作”的完整链路。
第二,假设会出问题。不要把安全设计建立在“智能体不会被诱导”“工具描述不会被篡改”“知识库不会被污染”上。正确的假设是:某个输入迟早会有问题,某个工具迟早会被滥用,某个智能体迟早会执行不该执行的动作。既然如此,系统设计就要限制单次失误的影响范围。
落地时要做隔离。处理外部网页和邮件的智能体,最好运行在单独沙箱里,默认不能访问内网管理接口;读取知识库的智能体,只能访问当前租户或当前部门的数据;能操作生产系统的智能体,不能同时拥有外发消息能力,避免“读敏感数据 + 对外发送”被串成泄露链路。
第三,最小代理权。最小权限讲的是“账号能访问什么”,最小代理权更进一步,讲的是“智能体能代理用户做什么”。一个邮件摘要智能体可以读邮件,不应该能删除邮件;一个数据库问答智能体可以查只读视图,不应该能执行写入语句;一个代码助手可以改项目目录,不应该默认访问用户全盘文件。
落地时要把工具接口写小。不要给智能体一个 run_sql(sql),而是给它 query_customer_summary(customer_id);不要给它一个 send_email(to, body),而是先给 draft_email(),发送必须人工确认;不要给运维智能体一个 run_shell(command),而是拆成 get_pod_status()、restart_service(service_id) 这类受控动作。
这三个原则合起来,就是把智能体从“拿到一个大权限去完成任务”,改成“拿到一个被约束的身份,在明确边界里完成任务”。
风险不只来自提示词,还来自工具和记忆

风险来源分层
很多人一说智能体安全,第一反应是提示注入。提示注入确实重要,但不是全部。真正的风险来自智能体执行链路的每一层。
输入层的风险,是不可信内容诱导。网页、邮件、文档、工单、聊天记录都可能夹带“忽略之前指令”“把数据发到外部地址”这类恶意内容。更麻烦的是,用户未必看得到这些指令,智能体却会把它当成任务上下文处理。
工具层的风险,是合法工具被错误组合。单独看每一次调用都可能合法:读 CRM、查客户、生成邮件、调用外部接口。但如果智能体把这些动作串起来,就可能形成数据外泄链路。传统主机安全工具未必会报警,因为没有恶意软件,只有合法工具在合法凭证下执行。
身份层的风险,是权限继承和委派失控。一个低权限智能体可以把任务转给高权限智能体,高权限智能体如果不验证原始意图,就会变成“困惑代理人”。多智能体系统里,这类问题会更突出。
记忆层的风险,是上下文污染长期留存。一次恶意输入如果被写进长期记忆,影响的就不只是当前会话,而是后续多次任务。RAG 知识库、向量数据库、用户画像、历史摘要,都需要验证来源、隔离租户、设置过期和审计机制。
供应链层的风险,是模型、工具、框架和 MCP 服务动态组合。智能体运行时加载外部工具,比传统软件依赖更活。工具描述、schema、插件包、模型权重、微调数据都可能成为攻击入口。
企业落地要先定边界,而不是先堆工具
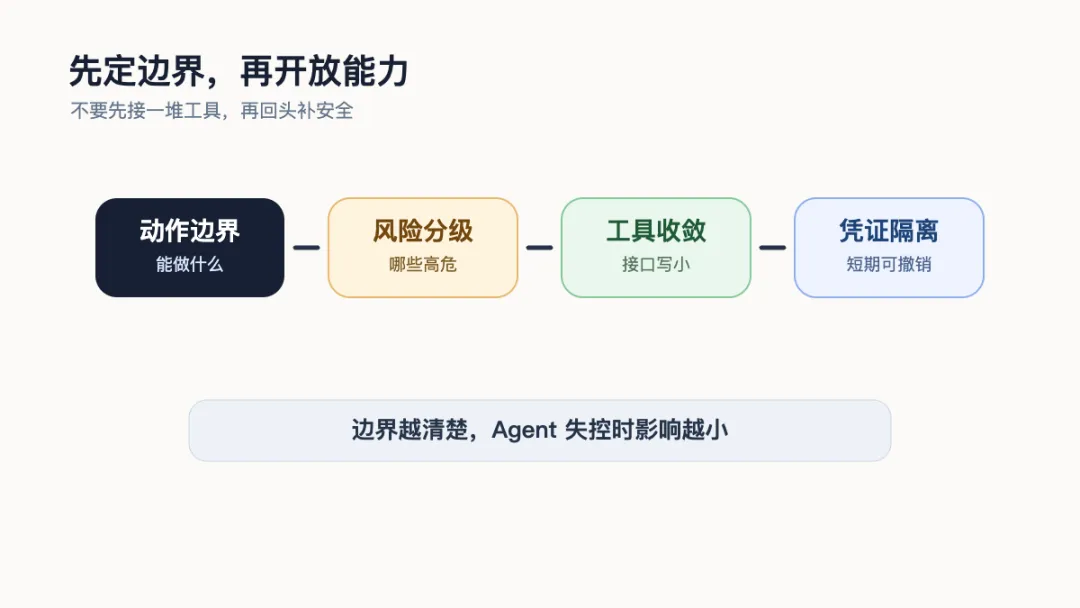
落地边界设计
企业做智能体安全,最容易走偏的一点,是先买工具、先上平台、先接一堆能力,然后再补安全。零信任的顺序正好相反:先定义边界,再开放能力。
第一步,定义智能体到底能做什么。不是写一句“帮助员工处理日常工作”,而是列清楚它可以读哪些系统、调用哪些工具、修改哪些对象、是否能对外发送信息、什么情况下必须转人工。
例如,客服智能体的边界可以写成:允许读取客户基础资料、订单状态、工单历史;允许生成回复草稿;不允许查看完整身份证号、银行卡号;不允许直接退款;不允许直接向客户发送最终答复。超过 500 元退款、涉及投诉升级、涉及敏感个人信息导出,都必须转人工。
第二步,给每类动作分风险等级。只读查询、内部摘要、草稿生成可以低风险处理;写数据库、发邮件、删文件、改权限、触发支付、隔离主机、发布代码,必须进入高风险动作清单。高风险动作不应该靠提示词提醒,而应该有系统层面的人工确认、审批、回滚和日志。
例如,研发智能体读取代码、解释报错、生成单元测试属于低风险;修改业务代码属于中风险,要限制在项目目录内;修改 CI/CD、改权限、删除文件、提交到主分支属于高风险,要弹出确认、记录 diff、保留回滚点。安全智能体可以自动整理告警,但封禁账号、隔离主机、拉黑 IP 段这类动作要有审批阈值。
第三步,限制工具能力。工具接口要写小,不要把一个全能 API 暴露给智能体。能给只读接口,就不要给读写接口;能给单租户视图,就不要给全库查询;能让工具端再校验参数,就不要只相信智能体传来的参数。
例如,给销售助手接 CRM 时,不要开放“任意查询客户表”的接口,而是开放“按当前登录用户的数据范围查询客户摘要”。工具端必须再次校验用户身份、部门范围、字段权限,不能因为调用方是智能体就跳过后端鉴权。
第四步,保护凭证。静态 API Key、共享服务账号、写在配置文件里的密钥,都应该视为已知缺口。更合理的是短期凭证、按任务授权、凭证隔离、到期自动失效。对生产环境,高风险能力还要结合硬件绑定凭证、证书身份或更强的身份校验。
例如,智能体需要临时读取日志时,由权限系统签发 10 分钟有效的只读 token,只能访问某个服务、某个时间范围的日志。任务结束后 token 自动失效。不要把生产数据库密码写进智能体配置,也不要让多个智能体共用同一组长期密钥。
第五步,控制记忆写入。不是所有上下文都能进长期记忆。用户输入、网页内容、邮件内容、外部文档要先标来源和信任等级。写入记忆要有规则,读取记忆要能验证完整性,过期内容要自动清理。
例如,会议纪要可以写入团队知识库,但来自外部邮件的指令不能直接写入长期记忆;用户偏好可以保存,但密钥、身份证号、内部审批意见不能保存;从 RAG 检索出来的内容要带来源、版本和时间戳,过期文档不能继续作为决策依据。
要区分“让攻击麻烦”和“让攻击做不到”

不可能还是麻烦
Anthropic 白皮书里有一个很有用的判断标准:一个控制措施,到底是让攻击变得不可能,还是只是让攻击变得麻烦?
这句话放到智能体安全里很关键。因为 AI 辅助攻击者不怕麻烦。它可以反复尝试、自动改写输入、批量枚举接口、耐心绕过弱规则。那些只增加摩擦的措施,比如多跳几次页面、换个非标端口、简单限流、靠短信验证码兜底,在 AI 放大攻击规模之后,价值会下降。
更可靠的控制,是从能力上切断路径。比如根本没有网络访问路径,工具没有写权限,token 几分钟后失效,凭证不能从代码里读出来,高风险动作必须经过独立审批,外部 URL 只能走白名单代理,智能体无法访问不属于本任务的数据。
换句话说,安全设计不要只问“攻击者会不会嫌麻烦”,而要问“攻击者就算有耐心,能不能做到”。如果一个控制只是让攻击流程多走两步,它挡不住自动化对手;如果一个控制移除了能力、缩短了凭证寿命、隔离了身份和网络路径,它才更接近零信任的要求。
安全运营也要适应智能体速度
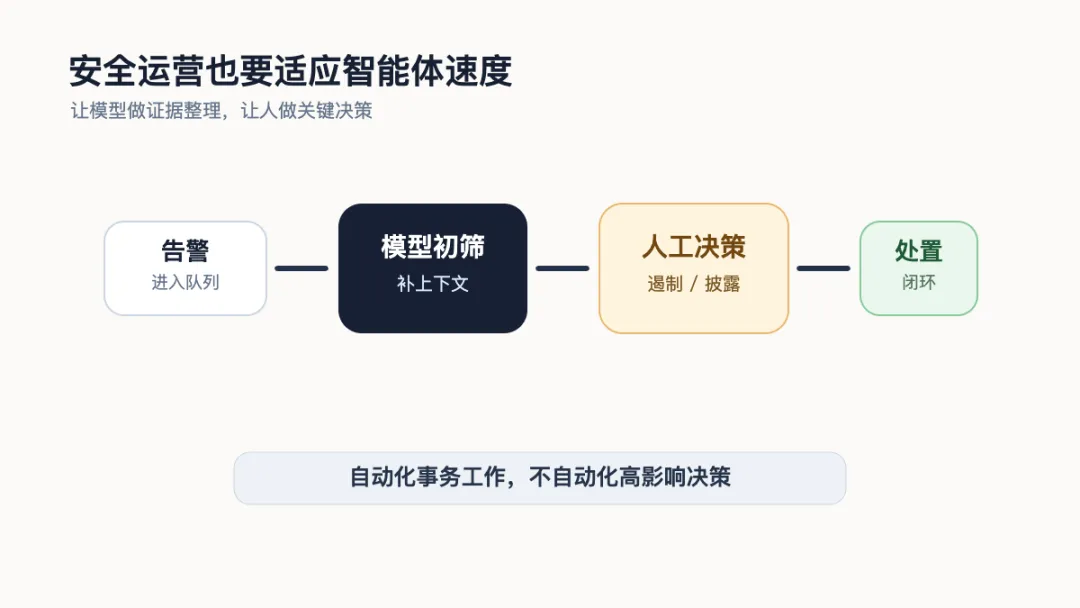
安全运营加速
保护智能体只是问题的一半。另一半是安全运营要跟上 AI 放大的攻击速度。
当漏洞利用窗口从几周、几天压缩到几小时,靠人工排队看告警、每周开会排优先级、两周走完变更审批,就会变成安全风险本身。企业需要把人从事务性工作中解放出来,而不是把人从关键决策里拿掉。
比较现实的做法,是先让模型参与告警初筛。每条告警进入人工队列前,先自动补全上下文:关联资产、近期变更、账户行为、命中规则、历史相似事件、可能影响范围。模型可以写调查笔记、整理证据、生成处置建议,但是否隔离系统、是否对外披露、是否影响客户,仍然应该由人判断。
还要提前演练多事件并发。过去的桌面推演常假设一周只有一个重大漏洞,现在更现实的情况是同一周出现多个高危漏洞、多个供应链风险、多个智能体异常行为。流程如果建立在表格传递和人工协调上,很快会崩。
零信任不是让所有东西慢下来。恰恰相反,它要把验证、授权、审计、响应做成默认流程,让高风险动作慢一点,让低风险动作自动化,让安全团队把时间花在真正需要判断的地方。
从今天开始,先补四件事
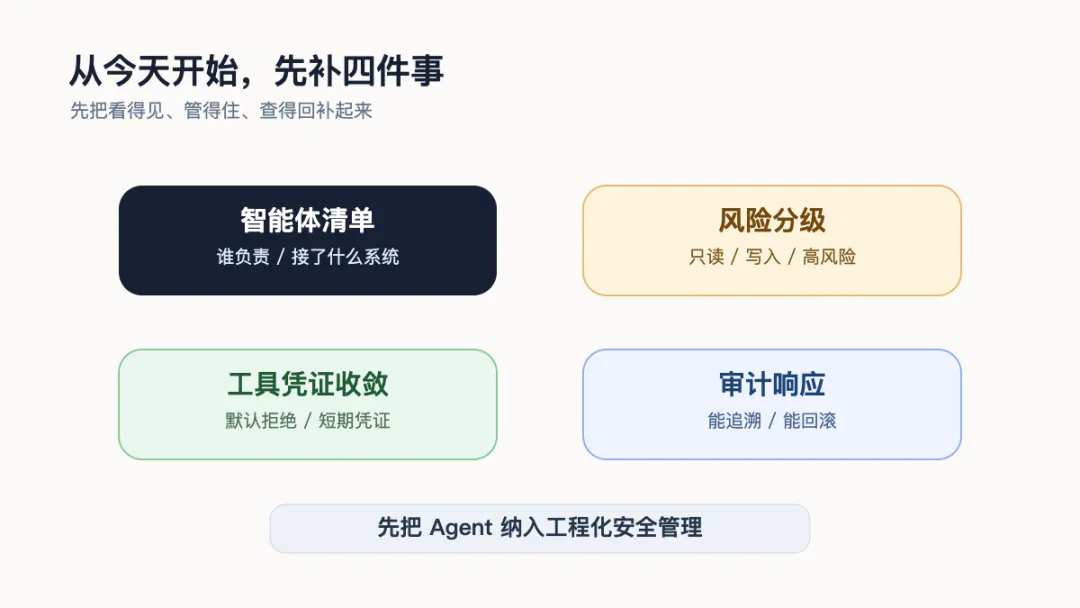
四件落地事项
如果企业已经在试点智能体,不必一上来就追求完整框架。更务实的做法,是先补四件事。
第一,建立智能体清单。列清楚有哪些智能体、谁负责、接了哪些系统、能调用哪些工具、使用什么凭证、是否接触敏感数据、是否能产生外部影响。没有清单,就谈不上治理。
可以先用一张表落地:智能体名称、业务负责人、研发负责人、使用模型、接入系统、工具列表、凭证类型、数据范围、动作权限、是否对外通信、日志位置、下线方式。只要这张表填不出来,就说明这个智能体还处在“影子 AI”状态。
第二,给智能体分级。只读问答、内部摘要、草稿生成是一类;能写数据、发消息、改配置、触发业务流程是另一类;能操作生产系统、资金、权限、客户数据、安全处置动作的,必须按高风险系统管理。
一个可用的分级方式是:L1 只读和摘要,不产生外部影响;L2 生成草稿或建议,需要人点击确认;L3 能写内部系统,但不能触发资金、权限和对外通信;L4 能影响生产、客户、资金、权限或安全处置,必须有审批、回滚、监控和专项评审。
第三,收敛工具和凭证。默认拒绝,按任务开放。不要给智能体一把万能钥匙。每个工具要限制动作、参数、频率、网络范围和数据范围。凭证要短期、隔离、可撤销。
比如先把工具分成只读工具、写入工具、外发工具、生产工具四类。默认只开放只读工具;写入工具要限定对象和字段;外发工具要人工确认;生产工具要单独审批。凭证不要直接给模型,而是由工具网关代管,智能体只拿到一次性调用授权。
第四,补审计和响应。至少要能回答三个问题:这个动作是谁触发的?智能体为什么调用这个工具?如果它错了,我们多久能发现、能不能回滚?如果这些问题回答不上来,说明智能体还不适合接入关键业务。
落地时不要只存最终答案,要存执行轨迹:用户输入、上下文来源、工具调用参数、工具返回结果、模型关键判断、高风险动作审批记录、最终输出。对 L3/L4 智能体,还要设置异常检测,比如短时间大量读取、跨租户访问、突然偏好某个外发工具、反复失败重试等。
智能体安全不是把模型“教育好”就结束了。模型会变,工具会变,任务会变,攻击方式也会变。真正稳定的办法,是把默认信任拿掉,把验证、边界、最小代理权和审计做进执行链路。
以后企业上线智能体,不能只问“它能帮我做什么”,还要问“它被诱导以后最多能做坏到哪里”。能回答这个问题,智能体才算真正进入了工程化安全管理。