



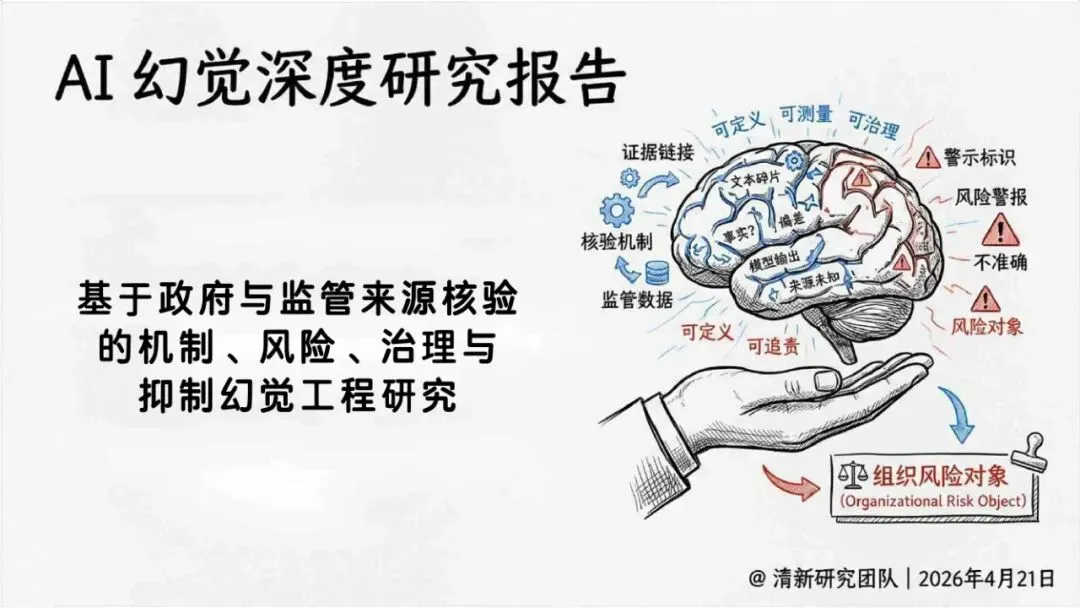
来源:清新研究
本篇系统梳理了《2026年AI幻觉深度研究报告》的核心结论与治理建议。
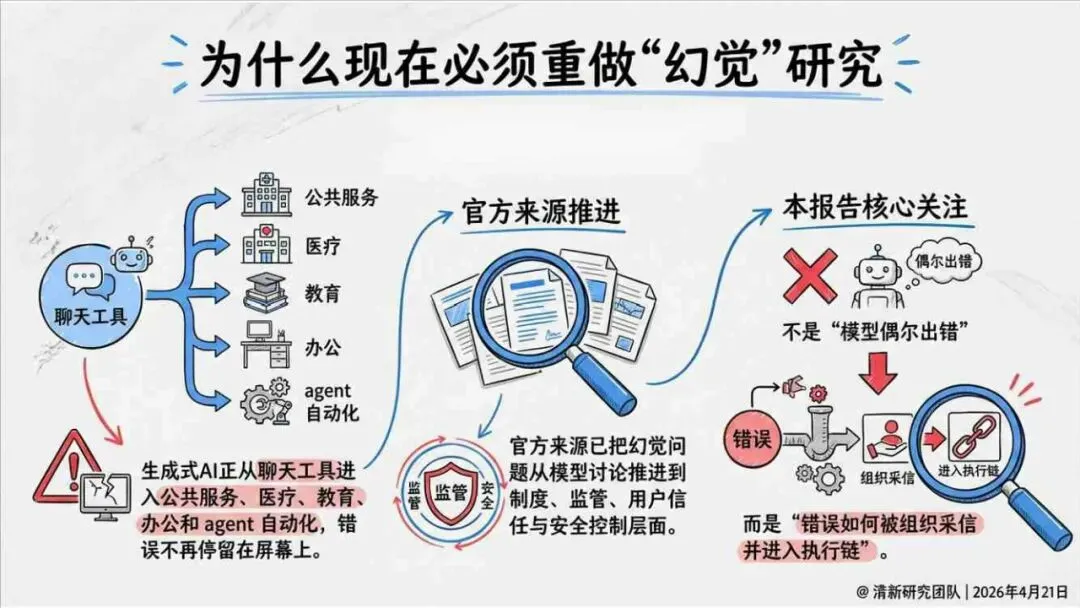
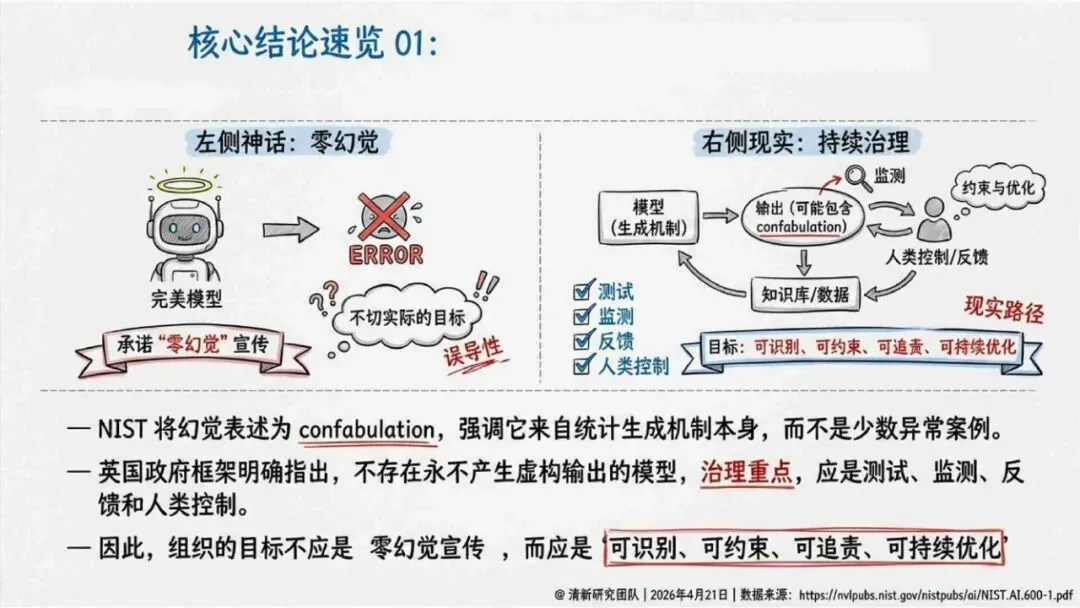
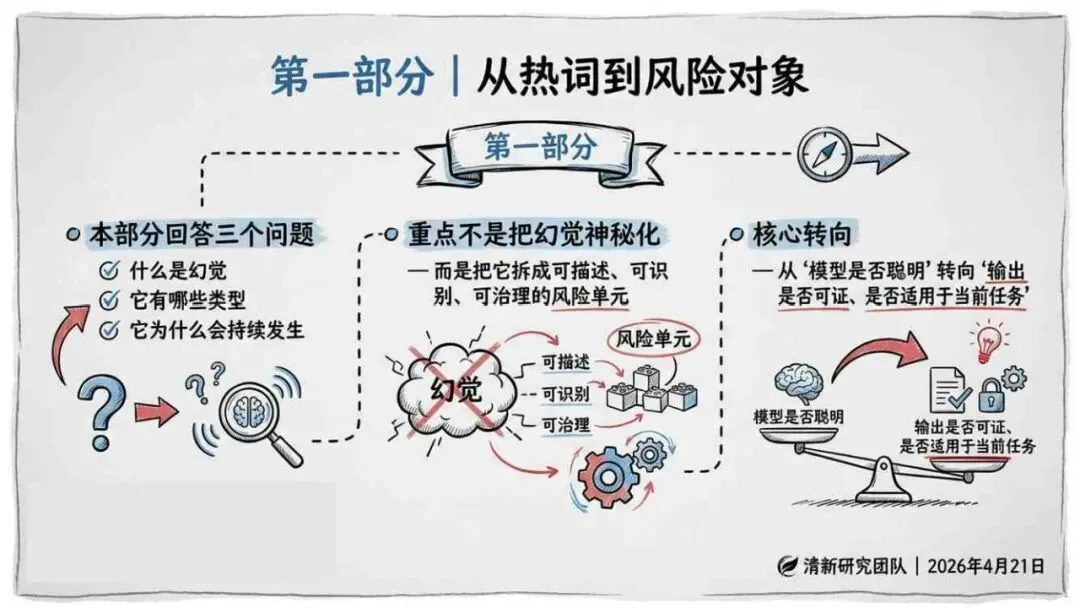
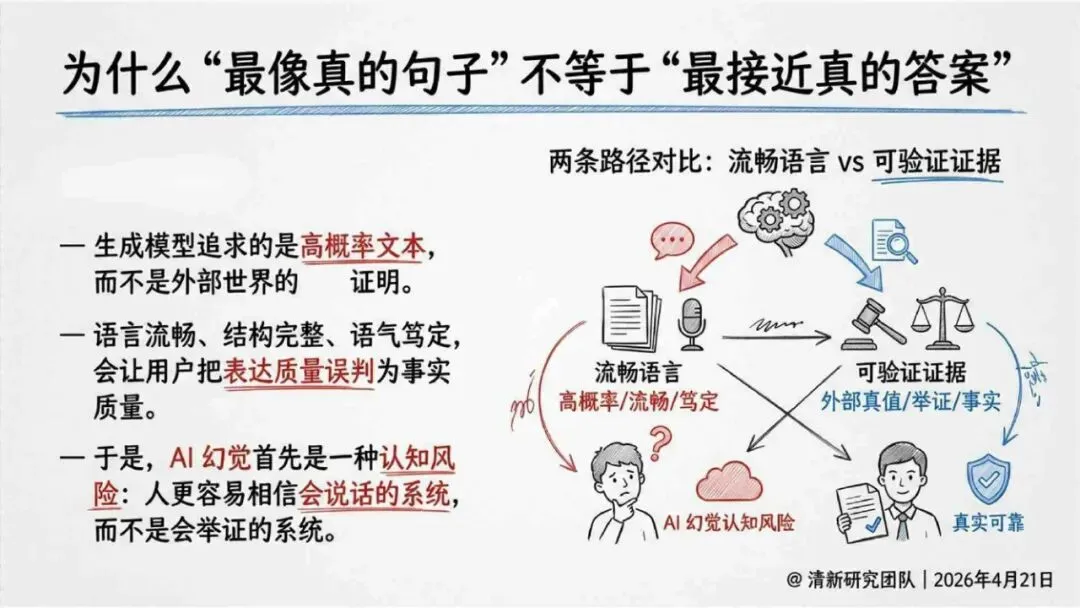
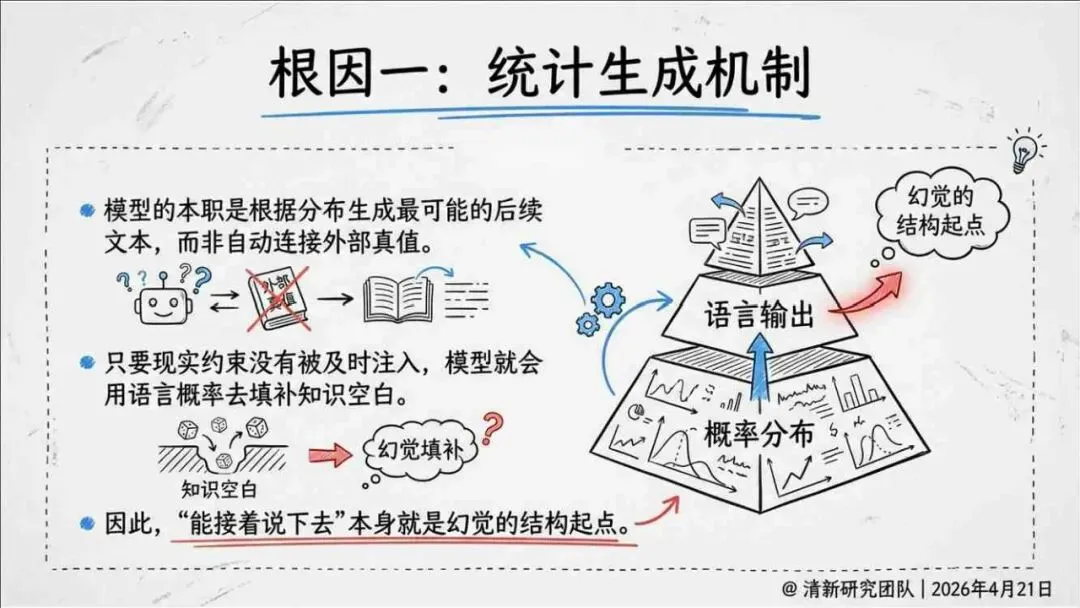
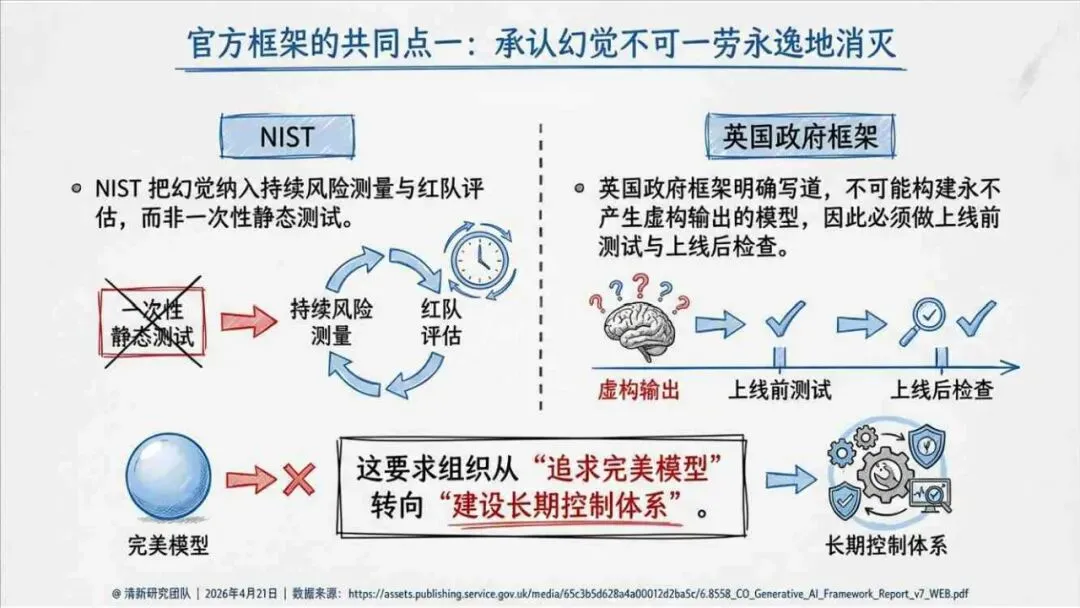
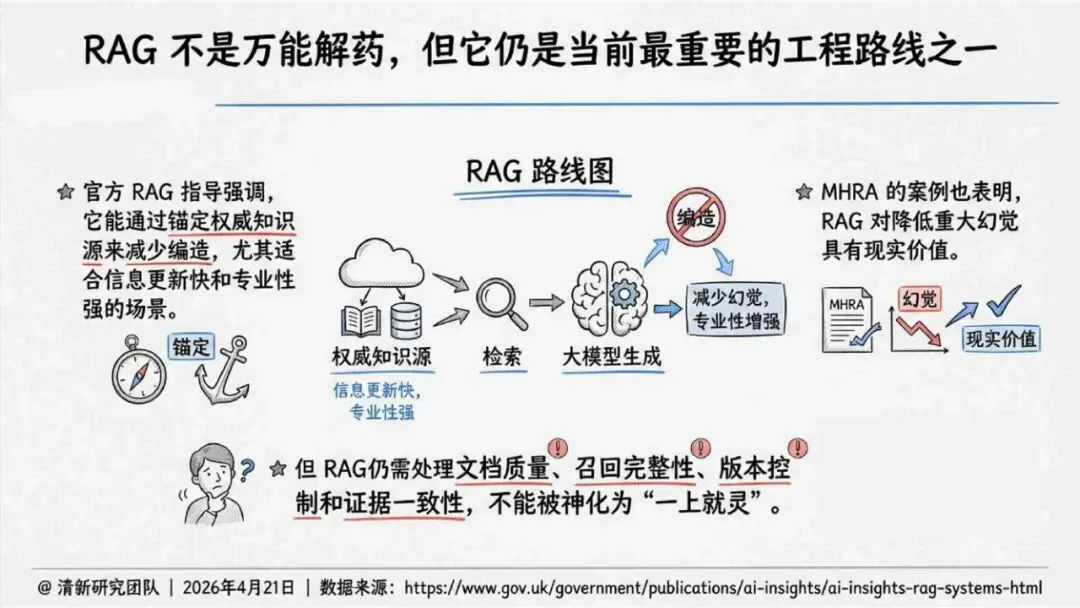
生成式AI在产业落地的关键之一,就是怎么读懂“幻觉”这件事。报告由清华大学新闻与传播学院新媒体研究中心指导、旗下“清新研究”团队撰写。内容体系覆盖幻觉分类、根源与全链条治理路径。幻觉本身是AI统计生成机制作用下的必然结果,不是偶然出错,也无法彻底消除。核心问题从“能不能让它不犯错”转变成“能不能在发生的时候看得见、控得住”。
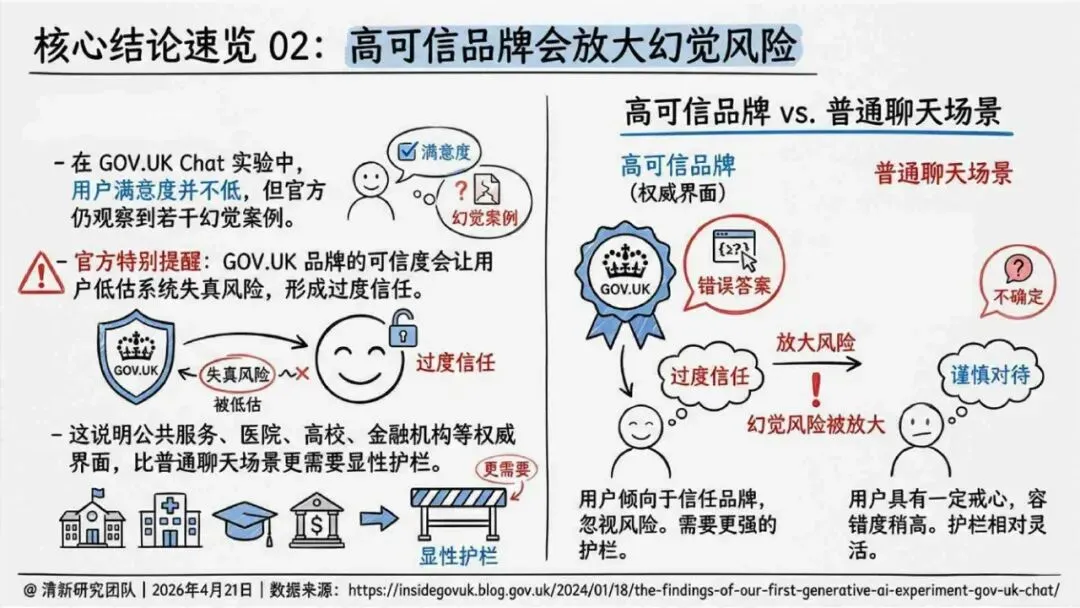
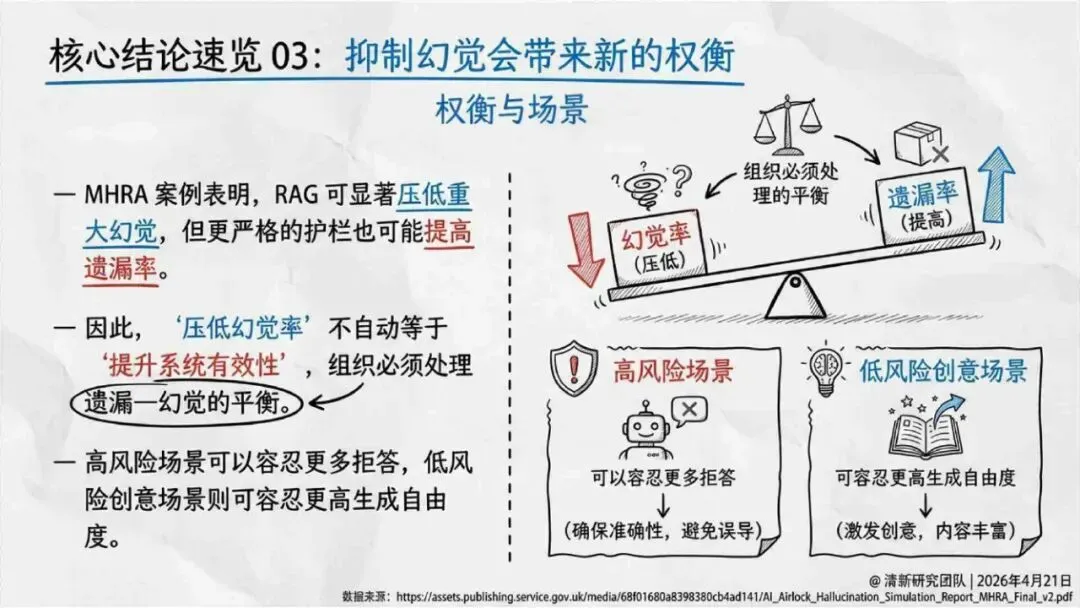
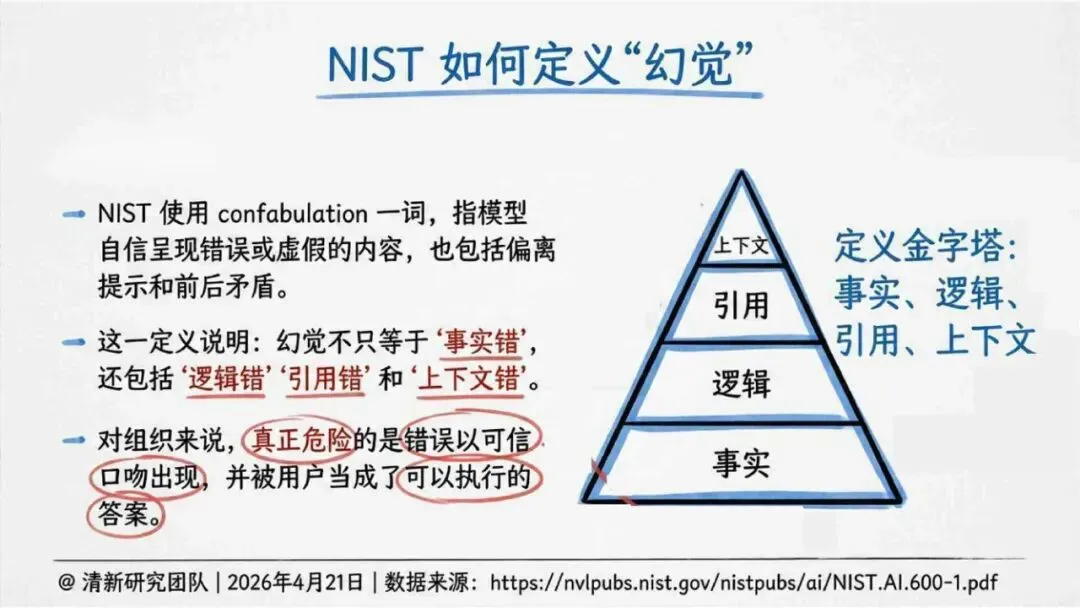
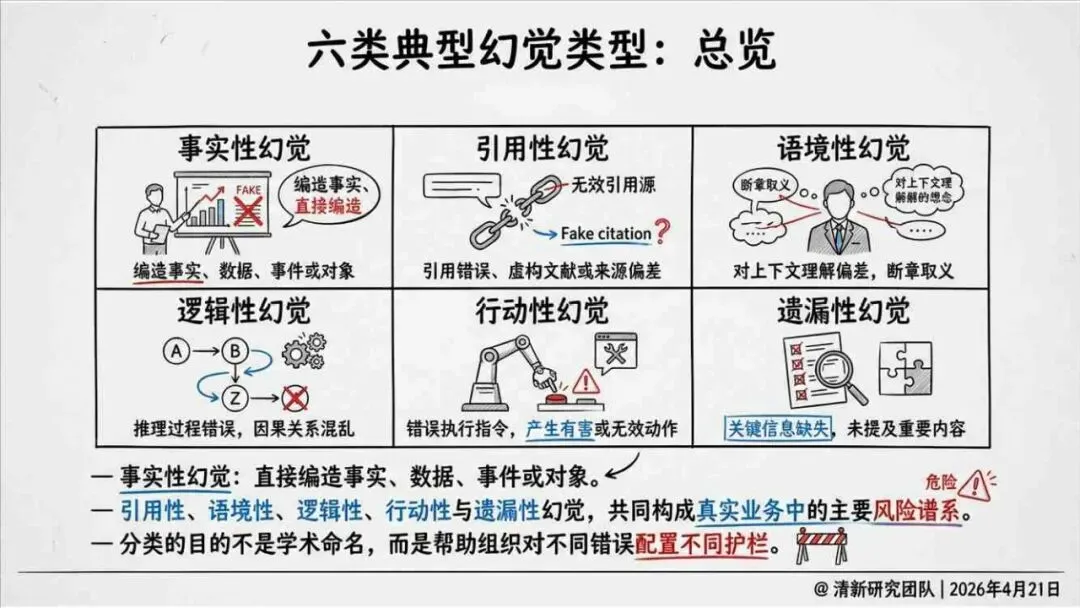
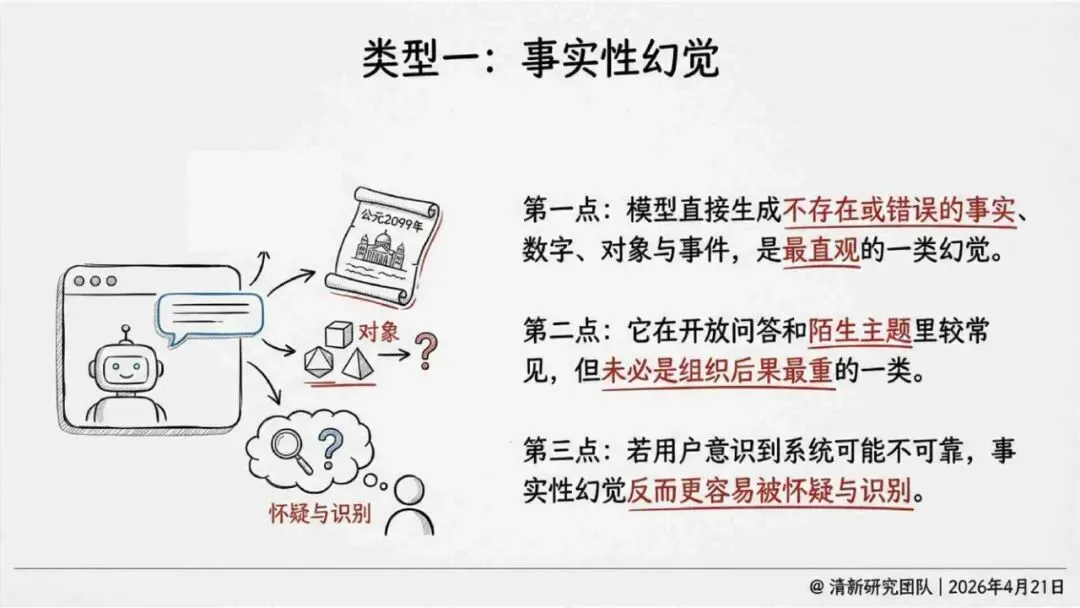
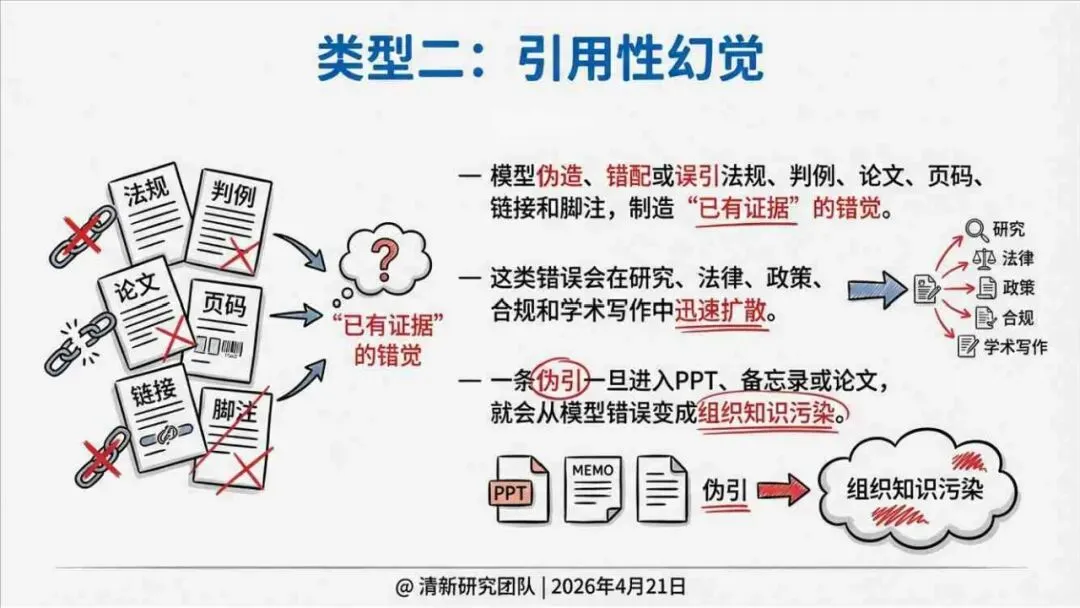
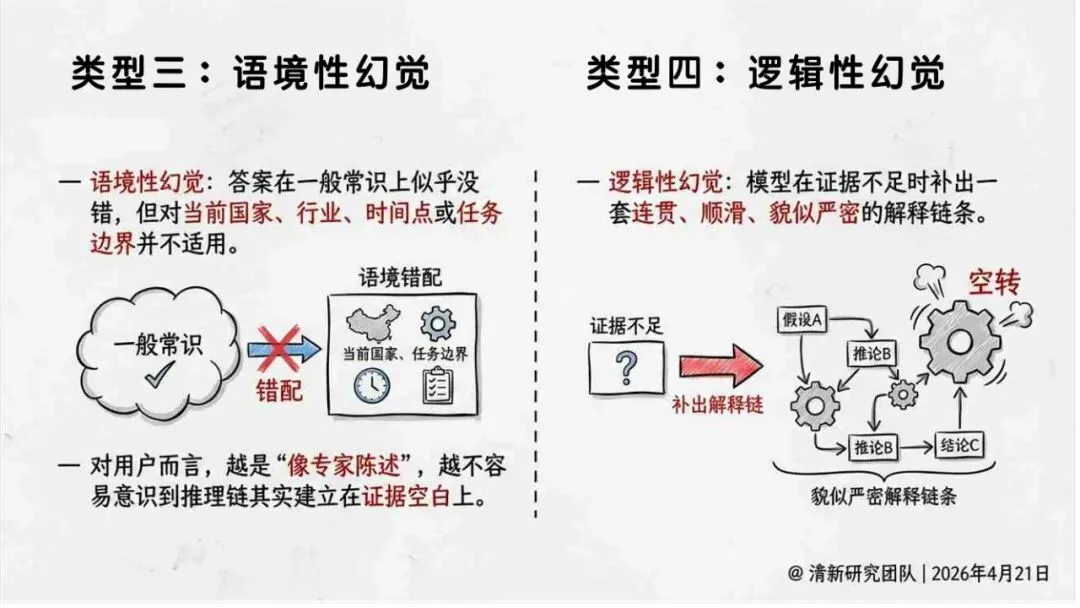
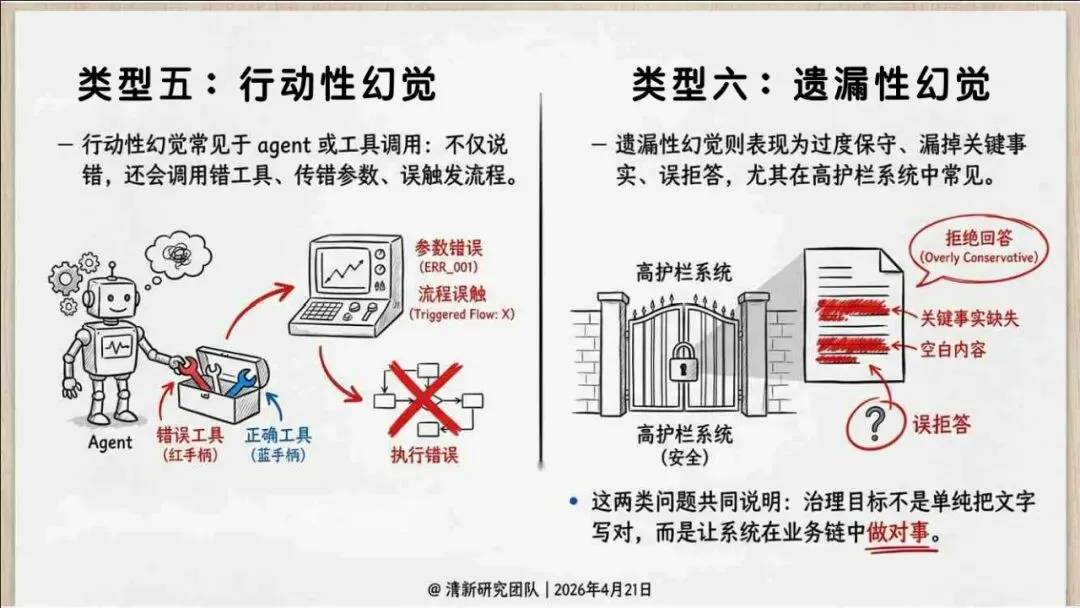
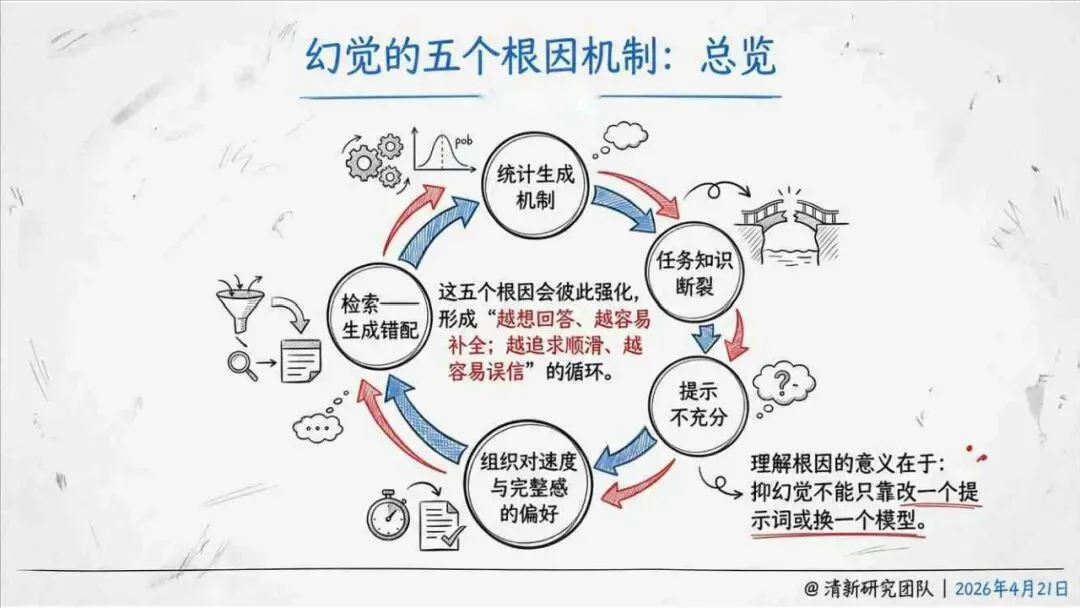
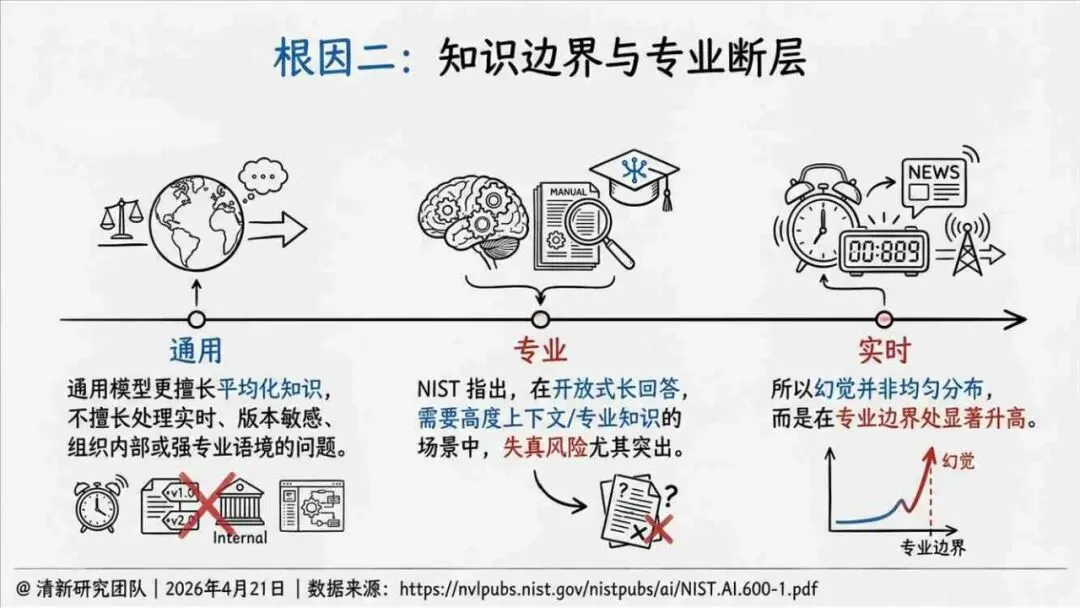
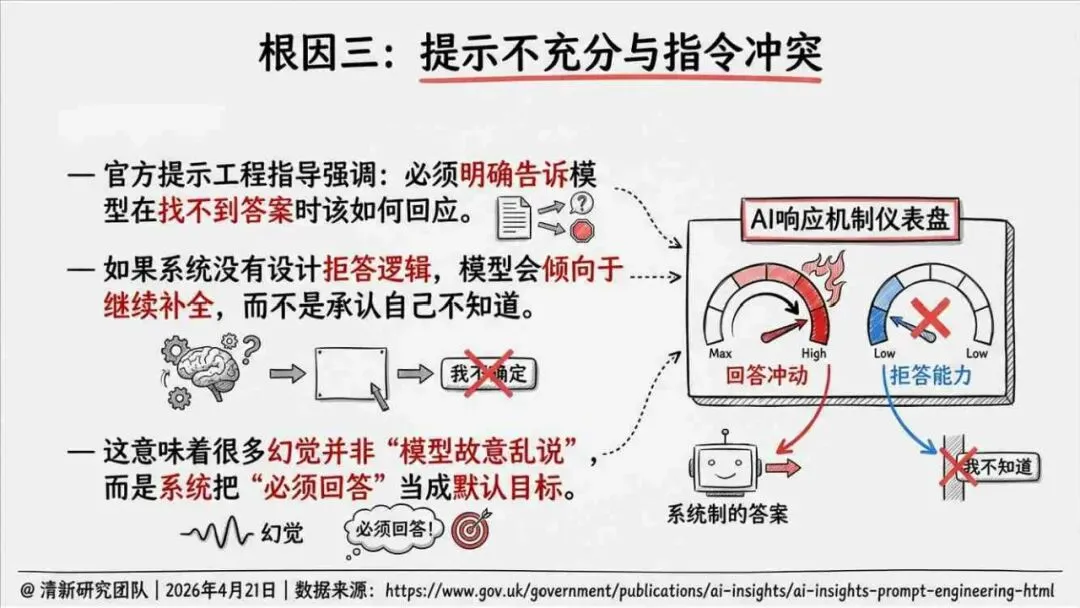
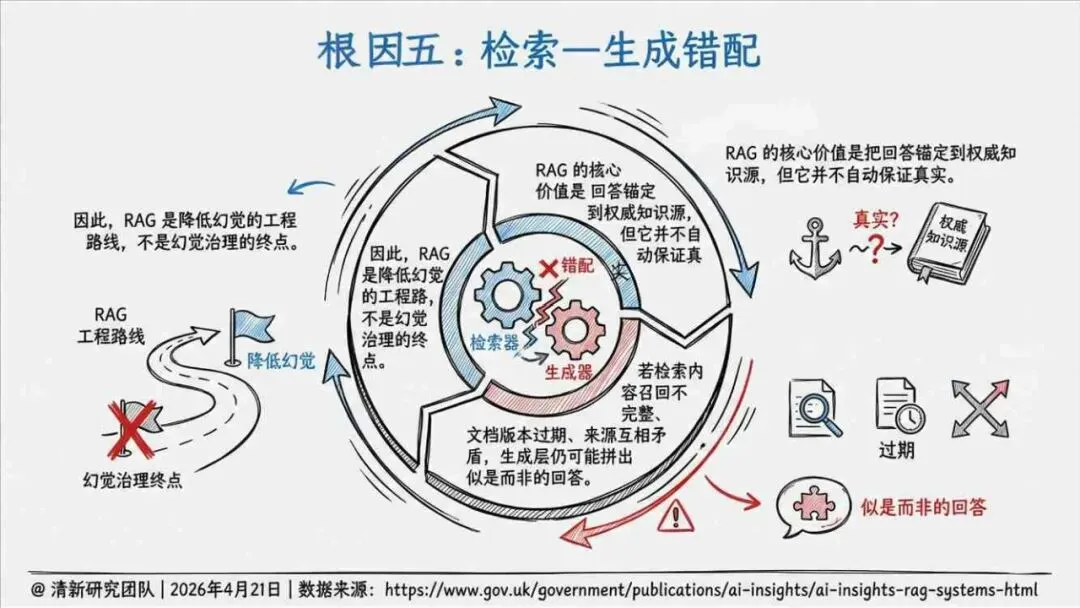
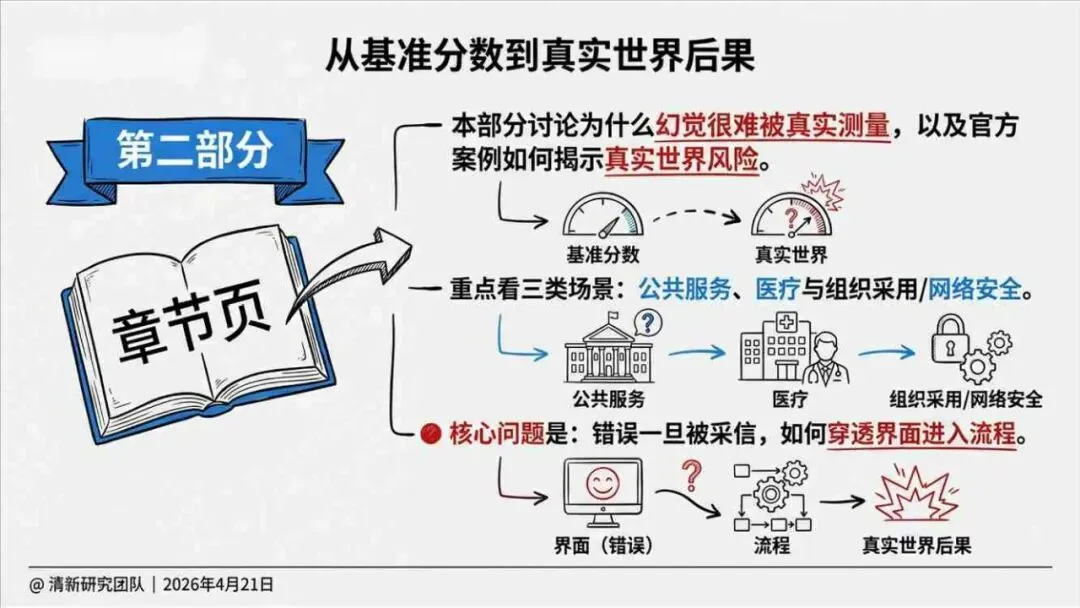
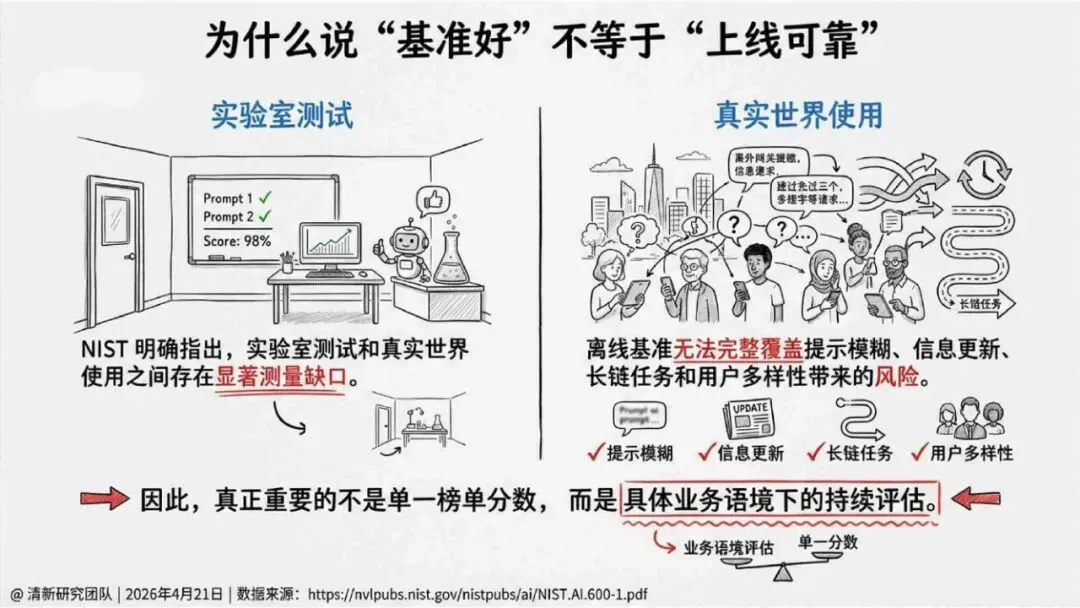
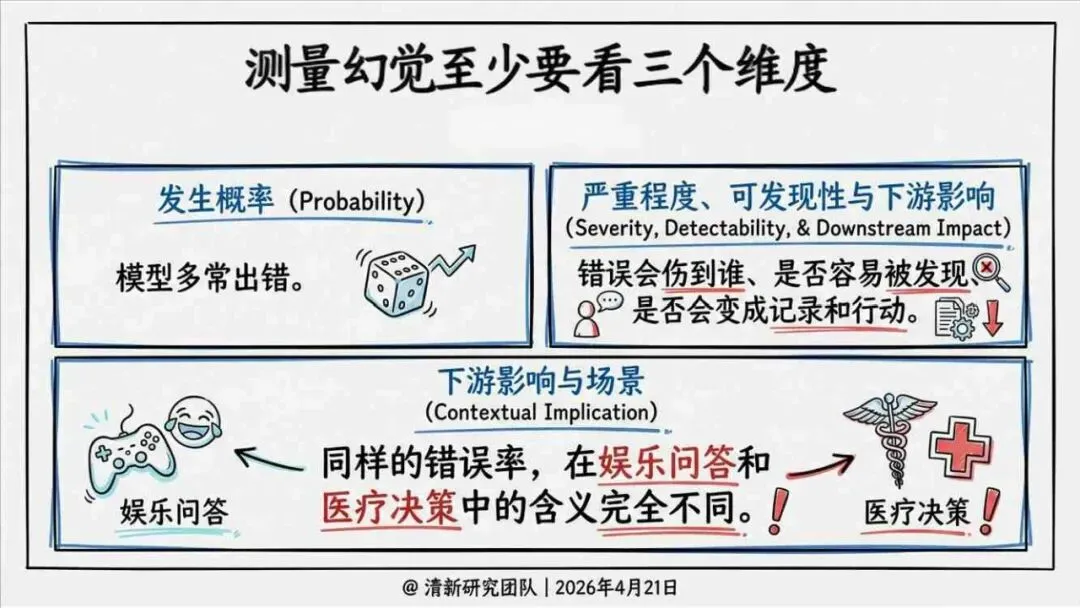
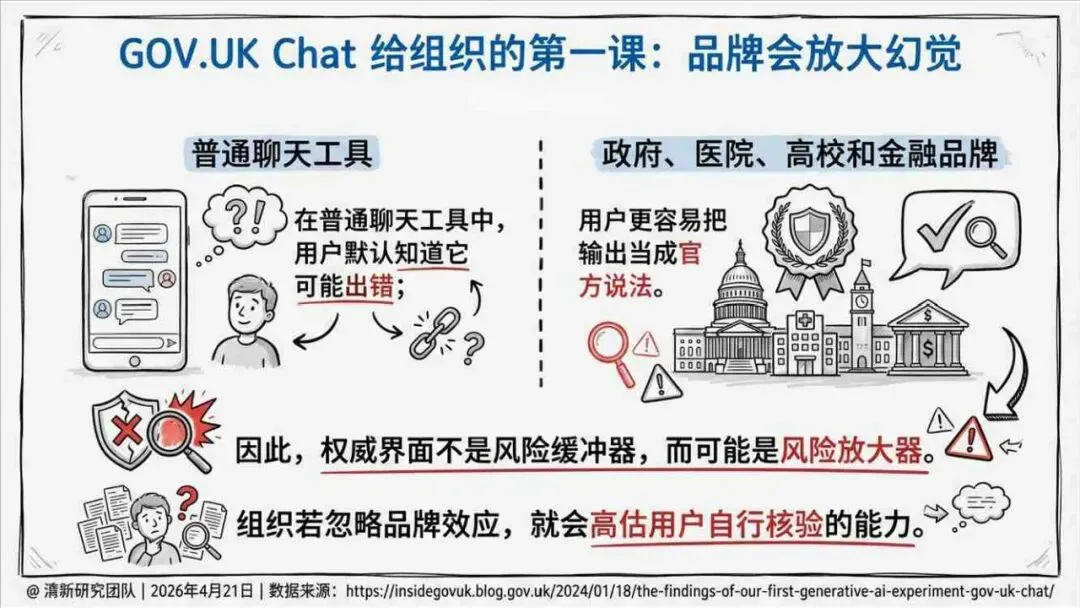
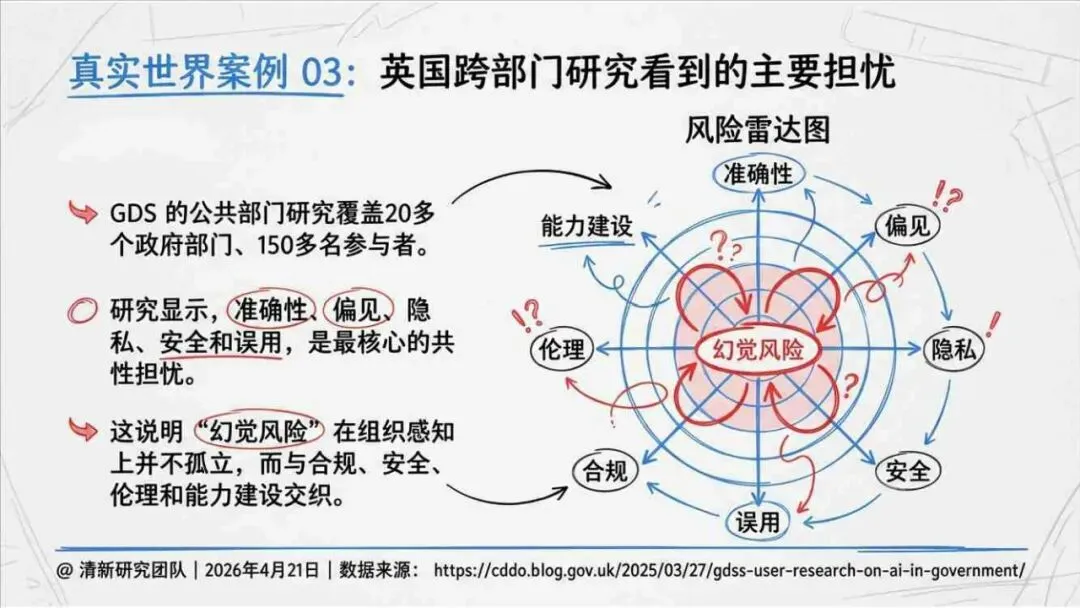
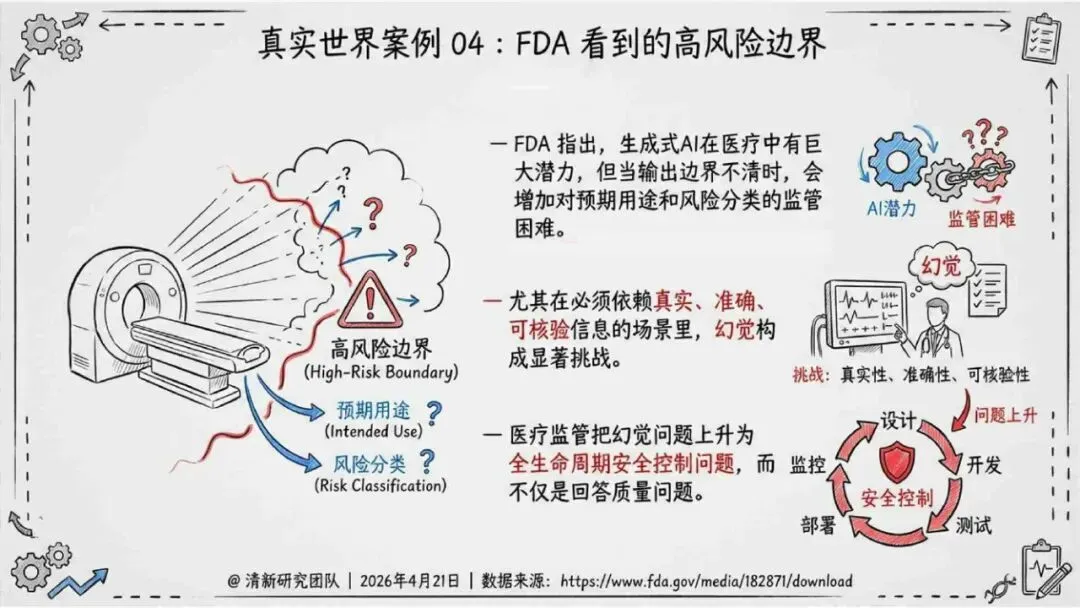
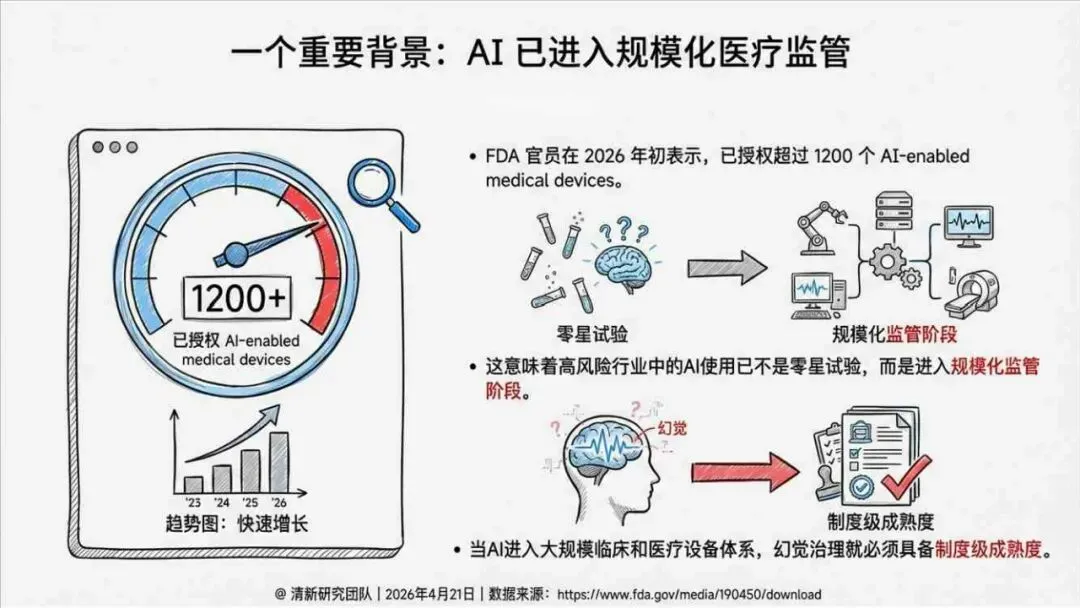
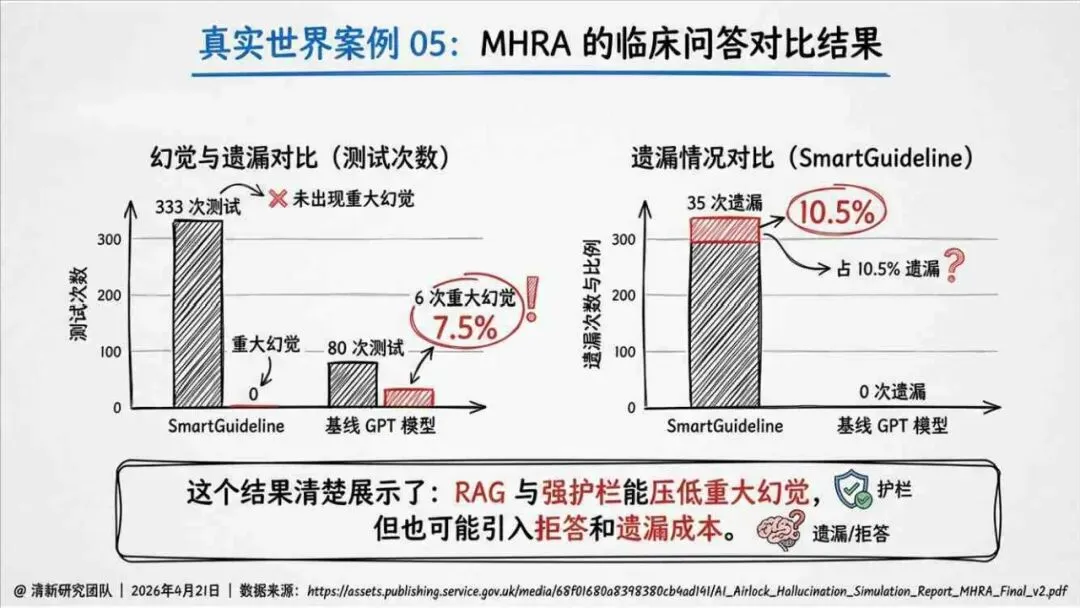
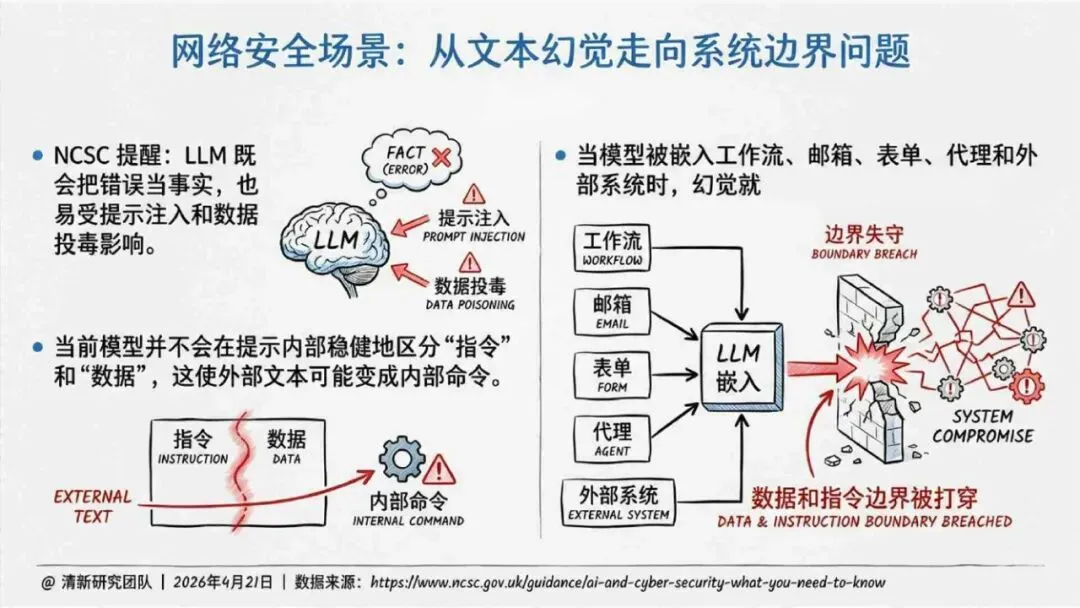
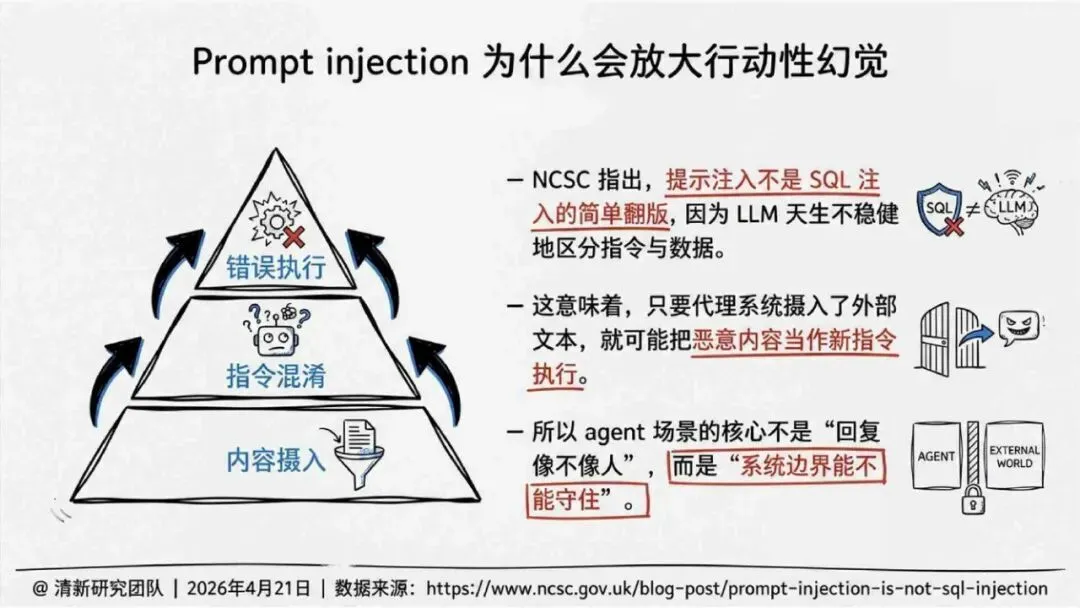
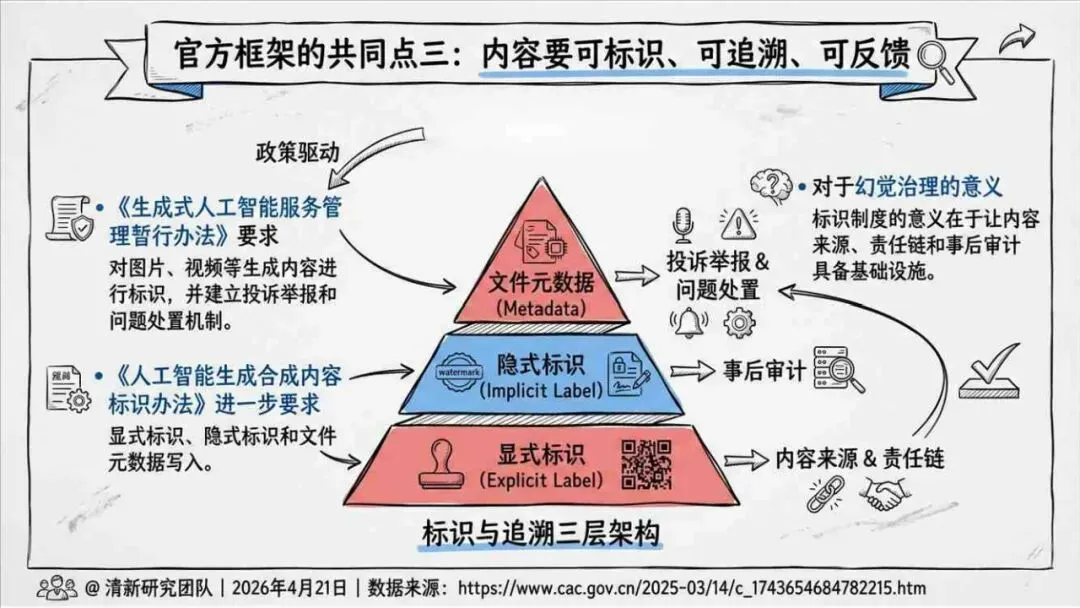
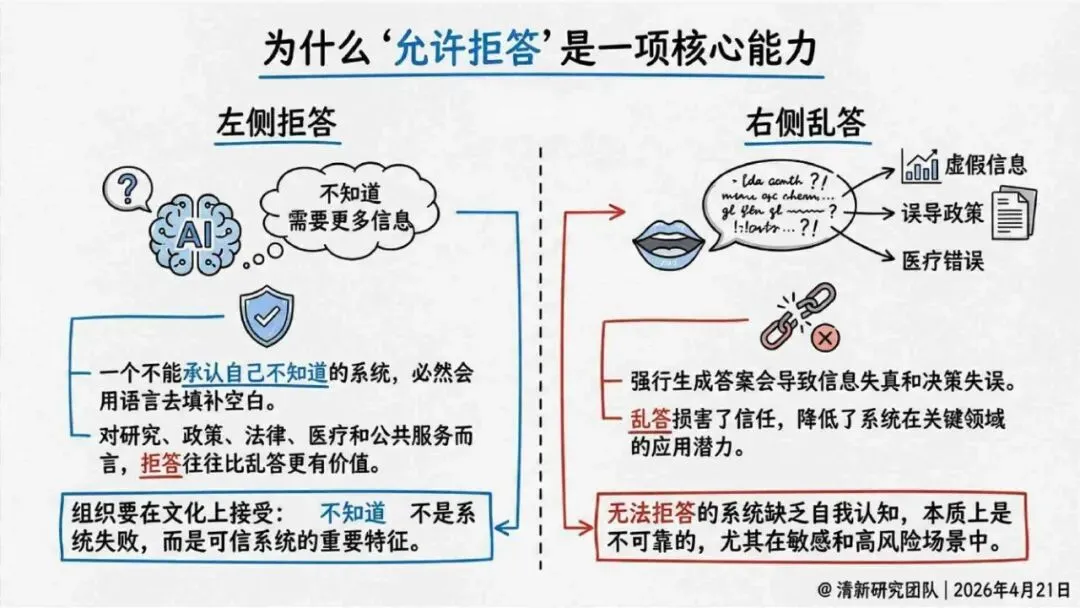
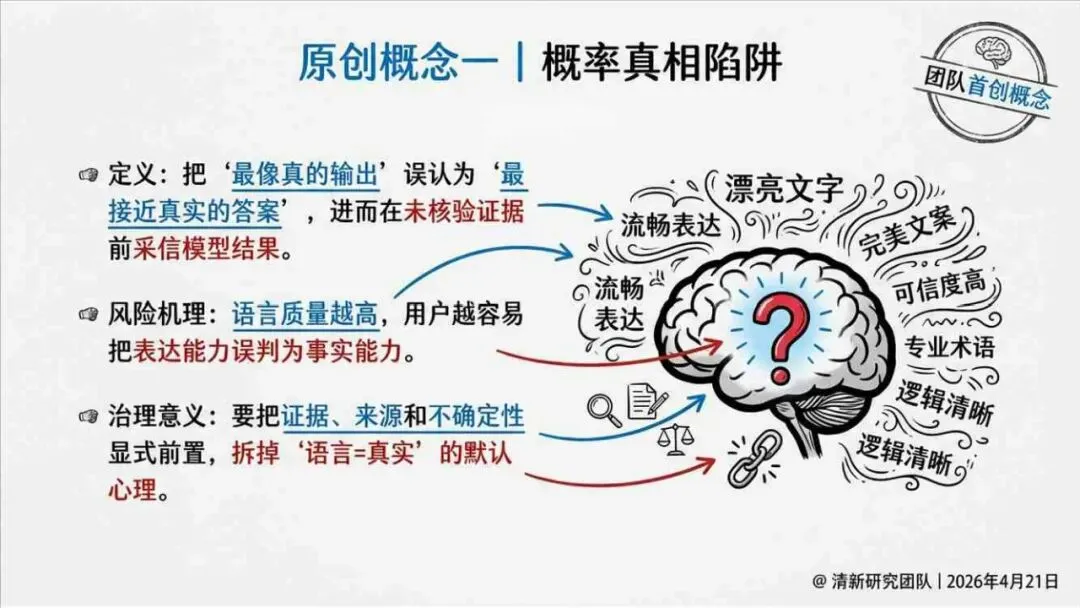
报告明确划分出真相/事实性、逻辑性、引用性、行动性、语境性、遗漏性六类幻觉;根源可归纳为统计生成偏好、知识断层、指令不足、组织偏好速度、检索—生成错配等五大因素。特别在医疗、法律、公共服务等高可信场景,品牌本身的公信力可能反过来放大用户对幻觉的过度信任,让本来不可靠的内容变成“被轻信的内容”。
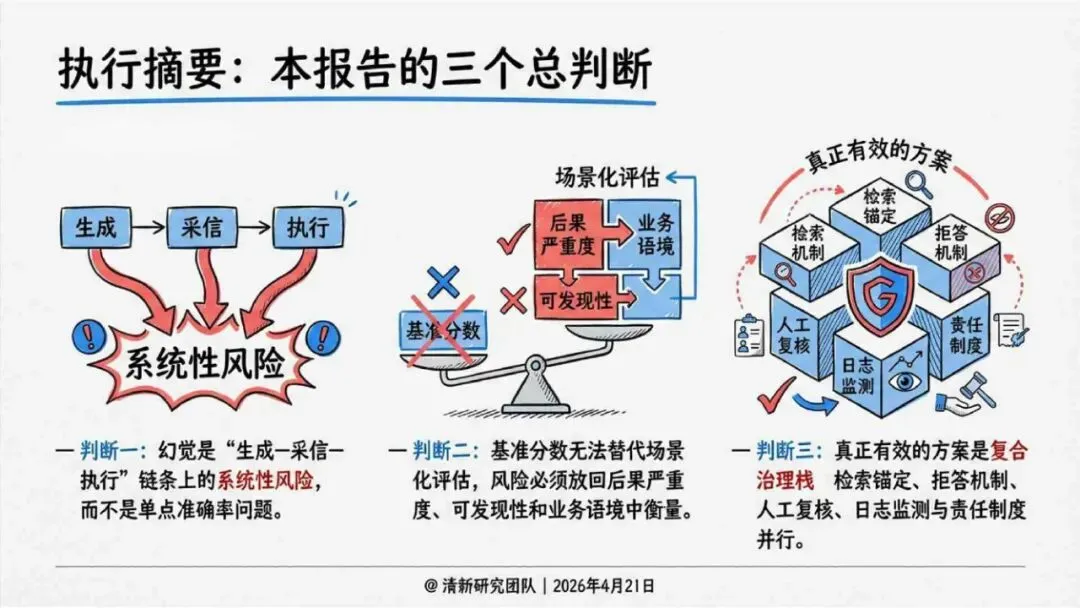
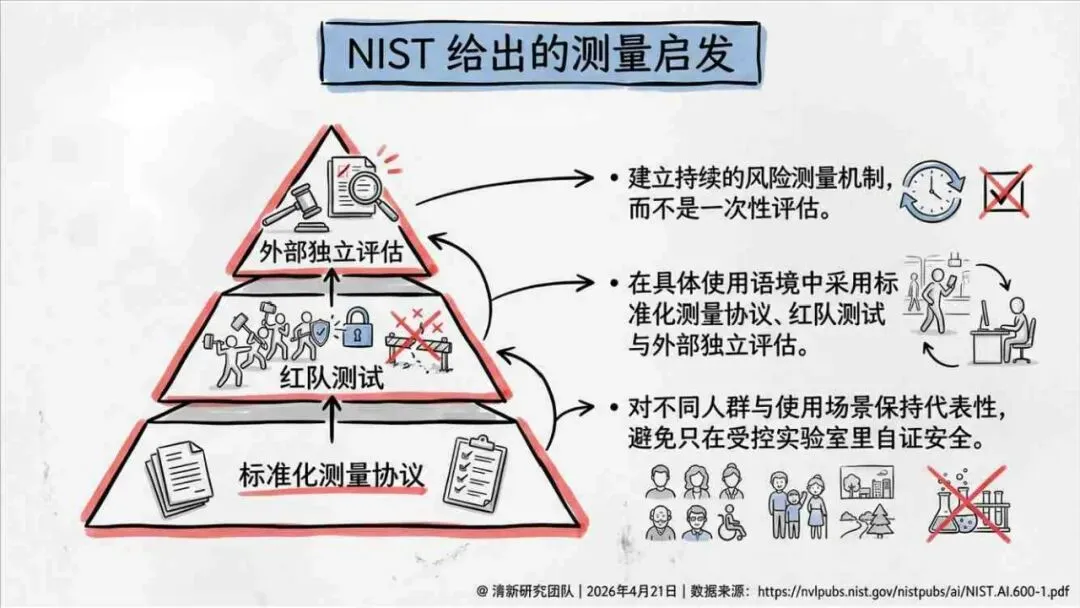
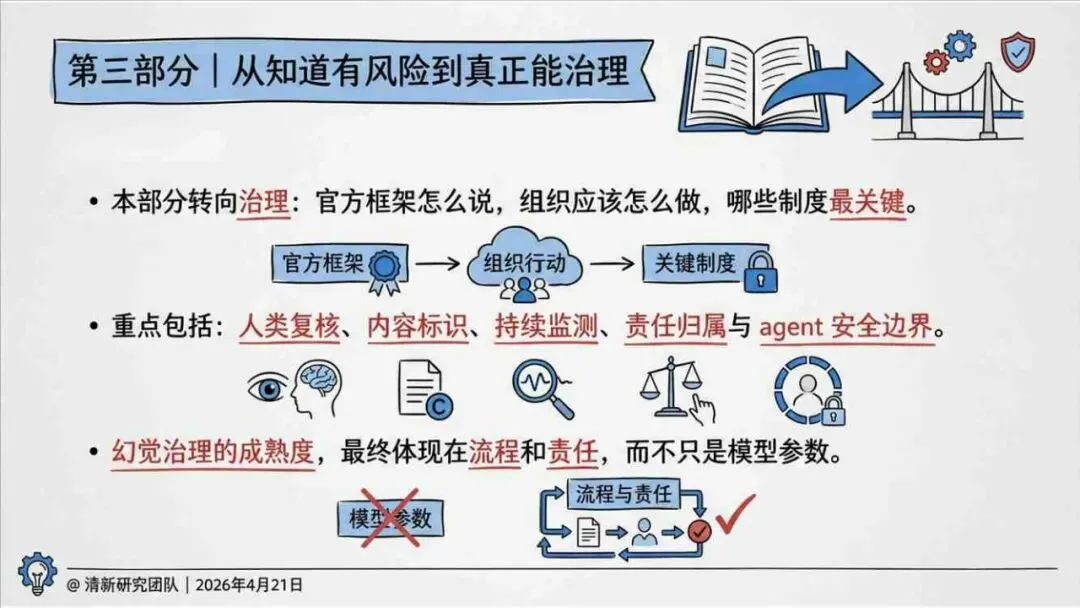
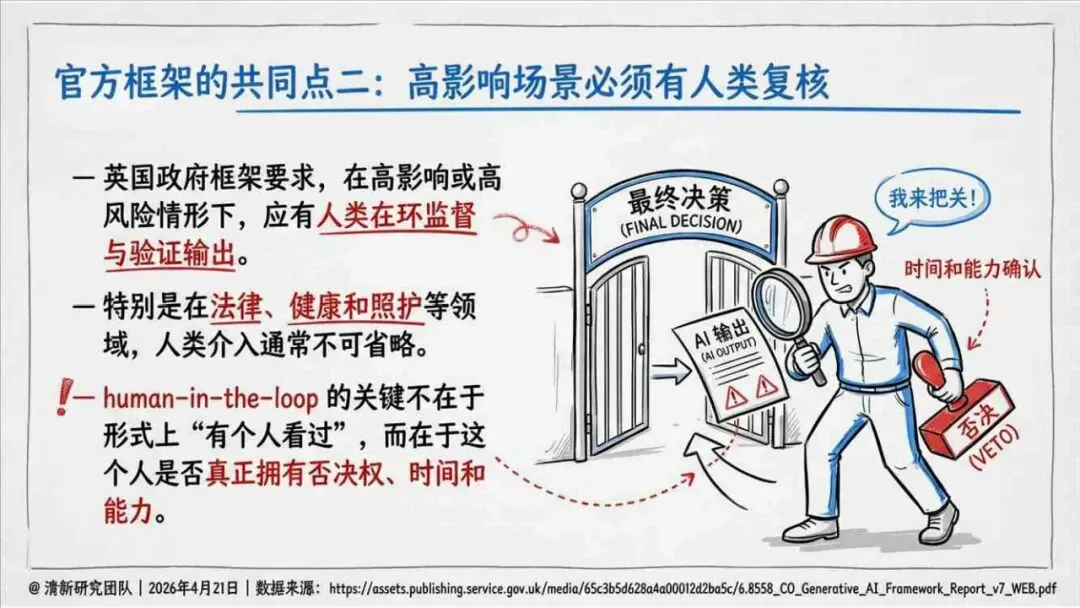
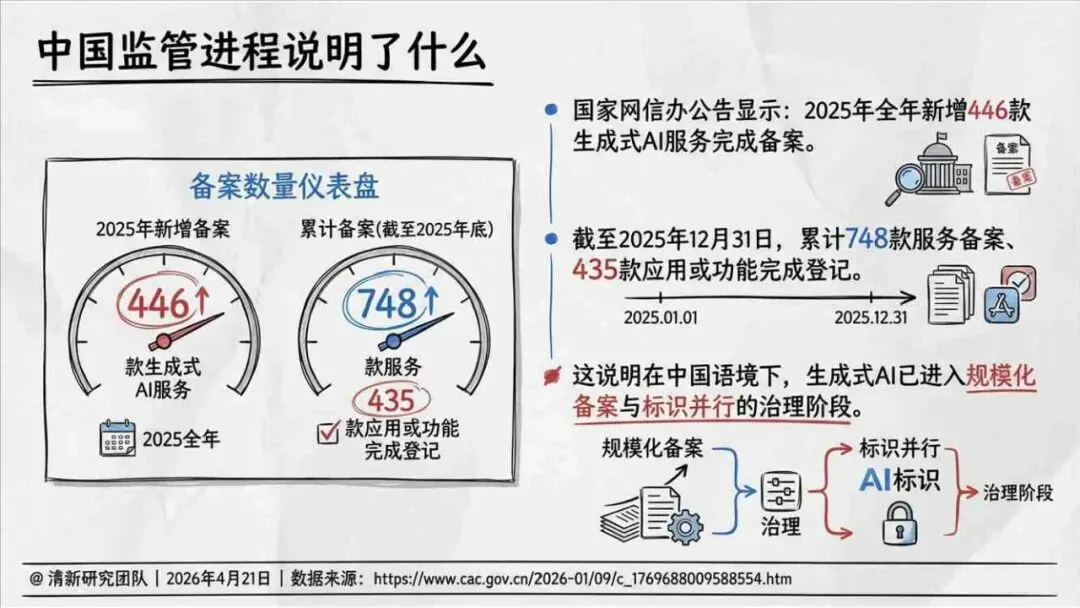
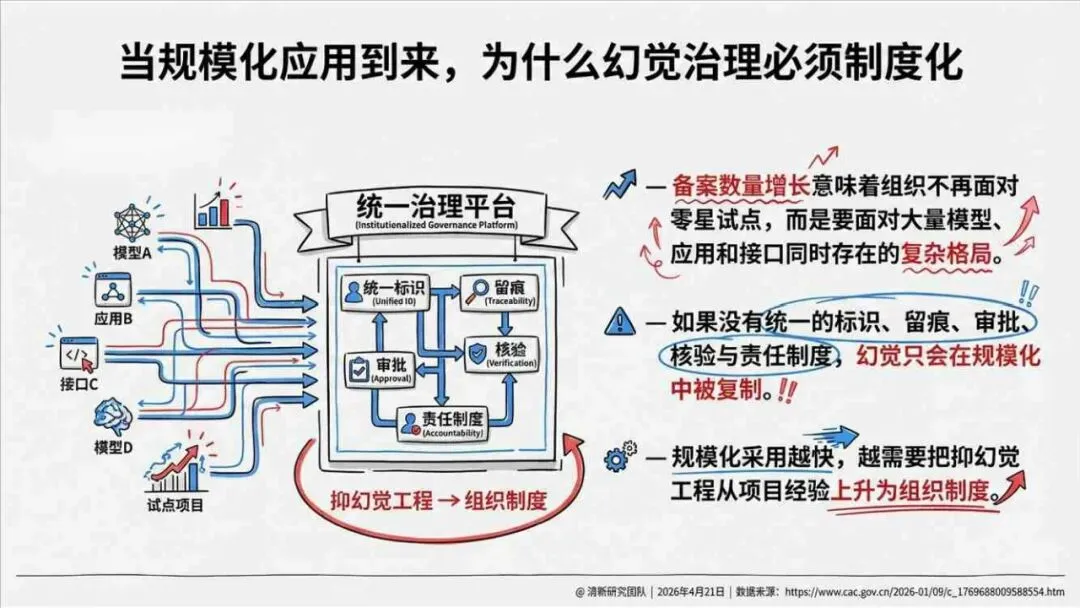
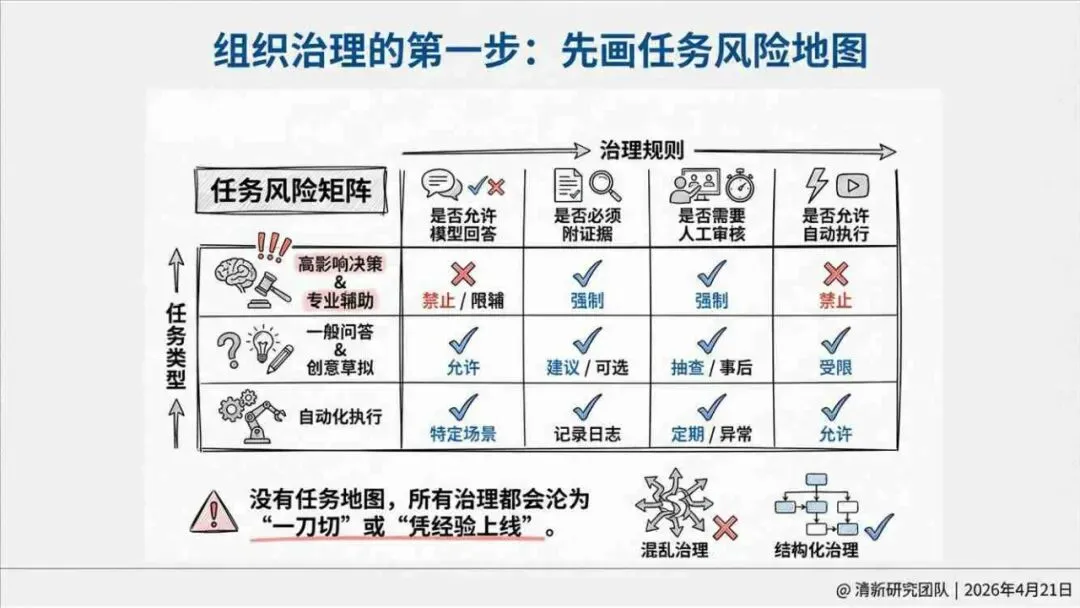
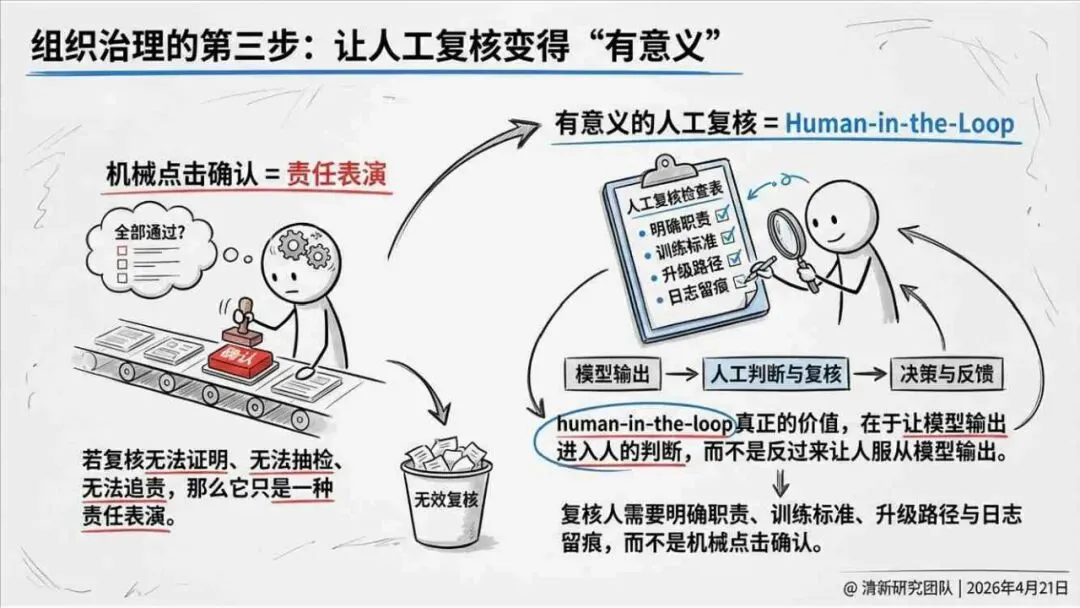
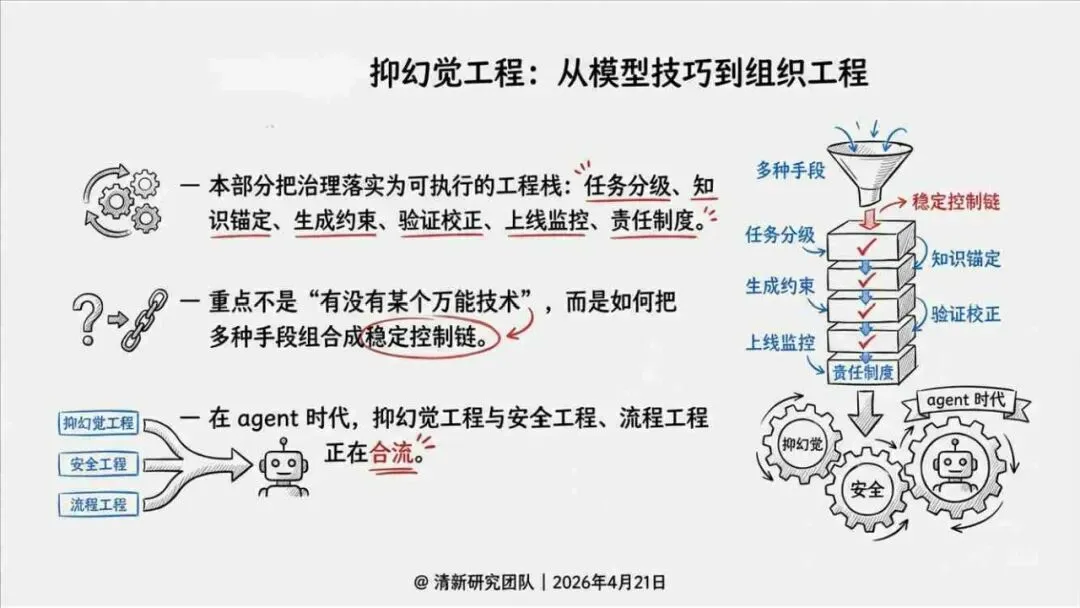
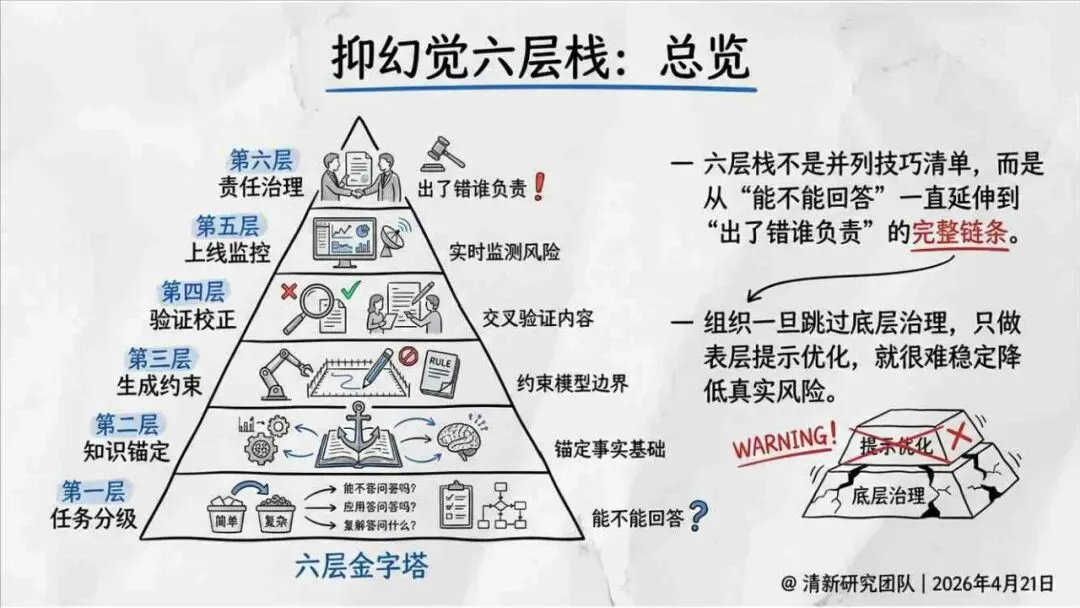
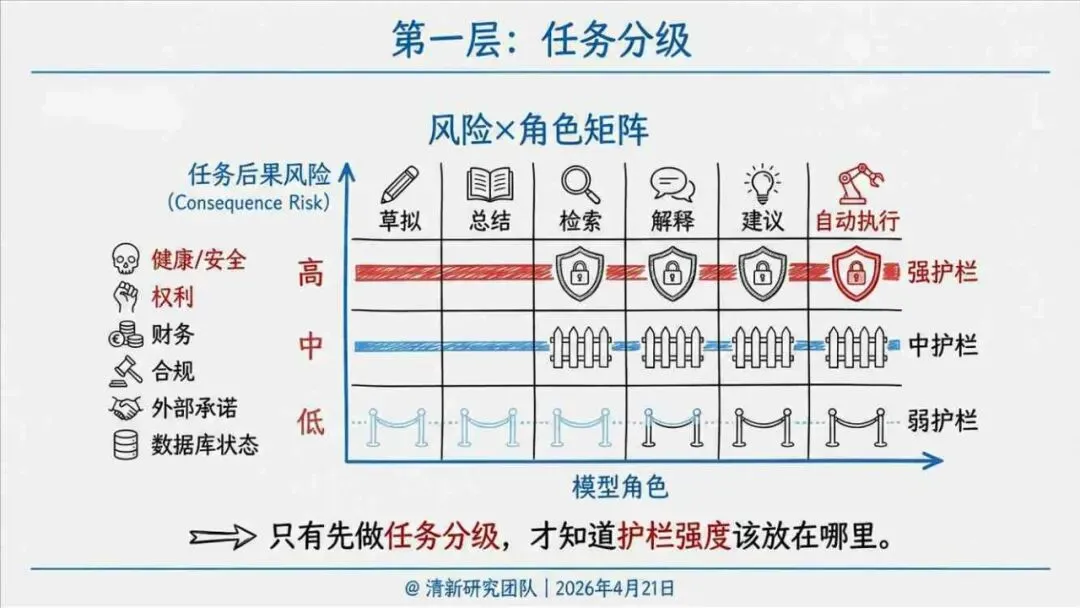
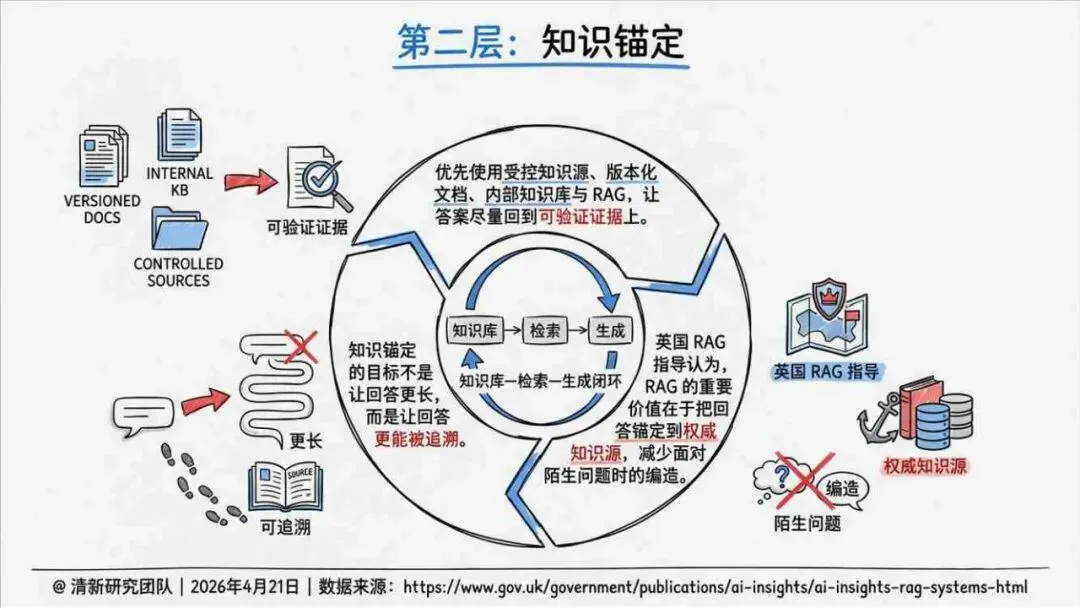
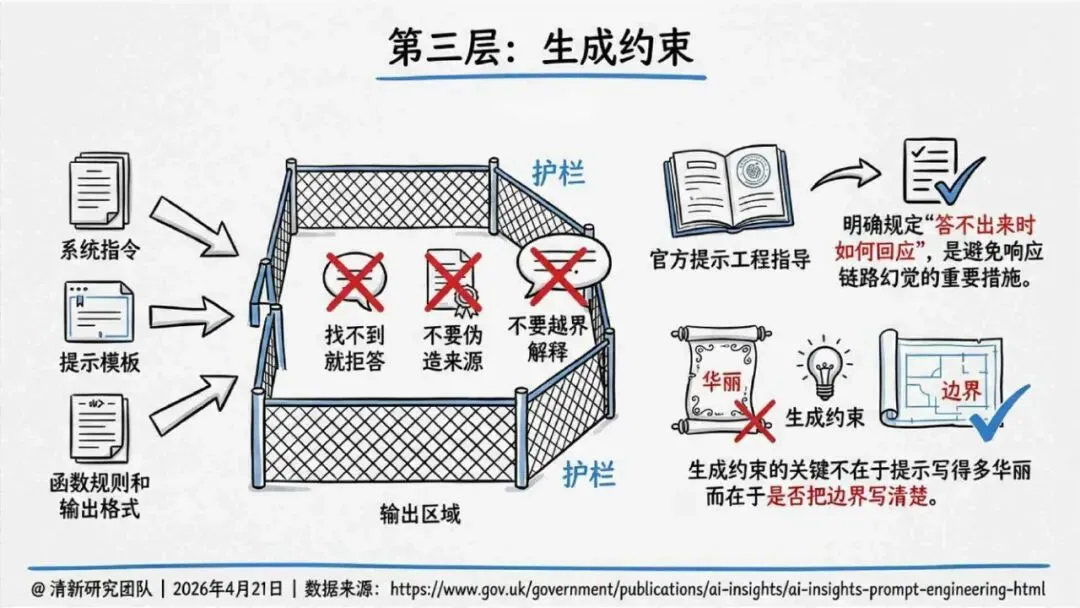
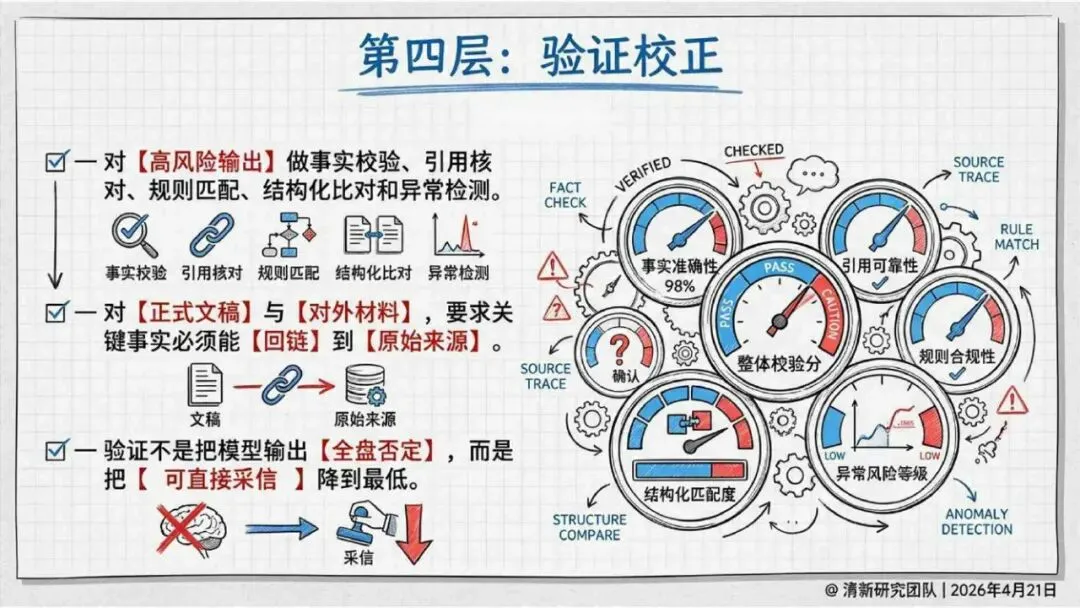
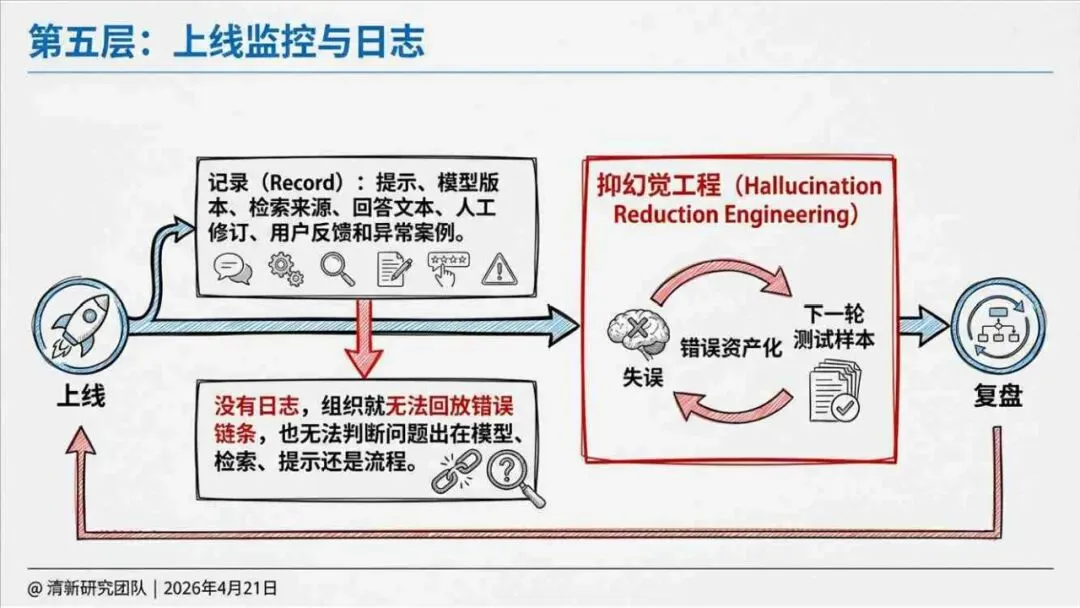
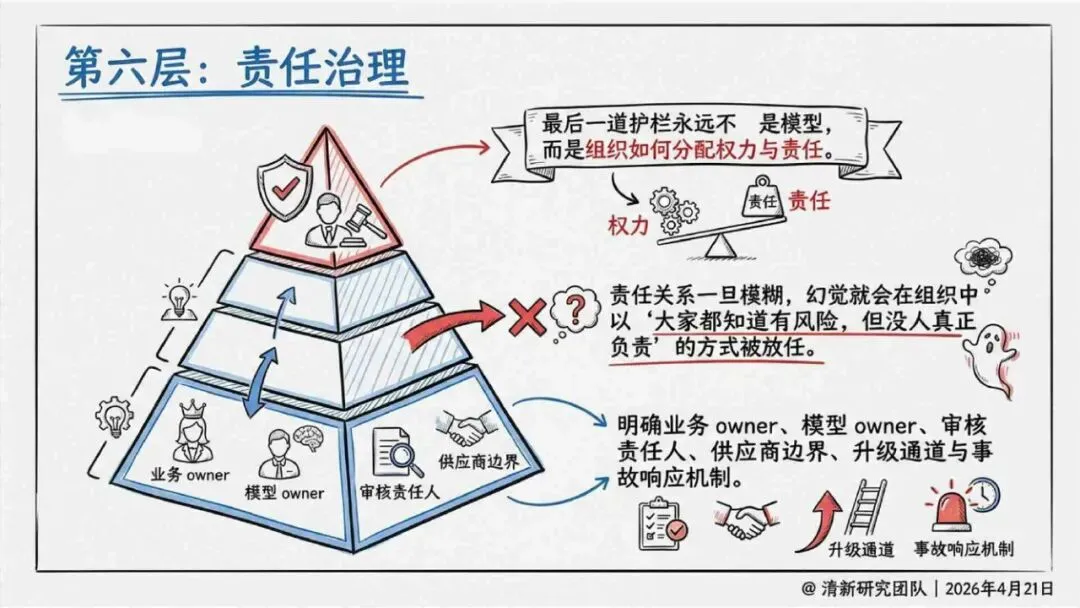
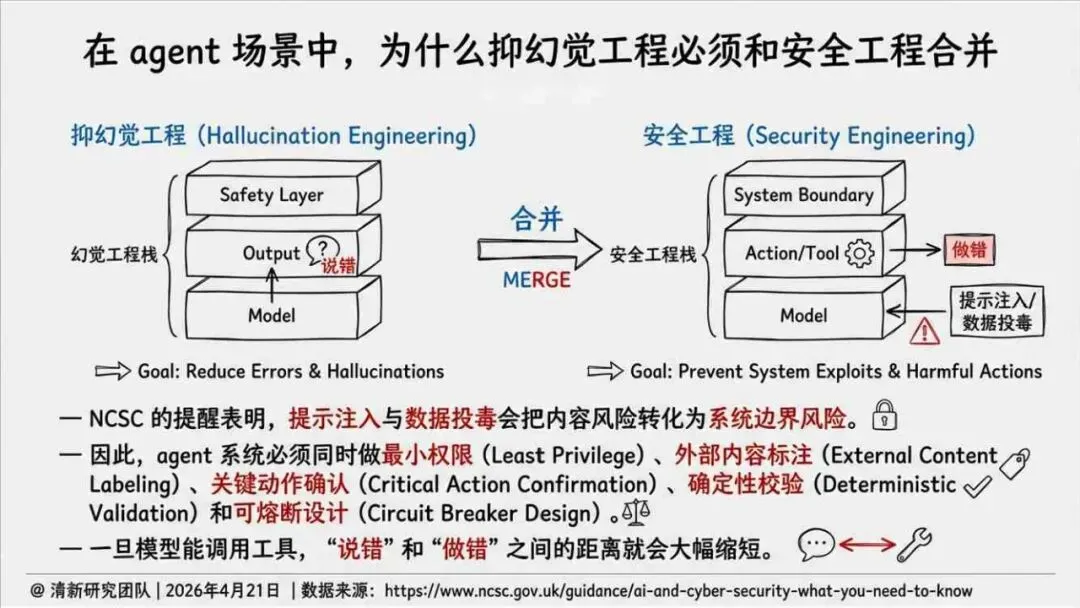
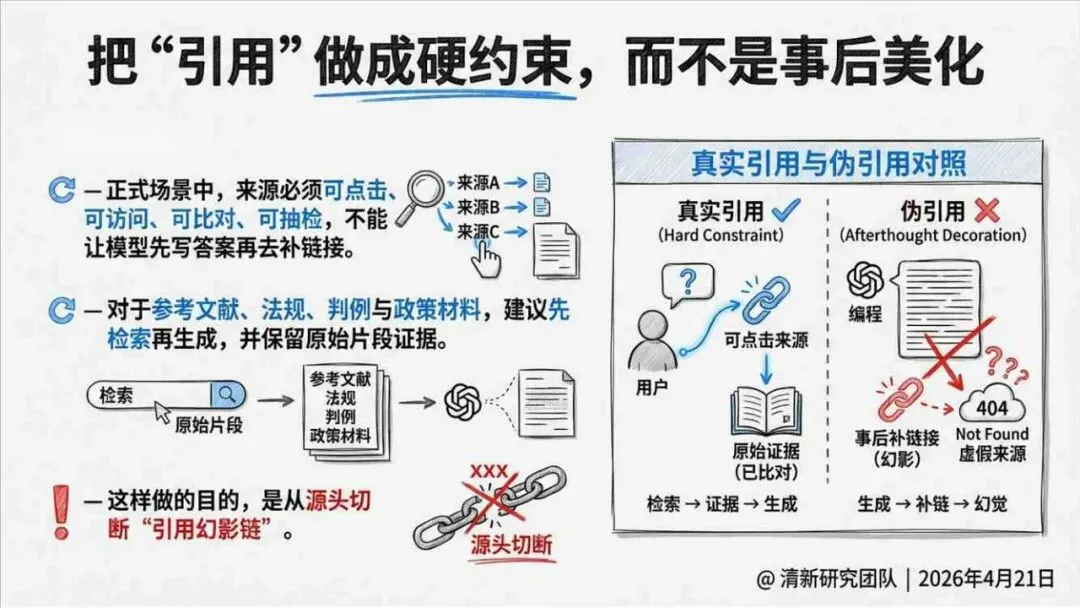
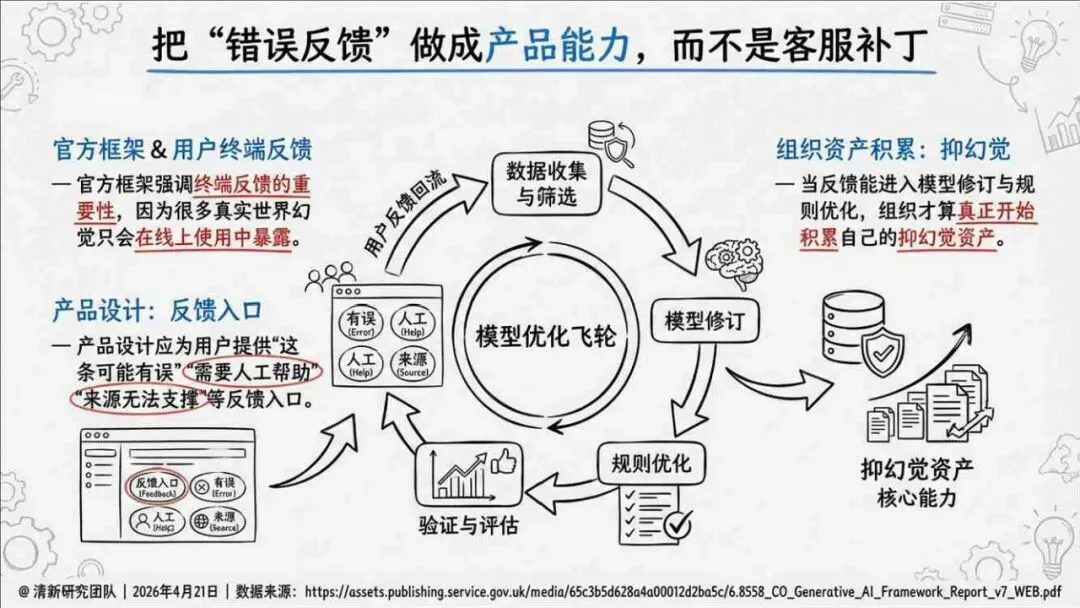
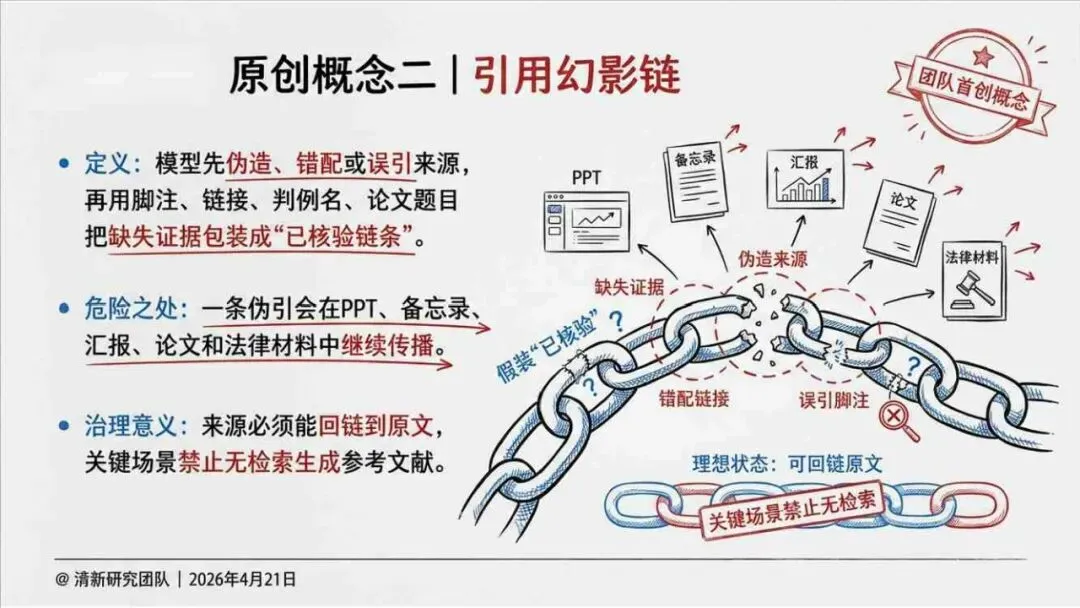
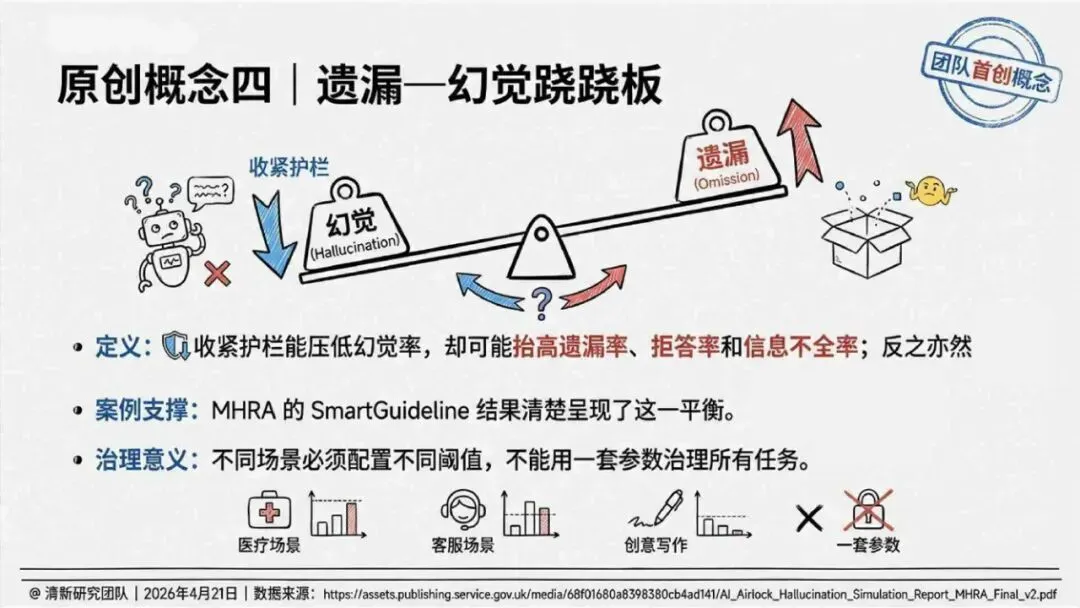
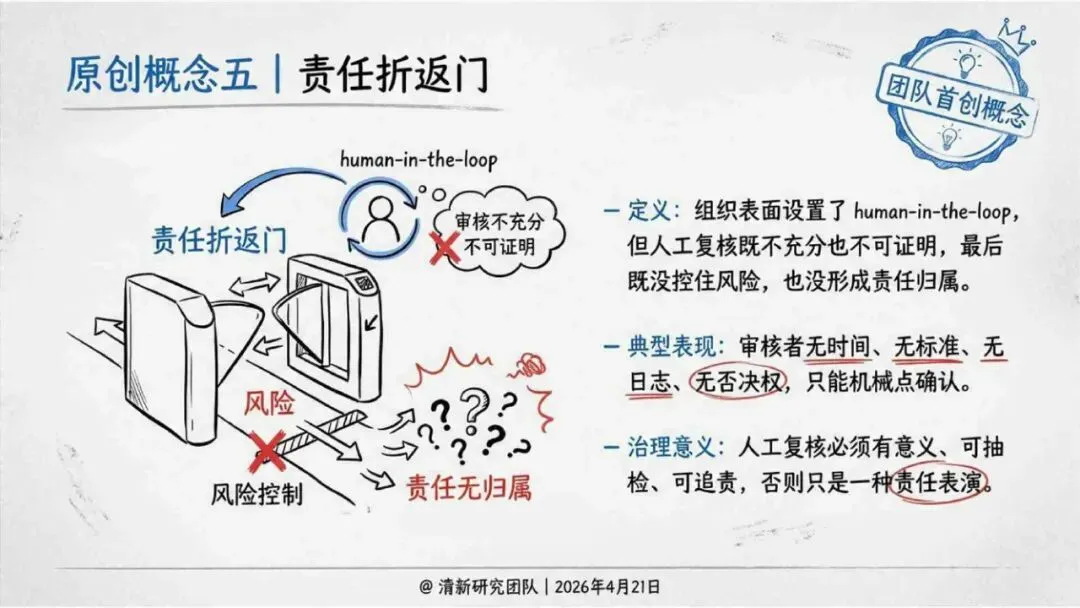
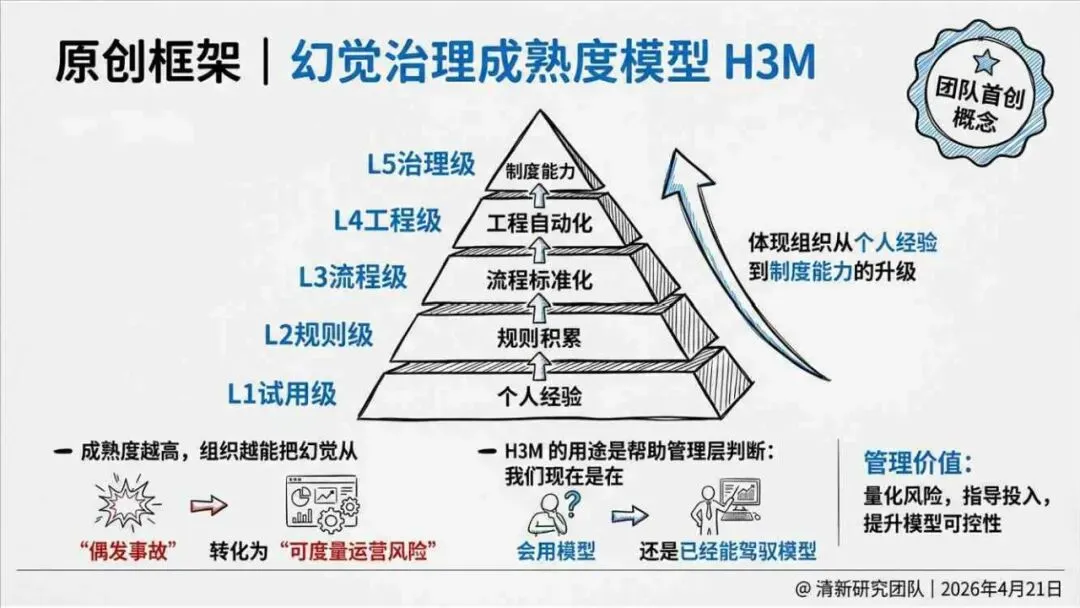
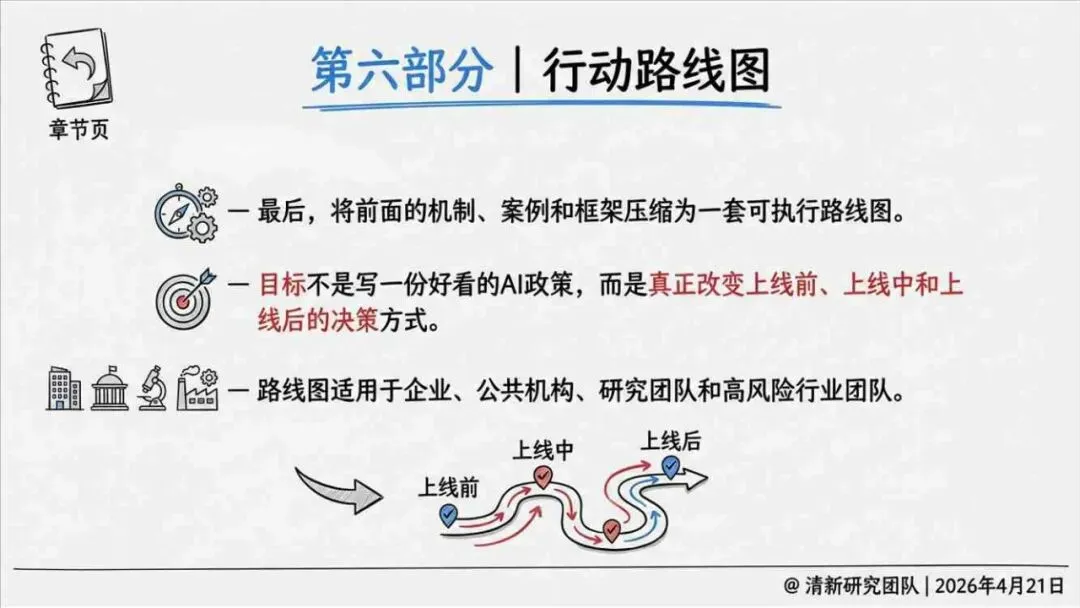
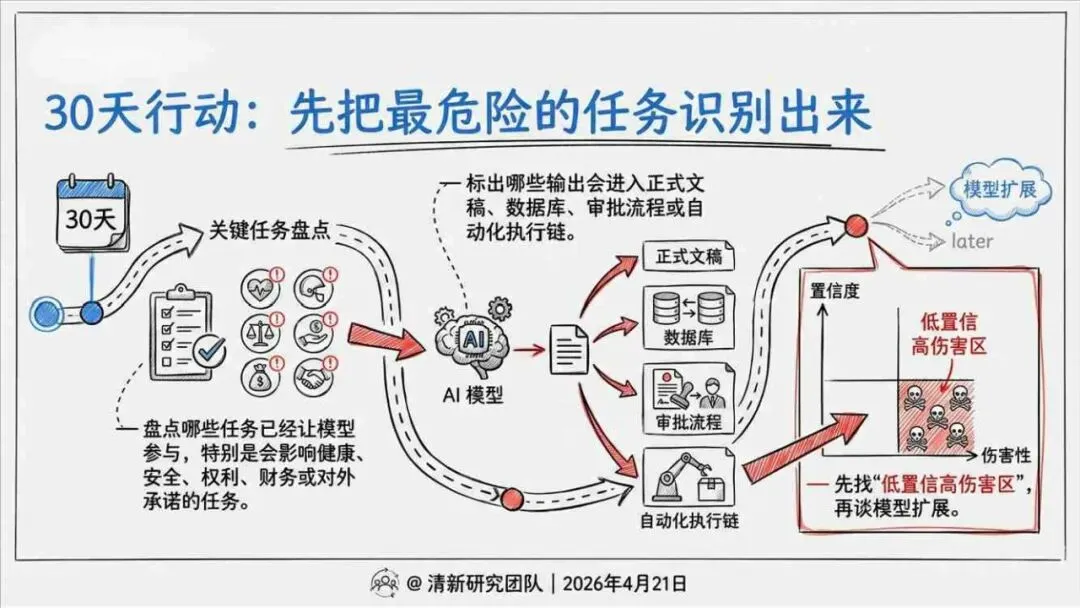
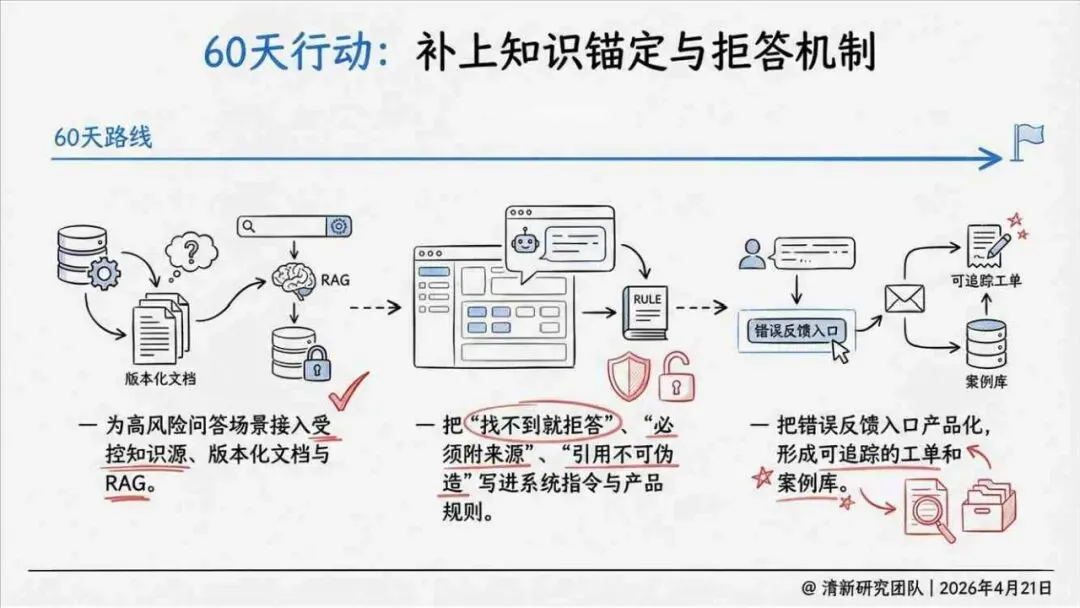
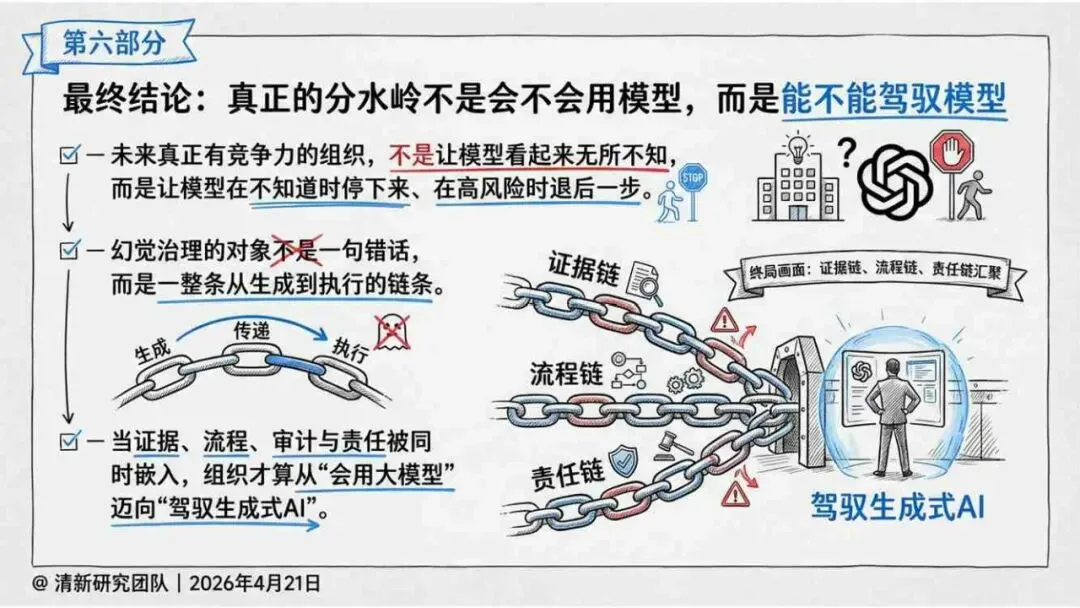
治理层面,报告提出的方向是承认“无法零幻觉”,但组织目标可以转向可识别、可约束、可追责。幻觉治理必须从技术层上移到制度层,建好从任务分级、知识锚定、生成约束、验证校正、上线监控到责任治理的全流程六层栈体系;同时在高风险场景引入人工在环监督、防引用幻影链和真实责任制。
报告为产业提供了一套从“做减法”(避免幻觉)转向“会驾驭”(管理幻觉)的新框架——用制度提升容错能力,而不是用规则硬挡幻觉。以下为报告核心摘要,转给关注AI可靠性的读者参考。
(关注公众号,对话框回复:AI幻觉,获取报告)


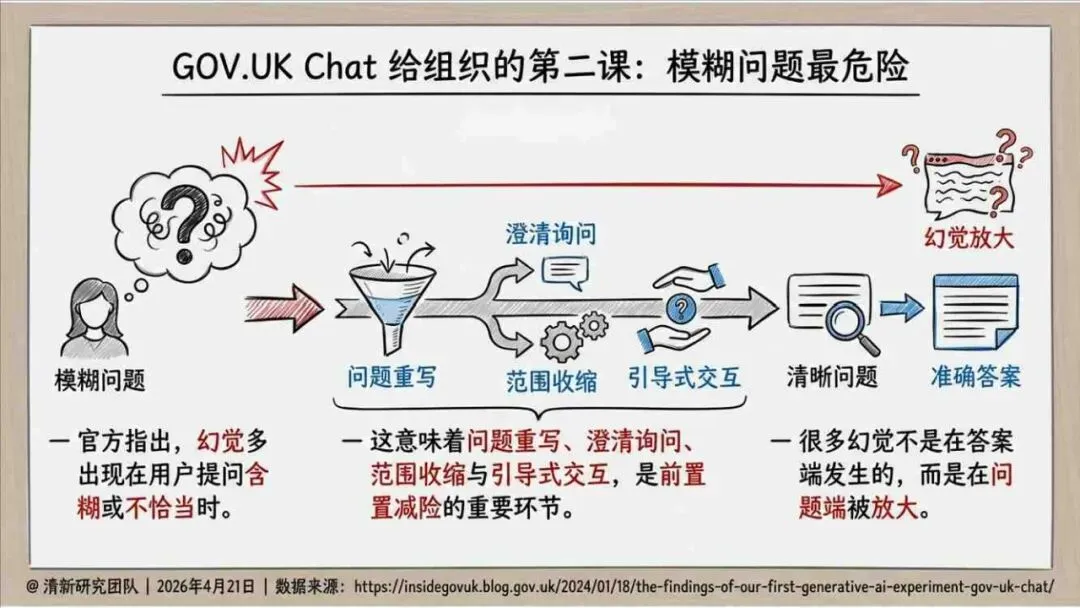
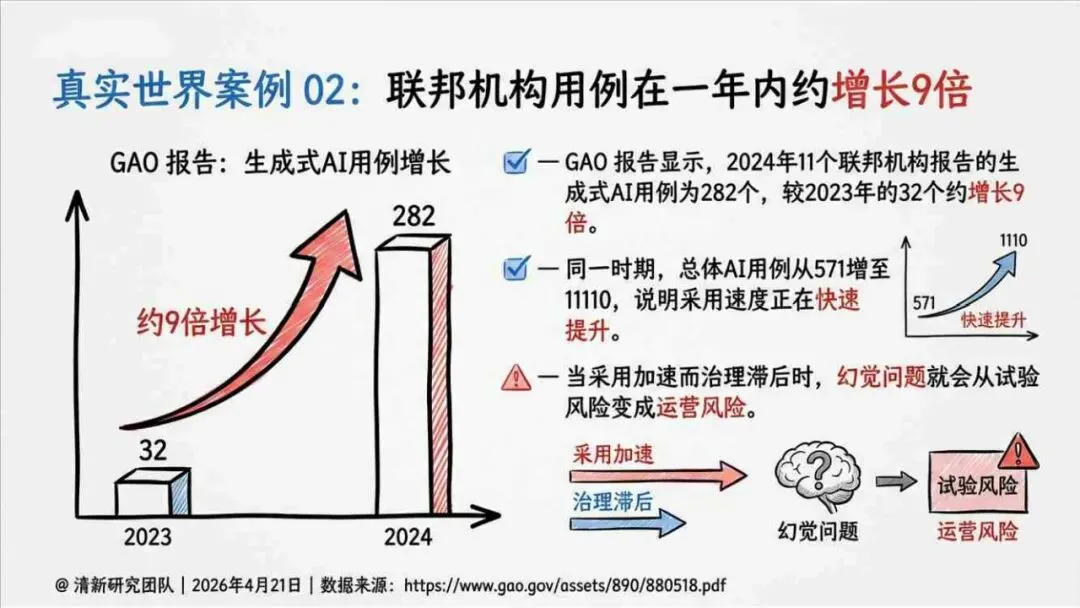
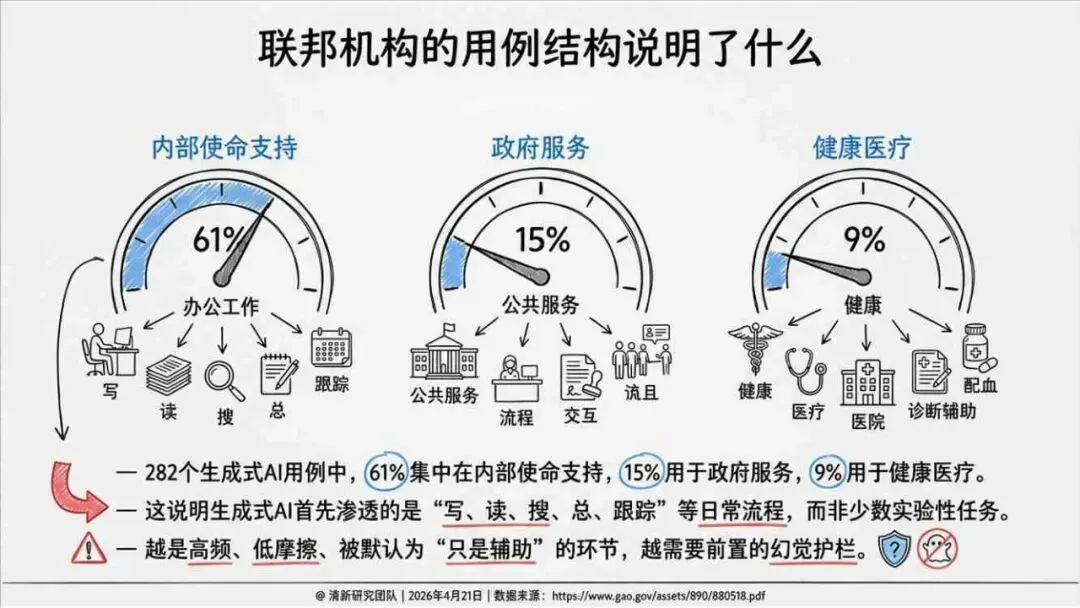
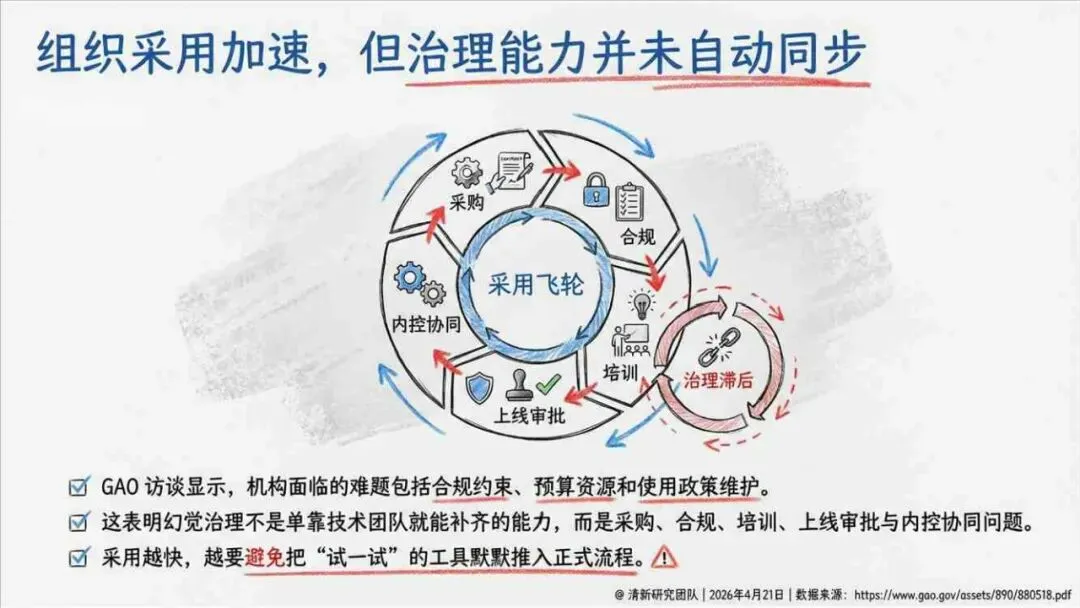



——END——


清华校友总会AI大数据专委会