



来源:清新研究
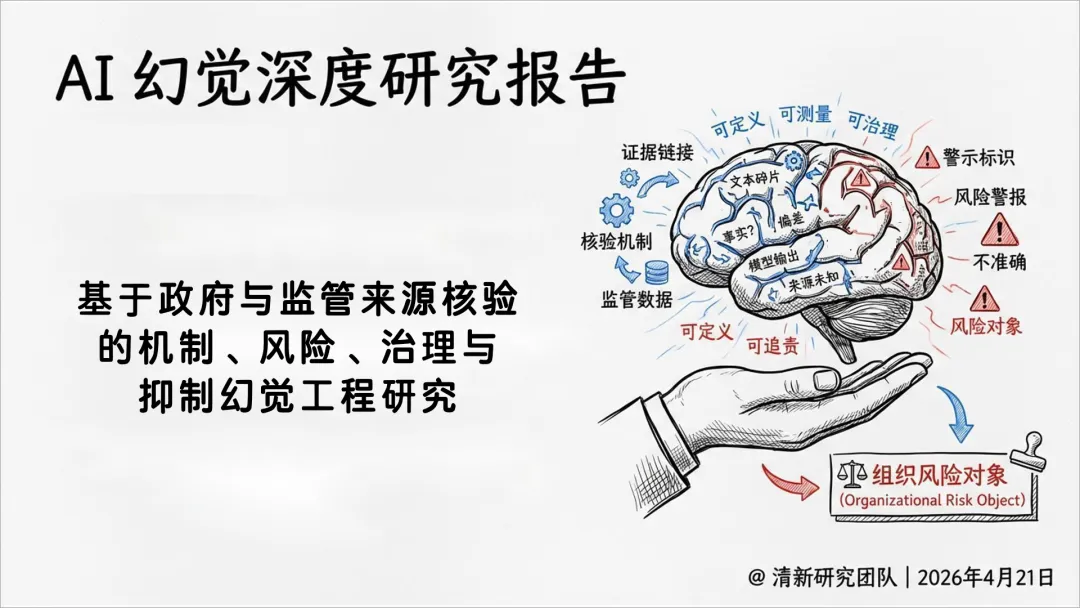
这份《清新研究:2026年AI幻觉深度研究报告》的核心内容概括如下:
? 报告总目标
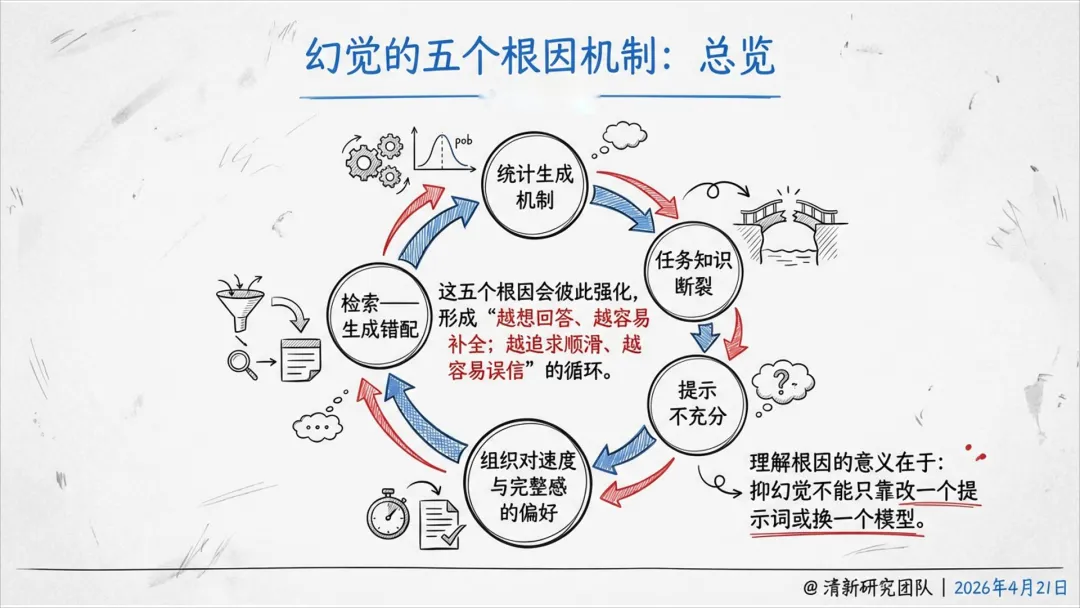
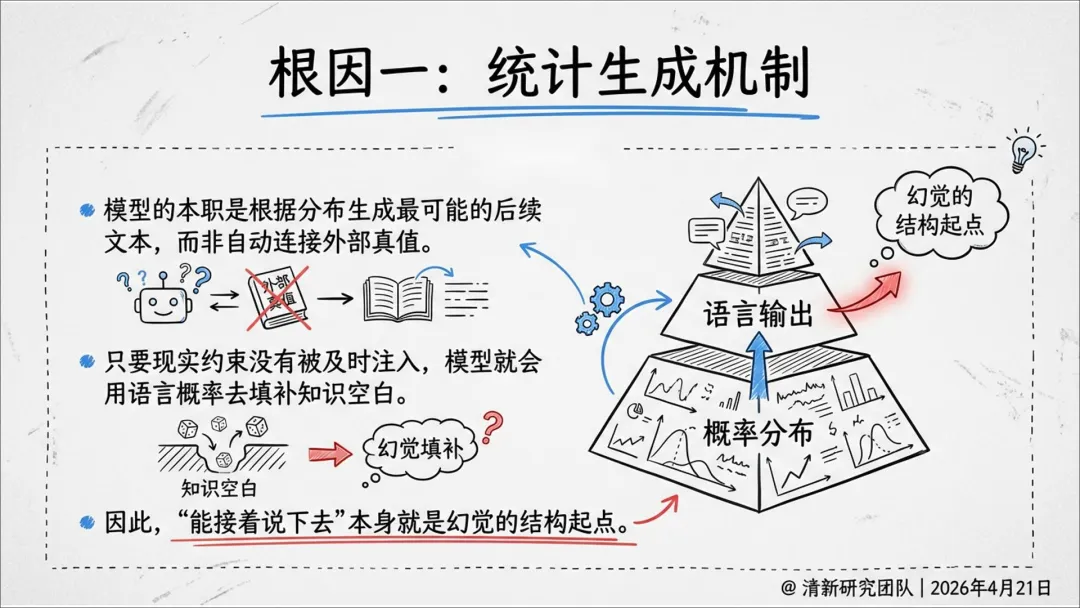
基于NIST、英国政府、FDA、MHRA、NCSC等政府与监管机构的实践,系统分析AI幻觉的机制、风险、治理与抑制工程,强调幻觉不再是单点准确率问题,而是组织级的系统性风险。
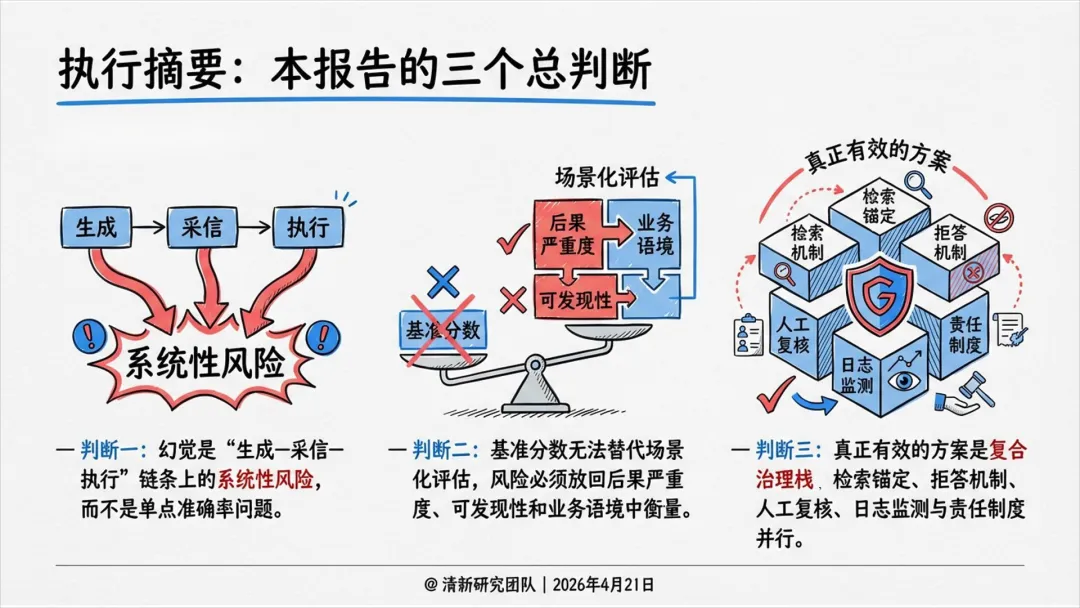
一、三大总判断
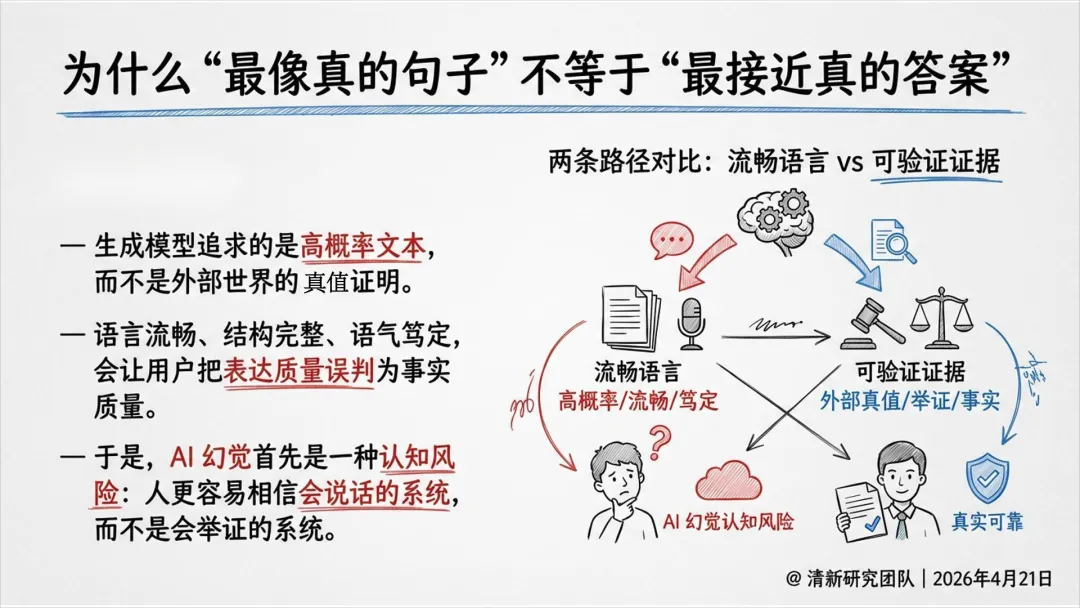
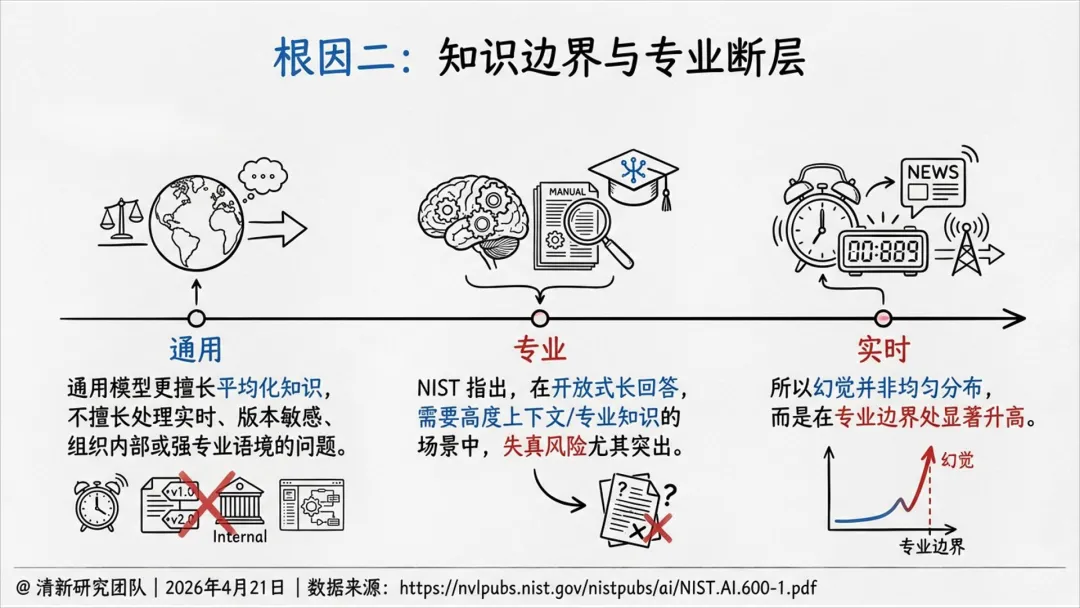
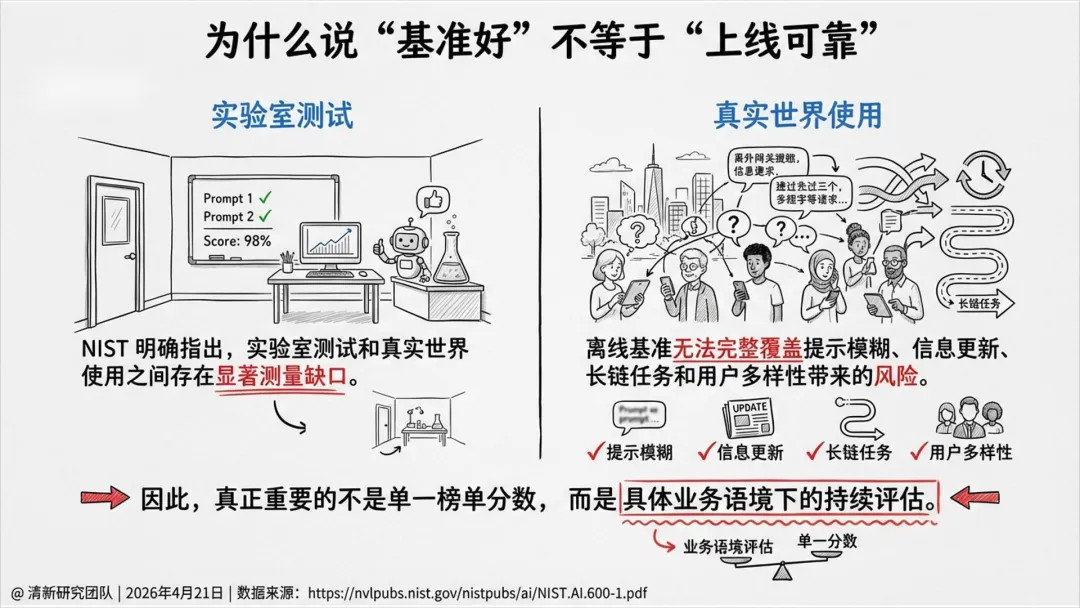
幻觉是“生成—采信—执行”链条上的系统性风险,不是单点准确率问题。
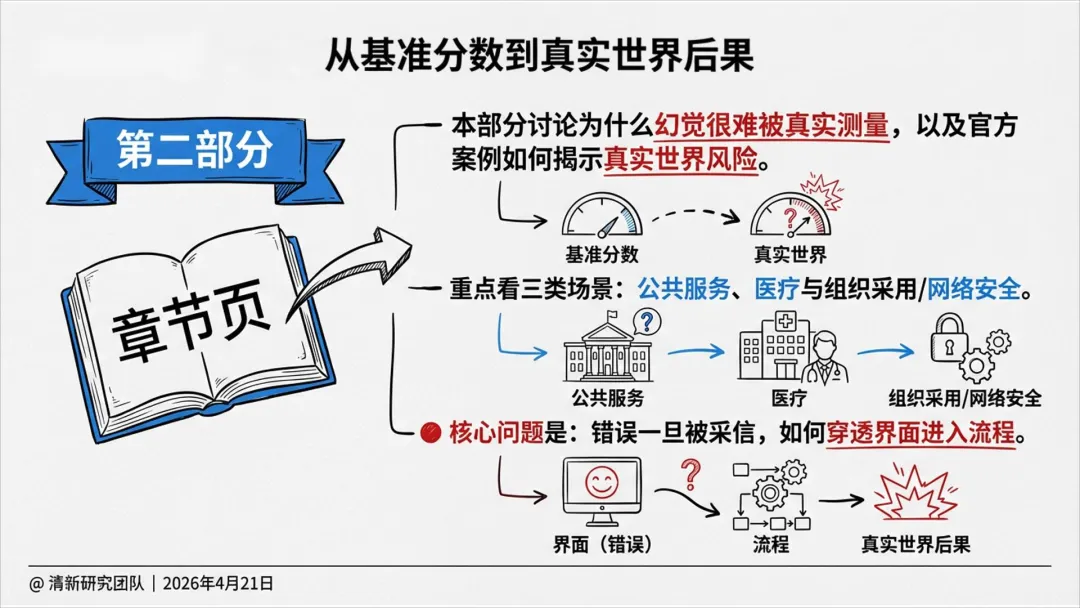
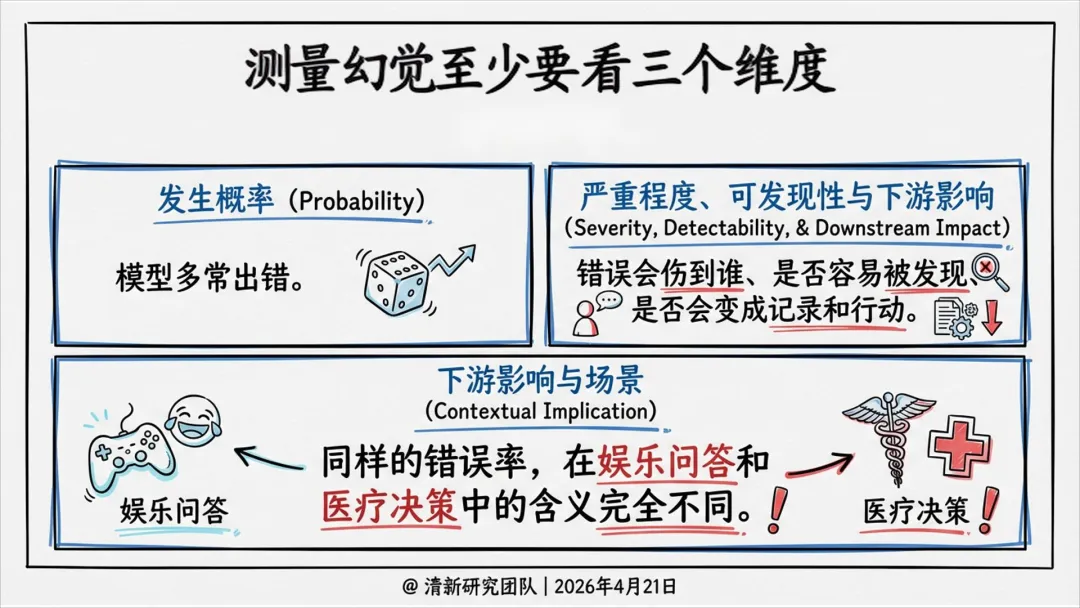
基准分数无法替代场景化评估,必须结合后果严重度、可发现性和业务语境。
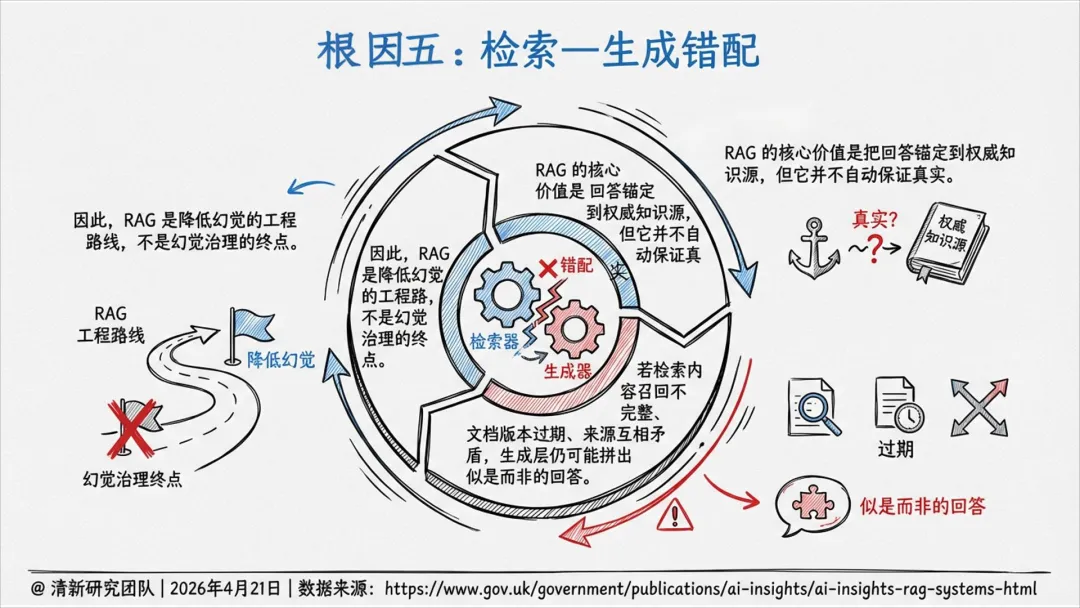
真正有效的方案是复合治理栈:检索锚定 + 拒答机制 + 人工复核 + 日志监测 + 责任制度。
二、核心结论速览
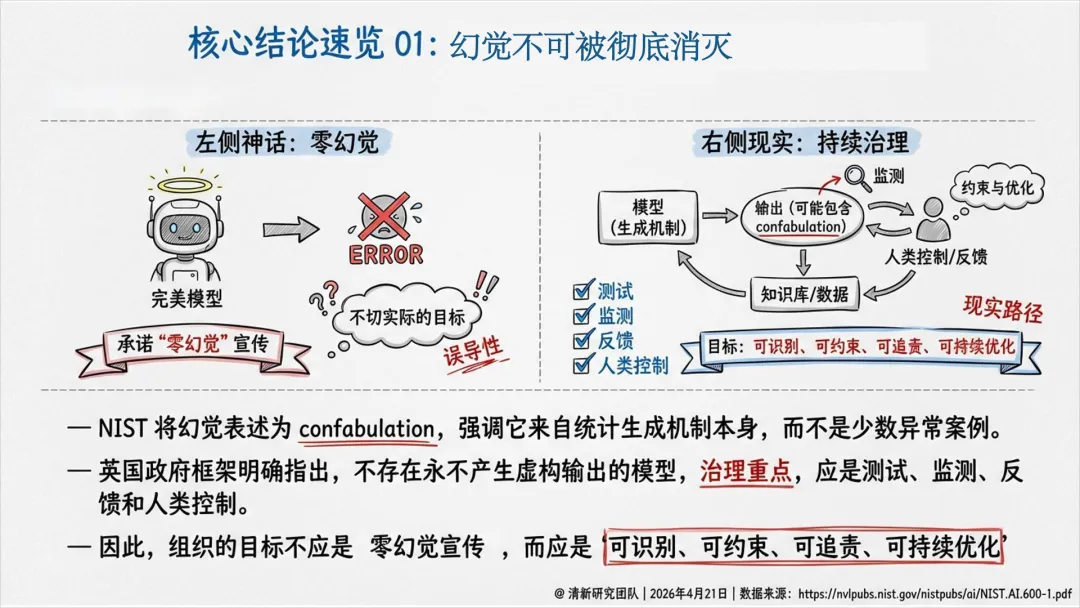
幻觉不可被彻底消灭,治理目标是可识别、可约束、可追责、可持续优化。
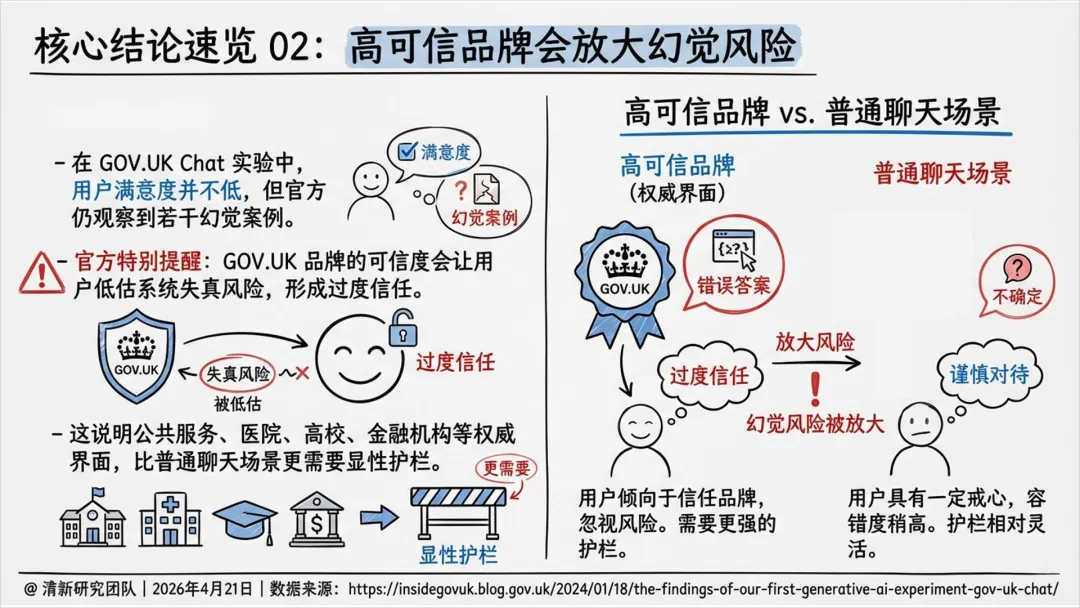
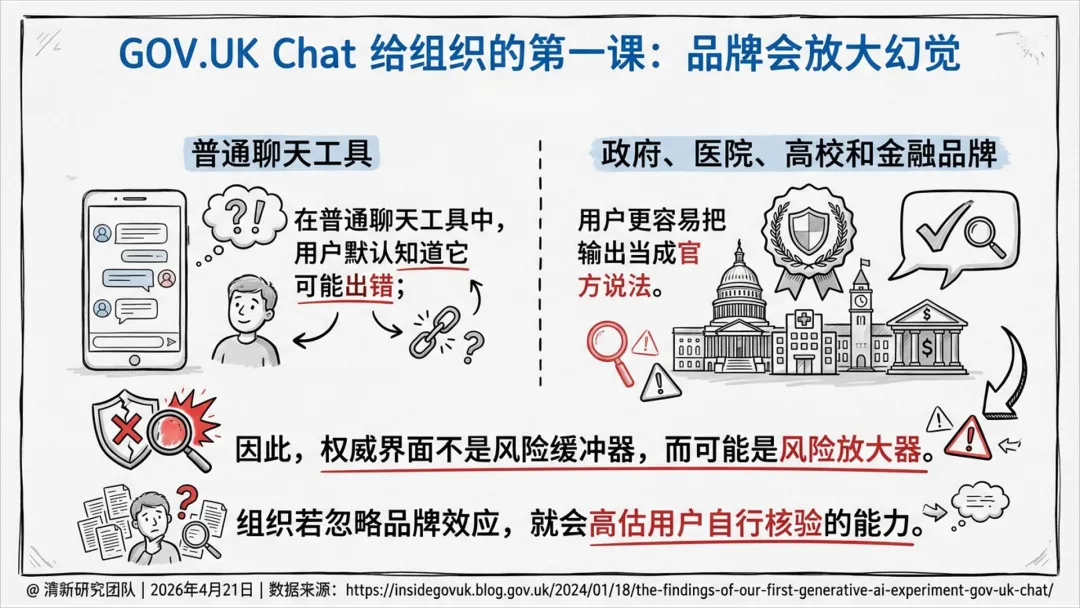
高信任品牌(如政府、医院、高校)会放大幻觉风险,用户更容易误信错误输出。
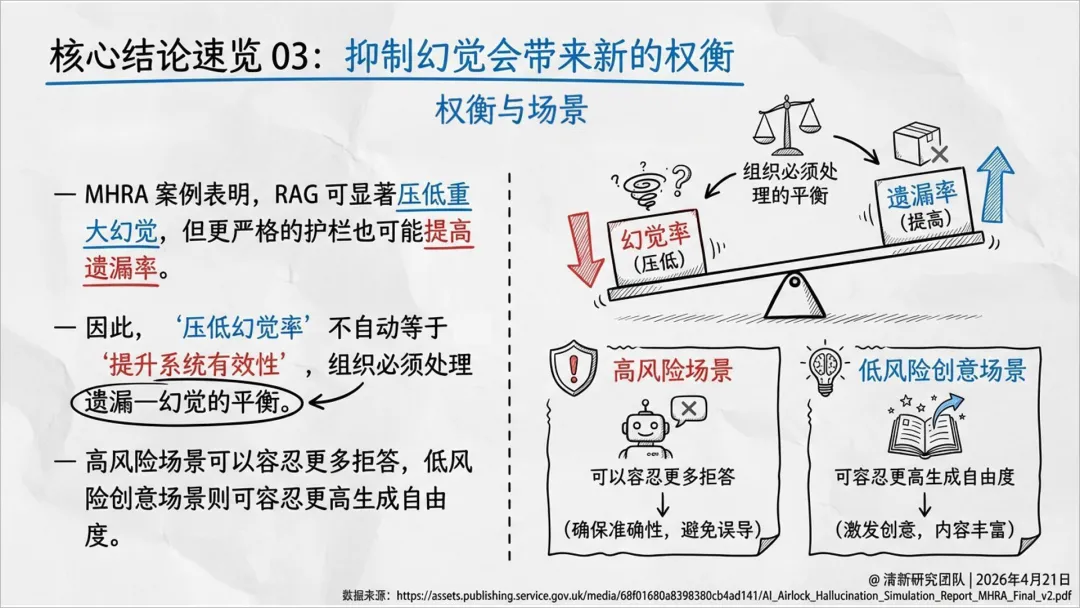
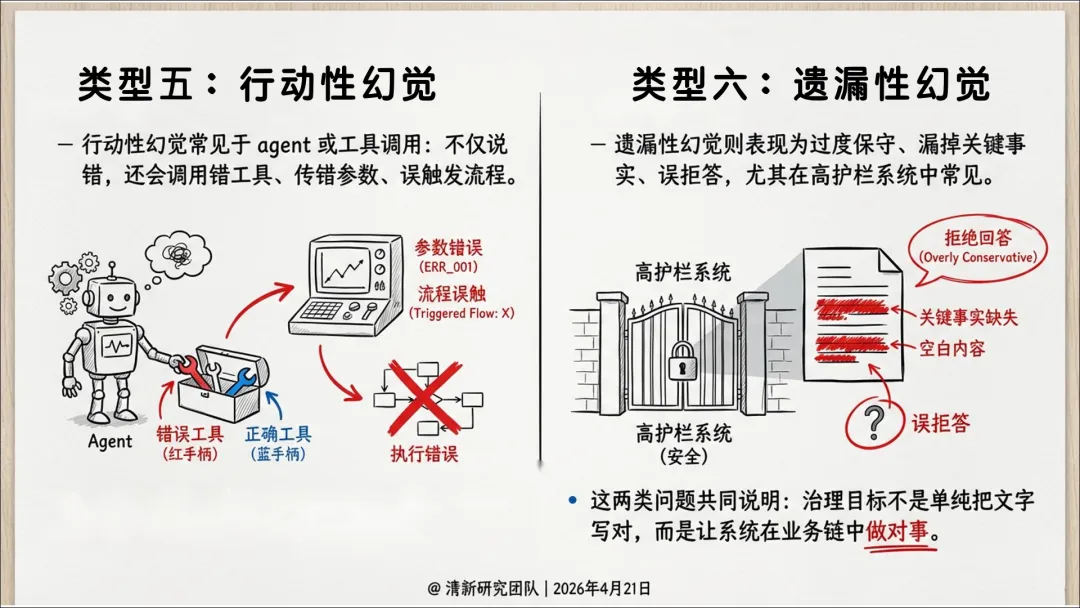
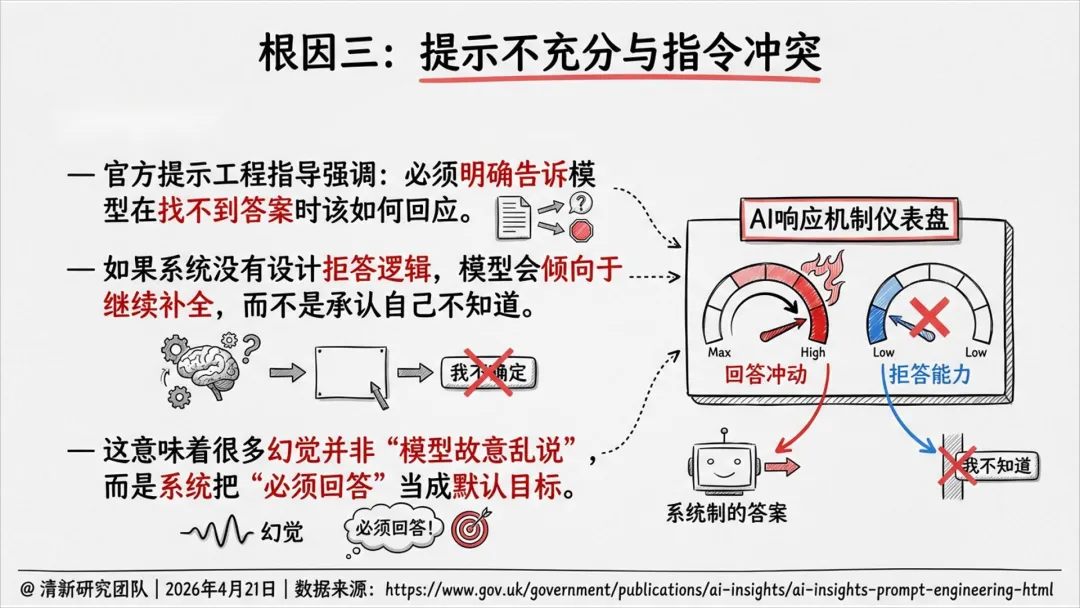
抑制幻觉会带来新的权衡:更严护栏可能提高遗漏率(拒答或漏掉关键信息)。
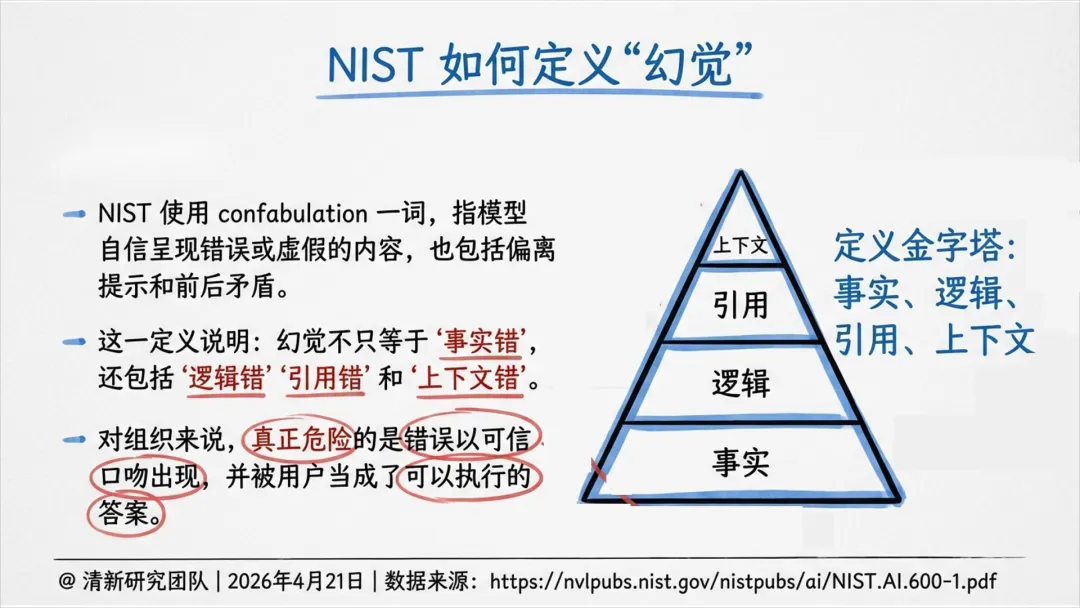
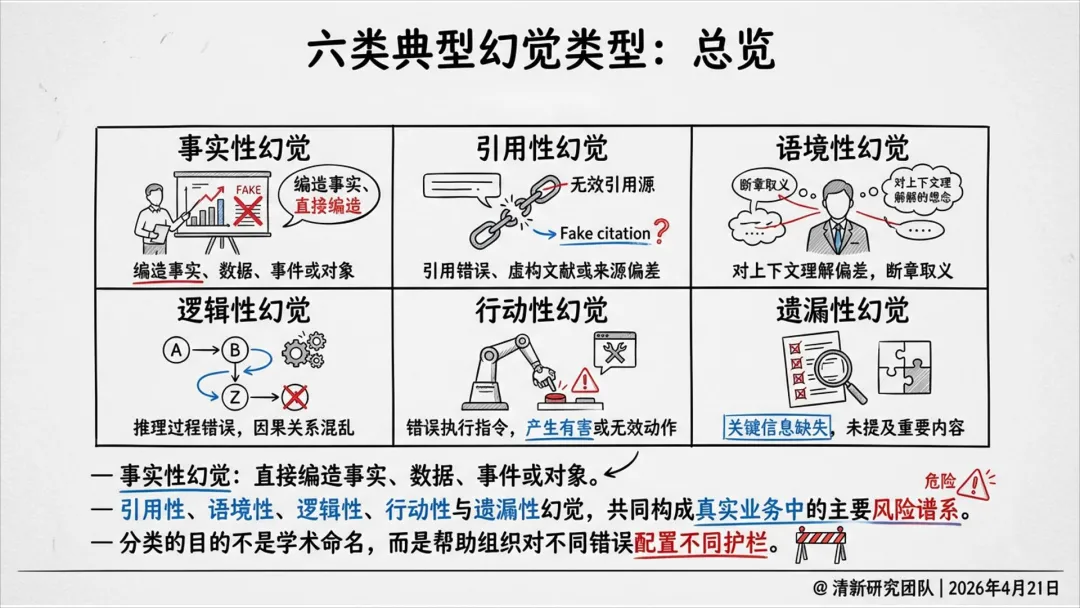
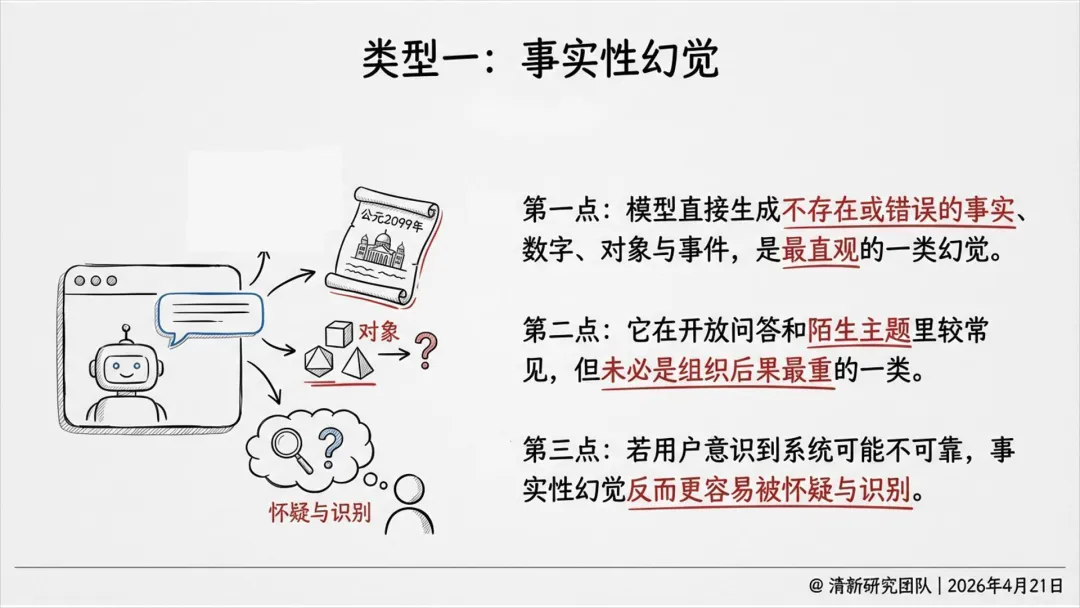
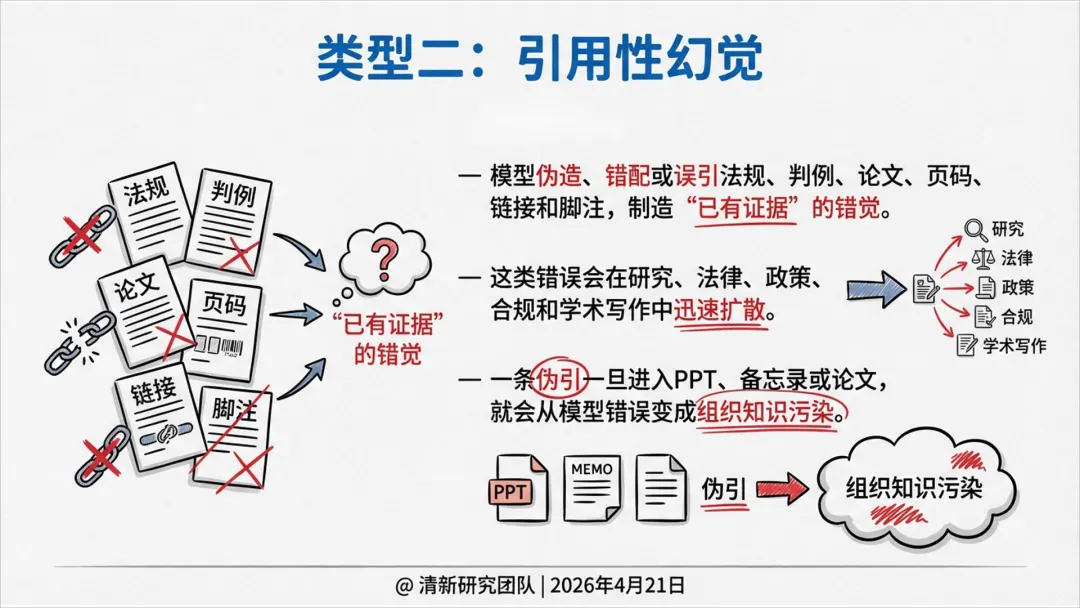
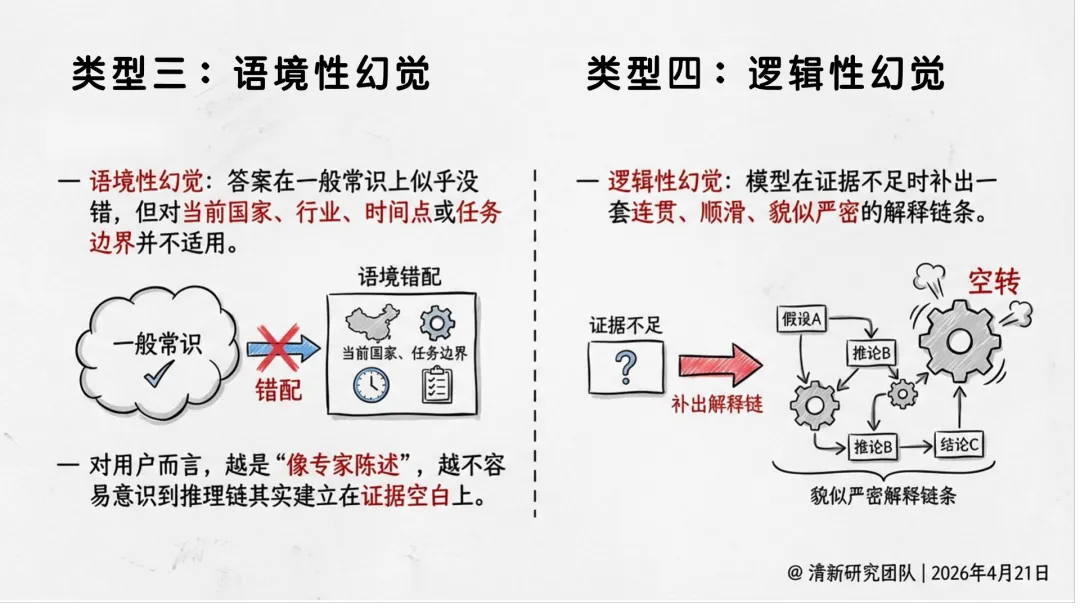
幻觉六类类型:事实性、引用性、语境性、逻辑性、行动性、遗漏性。
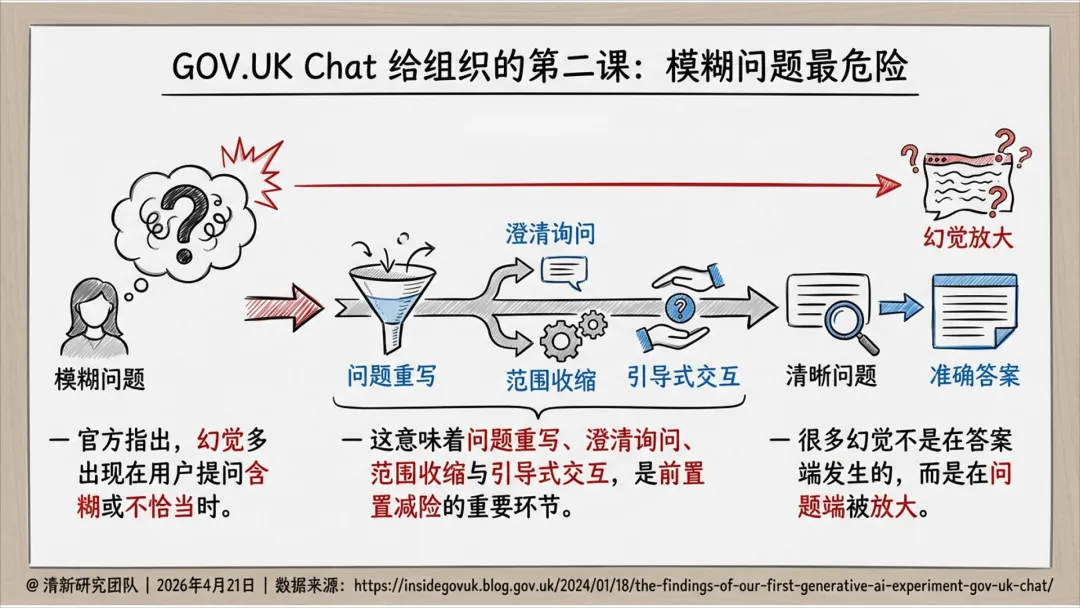
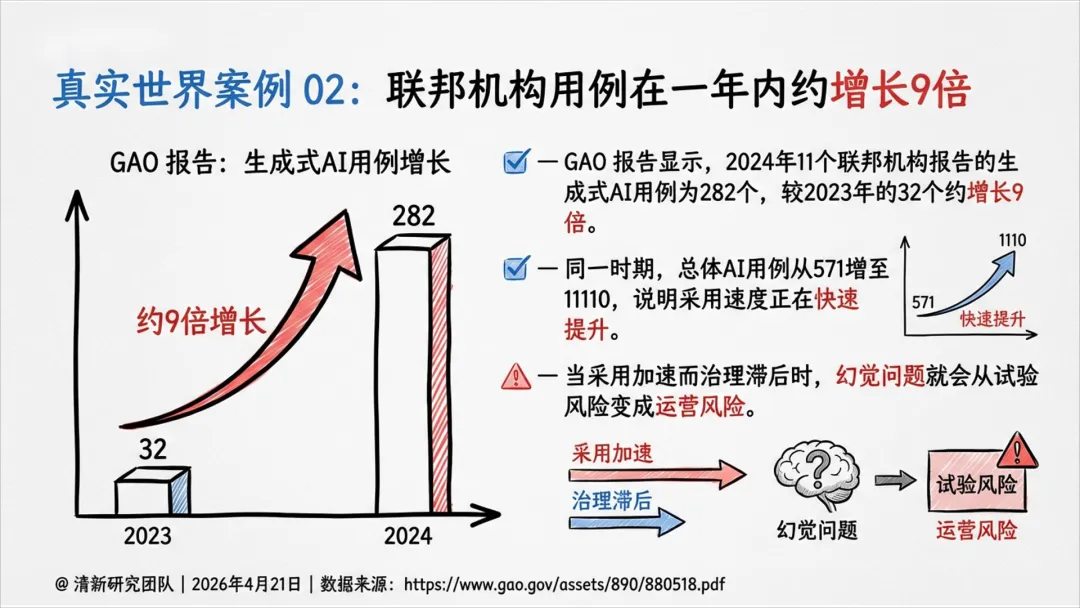
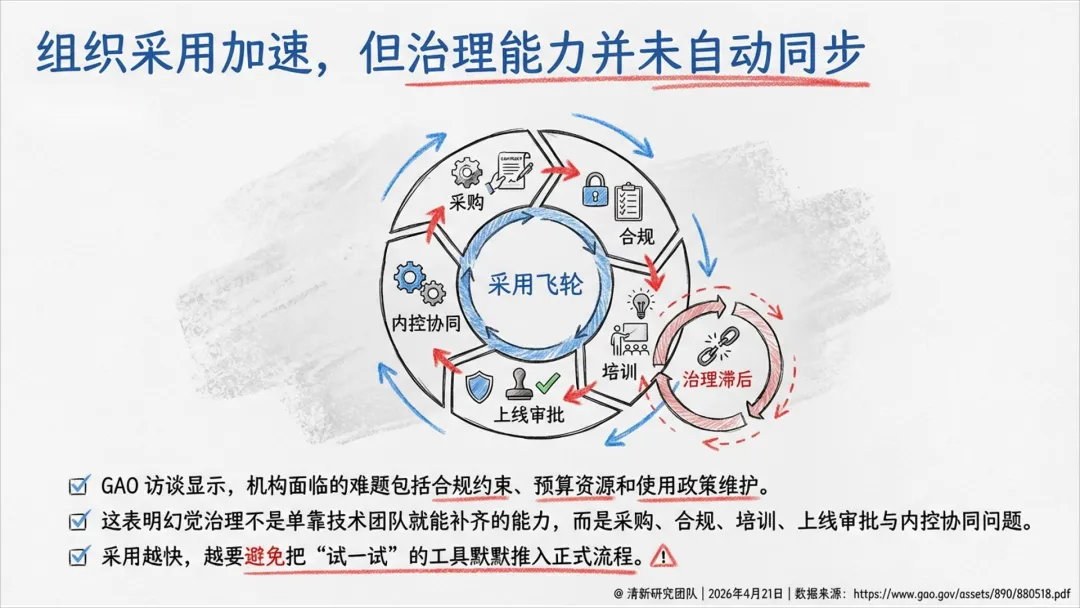
三、真实世界案例
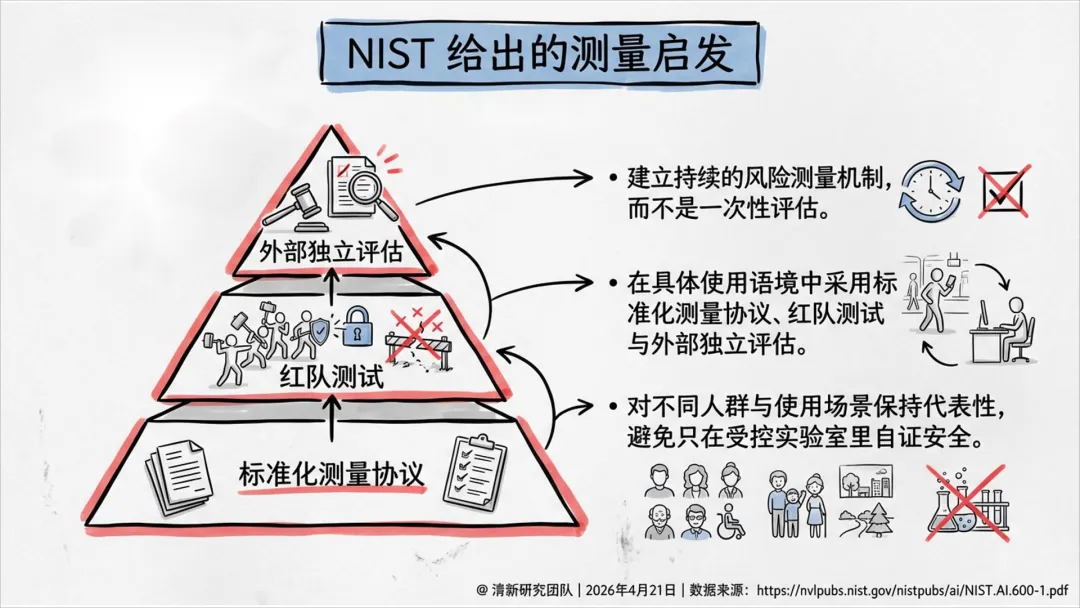
四、官方框架的共同点
幻觉不可一劳永逸地消灭
高影响场景必须有意义的人类复核
内容要可标识、可追溯、可反馈
中国:生成式AI进入规模化备案与标识并行阶段(748款备案)
五、组织治理四步法
画任务风险地图(区分高风险/低风险任务)
设置“不用或降格使用”规则(禁用清单 vs 辅助使用)
有意义的人工复核(有时间、标准、否决权、留痕)
建立抑幻觉六层工程栈:
任务分级 → 知识锚定 → 生成约束(拒答) → 验证校正 → 上线监控 → 责任制度
六、原创概念(用于组织理解幻觉风险)
| 概率真相陷阱 | |
| 引用幻影链 | |
| 低置信高伤害区 | |
| 责任折返门 |
七、行动路线图
30天:识别最危险的任务
60天:补上知识锚定与拒答机制
90天:制度化人工复核与日志、抽检、红队、归因闭环
八、最终结论
真正的分水岭不是会不会用模型,而是能不能驾驭模型。有竞争力的组织不是让模型无所不知,而是让它在不知道时停下来、在高风险时退后一步。幻觉治理的对象不是一句错话,而是一整条生成→采信→执行的链条。





(本星球常年对接50万+报告智库,每日精选50+行业报告学习分享!全星球报告无限制可以任意下载!)
免责声明:本社群只做内容收集和知识分享,严禁用于商业目的,报告版权归原撰写发布机构所有,相关报告通过公开合法渠道收集整理,如涉及侵权,请联系我们删除;如对报告内容存疑,请与撰写、发布机构联系。