


中国信息通信研究院云计算与大数据研究所 | 2026年3月
报告封面

核心内容解读
一、AI计算节点的定义与特征
报告原文:AI计算节点是大模型时代算力集群的核心技术架构,通过高速互联将多颗GPU、CPU、内存、存储等资源聚合为统一计算单元。
四大核心特征:
特征 | 解读 |
高密集约·聚合 | 算力资源高度整合,打破单机边界 |
高速超宽·互联 | TB级带宽、微秒级时延的数据通道 |
高效灵活·调度 | 动态分配算力资源,适配不同任务需求 |
高稳可靠·保障 | 故障自愈能力,保障训练任务连续性 |
二、发展背景:三大驱动力
报告原文:AI发展催生巨大智算缺口,智算中心成为国家战略支点,传统架构遭遇瓶颈。
驱动力一:AI算力需求爆发
IDC预测:2028年全球AI服务器市场规模将突破2227亿美元,保持高速增长态势。
驱动力二:智算中心上升为国家战略
算力已成为数字经济的核心基础设施,各国加速布局。
驱动力三:传统架构无法满足大模型需求
以CPU为中心的传统架构,GPU间通信带宽不足,成为算力效率的瓶颈。
三、发展阶段的演进脉络
报告原文:AI计算节点经历了分散式设备简单互联、机间协同组网、规模化卡间直连三个阶段。
阶段 | 时期 | 技术特征 |
01 分散式设备简单互联 | 互联网时期 | 设备独立,网络连接松散 |
02 机间协同组网 | AI发展初期 | 服务器间协作,算力逐步整合 |
03 规模化卡间直连 | 大模型爆发期 | GPU直连,突破带宽瓶颈 |

当前正处于第三阶段——大模型爆发带来的架构重构关键期。
四、核心技术:架构重构
报告原文:从"CPU为中心"到"GPU互联为中心",这是AI计算节点的核心演进方向。
架构变革的本质:
对比维度 | 传统架构 | 新架构 |
核心逻辑 | CPU是中心,GPU是外设 | GPU互联为核心,CPU辅助调度 |
通信方式 | GPU通过PCIe连接,经CPU中转 | GPU直连通信,绕过CPU |
带宽能力 | 64GB/s | 900GB/s级别 |
时延水平 | 毫秒级 | 微秒级 |
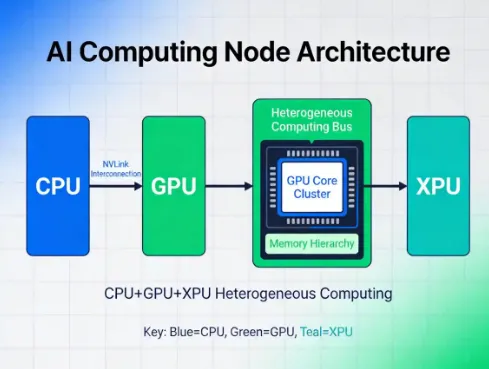
五、异构计算与芯粒技术
报告原文:CPU + GPU + XPU异构计算成为主流,Chiplet芯粒技术实现降本增效。
异构计算架构分工:
处理器 | 核心职责 |
CPU | 系统控制与全局任务调度 |
GPU | 深度学习大规模并行训练主力 |
XPU | 特定算子定制优化,能效更高 |
Chiplet芯粒技术优势:
• 降本增效:SoC拆解为小芯粒,良率提升、成本下降
• 灵活突破:混合工艺组合,缓解"内存墙"性能瓶颈
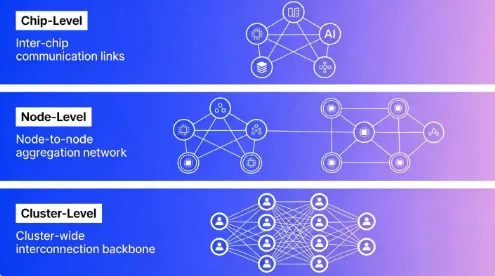
六、超低时延网络:三级互联体系
报告原文:构建节点内、节点间、集群级三级互联体系,实现万卡级算力扩展。
层级 | 技术方案 | 能力指标 |
节点内·芯片级 | NVLink全互联拓扑 | TB级带宽、微秒级时延 |
节点间·机柜级 | 高速交换机互联 | 低时延数据交换 |
集群级·数据中心级 | InfiniBand/RoCE | 支撑万卡级并行训练 |
行业判断
结合报告内容,可以得出以下趋势判断:
1. 算力竞争进入"系统级"阶段:拼的不再是GPU数量,而是互联效率与调度能力
2. 架构重构加速推进:以GPU互联为核心的新架构将成为主流
3. 异构计算成为标配:CPU+GPU+XPU的组合将更灵活多样
4. 国产替代窗口期:架构重构期为国产芯片提供了重新定义互联标准的机会
报告来源:中国信息通信研究院《AI计算节点发展研究报告(2026年)》,2026年3月发布
