



在AI技术迅猛发展的时代,数据中心不再是简单的服务器仓库,而是支撑人工智能革命的核心基础设施。近日,Siemens联合NVIDIA和nVent发布的《100MW Hyperscale AI Blueprint》白皮书,为我们描绘了一幅高效、可扩展的AI数据中心蓝图。这份技术文档不仅仅是一份参考架构,更是针对AI工作负载的痛点——功率密度、冷却效率和运营弹性——提供的实用解决方案。它以NVIDIA GB200 NVL72系统为核心,整合Siemens工业级电气系统和nVent液冷技术,旨在帮助运营商快速部署、降低能耗,并最大化“每瓦特 Tokens”(tokens-per-watt)的输出。

白皮书总计约22页,为基于 NVIDIA GB200 NVL72 平台的超大规模 AI 数据中心提供一套标准化的、可快速部署的 Tier III级基础设施蓝图。白皮书强调AI基础设施的关键指标:部署速度和“每瓦特Tokens”(tokens-per-watt)效率。设计围绕NVIDIA GB200 NVL72机架,每个机架功率127 kW(液冷102 kW,风冷25 kW)。内容目录清晰列出章节:从趋势概述到功率、冷却、自动化,再到结语和附录。
白皮书原文:上方二维码扫码分享,备注公司+姓名+职务
一.设计理念与核心挑战
在 AI 时代,基础设施的衡量标准已经改变。传统的指标不再适用,新的 KPI 是“从部署到生成 Token 的速度”以及“每瓦特电力能产生多少 Token”。
为了支撑 NVIDIA GB200 NVL72 这种单机架功率密度高达 127 kW 的计算怪兽,本白皮书提出了一种基于 “Pod(微模块)” 的模块化设计理念。这种设计旨在平衡高性能、高能效和全球范围内的快速复制能力。
关键规格概览
总容量:100 MW IT 负载。 计算核心:NVIDIA GB200 NVL72 机架(72个 GPU + 36个 Grace CPU)。 可靠性等级:Tier III(可同时维护,Concurrently Maintainable)。 冷却技术:nVent 机架级液冷 + 西门子工业级自动化控制。 扩展性:设计已前瞻性地支持下一代 NVIDIA GB300 NVL72 平台。
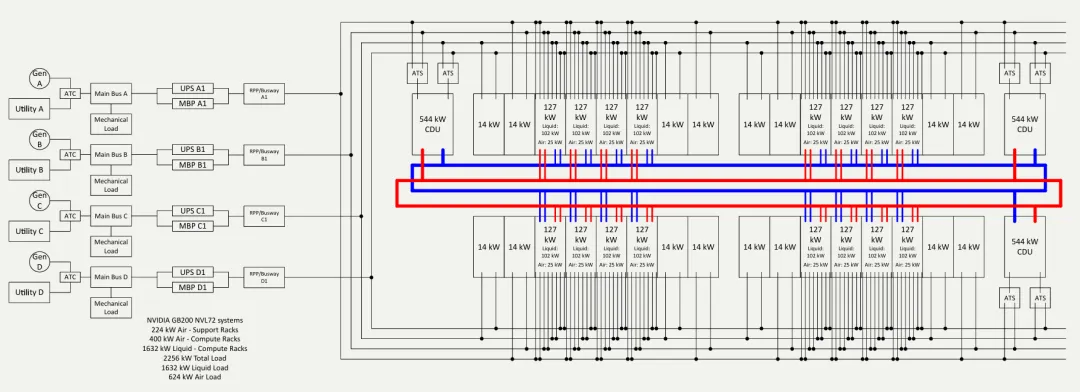
参考架构⽰意图
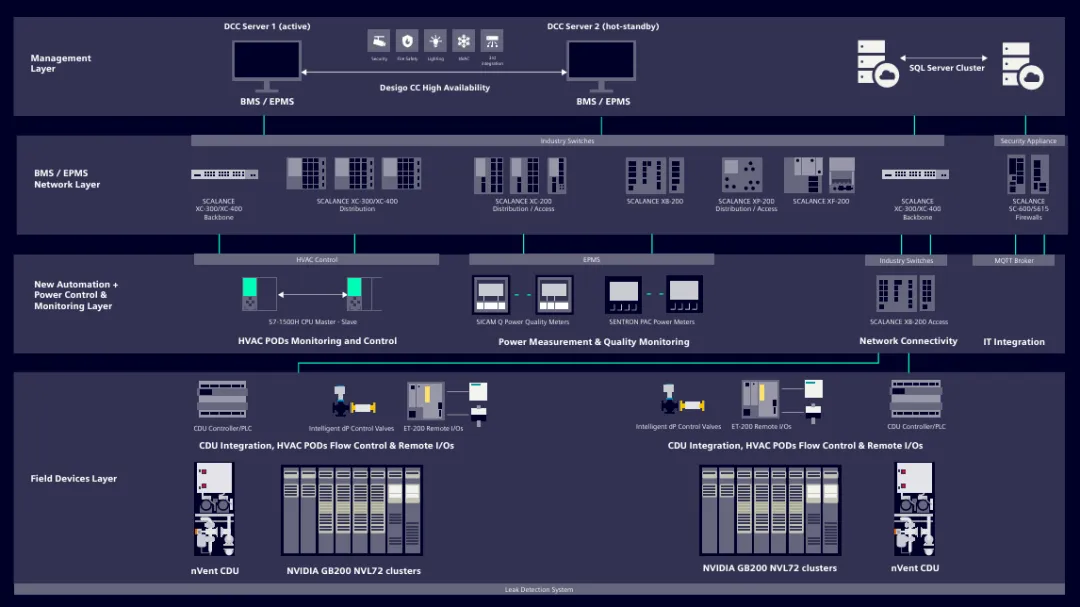
第二章:Pod 级模块化架构详解
白皮书的核心构建单元是 Pod。整个 100 MW 数据中心由约 40 个 Pod 拼接而成。
1. Pod 的构成
每个 Pod 是一个独立的故障隔离域,包含 32 个机架:
计算机架(Compute Racks):部署 NVIDIA GB200 NVL72,主要采用液冷。
网络与支持机架(Network/Support Racks):部署交换机等设备,主要采用风冷。
2. Pod 的负载分布
单个 Pod 的总 IT 负载设计为 2.256 MW,具体分配如下:
液冷负载:1632 kW(由计算侧产生)。
风冷负载:624 kW(由网络设备和计算侧残留热量产生)。
这种设计使得数据中心可以像搭积木一样进行扩容,不仅简化了规划,还实现了核心、边缘和混合环境的统一部署标准。
第三章:电力架构——为高密度而生
如何安全地向单机架输送 127 kW 的电力?本方案采用了 415V 直供 配合 “4-to-make-3” 的冗余策略。
1. 中压与低压拓扑 (MV/LV Topology)
输入侧:双路市电接入(Utility A/B),经由中压开关柜(MV Switchgear)分配。
冗余模型:系统设计为 Tier III 级。每个 Pod 配备 4 台 1500 kW 的 UPS。
4-to-make-3 逻辑:这是一种高效的 N+1 模式。4 组电力系统共同承担 3 组负载的压力。当其中一组进行维护或发生故障时,剩余 3 组可以无缝接管所有负载,无需停机。
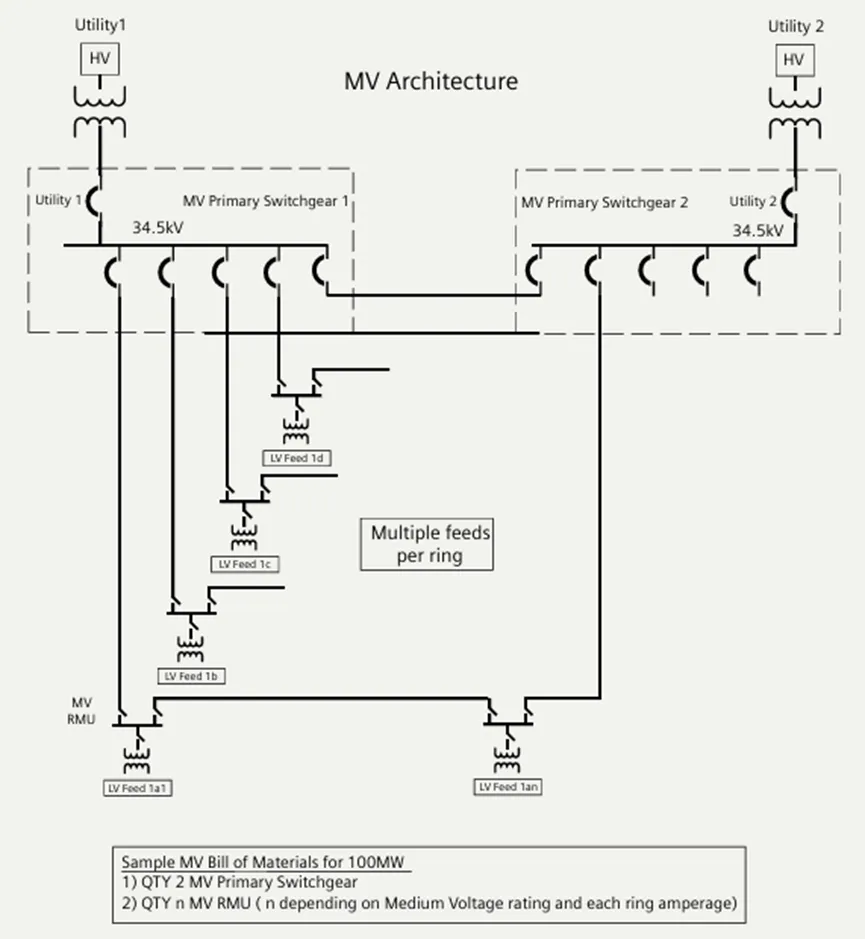 兆瓦级电源架构⽰意图,清晰展示了从 Utility 到 UPS 再到末端的四路并行架构。
兆瓦级电源架构⽰意图,清晰展示了从 Utility 到 UPS 再到末端的四路并行架构。2. 末端配电细节
为了减少线缆混乱并提高灵活性,方案放弃了传统的列头柜,全线采用智能母线槽(Busway)。电压等级为415V AC。
GB200 NVL72 机架供电:每个机架内部有 8 个电源架,实现机架级 N+1 冗余。每个机架从母线槽引出 8 个 60A 电路 进行供电。
CDU供电:每个 CDU 由 4 个 30A 电路供电,确保冷却系统的绝对安全。
网络机架供电:每个机架配备 2 个 30A 电路(双路馈电)。
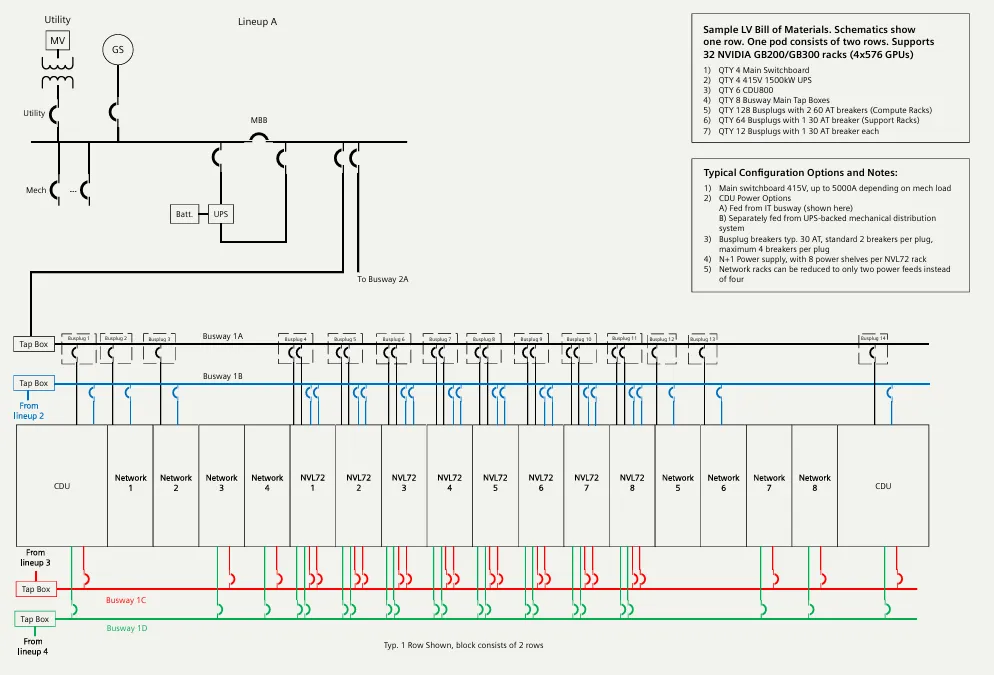
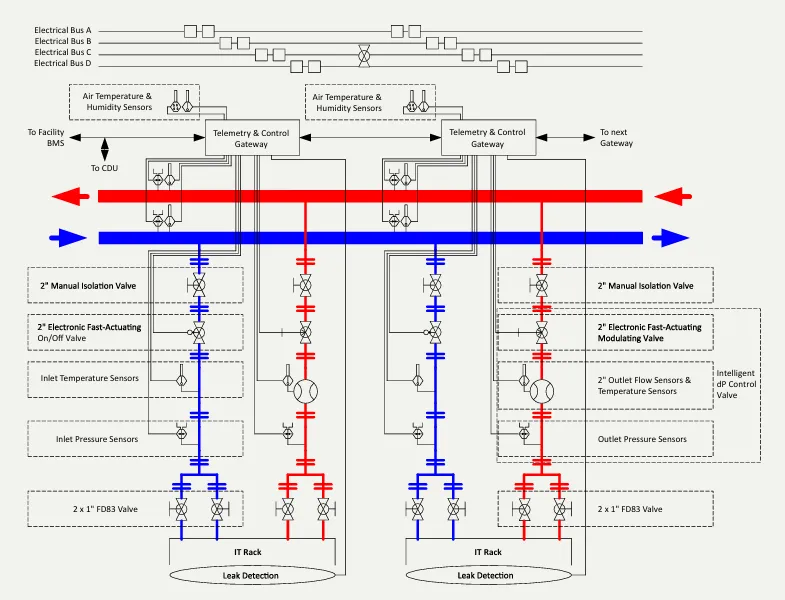
第四章:冷却架构——液冷系统的革新
随着芯片热密度的提升,风冷已成过去式。本方案采用了 nVent 的直接芯片液冷(Direct-to-Chip) 技术,并引入了独特的冗余设计。
1. 温水冷却策略
ASHRAE 标准:系统运行在 W32-W45 温水等级。
无冷机运行(Chiller-free):由于回水温度较高,在大部分温带气候下,仅需使用干冷器(Dry Cooler)与室外空气进行热交换即可,无需开启压缩机,从而大幅降低 PUE。
2. CDU800:解耦热与其电气冗余
这是白皮书中强调的技术亮点。每个 Pod 配置 3 台 nVent CDU800,总计支持 1.63 MW 的液体热负载。
传统痛点:传统 CDU 通常是单路供电,为了冗余往往需要配置 N+1 台设备(即 3 用 1 备),这增加了成本和占地。本方案创新:CDU800 内部集成了两个完全独立的泵,每个泵由独立的外部电源供电。效果:即使损失了一路电源、一个变频器(VFD)或一个泵,剩余的泵仍能驱动 CDU 输出 100% 的额定冷量(544 kW)。
结论:这种设计将“电气可用性”与“热容量”解耦,无需额外部署第 4 台 CDU 即可满足高可用性要求。
3. 安全机制
泄漏检测:集成多级泄漏传感器。
自动隔离:一旦检测到泄漏,控制系统会触发机架级的电动阀门,瞬间切断故障机架的液路,而 Pod 内其他机架继续正常运行。
第五章:自动化与控制——OT 与 IT 的融合
为了管理如此复杂的系统,白皮书提出使用 IDCMS(集成数据中心管理套件) 来打破 OT(运营技术)与 IT 之间的壁垒。
1. 统一管理平台
IDCMS 集成了楼宇管理(BMS)和电力管理(EPMS),并与 NVIDIA Mission Control 深度对接。这意味着:设施侧的冷却状态可以实时反馈给 IT 侧的调度系统;IT 侧的负载预测可以提前通知设施侧调整冷却能力。
2. 遥测与控制网关
在物理层,方案部署了 Rack Telemetry & Control Gateway(机架遥测控制网关):
位置:每个液冷机架配备一个。
功能:它是连接 CDU 控制器和 IDCMS 的数字桥梁。它负责监控局部传感器,并控制调节阀。
响应:当发生泄漏或压力异常时,网关可自主判断并执行保护动作,同时向中央系统报警。
3. 电能质量监测
系统集成了 SICAM Q 和 SENTRON PAC 仪表,实时监控电能质量。在 AI 训练这种长周期高负载任务中,微小的电力波动都可能导致计算中断,该系统可提前识别此类风险。
第六章:结论与未来展望
这份白皮书不仅是针对当下的解决方案,也为未来预留了空间。标准化:通过标准化的 Pod 设计,消除了定制化设计带来的时间成本。密度与效率:实现了 100 MW 规模下的高密度计算与低 PUE 的统一。前瞻性:明确指出该架构(包括电力和冷却管路)已准备好支持下一代 NVIDIA GB300 平台。
对于数据中心运营商而言,这份蓝图提供了一条从“传统风冷”向“液冷 AI 工厂”转型的低风险、高可靠实施路径。
白皮书原文:上方二维码扫码分享,备注公司+姓名+职务
欢迎关注「液冷产业链最前沿」!我们专注液冷领域,为您提供:最新政策与市场动态的实时追踪,标杆企业战略与技术的深度剖析,以及贯穿上下游的产业链硬核分析。添加好友:lxyc18615618005,免费领取最新研报。跟着我们走在液冷赛道最前端~。以下为最新内容,点击链接即可深度阅读: