



引言:一个新时代的开端
2025年1月,月之暗面(Moonshot AI)发布了Kimi K2.5,这不仅仅是一次模型更新,更代表着AI智能体发展的一个重要里程碑。如果说过去的AI模型是单核处理器,那么K2.5就是首个真正实现多核并行的智能体系统。
本文将基于Kimi K2.5官方技术报告,为你深入解析这个开创性模型背后的技术突破、设计理念和实际应用价值。

第一部分:核心突破——三大技术创新
1. 文本与视觉的原生融合:从补课到共同成长
传统方法的困境
在过去,大多数多模态模型采用的是先文本后视觉的训练策略。想象一下,这就像一个学生先花10年学习文字阅读,然后再用1年时间补习图像理解。这种方法存在明显的问题:
• 能力失衡:文本能力过强,视觉能力相对薄弱 • 相互冲突:后期加入视觉数据会干扰已有的文本能力 • 效率低下:需要在训练后期使用高比例(50%以上)的视觉数据来追赶
K2.5的创新:原生多模态预训练
月之暗面团队通过大量实验发现了一个反直觉的结论:在固定的训练资源下,早期融入少量视觉数据(10%-20%),效果比后期大量注入视觉数据(50%)更好。
这一发现催生了K2.5的核心策略:
训练方案对比:
传统方法:[纯文本 80%] → [文本50% + 视觉50%]
K2.5方法:[文本90% + 视觉10%] 从始至终
技术细节:三阶段训练流程
K2.5的预训练包含三个精心设计的阶段:
1. 阶段一:视觉编码器训练(1T tokens) • 独立训练MoonViT-3D视觉编码器 • 使用图像标注、合成描述、定位框、OCR文本等多样化数据 • 采用SigLIP对比损失 + 图像描述生成双重目标 2. 阶段二:联合预训练(15T tokens) • 同时优化视觉编码器和语言模型 • 保持10%视觉 + 90%文本的恒定比例 • 在4K序列长度下进行 3. 阶段三:长上下文激活与高质量微调(500B-200B tokens) • 使用YaRN插值技术将上下文从4K扩展到262K • 注入高质量推理、长文本、长视频数据 • 最终支持256K token的超长上下文
实验验证:早期融合的优势
技术报告中的表1清楚展示了不同策略的效果对比:
| 25.8 | 43.8 | 65.7 | 45.5 | 58.5 | 24.8 | ||
结论显而易见:早期融入10%视觉数据的策略,在所有任务上都取得了最佳表现。
为什么早期融合更好?
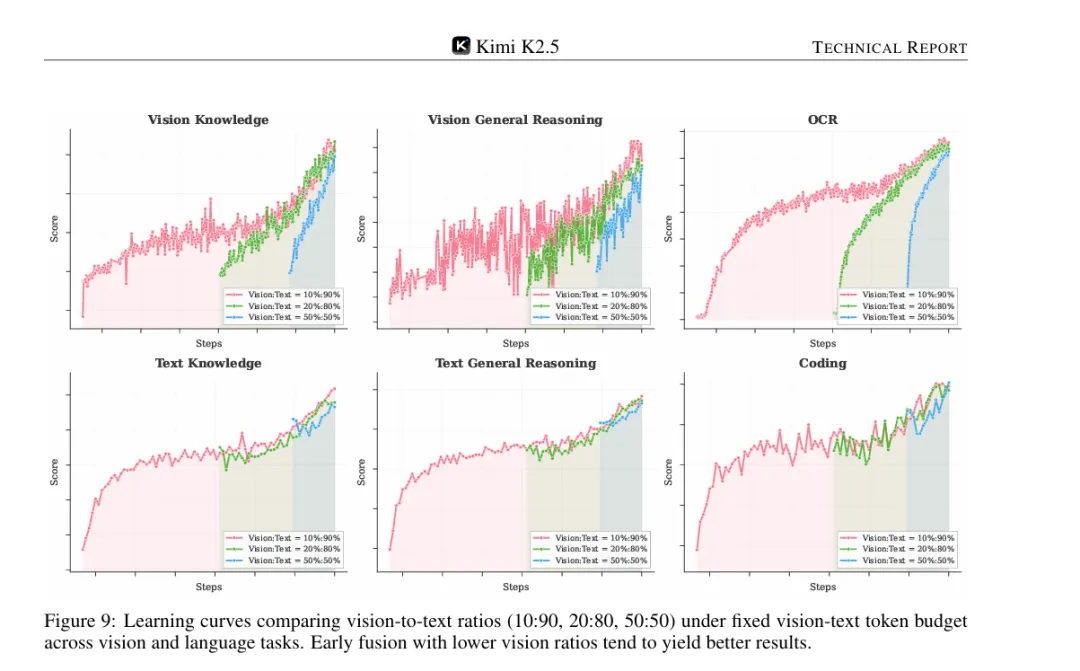
• 中期/后期融合:当视觉数据突然注入时,文本性能会先下降再恢复(dip-and-recover现象) • 早期融合:文本性能曲线始终平稳上升,没有波动
这说明早期融合能让模型自然地学习统一的多模态表示,而不是后期被迫调整已经固化的文本表示空间。
2. Zero-Vision SFT:用文本激活视觉能力
传统视觉微调的瓶颈
在监督微调(SFT)阶段,传统方法需要大量高质量的视觉指令数据,包括:
• 人工标注的视觉推理链 • 精心设计的多模态对话样本 • 视觉工具使用的示范轨迹
但这类数据有两个致命问题:
1. 数量少:人工标注成本极高 2. 质量低:往往局限于简单的图表和基础操作(裁剪、旋转、翻转)
K2.5的创新:零视觉监督微调
月之暗面团队发现了一个惊人的现象:仅使用纯文本的SFT数据,就能激活模型的视觉推理和工具使用能力!
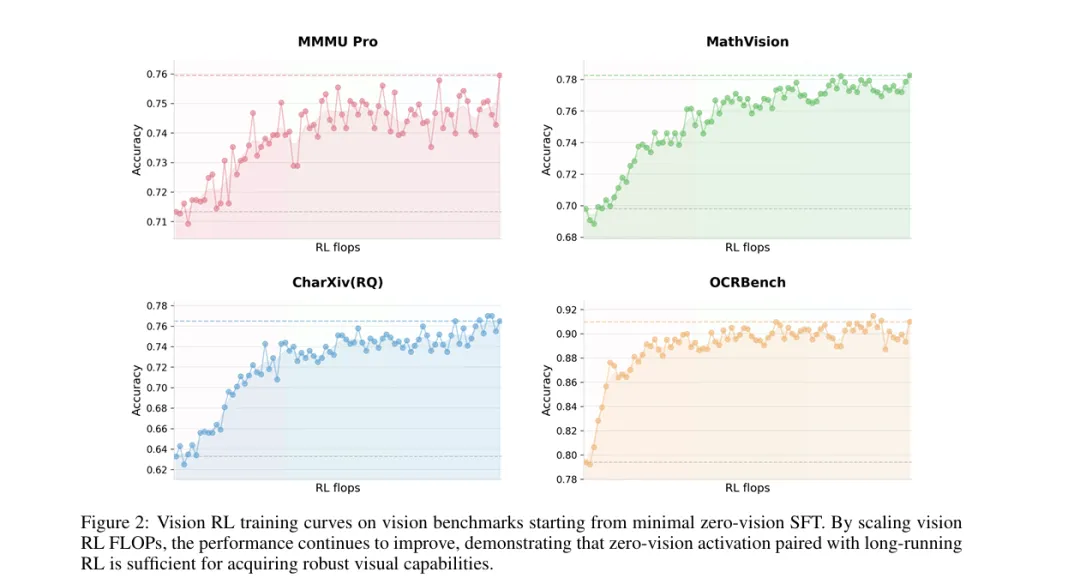
技术原理
关键在于预训练阶段已经建立了强大的文本-视觉对齐。具体做法:
# 将所有图像操作转换为代码形式
# 例如:不是直接标注"这个物体的大小是X"
# 而是生成Python代码来计算:
from PIL import Image
import numpy as np
# 加载图像
img = Image.open('input.png')
img_array = np.array(img)
# 二值化处理
threshold = 128
binary = (img_array > threshold).astype(int)
# 计算物体大小
object_size = np.sum(binary)
print(f"物体像素数: {object_size}")
这种零视觉激活方式的优势:
• ✅ 泛化性强:能自然迁移到各类视觉任务 • ✅ 多样性高:继承了丰富的文本SFT数据 • ✅ 成本低:无需专门标注视觉数据
实验对比
初步实验显示,Zero-Vision SFT在视觉智能体任务上的表现显著优于传统的文本-视觉联合SFT。原因可能是:
• 传统方法的视觉数据质量不足,反而引入噪声 • Zero-Vision SFT避免了低质量视觉数据的干扰
3. 联合多模态强化学习:视觉反哺文本
传统RL的模态分离
传统的多模态强化学习通常按模态划分专家:
• "文本专家"只从文本任务中学习 • "视觉专家"只从视觉任务中学习
这导致两个问题:
1. 能力孤立,缺乏跨模态迁移 2. 视觉训练可能损害文本性能
K2.5的创新:按能力划分,而非按模态
K2.5的强化学习策略完全不同:
传统方法:
├── 文本专家 ← 文本任务
└── 视觉专家 ← 视觉任务
K2.5方法:
├── 知识专家 ← 文本知识任务 + 视觉知识任务
├── 推理专家 ← 文本推理任务 + 视觉推理任务
├── 编程专家 ← 文本编码任务 + 视觉编码任务
└── 智能体专家 ← 文本工具使用 + 视觉工具使用
惊人发现:视觉RL提升文本能力
通常认为,视觉训练会损害文本性能。但K2.5的实验结果完全相反:
| +1.7% | |||
| +2.1% | |||
| +2.2% |
为什么视觉RL能提升文本能力?
技术报告给出的分析:
1. 校准改进:视觉RL提升了结构化信息提取的准确性 2. 不确定性降低:在类似视觉推理的文本任务(如计数、OCR式任务)上减少了错误 3. 跨模态泛化:视觉训练中学到的能力自然迁移到了文本领域
这种双向增强——文本引导视觉,视觉反哺文本——代表了联合训练的真正优势。
第二部分:Agent Swarm——智能体集群的革命
传统智能体的"串行困境"
想象你要完成一个复杂项目,需要:
1. 搜索技术文档 2. 查看GitHub示例 3. 编写代码 4. 编写测试用例 5. 生成文档
传统AI智能体会这样工作:
时间线:
[0-5分钟] 搜索文档 → 等待...
[5-10分钟] 查看GitHub → 等待...
[10-20分钟] 编写代码 → 等待...
[20-25分钟] 编写测试 → 等待...
[25-30分钟] 生成文档 → 完成
总耗时:30分钟
这种"单线程"执行模式存在严重问题:
• ⏰ 延迟高:每一步都要等待 • ? 效率低:无法并行处理独立任务 • ? 扩展性差:任务越复杂,等待时间指数增长
Agent Swarm:并行智能体编排
K2.5引入的Agent Swarm完全改变了这一模式:
时间线:
[0-5分钟] 主协调器分析任务
├── 子智能体1:搜索文档 ⚡
├── 子智能体2:查看GitHub ⚡
├── 子智能体3:编写代码 ⚡
└── 子智能体4:编写测试 ⚡
(四个任务同时进行)
[5-8分钟] 主协调器汇总结果
└── 子智能体5:生成文档 ⚡
总耗时:8分钟(提速3.75倍)
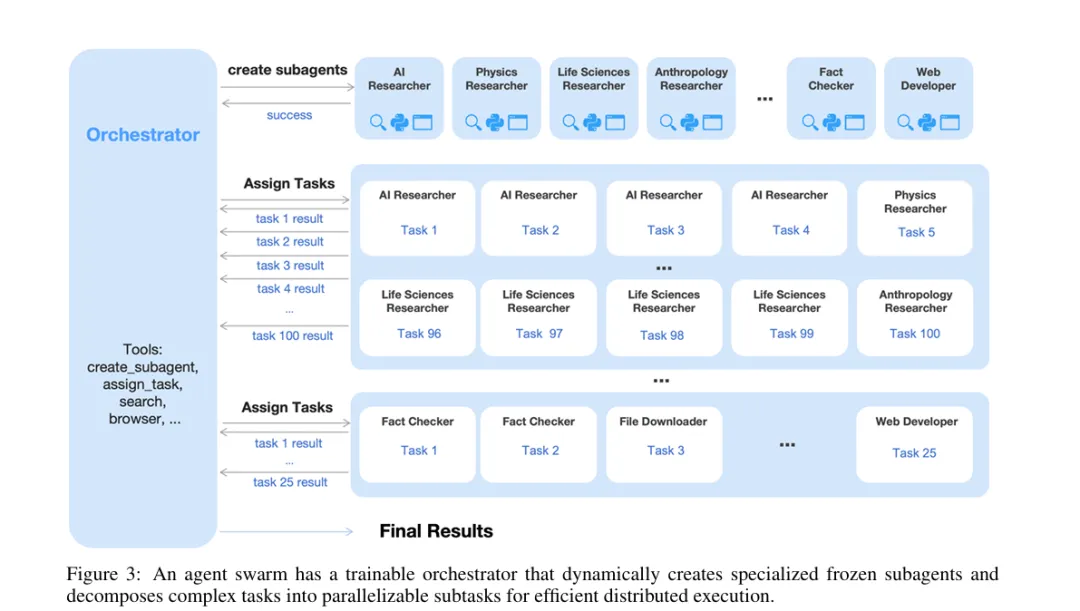
技术架构:三层设计
1. 主协调器(Orchestrator)
• 职责:任务分析、拆解、调度 • 特点:可训练,通过RL学习最优编排策略 • 工具: • create_subagent:创建专门化子智能体• assign_task:分配任务给子智能体
2. 子智能体(Sub-agents)
• 职责:执行具体领域任务 • 特点:冻结参数,来自固定的中间检查点 • 类型:搜索专家、编码专家、浏览专家、分析专家等
3. 独立沙盒环境
• 每个子智能体运行在隔离环境中 • 互不干扰,保证执行稳定性 
训练方法:PARL(并行智能体强化学习)
核心挑战
训练一个可靠的并行编排器极其困难:
1. 信用分配模糊:最终结果好,不代表每个子智能体都做对了 2. 训练不稳定:多智能体联合优化容易发散 3. 奖励稀疏:只有最终结果,缺乏中间反馈
K2.5的解决方案:解耦架构
训练策略:
✅ 主协调器:可训练,参数更新
❌ 子智能体:冻结,参数固定
优点:
1. 避免信用分配问题(子智能体的错误不影响主协调器梯度)
2. 提升训练稳定性(单一优化目标)
3. 提高资源效率(只训练协调器)
PARL奖励函数
技术报告设计了一个精妙的多目标奖励函数:
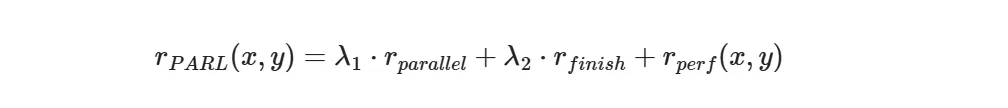
三个组成部分:
1. 并行度奖励 $r_{parallel}$ • 目的:鼓励创建子智能体 • 防止问题:串行惰性(Orchestrator懒得并行,直接自己做) 2. 完成率奖励 $r_{finish}$ • 目的:确保子任务真正完成 • 防止问题:虚假并行(创建很多子智能体但都不工作) 3. 性能奖励 $r_{perf}$ • 目的:保证最终质量 • 衡量:任务完成的正确性和质量
训练策略:退火机制
为了避免过度优化并行度而牺牲质量,K2.5采用退火策略:
# 训练初期:λ1, λ2 较大,鼓励探索并行
# 训练后期:λ1, λ2 → 0,只优化性能
训练过程:
[初期] λ1=0.5, λ2=0.5 → 学习如何并行
[中期] λ1=0.2, λ2=0.2 → 平衡并行与性能
[后期] λ1=0.0, λ2=0.0 → 纯粹追求质量
关键步数(Critical Steps):衡量真实成本
传统计数方法的问题
传统的步数统计:
总步数 = 主智能体步数 + 所有子智能体步数之和
这种计数不反映真实时间成本!例如:
• 3个子智能体并行执行,每个10步 • 传统计数:1 + 3×10 = 31步 • 实际耗时:只相当于1 + 10 = 11步(并行执行)
K2.5的关键步数定义
借鉴计算图中"关键路径"的概念:

实际效果
通过关键步数的约束,K2.5的编排器被迫学习:
• ✅ 均衡分配任务(避免某个子智能体成为瓶颈) • ✅ 有效并行化(减少关键路径长度) • ✅ 避免无效并行(不创建对缩短时间无用的子智能体)
第三部分:MoonViT-3D——统一的视觉编码器
设计理念:图像与视频的共享表示
传统方法的问题
大多数多模态模型对图像和视频采用不同的架构:
• 图像编码器:2D Vision Transformer • 视频编码器:额外的时序模块(3D卷积、时序Transformer等)
这导致:
1. 参数冗余(两套参数) 2. 知识割裂(图像理解不能迁移到视频) 3. 维护复杂(需要分别优化)
MoonViT-3D的创新:完全共享的参数空间
K2.5的视觉编码器实现了真正的统一:
架构特点:
├── 同一套参数同时处理图像和视频
├── 同一个注意力机制同时处理空间和时间
└── 同一个嵌入空间表示静态和动态视觉
技术细节:
1. 基础:SigLIP-SO-400M(4亿参数)
2. 策略:NaViT的patch packing
3. 扩展:时空体积处理(spatiotemporal volumes)
技术实现:Patch n’ Pack的时空扩展
处理图像
原始图像(任意分辨率)
↓
分割成patches(如16×16)
↓
展平成1D序列
↓
打包(pack)成连续序列
↓
标准Transformer处理
优势:
• ✅ 支持任意分辨率输入 • ✅ 高效批处理不同尺寸的图像 • ✅ 无需复杂的图像分割与拼接
处理视频
关键创新:将时间维度也纳入"patch n’ pack"框架
连续4帧视频
↓
视为一个时空体积
↓
提取2D patches(每帧独立)
↓
联合展平成1D序列
↓
同一个Transformer处理空间和时间
↓
时序池化(4帧 → 1个表示)
时序压缩机制
# 伪代码示例
for chunk in video.chunks(size=4): # 每4帧一组
patches = []
for frame in chunk:
# 共享的MoonViT处理每一帧
frame_patches = moonvit.encode(frame)
patches.append(frame_patches)
# patch级别的时序平均
compressed = temporal_average(patches, dim=time)
video_embeddings.append(compressed)
# 结果:4倍时序压缩
# 原始:1小时视频 = 108,000帧
# 压缩后:相当于27,000帧的表示
优势:
• ✅ 4倍时序压缩:能在相同上下文窗口处理4倍长的视频 • ✅ 参数完全共享:图像和视频使用同一套权重 • ✅ 知识自然迁移:图像理解能力直接增强视频理解
实际效果:领先的视频理解能力
技术报告Table 4显示,K2.5在所有主要视频基准上达到SOTA或接近SOTA:
| 86.6% | ||||
| 80.4% | ||||
| 70.3% | ||||
| 79.8% | ||||
| 75.9% |
特别值得注意:
• LongVideoBench(79.8%):支持超长视频(2000+帧) • LVBench(75.9%):新的全球最高分
第四部分:性能评估——全面领先
1. 推理与通用能力
数学推理:接近满分
| 96.1% | ||||
| 95.4% | ||||
| 86.3% |
AIME 2025是美国数学邀请赛,K2.5达到96.1%,仅次于GPT-5.2的满分。
科学推理与知识
| 87.6% | ||
| 87.1% | ||
工具使用下的HLE表现
Humanity’s Last Exam(人类最后的考试)是最难的综合测试:
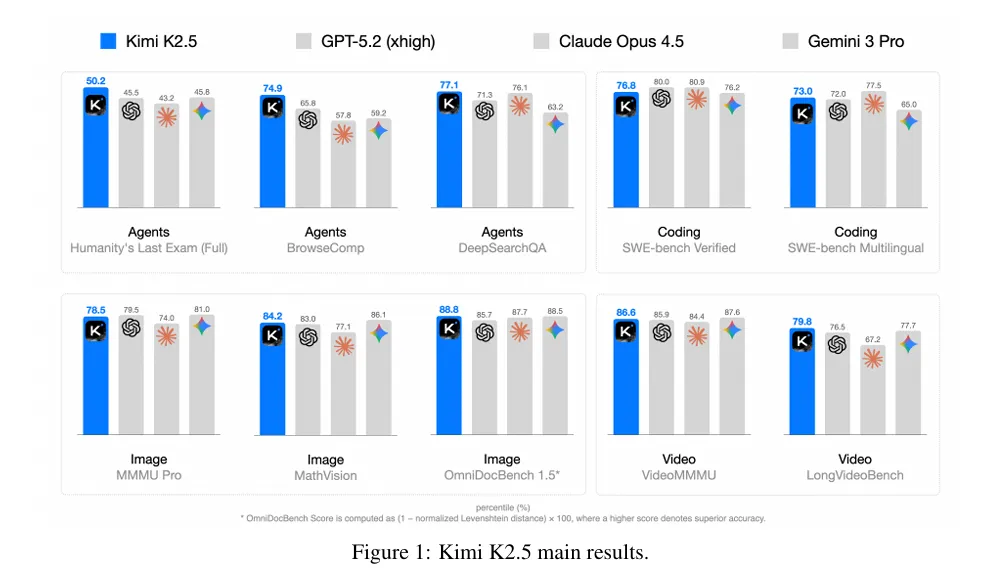
| 50.2% | |||
| 51.8% | |||
| 39.8% |
K2.5在工具使用场景下大幅领先,体现了智能体能力的优势。
2. 编程与软件工程
真实世界软件工程
| 76.8% | ||||
| 73.0% | ||||
| 85.0% | ||||
| 50.6% |
竞赛级编程
3. 智能体能力:绝对领先
这是K2.5最突出的领域:
搜索与浏览任务
| 78.4% | ||||
| 78.4% | ||||
| 79.0% | ||||
| 77.1% | ||||
| 57.4% |
关键发现:
• Agent Swarm加持下,BrowseComp从60.6%提升到78.4%(+17.8%) • WideSearch从72.7%提升到79.0%(+6.3%)
效率提升:3-4.5倍加速
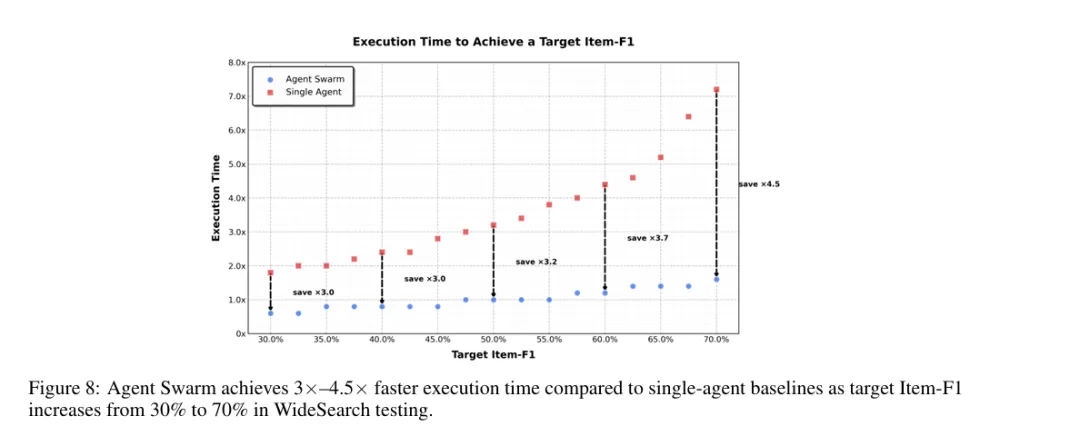
在WideSearch测试中:
• 达到30% Item-F1:单智能体需要1.8×时间,Agent Swarm只需0.6× • 达到70% Item-F1:单智能体需要7.0×时间,Agent Swarm只需1.6×
速度提升随任务复杂度增长而增大!
4. 视觉理解:多维度领先
图像理解
| 78.5% | |||
| 86.1% | |||
| 71.2% | |||
| 47.4% | |||
| 9% | |||
| 11% | |||
| 92.3% | |||
| 88.8% | |||
| 92.6% |
视频理解
| 86.6% | ||
| 80.4% | ||
| 70.4% | ||
| 79.8% | ||
| 75.9% |
5. 计算机使用能力
| 66.3% | ||||
| 63.4% |
K2.5在GUI操作任务上表现出色,大幅领先开源模型,接近Claude Opus 4.5的水平。
第五部分:Token效率优化——Toggle算法
问题:长思考链的低效
大模型的思考需要消耗大量token:
• AIME 2025:K2.5平均每题思考25,000 tokens • HMMT 2025:平均27,000 tokens • IMO-AnswerBench:平均36,000 tokens
这带来两个问题:
1. 成本高:每次推理都很昂贵 2. 速度慢:用户等待时间长
Toggle:交替优化算法
核心思想
在两种训练模式之间切换:
Phase 0(预算限制阶段):
- 条件:平均准确率 > λ 或 token数 ≤ budget
- 目标:在预算内解决问题
- 防止:过早牺牲质量追求效率
Phase 1(标准扩展阶段):
- 条件:无限制
- 目标:充分利用计算资源
- 鼓励:深度推理和复杂思考
训练流程
for iteration inrange(total_iterations):
phase = (iteration // m) % 2# 每m次迭代切换一次
if phase == 0: # 预算限制阶段
if mean_accuracy > λ or token_count <= budget:
reward = r(x, y) # 正常奖励
else:
reward = 0# 超预算且准确率低,无奖励
else: # phase == 1,标准扩展阶段
reward = r(x, y) # 始终给奖励
预算估计
预算基于正确响应的分位数:
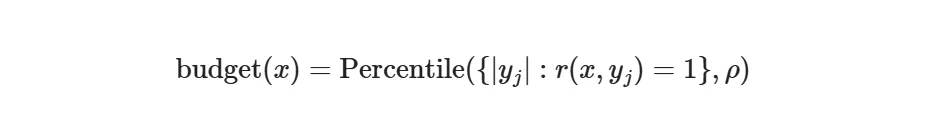
例如:
• ρ = 75:使用正确答案中第75百分位的token数作为预算 • 一次性估计,训练期间固定
实际效果

关键收获:
• ✅ 平均减少25-30% token使用 • ✅ 性能几乎无损(甚至略有提升) • ✅ 跨领域泛化:仅在数学和编程上训练,在GPQA和MMLU-Pro上也有效
第六部分:训练基础设施——大规模工程实践
硬件配置
集群规模:
├── GPU:NVIDIA H800
├── 互连:8×400 Gbps RoCE(RDMA over Converged Ethernet)
└── 节点:32的倍数(灵活扩展)
并行策略:
├── Pipeline Parallelism (PP):16-way,带虚拟阶段
├── Expert Parallelism (EP):16-way
└── Data Parallelism:ZeRO-1
关键技术:DEP(解耦编码器处理)
传统多模态训练的瓶颈
在标准Pipeline Parallelism中:
• 视觉编码器和文本嵌入都在Stage-0 • 问题:视觉输入大小变化(图像数量、分辨率)导致Stage-0负载剧烈波动 • 后果:内存溢出、负载不均衡
K2.5的创新:DEP三阶段执行
阶段1:均衡视觉前向(Balanced Vision Forward)
├── 视觉编码器在所有GPU上复制
├── 根据负载(图像/patch数)均匀分配工作
├── 丢弃中间激活,只保留最终输出
└── 结果gather到PP Stage-0
阶段2:主干训练(Backbone Training)
├── 正常执行Transformer的前向和反向传播
├── 完全复用文本训练的并行策略
└── 梯度累积到视觉编码器输出
阶段3:视觉重计算与反向(Vision Recomputation & Backward)
├── 重新计算视觉编码器前向
├── 执行反向传播计算梯度
└── 更新视觉编码器参数
优势
1. ✅ 负载均衡:视觉处理均匀分布在所有GPU 2. ✅ 策略解耦:主干网络可以完全复用文本训练的优化配置 3. ✅ 内存高效:丢弃中间激活,只在需要时重计算 4. ✅ 效率高:多模态训练达到纯文本训练的90%效率
数据基础设施
存储方案
• 对象存储:使用S3兼容的云存储 • 原生格式:视觉数据保持原始格式(JPEG、PNG等) • 分层缓存:多级缓存提升加载吞吐
数据加载特性
数据管道功能:
├── 动态洗牌(Dynamic Shuffling)
├── 实时混合(Real-time Blending)
├── 在线分词(Online Tokenization)
├── 序列打包(Sequence Packing)
├── 随机增强(Stochastic Augmentation)
└── 完全确定性(Full Determinism)
关键设计:
• 确定性训练:通过严格的随机种子和worker状态管理,保证中断后恢复的数据序列完全一致 • 几何变换:图像增强时保持2D空间坐标和方向元数据的完整性
第七部分:开源与生态
开源内容
Kimi K2.5已在Hugging Face开源:
仓库:moonshotai/Kimi-K2.5
内容:
├── 后训练检查点(Post-trained checkpoints)
├── 模型权重
├── 推理示例代码
└── 评估脚本
不包含:
• ❌ 预训练数据 • ❌ 训练代码 • ❌ SFT和RL数据
使用场景
1. 智能代码助手
传统:逐步生成代码
K2.5:并行搜索文档 + 查看示例 + 生成实现 + 编写测试
2. 自动化测试生成
并行生成:
├── 正常场景测试
├── 边界条件测试
├── 异常场景测试
└── 性能测试
3. 技术调研助手
Agent Swarm并行:
├── 搜索官方文档
├── 查找GitHub示例
├── 阅读技术博客
└── 观看视频教程
→ 汇总成完整调研报告
4. Bug修复
并行操作:
├── 分析错误日志
├── 搜索类似问题
├── 生成修复方案
└── 验证修复效果
与现有产品的关系
第八部分:技术意义与未来展望
技术突破的深层意义
1. 多模态训练的新范式
K2.5证明:
• ✅ 早期融合优于后期融合 • ✅ 文本和视觉可以互相增强 • ✅ Zero-Vision SFT可行且高效
这为未来的多模态模型训练提供了新的方向。
2. 智能体架构的革命
Agent Swarm不仅是性能优化,更是思维方式的转变:
• 从"串行执行"到"并行编排" • 从"单一智能体"到"智能体集群" • 从"固定流程"到"学习调度"
3. 视觉编码的统一
MoonViT-3D证明:
• ✅ 图像和视频可以用同一套参数处理 • ✅ 时空表示可以完全统一 • ✅ 知识可以自然跨模态迁移
当前限制
1. 开源范围
• 仅开源后训练检查点 • 不包含预训练和数据
2. 计算成本
• 训练需要大规模GPU集群 • 推理成本较高(尤其是Agent Swarm模式)
3. Agent Swarm的适用场景
• 最适合可并行化的任务 • 对于纯串行任务,提升有限
未来方向
1. 更高效的并行编排
• 动态子智能体数量调整 • 更智能的任务分解 • 跨任务的知识复用
2. 更长的上下文
• 当前256K已经很长 • 未来可能扩展到百万级别
3. 更强的多模态融合
• 音频模态的加入 • 3D视觉理解 • 多模态生成能力
4. 更广的生态
• 更多领域专门化的子智能体 • 开发者可以自定义子智能体 • 智能体市场和共享机制
结论:智能体时代的里程碑
Kimi K2.5不仅仅是一个新模型,它代表着AI发展的一个重要转折点:
1. 从单模态到原生多模态:不是简单的"加法",而是真正的"融合" 2. 从串行到并行:不是线性提速,而是架构级别的突破 3. 从单兵到集群:不是简单的复制,而是智能的协作
对于开发者来说,K2.5提供了:
• ⚡ 更快的响应速度(Agent Swarm带来3-4.5倍加速) • ? 更高的任务质量(多个基准测试达到SOTA) • ? 更强的工具使用能力(智能体任务大幅领先)
对于研究者来说,K2.5揭示了:
• ? 多模态训练的新范式(早期融合、联合RL) • ? 并行智能体的可行性(PARL、解耦架构) • ? 视觉理解的统一方案(MoonViT-3D)
最重要的是,K2.5是完全开源的。这意味着整个社区都可以在这个基础上继续探索,推动通用智能体(General Agentic Intelligence)的发展。
正如技术报告所言:
“Kimi K2.5 represents a unified architecture for general-purpose agentic intelligence, integrating vision and language, thinking and instant modes, chats and agents.”
这不是终点,而是一个新时代的开始。
参考资料
1. Kimi K2.5 Technical Report - Kimi Team, Moonshot AI, 2025 2. Kimi K2 Technical Report - Kimi Team, Moonshot AI, 2025 3. Kimi K2 Thinking - Moonshot AI, 2025 4. 模型下载:https://huggingface.co/moonshotai/Kimi-K2.5 5. 官方网站:https://moonshotai.github.io/
