



特
别
声
明
《证券期货投资者适当性管理办法》已于2017年7月1日起正式实施。通过新媒体形式制作的本订阅号信息仅面向中原证券客户中的金融机构专业投资者。若您非中原证券客户中的金融机构专业投资者,为保证服务质量、控制投资风险,请取消关注本订阅号,请勿订阅、接受或使用本订阅号中的任何信息。因本订阅号暂时无法设置访问限制,若给您造成不便,烦请谅解!

核心观点
投资要点:
The Information报道,DeepSeek将在2026年2月中旬推出新一代旗舰AI模型 DeepSeek V4,V4编码能力超越Claude和GPT系列。我们认为V4对标预期中在2025年5月发布的R2模型。
2026年1月12日,DeepSeek论文聚焦分配的稀疏化方案,引入了名为“Engram”的条件记忆模块,明显改善了模型性能,成为MOE的重要补充。同时通过对计算与内存的解耦,缓解了当前GPU内存受限的困境,有望大幅缓解国产AI芯片厂商HBM被卡脖子的境况。
2026年1月1日,DeepSeek论文提出了名为mHC的新网络架构,解决信息的流动。mHC架构是建立在此前字节发布的HC基础上,重点改进了ResNet架构信息通道宽度受限、增加的计算冗余和内存占用的问题。在MoE模型上,mHC使得模型训练的收敛速度提升了约1.8倍。
DeepSeek在模型DeepSeek-OCR和DeepSeek-OCR2中,将视觉作为文本压缩媒介的新方法,将文本以图片的方式进行输入,可以极大减少输入所需要的token数量,解决长文本输入问题。
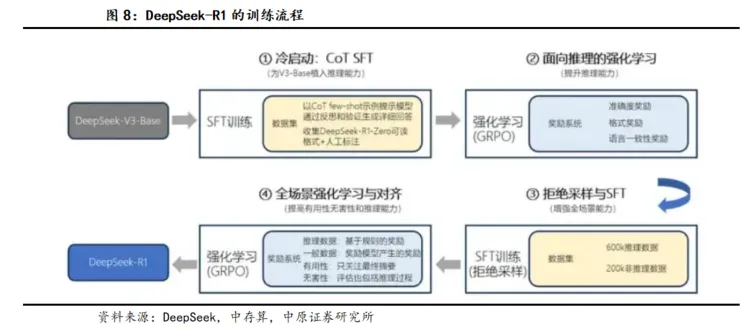
2026年1月4日,DeepSeek更新了R1论文,从22页增加到了86页,让业界对V4的发布充满了更多的期待。根据论文的成本数据,R1的总训练成本为586万美元,远低于顶级模型训练动辄千万美元的门槛,其中预训练和后训练分别占总成本的95%和5%。
结合DeepSeek当前的研究成果,我们给出V4潜在的创新方向的猜想和影响力预测:
(1)模型成本的降低,有望较大缓解地目前国内缺芯的状况。
(2)继续开源路线,同时模型能力超越闭源模型。有望深刻改变海外AI产业的发展格局,利好AI应用的落地。
(3)基于独立于transformer的全新架构。这意味着V4将带来里程碑意义的技术突破,开启大模型发展的新范式,帮助人类更快地通往AGI。
(4)与国产芯片进一步的深度融合,可能部分或全部采用国产芯片进行训练,利好国产算力的生态建设。
风险提示:国际局势的不确定性;海外AI产业竞争格局变化带来市场调整风险。

报告正文
1. DeepSeek最新进展
根据The Information报道,DeepSeek将在2026年2月中旬推出新一代旗舰AI模型 DeepSeek V4,V4编码能力超越Claude和GPT系列。
继2025年春节期间推出DeepSeek-R1以后,预期在2025年5月推出的R2一直是市场关注的焦点,但是R1在5月仅进行一次小版本更新看齐头部模型性能。接着在后续V3.1和V3.2的更新中,DeepSeek不再采取基础模型加推理模型这种模式(V3和R1),而是直接推出两者结合的混合模型,因而V4就已经对标预期中的R2模型。
此前我们在专题报告中分析了DeepSeek在R1之后进行的重要发展动向,包括:
(1)适配国产芯片:2025年8月DeepSeek发布了V3.1,其采用UE8M0 FP8缩放格式训练,面向即将发布的下一代国产芯片而设计。9月DeepSeek发布V3.2-Exp,发布当天华为昇腾和寒武纪宣布完成对其的零日适配,V3.2-Exp还同时开源TileLang和CUDA两个版本的算子,极大地改善了CUDA带来的从英伟达GPU切换到国产芯片的生态壁垒难题(详见《人工智能专题:后R1时代,DeepSeek发展的三大阶段》)。
(2)在新的注意力机制上的研究:包括了在2025年2月在论文《Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention》中提出了原生稀疏注意力(NSA),在2025年9月发布的V3.2-Exp中引入了DeepSeek稀疏注意力机制(DSA),从而将稀疏注意力从推理阶段进一步拓展到了预训练阶段,为模型计算效率的提升、模型上下文的拓展、后训练潜能的释放留下了更多的发展空间(详见《人工智能专题:DeepSeek的稀疏注意力机制给AI产业释放更大的发展潜能》)。
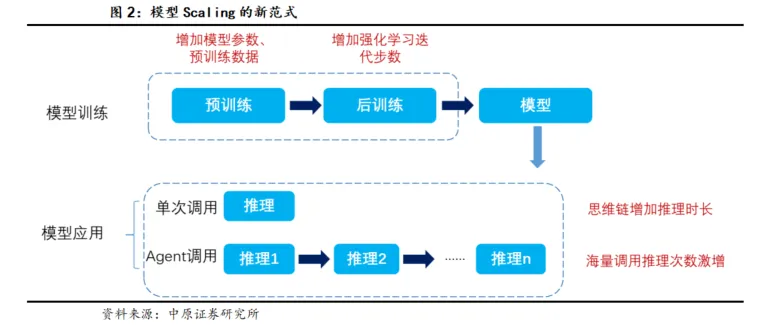
(3)大模型发展路径的探索:2025年12月1日,DeepSeek发布了V3.2和V3.2-Speciale,同时进行了更多关于模型发展路径及Scaling的有效性的探索。V3.2并没有针对测试集的工具进行特殊训练,是真实获得的泛化能力,证明了强化学习有效性。同时在模型训练方面,V3.2验证了扩大后训练强化学习带来的模型能力提升路径(DeepSeek-V3.2把相当于预训练成本10%以上的算力投入在了后训练的强化学习中),同时DeepSeek也计划加大预训练规模来实现模型能力更大的提升。DeepSeek通过在强化学习中使用合成数据,带来了DeepSeek-V3.2在Tau2Bench、MCP-Mark和MCP-Universe基准测试中的性能显著提升,取得了在真实环境中进行强化学习所无法获得的能力,证实了合成数据的发展潜力。(详见《计算机行业月报:手机端AI应用加速,DeepSeek将加大预训练规模》)
下面我们将就DeepSeek后续发布的5篇论文展开技术走向分析,并对V4的潜在影响力进行预测。
2. 稀疏化分配方案的引入,将带来性能提升和计算与内存的解耦
2026年1月12日,DeepSeek发布新论文《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》,聚焦分配的稀疏化方案。
当前主流的大语言模型在面对知识类的问题时,仍然需要动用宝贵的推理资源通过计算来模拟检索过程,造成了大量的资源浪费。考虑到大模型的稀疏性不应该只体现在计算上,还应该体现在分配上,DeepSeek本次提出了“条件记忆”的新机制,并引入了名为“Engram”的条件记忆模块,依靠稀疏查找来检索固定知识的静态嵌入。
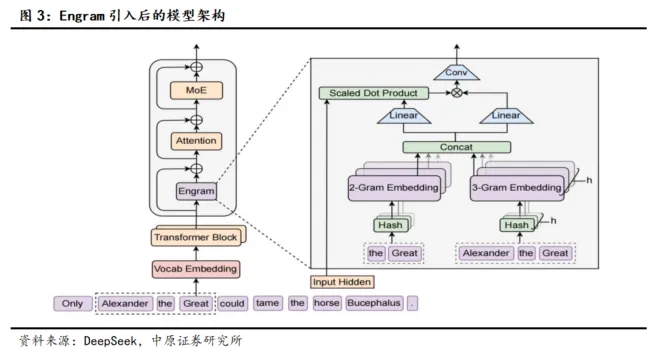
由于Engram是对文本进行哈希映射,映射对象为规模可扩展的静态记忆表,进行常数时间复杂度的知识检索,查找复杂度与模型规模无关,因而达到了稀疏的效果。实验表明,当20%-25%的稀疏参数预算分配给Engram时(剩余部分留给MoE),模型整体性能达到最佳。
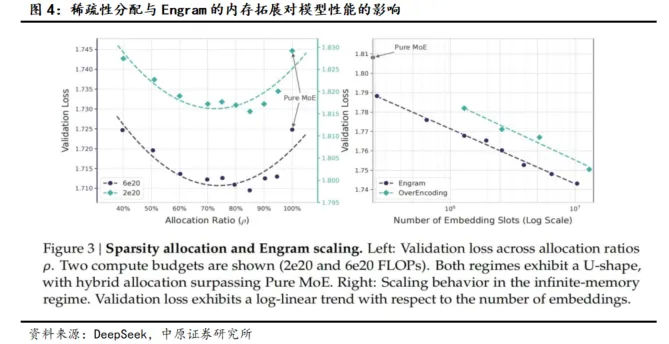
DeepSeek的实验数据研究表明,Engram的引入可以实现更高的效率,成为MoE的理想补充。除了知识密集型任务,Engram的引入还可以使得通用推理、代码、数学问题上获得显著的改进。DeepSeek认为这主要源于Engram减轻了主干网络在早期重构静态知识的负担,从而增加了可用于复杂推理的有效深度。同时,Engram架构还在长文本处理方面展现出了结构性优势,在处理需要极高精度的长文本任务时,具备更强的优越性。
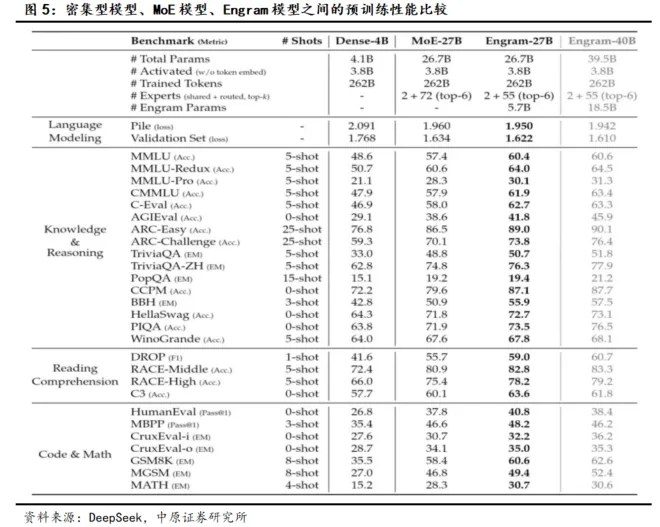
除此以外,Engram引入后,将模型参数表卸载到主机内存并不会带来显著效率损失,因而很大程度上缓解了当前GPU内存受限的困境,为模型参数的进一步提升打开了通道。这意味着Engram实现了计算与内存的解耦,为挂载TB级别的超大规模记忆库提供了可行路径,有望大幅缓解国产AI芯片厂商HBM被卡脖子的境况。
3. 模型层间信息传输方式的底层架构创新
2026年1月1日,DeepSeek发布新论文《mHC: Manifold-Constrained Hyper-Connections》,并提出了名为mHC的新网络架构,解决信息的流动。
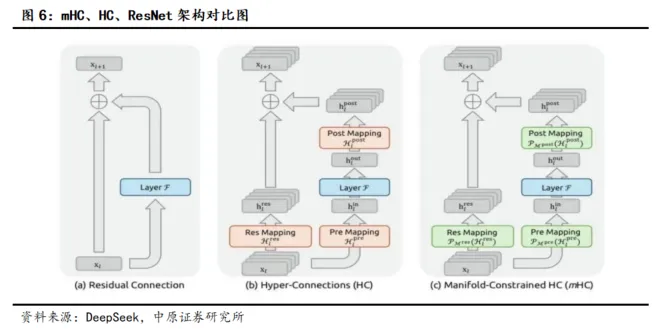
mHC架构是建立在此前字节发布的Hyper-Connections(HC)基础上,重点改进了ResNet架构。
2015年微软亚洲研究院的何恺明等人提出ResNet(残差网络)架构,让信息可以跳过某些层直接传递,解决了此前神经网络越深、训练越困难的问题,让上百层甚至上千层网络成为可能,因而成为了2017年问世的Transformer的底层组件,也是目前AI大模型所使用的主流技术架构。ResNet虽然稳定,但是信息通道宽度受限,增加的计算冗余和内存占用,随着模型参数的增加,模型层数的增长,带来的浪费就更加明显。
2024年9月,字节跳动发表了Hyper-Connections(超连接),提出将单一残差流拓展为多流并行架构,但是HC在提升模型性能的同时,信号被持续地放大,将模型训练变得不稳定。随着模型的增大、层数的增多,HC所展现出来的问题越严重,因而只能用于小模型和理论推演中,在大模型训练中无法有效应用。
为了解决HC的稳定性和可扩展问题,DeepSeek推出了mHC。mHC引入了一种类似“加权平均”的思路,由于凸组合的结果不会超过输入的最大值,保证信号不会被无限放大。试验结果表明在MoE模型上,mHC使得模型训练的收敛速度提升了约1.8倍。
4. 长文本输入:用图像承载文本信息,实现高效压缩
2025年10月20日,DeepSeek发布了新模型DeepSeek-OCR,并发布论文《DeepSeek-OCR:Contexts Optical Compression》,提出将视觉作为文本压缩媒介的新方法。2026年1月27日,DeepSeek又进行了模型升级,开源了模型DeepSeek-OCR2,并发布论文《DeepSeek-OCR 2: Visual Causal Flow》,采用创新的DeepEncoder V2方法。
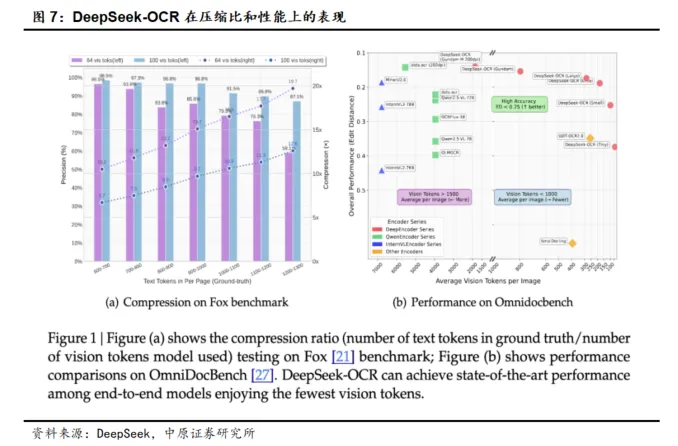
大模型在面对长文本时候,算力需求大幅提升,未解决这一难题,DeepSeek将文本以图片的方式进行输入,可以极大减少输入所需要的token数量。
DeepSeek的实验数据显示,当文本token数在视觉token的10倍以内(即压缩率<10×)时,模型的解码精度可达97%;当压缩率达到20×,解码准确率仍保持在约60%,展现出了非常大的发展潜力。
在DeepSeek-OCR 2中,DeepEncoder V2初步验证了使用语言模型机构作为视觉编码器的潜力,为迈向统一的全模态编码器提供了一个新的发展路径。
5. R1论文从22页更新至86页,更加公开透明
2026年1月4日,DeepSeek更新了R1论文,将论文页数从22页增加到了86页。在新论文中,DeepSeek进一步展示了更多R1训练的相关细节,包括了训练流程、基础设施、消融实验、中间检查点、失败的尝试、R1模型的不足等等。DeepSeek更加公开透明,必然来自于对当前研究成果的自信,因而也让业界对V4的发布充满了更多的期待。
继此前披露了DeepSeek-V3的训练成本以后,本次论文进一步披露了DeepSeek-R1进行进一步训练的成本为29.4万美元。这意味着R1的总训练成本为586万美元,远低于顶级模型训练动辄千万美元的门槛,其中预训练和后训练分别占总成本的95%和5%。
6. V4的潜在创新猜想和影响力预测
结合DeepSeek当前的研究成果,我们给出V4潜在的创新方向的猜想和影响力预测:
(1)模型成本的降低。
DeepSeek在2026年新发布的论文中公开的Engram架构和mHC都有望较大改善模型的成本,因而对于新模型来说,成本有望大幅降低,有望较大地缓解目前国内缺芯的状况。
(2)继续开源路线,同时模型能力超越闭源模型。
以DeepSeek目前的行事风格来看,其仍然是开源路线最坚定的拥护者,有望继续开源路线。目前,国产厂商主要坚持开源路线,且模型性能较海外还有一定落后,但是成本控制上优势较为明显。我们认为V4如果能够实现能力较大超越,将对海外闭源模型厂商,特别是以OpenAI、Anthropic为代表的仅专注于大模型赛道的厂商形成较大的盈利冲击,并有望深刻改变海外AI产业的发展格局。
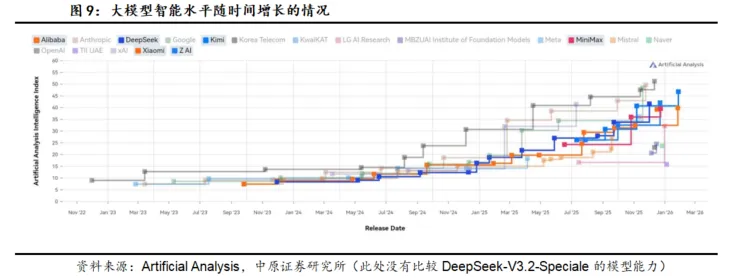
V4如果继续采用开源,其模型能力的提升将给下游AI应用厂商带来更大的助力,利好AI应用的落地。
(3)基于独立于transformer的全新架构。这意味着V4将带来里程碑意义的技术突破,开启大模型发展的新范式,帮助人类更快地通往AGI。
2026年1月20日,DeepSeek在更新的FlashMLA代码库中,意外曝光了名为Model 1的新模型,还拥有了于DeepSeek-V3.2并列的独立文件。从DeepSeek的命名体系来看,Model 1属于全新的模型体系,这或许意味着市场预期中的V4将采用全新的技术路径或基础架构。
(4)与国产芯片进一步的深度融合,可能部分或全部采用国产芯片进行训练。
考虑到2025年DeepSeek也已经实现与国产芯片的协同优化,2026年DeepSeek也有望在国产适配方面获得更多的进展,利好国产算力的生态建设。
7. 风险提示
国际局势的不确定性;海外AI产业竞争格局变化带来市场调整风险。

免
责
声
明
证券分析师承诺:
本报告署名分析师具有中国证券业协会授予的证券分析师执业资格,本人任职符合监管机构相关合规要求。本人基于认真审慎的职业态度、专业严谨的研究方法与分析逻辑,独立、客观的制作本报告。本报告准确的反映了本人的研究观点,本人对报告内容和观点负责,保证报告信息来源合法合规。
重要声明:
中原证券股份有限公司具备证券投资咨询业务资格。本报告由中原证券股份有限公司(以下简称“本公司”)制作并仅向本公司客户发布,本公司不会因任何机构或个人接收到本报告而视其为本公司的当然客户。
本报告中的信息均来源于已公开的资料,本公司对这些信息的准确性及完整性不作任何保证,也不保证所含的信息不会发生任何变更。本报告中的推测、预测、评估、建议均为报告发布日的判断,本报告中的证券或投资标的价格、价值及投资带来的收益可能会波动,过往的业绩表现也不应当作为未来证券或投资标的表现的依据和担保。报告中的信息或所表达的意见并不构成所述证券买卖的出价或征价。本报告所含观点和建议并未考虑投资者的具体投资目标、财务状况以及特殊需求,任何时候不应视为对特定投资者关于特定证券或投资标的的推荐。
本报告具有专业性,仅供专业投资者和合格投资者参考。根据《证券期货投资者适当性管理办法》相关规定,本报告作为资讯类服务属于低风险(R1)等级,普通投资者应在投资顾问指导下谨慎使用。
本报告版权归本公司所有,未经本公司书面授权,任何机构、个人不得刊载、转发本报告或本报告任何部分,不得以任何侵犯本公司版权的其他方式使用。未经授权的刊载、转发,本公司不承担任何刊载、转发责任。获得本公司书面授权的刊载、转发、引用,须在本公司允许的范围内使用,并注明报告出处、发布人、发布日期,提示使用本报告的风险。
若本公司客户(以下简称“该客户”)向第三方发送本报告,则由该客户独自为其发送行为负责,提醒通过该种途径获得本报告的投资者注意,本公司不对通过该种途径获得本报告所引起的任何损失承担任何责任。
特别声明:
在合法合规的前提下,本公司及其所属关联机构可能会持有报告中提到的公司所发行的证券头寸并进行交易,还可能为这些公司提供或争取提供投资银行、财务顾问等各种服务。本公司资产管理部门、自营部门以及其他投资业务部门可能独立做出与本报告意见或者建议不一致的投资决策。投资者应当考虑到潜在的利益冲突,勿将本报告作为投资或者其他决定的唯一信赖依据。