


法务团队最近总在崩溃。
他们上线了一套 RAG(检索增强生成)系统,专门用来检索几百份采购合同。
有人问"违约金比例是多少",系统斩钉截铁地甩出一个数字。
核对原文才发现,这个数字压根不属于这份合同,它本该属于另一个条款,却被从句子中间齐刷刷切断,又和别的碎片拼成了一个"看起来很完整"的答案。
财务部门更惨。
一次现金流问答,RAG 把资产负债表里"流动资产合计"那一行从数字中间切开,后半截混进了下一个知识块。
AI 捧着半张表格,一本正经地算出一个错误的总资产,还振振有词地说了出来。
技术团队排查了整整两周。
换了 embedding(嵌入)模型,没用。加了 reranker(重排序器),没用。把向量数据库从一个牌子换成另一个牌子,还是没用。
没有人怀疑过最开始、几乎没人在意的那一步:把文档切成一个个小块,chunking(切块)。
所有人都心照不宣地跳过了这一步
2026年7月1日,一条推文把这件事捅到了台前。
发帖人是 @bigaiguy(Spencer Baggins),开篇就是暴击:
"RAG's dirty secret: everyone's using the wrong chunking method for their documents. Ekimetrics just proved it with actual numbers."
「RAG 的脏秘密:每个人都在为自己的文档使用错误的切块方法。Ekimetrics 刚刚用实打实的数字证明了这一点。」
他接着写道:
"Every RAG pipeline picks one chunking strategy and applies it to every document. Recursive splitter for everything. Or page splitting for everything. Nobody tests whether that strategy actually fits the document in front of them."
「每一套 RAG 管道都只选一种切块策略,然后用它处理所有文档,要么递归分割器包打天下,要么按页切分了事。没人会去测试,这套策略到底适不适合眼前这份文档。」
他引用的,是 Ekimetrics 团队的新论文《Adaptive Chunking: Optimizing Chunking-Method Selection for RAG》,刚被 LREC 2026 接收。
论文用 33 份真实文档、跨技术/法律/可持续发展三个领域、总计约 118 万 token 的实验证明:不存在一种放之四海而皆准的切块方法,最优策略因文档而异。
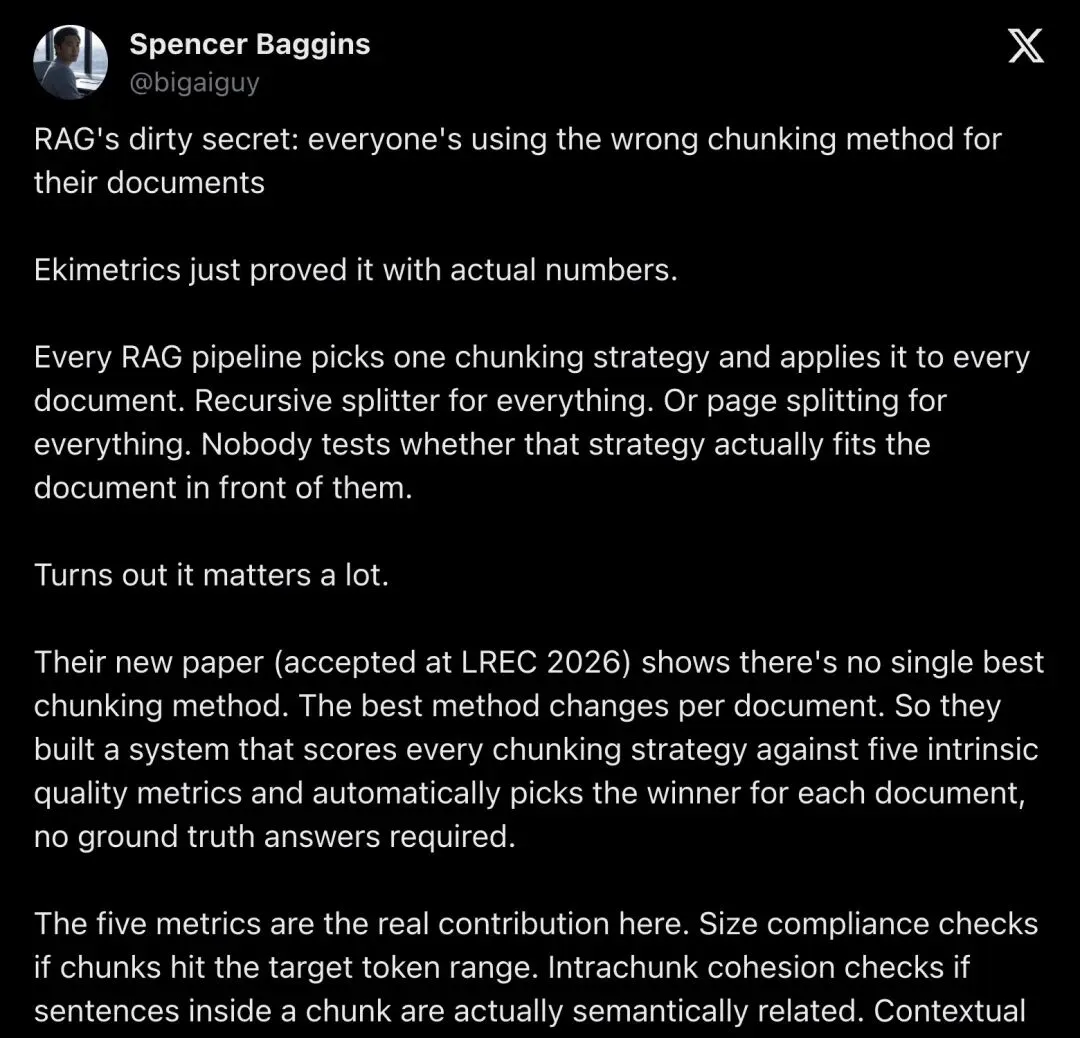


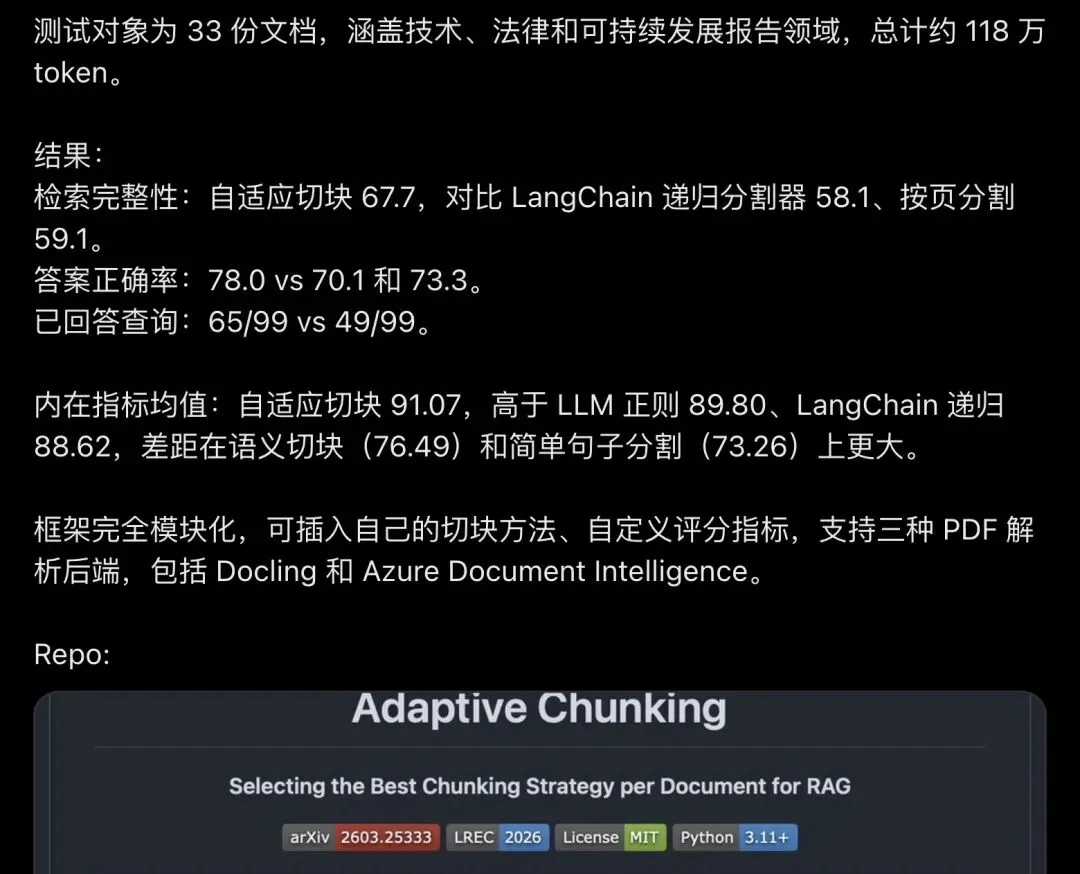
▲ @bigaiguy 的推文详细列出了五大指标和实验数字,是这场"揭秘"的起点。
这条推文戳中的问题,几乎每一个做过 RAG 的工程师都遇到过,只是很少有人往切块这个方向去想。
切错一步,AI 吃到的就是错误答案
要理解这个"脏秘密"为什么致命,得先明白切块在 RAG 里扮演什么角色。
RAG 的标准流程分三步:索引(把文档切块、向量化、存进数据库)、检索(根据问题找最相关的块)、生成(把检索到的内容喂给大模型作答)。
即便是支持 128k、200k token 的模型,把一整份 50 页报告塞进上下文窗口也行不通。
模型会"lost in the middle"(迷失在中间),对中间信息的关注度大幅下降;语义被压缩成一个向量后,具体细节全被磨平;每次检索都带着超长上下文,延迟和费用一起飙升。
切块的意义,就是把长文档变成一串语义自洽、粒度合适的小单元,让检索精准命中,也让大模型拿到的上下文既完整又不冗余。
可一旦切坏了,代价立刻显现。
把表格从中间切两半,检索只拿到半张表,模型算错数字。
把"如上文所述的合同条款"和条款本身拆到两个块里,指代链断裂,模型搞不懂"上文"指的到底是什么。
用 200 token 的细粒度切法处理法律合同,条款完整性荡然无存。用 2000 token 的大块处理产品说明书,噪音淹没细节,具体参数根本查不到。
Weaviate 在自己的技术长文里这样写道:
"In production LLM RAG pipelines, chunking is not just a preprocessing step , it defines the quality of retrieval and the effectiveness of agent memory."
「在生产级 LLM RAG 管道里,切块从来就不只是一个预处理步骤,它直接决定了检索质量和 agent 记忆的有效性。」
Chroma 的研究给出过一个数字:不同切块策略之间的召回率差距,最高能到 9 个百分点。这背后是实打实的检索命中率差距。
七种切法,没有一种是万能药
问题是,市面上从来不缺切块方法,缺的是知道该用哪一种的判断力。
固定大小切块:按 512 token 或 1000 字符直接切,简单快,但完全不管语义,经常在句子中间、表格中间贸然切下去,只适合原型验证。
递归字符分割(RecursiveCharacterTextSplitter):LangChain 的事实标准,按段落、句子、空格、字符的优先级依次尝试,尽量保住语义单元的完整性。它是目前绝大多数团队默认在用的那套方法。
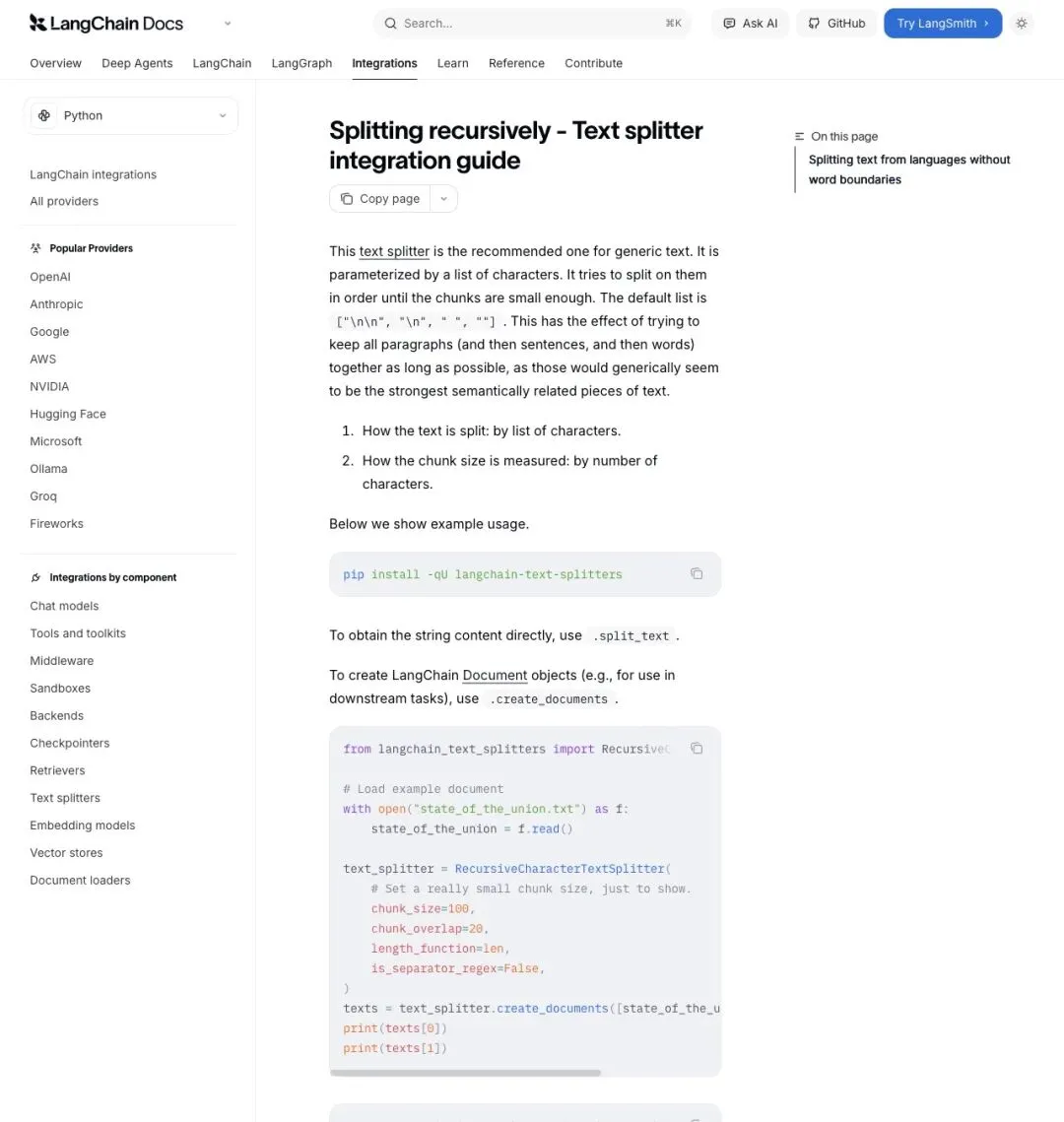
▲ LangChain 官方文档:递归分割器是"推荐用于通用文本"的默认选择,几乎是行业标配,代码示例直接摆在文档首页。
但默认不等于最优。同一组参数,放到法律合同和技术报告上,表现可能天差地别。
结构感知切块:靠 Markdown 标题、HTML 标签、代码函数定义等天然边界切分,对结构化文档很强,碰上纯文本或扫描版 PDF 就抓瞎。
按页切块:把每一页当作一个块,专治 PDF。NVIDIA 2024 年的基准测试里,这种方法准确率最高、方差最低,完美保留页内表格和图表布局,前提是这份 PDF 真的按有意义的方式分页。
语义切块:先把文档拆成句子分别做 embedding,算相邻句子的相似度,相似度骤降的地方就是切点。理论上能发现结构方法看不见的主题切换,但成本高,调参敏感,有基准测出它切出的碎片平均只有 43 token,准确率反而掉到 54%。
LLM-based / Agentic 切块:直接让大模型自己读文档、自己决定切点,质量能到天花板,但每份文档要调用多次大模型,贵、慢,只适合小规模高价值场景。
Late Chunking(晚切块):反过来做,先用长上下文 embedding 模型跑完整篇文档,拿到已经"读过全文"的 token 级向量,再切块、再池化。块与块之间的指代和上下文关系因此被保留下来,Jina AI 提出的这个思路,在跨引用密集的文档上效果明显。
▲ Weaviate 的技术长文把七八种策略摆在一起对比,还给出了详细的选择决策表,作者是团队增长负责人 Femke Plantinga 和机器学习工程师 Victoria Slocum。
Weaviate、Firecrawl、LightOn、Ekimetrics,还有 Reddit 上一票被现实毒打过的工程师,说法出奇一致:法律文件和产品手册喜欢大块加语义边界,发票收据喜欢小块加元数据,按页切块在报告类文档上经常"无敌"。
没有一种切法能通吃所有场景。真正该问的问题,从来都是具体的:对这份文档,哪个切块器最好?
光知道要因文档而异没用。谁来判断、怎么判断,才是真正的难题。
一篇论文,把「没有银弹」做成了实锤
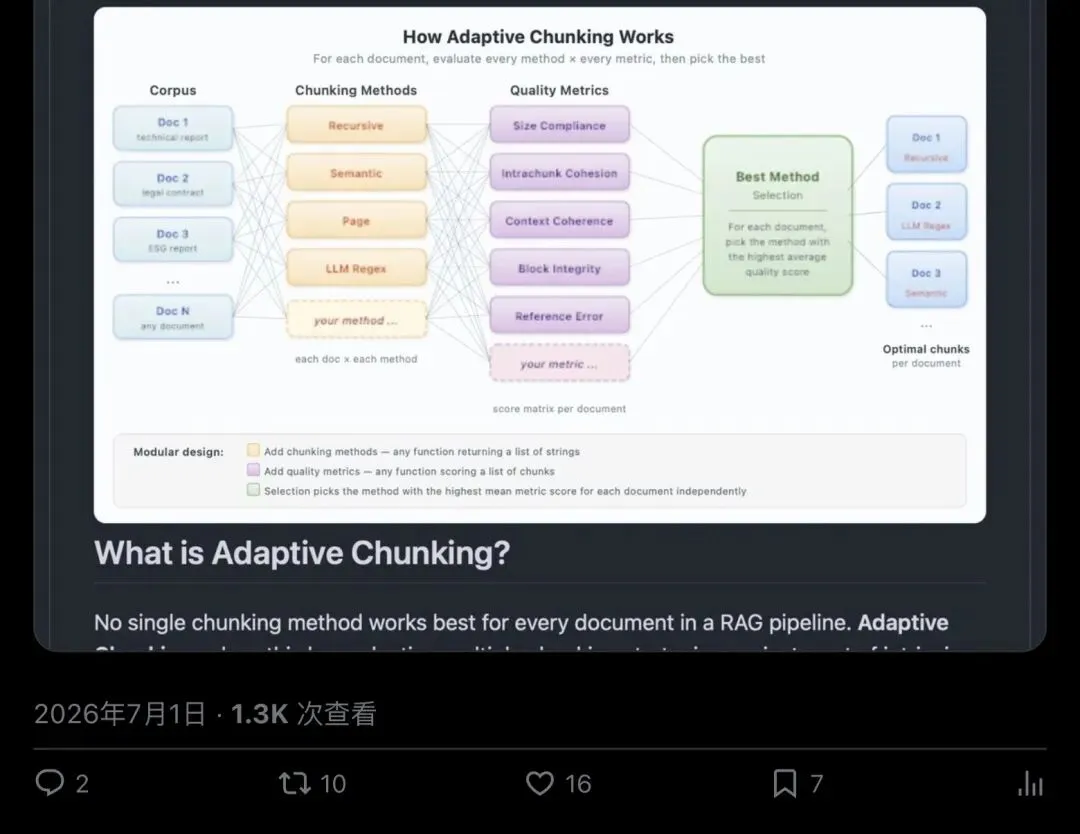
Ekimetrics 团队没有再发明一种新切法,他们造的是一套自动选切法的系统。
论文摘要开门见山:
"Yet, commonly used 'one-size-fits-all' approaches often fail to capture the nuanced structure and semantics of diverse texts. Despite its central role, chunking lacks a dedicated evaluation framework."
「然而,常见的"千篇一律"式方法,往往无法捕捉不同文本之间微妙的结构和语义差异。尽管切块在 RAG 中扮演核心角色,它却始终缺少一套专门的评估框架。」
▲ arXiv 论文摘要页:作者 Paulo Roberto de Moura Júnior、Jean Lelong、Annabelle Blangero,2026年3月26日提交,已被 LREC 2026 接收。
论文提出的核心思路是:对同一份文档,同时跑多种候选切块策略,再用五项完全不需要人工标注、不需要下游 RAG 评测的"内在指标"给每种结果打分,自动选出赢家。
Size Compliance(尺寸合规性):块的 token 数是否落在目标区间。太小丢上下文,太大稀释精度、推高成本。
Intrachunk Cohesion(块内聚合度):块里每句话和整块的语义相似度,衡量这个块内容是否在讲同一件事。
Document Contextual Coherence(文档上下文连贯性):这个块放回前后文窗口里,还像不像原文档的一部分。
Block Integrity(结构块完整性):段落、表格、列表这些结构单元有没有被完整保留,财务报告里的"合并资产负债表"如果被强行切断,这项指标会第一时间亮红灯。
Filtered Missing Reference Error(过滤后的指代缺失错误):核心指代链有没有被切块动作生生拆散。法律合同里那些"如前所述""见第3.2条",全靠这项指标兜底。
GitHub 仓库首页开篇,就把结论摆在明面上:
"No single chunking method works best for every document in a RAG pipeline."
「在一个 RAG 管道里,没有哪一种切块方法能对所有文档都是最佳选择。」
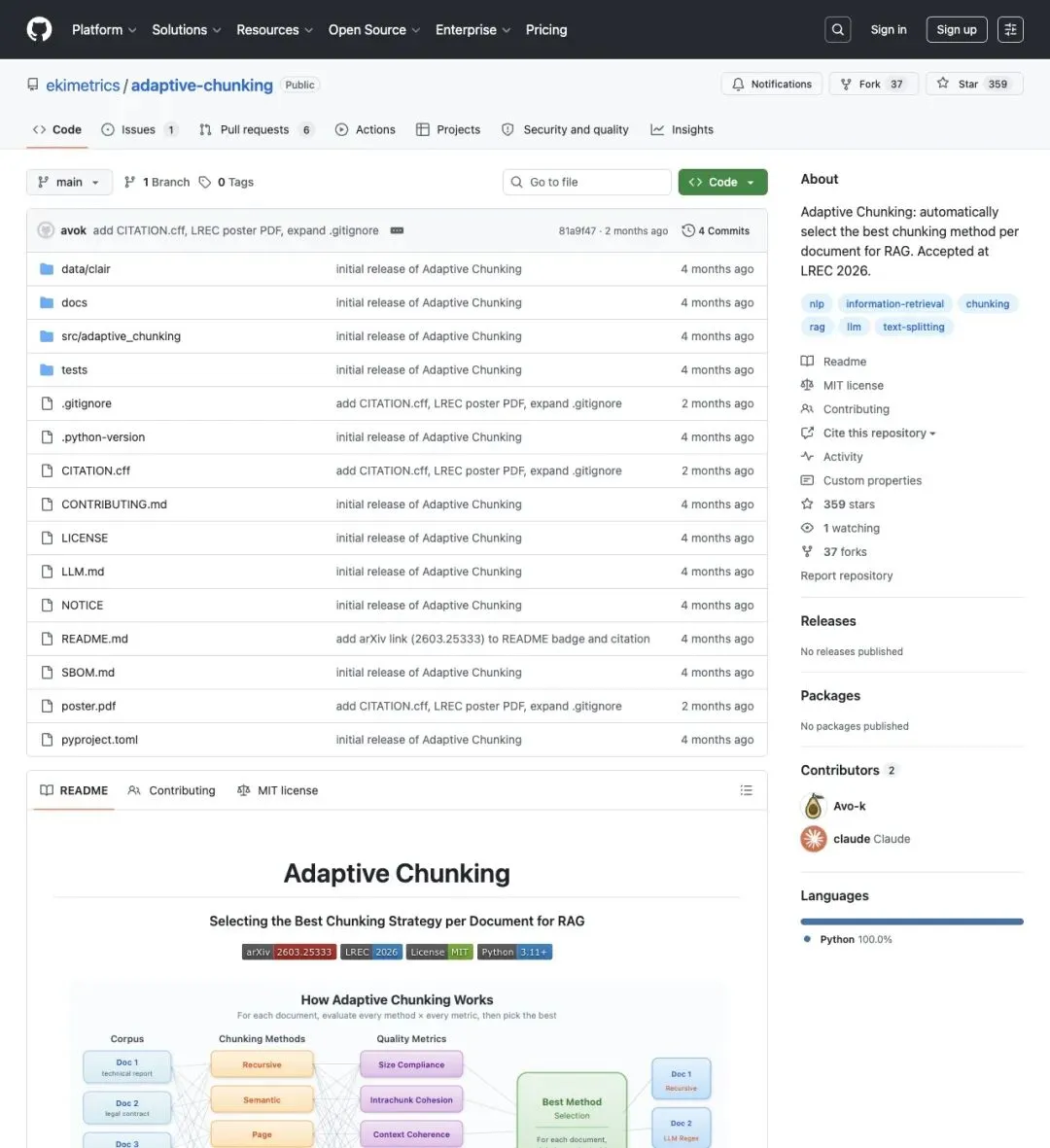
▲ GitHub 仓库 ekimetrics/adaptive-chunking:359 星、37 次 fork,架构图清楚画出"每份文档 × 每种切法 × 每项指标 → 选出最优"的完整流程,代码和 33 份测试文档全部开源可复现。
有意思的是,这个仓库的贡献者列表里,除了两位人类作者,还挂着一个叫 "claude" 的账号。
AI 参与写"帮 AI 更好读文档"的代码,这事儿本身就很有 2026 年的味道。
这套框架真正的价值,是把"该用哪种切法"这个问题,从工程师的直觉判断,变成了一套可以自动运行、可以量化、可以放进生产管道实时跑的决策系统。
数字不会说谎
理论讲得再漂亮,最后还是要看数字。
在 33 份文档、三个领域的测试里(Wilcoxon 检验 p < 0.05,统计显著):
检索完整性:自适应切块 67.7分,对比 LangChain 递归分割器 58.1 分,按页切块 59.1 分。
答案正确率:自适应 78.0分,对比 70.1 分和 73.3 分。
成功回答的查询数:自适应 65/99,两个基线方法都只有 49/99,同样的 99 道题,自适应切块多答对了 16 道。
同一套 embedding 模型,同一个检索器,同一个大模型,同一套 prompt,唯一变化的只有切块方式,回答质量的提升就已经摆在那里。
内在指标上的差距同样明显:自适应切块均值 91.07,LLM regex 切块 89.80,LangChain 递归分割器 88.62,语义切块跌到 76.49,纯句子切分只有 73.26(p < 0.001)。
▲ Firecrawl 的 2026 年总结文章,汇总了 NVIDIA、Chroma、临床研究等多份独立基准,彼此互不相关,却指向同一个结论。
这背后站着好几个互不相关的独立信源。
NVIDIA 2024 年的基准测试里,按页切块在多数数据集上准确率达到 0.648,方差最低。
Chroma Research 发现,LLM 增强的语义切块能冲到 0.919 的召回率,但代价是要给每句话都做一次 embedding,成本飙升。
一项发表在 MDPI Bioengineering 上的临床决策支持研究里,自适应加逻辑主题边界的方法准确率 87%,固定大小切块只有 13%(p=0.001)。这个差距已经跨过了"优化"的范畴,直接决定"能用"还是"不能用"。
Vecta 2026 测试了 50 篇学术论文,512 token 的递归切块拿下 69% 正确率,语义切块反而因为碎片化严重只有 54%。
基准结果也没有全部一边倒。NAACL 2025 的一项研究发现,在某些设置下,固定 200 词的简单切块表现和语义切块相当,成本却低得多,这恰恰印证了论文的核心主张:没有永远的赢家,只有适不适合眼前这份文档。
Reddit r/Rag 上工程师们的总结更干脆:法律文件喜欢大块,发票收据喜欢小块加元数据,没有一个独立信源敢说"用我的方法就永远赢"。
技术洁癖之外,是真金白银的账
前面这些还只是准确率层面的差距,LightOn 的技术博客把账算到了钱上。
标题就毫不拐弯:
"Adaptive Chunking: Reasoning Starts Before the LLM Sees a Token"
「自适应切块:推理,从大模型看到第一个 token 之前就已经开始。」
▲ LightOn 博客把切块问题上升到"生产级 RAG 系统的文档感知式切块选择",2026年5月19日发布。
文章里有一段话戳得很准:
"Pipelines inherit the structure of the chunks they index. A broken table becomes a broken embedding. Fragmented references become fragmented retrieval. Oversized chunks dilute semantic precision. Aggressive splitting destroys context."
「管道会继承它索引进去的那些块的结构:一张被切坏的表格,会变成一个被切坏的向量;断裂的指代,会变成断裂的检索;过大的块稀释语义精度;过度激进的切分则直接摧毁上下文。」
这条逻辑链条一旦启动就停不下来。
切坏的上下文喂给大模型,模型没法一次得到干净答案,于是需要更多轮对话、更多次检索去补偿。到了 agent 场景,这种补偿会在多轮循环里滚雪球,每一轮都在为上游那次切分的失误买单。
LightOn 的态度很明确:解决办法不靠换一个更贵的大模型,靠的是让大模型第一次看到上下文时,那份上下文就已经是干净的。
这也是为什么 Ekimetrics 特意把五个指标都设计成"内在指标",不需要人工标注问答对,不需要跑一遍完整的下游检索评测,可以直接嵌进索引阶段实时运行,成本可控,"自适应"才不会变成另一个吞钱的黑洞。
现在就能做的三件事
看到这里,大部分人的第一反应可能是:这套框架挺好,但不可能现在就重写整条 RAG 管道。
好消息是,不需要。
第一步,先检查解析质量。
如果 PDF 转文本这一步就已经把页眉页脚、OCR 错字、HTML 残留一起塞了进去,后面用什么切块策略都是在给垃圾"整容"。Docling、Firecrawl、Unstructured 这些工具能先把文档转成干净的结构化文本。
第二步,对自己的真实语料,至少跑两三种策略做对比,而不要打开项目模板里写好的那个 splitter 就直接上生产:
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=80,
separators=["\n\n", "\n", "。", ",", " ", ""]
)
chunks = splitter.split_text(long_document)
Firecrawl 的建议是,大多数场景从 400-512 token、10-20% overlap 的递归切块开始。但起点不等于终点,PDF 报告加一组按页切块做对照,法律合同加一组更大 chunk size 或语义边界做对照。
第三步,建一个哪怕只有 20-50 条查询的小规模测试集,实测 recall、precision、答案正确率,用数据说话。如果资源允许,可以直接试试 Ekimetrics 开源的框架,让它自动跑多种候选、打分选优:
from adaptive_chunking import chunk_files
chunks = chunk_files("path/to/pdfs/", chunk_size=800, parser="docling")
# 内部自动跑多种策略、五项指标打分,为每份文档选出最优切法
别忘了几个最容易踩的坑:表格、代码、JSON 不能直接套用纯文本 splitter;15% 左右的 overlap 常常能救回被切断的指代链;reranker 救不了烂切块,它只能在候选池子里挑相对好的,没法凭空补出根本不存在的上下文。
尾声
回到开头那两个崩溃的团队。
法务的合同问答系统,后来换成了大块加语义边界的切法,条款不再被腰斩,指代链完整保留。
财务的财报问答,换成了按页切块,表格不再横切两半,总资产终于算对了。
模型没换,reranker 没加,向量数据库也没换。
改的只是最开始那一步该怎么走。
Ekimetrics 的论文、Weaviate 和 Firecrawl 的系统性总结、NVIDIA 和 Chroma 的独立基准,还有无数工程师在 Reddit 和 GitHub 上留下的经验,指向的都是同一件事:停止对所有文档使用同一种切块策略,开始测量、比较,为不同的文档找到不同的答案。
下一次你的 RAG 又开始胡言乱语、召回率死活上不去、agent 烧着 token 在原地打转的时候,或许该先问自己一句。
这份文档,真的应该用你一直在用的那种切法吗?
答案,往往就藏在最初动手切的那个决定里。