


摘要
本报告整理了我们在 modular division 任务上完成的 grokking 复现实验和相图分析。第一部分复现 arXiv:2201.02177v1 Figure 1 的核心现象:模型先快速记忆训练集,随后在长时间训练后突然获得验证集泛化能力。第二部分借鉴 arXiv:2205.10343v2 Figure 6 的相图方法,在同一 mod_division, p=97 体系上扫描 decoder learning rate 和 decoder weight decay,把每个超参数格点归入 memorization、grokking、comprehension 或 confusion 四类 phase。
核心结论是:在无 weight decay 或弱正则区域,模型多表现为先记忆而不及时泛化;中等 decoder weight decay 形成宽的 grokking 带;过强 weight decay 会让训练本身也无法达标,进入 confusion;在 decoder_weight_decay=1, decoder_lr=3e-3 处出现一个 comprehension 格点,即训练和验证几乎同步达标。
研究问题
我们关心两个层次的问题:
在真实训练日志中,modular division transformer 是否能复现经典 grokking 动力学。
在同一体系上,学习率和 weight decay 如何改变模型最终落入的 phase。
第一张关键图回答时间动力学问题,第二张关键图回答超参数空间结构问题。
实验体系
任务为模 97 除法:
x / y mod 97, 其中 0 <= x < 97, 0 < y < 97
总样本数为 97 * 96 = 9312,训练集比例为 0.5。输入 token 为 [x, op, y, =],模型预测 x / y mod 97。
模型为 2 层 decoder-only causal transformer:
| 参数 | 值 |
|---|---|
d_model | 128 |
n_heads | 4 |
n_layers | 2 |
d_mlp | 512 |
train_fraction | 0.5 |
seed | 0 |
Figure 1 复现实验使用 Adam,lr=1e-3,无 weight decay,训练到 1_000_000 steps。相图实验使用分组优化器:embedding 作为 representation,decoder 部分扫描 learning rate 和 weight decay。
关键图 1:完整 grokking 动力学
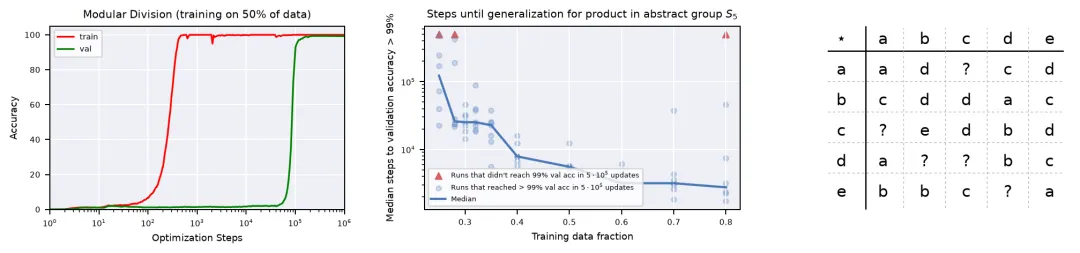
左图是本报告后续相图分析的基础。它显示在 mod_division, p=97 上,训练准确率先快速上升,验证准确率长时间停留在随机附近,随后在约 10^5 steps 附近跃升。这正是 grokking 的典型时间结构:模型先记忆训练集,再经过很长延迟后学到可泛化规则。
从真实日志的关键数值如下:
| 指标 | step | accuracy |
|---|---|---|
| 训练准确率首次超过 90% | 393 | 0.9296 |
| 验证准确率首次超过 90% | 100893 | 0.9302 |
| 训练准确率首次超过 99% | 461 | 0.9953 |
| 验证准确率首次超过 99% | 163063 | 0.9903 |
| 最终训练准确率 | 1000000 | 1.0000 |
| 最终验证准确率 | 1000000 | 0.9923 |
按 90% 阈值计算,训练达标和验证达标之间相隔 100500 steps。这个延迟说明模型的“记忆阶段”和“泛化阶段”在时间上明显分离。
相图判据
相图采用 arXiv:2205.10343v2 Figure 6 的口径。阈值、截止步数和延迟线为:
threshold = 0.9deadline_steps = 100000delay_steps = 1000
phase 定义如下:
| phase | 判据 |
|---|---|
comprehension | 训练和验证都在 deadline 内超过阈值,且验证达标比训练达标晚不到 delay_steps |
grokking | 训练和验证都在 deadline 内超过阈值,但验证明显滞后 |
memorization | 训练在 deadline 内超过阈值,验证没有 |
confusion | 训练在 deadline 内也没有超过阈值 |
我们扫描的范围为:
decoder learning rate: 1e-5, 3e-5, 1e-4, 3e-4, 1e-3, 3e-3, 1e-2decoder weight decay: 0, 0.03, 0.1, 0.3, 1, 3, 10, 20
关键图 2:扩展相图
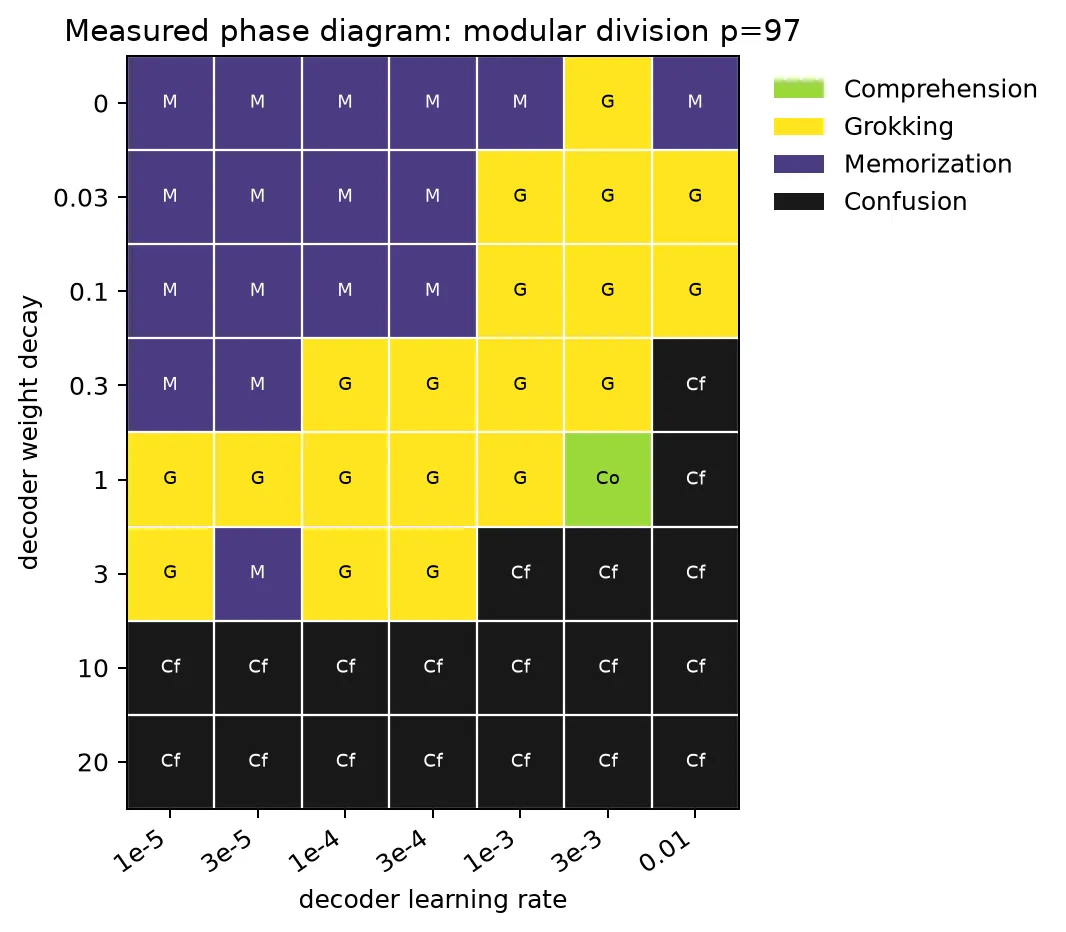
这张图来自完整相图输出,56 个格点的 phase 计数为:
| phase | count |
|---|---|
grokking | 19 |
confusion | 19 |
memorization | 17 |
comprehension | 1 |
完整网格如下,其中 Co 表示 comprehension,G 表示 grokking,M 表示 memorization,Cf 表示 confusion。
| decoder weight decay \ decoder lr | 1e-5 | 3e-5 | 1e-4 | 3e-4 | 1e-3 | 3e-3 | 1e-2 |
|---|---|---|---|---|---|---|---|
0 | M | M | M | M | M | G | M |
0.03 | M | M | M | M | G | G | G |
0.1 | M | M | M | M | G | G | G |
0.3 | M | M | G | G | G | G | Cf |
1 | G | G | G | G | G | Co | Cf |
3 | G | M | G | G | Cf | Cf | Cf |
10 | Cf | Cf | Cf | Cf | Cf | Cf | Cf |
20 | Cf | Cf | Cf | Cf | Cf | Cf | Cf |
唯一的 comprehension 格点为:
| decoder lr | decoder weight decay | train 90% step | val 90% step | delay | final val acc |
|---|---|---|---|---|---|
3e-3 | 1 | 342 | 1146 | 804 | 0.9759 |
结果解释
1. Grokking 是中等正则区域的主导现象
在 decoder_weight_decay=0.3 和 1 附近,很多 learning rate 都进入 grokking 或 comprehension。这个区域的共同点是,正则强度足以抑制纯记忆解,但又没有强到破坏训练集拟合。模型仍会先学会训练集,但验证集泛化会在之后补上。
这和 Figure 1 的长时间动力学一致:同一任务可以在某些超参数下表现为延迟泛化,而不是训练失败或单纯记忆。
2. 低 weight decay 更容易停在 memorization
在 weight_decay=0, 0.03, 0.1 的低 learning rate 区域,大多数格点是 memorization。模型能在 deadline 内把训练集拟合到 90% 以上,但验证集没有同步达到 90%。这说明无正则或弱正则时,训练动力学优先找到记忆训练集的解。
一个重要例子是 weight_decay=0, lr=1e-3。它在 100000 step 的相图 deadline 内被判为 memorization,但在 100 万步长实验中最终会 grok。这说明 phase 分类依赖观测窗口:同一训练轨迹在较短窗口中看起来是 memorization,在更长窗口中则显示为 grokking。
3. 过强 weight decay 导致 confusion
当 decoder_weight_decay=10 或 20 时,所有 learning rate 都进入 confusion。此时训练准确率本身也无法在 100000 步内超过 90%。这说明正则不是单调有益的:它可以帮助从记忆解走向泛化解,但过强时会压制模型对训练数据的基本拟合。
4. Learning rate 改变 phase 边界,且不是简单单调
learning rate 提高通常能缩短训练和验证达标时间,但过高时会把系统推入 confusion。例如在 weight_decay=1 下,lr=3e-3 是唯一 comprehension,而 lr=1e-2 直接进入 confusion。相图中的边界因此是二维的,不应只用单个超参数解释。
与论文图的关系
我们的 Figure 1 复现实验对应 arXiv:2201.02177v1 中 grokking 的经典观察:训练准确率先到达高水平,验证准确率在长时间后突然上升。
我们的相图分析借鉴 arXiv:2205.10343v2 Figure 6 的分类框架,但没有照搬其 toy model 设置,而是把同样判据移植到已经复现过 grokking 的 modular division transformer 上。因此,报告中的相图不是论文 Figure 6 的逐像素复刻,而是“在前一篇 Figure 1 体系上的同类 phase 分析”。
局限与后续方向
当前相图是 seed=0 的单 seed 结果。phase 边界附近可能存在随机种子敏感性,后续应对关键边界格点做多 seed 重复,尤其是 weight_decay=0.3 到 3、lr=1e-4 到 1e-2 之间的区域。
第二,phase 分类依赖 deadline_steps=100000。Figure 1 长轨迹已经说明,有些格点如果给到更长预算,会从 memorization 转成 grokking。因此,严格说相图描述的是“在给定观察窗口内的 phase”,不是无限时间极限。
第三,本报告使用 modular division transformer 体系,而 arXiv:2205.10343v2 的 Figure 6 来自其有效理论和相关 toy 设置。要进一步对齐论文,可在 mod_addition 任务上重复同样相图扫描,并比较两种任务的 phase 边界。
结论
我们完成了从单条 grokking 训练曲线到二维 phase diagram 的连贯分析。Figure 1 的长轨迹证明该 modular division transformer 存在典型延迟泛化;扩展相图进一步显示,这种延迟泛化不是孤立现象,而是在中等正则和合适 learning rate 区域形成稳定带状结构。弱正则偏向 memorization,强正则导致 confusion,中间区域则支持 grokking,局部甚至达到 comprehension。
这说明 grokking 在该体系中不仅是时间轴上的突然跃迁,也是超参数空间中可定位、可扫描、可比较的 phase 现象。