这份由中国信通院与中车工业研究院 2026 年 5 月发布的《人工智能模数共振体系研究报告(2026 年)》,聚焦数据与模型双向共振,系统阐释模数共振体系内涵、核心要素、能力支撑、协同机制并给出落地建议,为 AI 与实体经济融合提供指引,核心结论如下:
一、定义与内涵
模数共振本质是高质量数据集、高效能模型、高价值应用的闭环共生体系,核心为以模引数、用数赋模,打破传统 “数据单向供给、模型静态训练” 的断裂模式,构建 “数据滋养模型、模型反哺数据、应用反哺数据积累” 的动态持续进化范式,破解数据质量参差、模型场景适配差、应用落地难等痛点,是培育新质生产力、赋能产业智能化的核心引擎。
二、三大核心要素
高质量数据集:具备高技术含量、高知识密度、高效益场景特征,覆盖制造、医疗、交通等重点行业,突破人工标注瓶颈,融合行业机理与多模态信息,聚焦稀缺长尾场景,为模型提供高价值训练底座。
高效能模型:涵盖基础、行业、场景三级模型,具备高算效比、高泛化性、高鲁棒性,通过轻量化、知识蒸馏等技术适配边缘部署,能应对数据噪声、环境突变等干扰,精准匹配行业专业需求。
高价值应用:深度融入产业全流程,具备场景刚需化、价值可量化、产业深度化特征,锚定行业核心痛点,以效率提升、成本降低等量化价值为导向,推动产业模式重构与业态创新。
三、五大能力支撑
构成 “反馈 - 优化” 闭环,保障体系运转:
数据集设计与构建:拆解模型需求、搭建多源数据体系、制定标准化标注流程、建立全流程质检机制,夯实数据基础。
数据集质量评估:发布可信 AI 数据集质量评估体系 2.0,从完整性、准确性、合规性等维度,覆盖多模态数据与行业场景,实现科学量化测评。
模型微调与优化:设计结构化指令数据、精准调整模型参数、初步测试诊断适配效果,衔接通用预训练与场景化应用。
模型性能基准测试:依托信通院 “方升” 体系 3.0,从基础属性、通用能力、行业能力等维度全面测评,定位性能瓶颈根源。
数据增强与优化:基于模型反馈精准修复数据缺陷、迭代处理规则、建立长效监控机制,实现数据价值动态跃升。
四、三大协同运行机制
保障模数共振高效协同:
模型 - 数据关联映射:从模型类型、任务场景、性能指标三维匹配,实现数据特征与模型能力精准适配,避免数据无效供给。
模数闭环迭代:通过规则、技术、机制三重迭代,推动数据处理标准升级、工具方法革新、组织流程协同,形成螺旋式质量提升闭环。
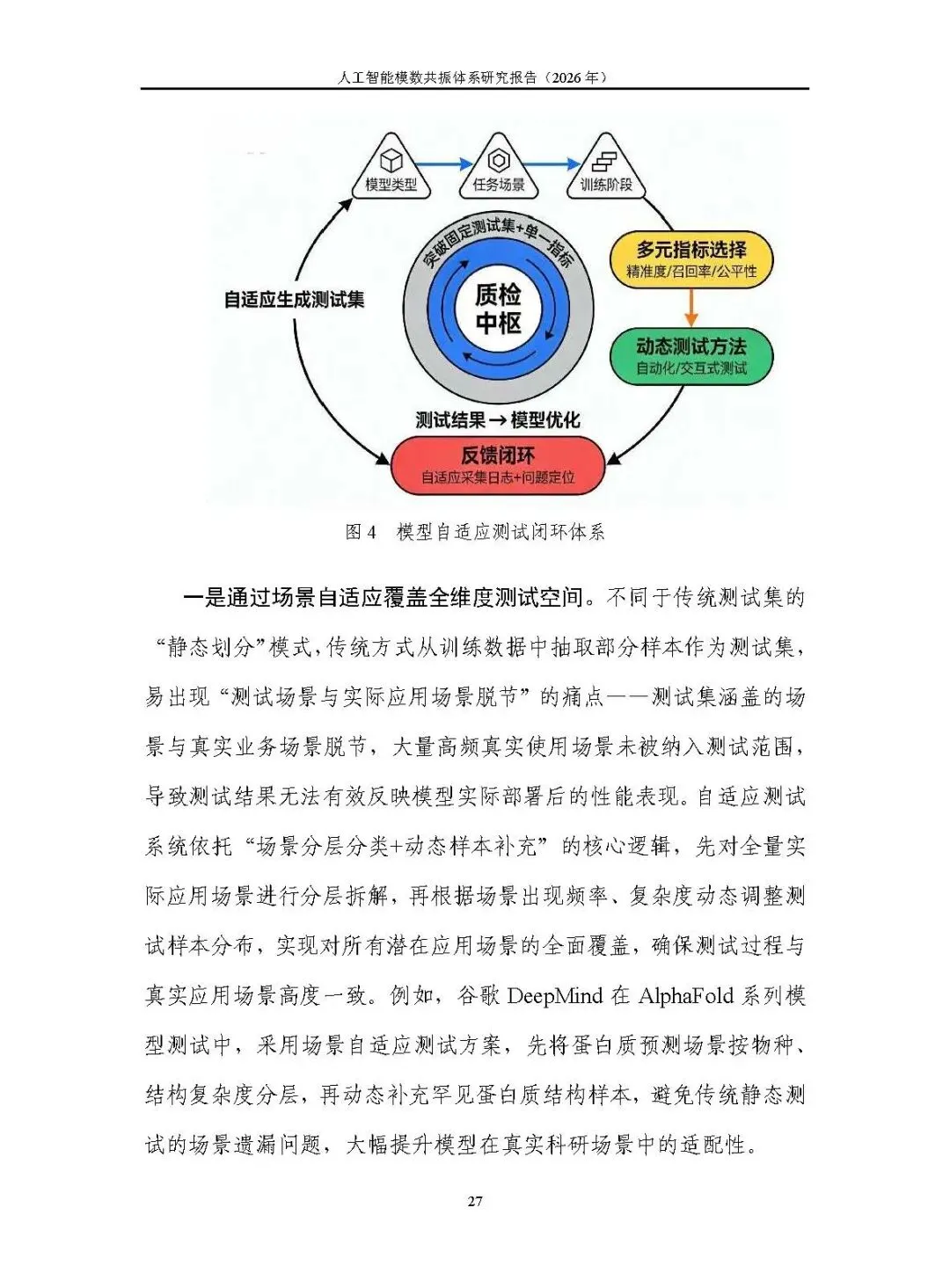
模型自适应测试:实现场景、指标、反馈自适应,覆盖全维度测试空间,精准区分数据与模型问题,反哺针对性优化。
五、落地发展建议
统筹数据与模型建设:分层构建行业通识与专识数据集,联动行业大模型与特色智能体,适配通用与垂直场景需求。
完善评测能力机制:定制行业评测数据集与分级标准,构建 “评测 - 优化 - 提升” 循环,以评测驱动数据与模型双向升级。
构建生态协同机制:打造 “模数共振空间”,建设算力底座与全链条管理机制,破解数据孤岛,推动多元主体协同。
强化关键要素保障:攻关核心技术、制定行业标准、培育复合型人才、搭建交流平台,筑牢技术、标准、人才、生态支撑。
六、总结
模数共振是 AI 从单点突破走向系统化、产业级赋能的核心路径,通过数据、模型、应用的闭环协同,实现技术迭代与产业价值倍增。当前仍面临技术瓶颈、生态割裂等挑战,需产学研协同推进,助力 AI 高质量发展与实体经济深度融合。