1、智谱:承载清华系技术积淀,探索终极AGI目标
1.1 历程:基于自研GLM架构,打造全模态产品矩阵
北京智谱华章科技股份有限公司((称““智谱”)成立于2019年6月,由清华大学计算 机系知识工程实验室的技术成果转化而来,凭借团队的学术严谨性和创新精神,积极探 索AI领域的前沿发展。公司已形成基于GLM基座的大语言模型、多模态模型、代码模 型、AI Agent 等丰富的模型及产品矩阵,采用本地化部署与云端部署两大类商业化方式, 向科技、互联网、公共服务等领域的企业提供灵活的模型服务。截至2025年6月30日, 智谱的模型已服务超8000家机构客户,赋能约8000万台设备。

智谱的发展历程分为三个阶段: ⚫ 2019-2022年:底层夯实与开源探索期。智谱于2019年6月成立,源自清华计算 机系知识工程实验室技术成果转化。2020年公司启动GLM预训练架构开发,专注 大模型算法开发。2021年3月智谱发布GLM,打破了BERT和GPT瓶颈的全新训 练范式,后续相继发布GLM-10B/130B模型以及专业代码模型CodeGeeX。MaaS产 品及商业化平台于2021年正式发布。 ⚫ 2023-2024年:对话模型最先发布、逐步形成多模态矩阵。2023年3月智谱发布 十亿基座对话模型ChatGLM,随后保持高频迭代(6月ChatGLM2,10月ChatGLM3) 并发布C端产品(“ 智谱清言”,实现技术向产品的转化。同时,智谱也在持续探索多 模态领域,陆续推出VisualGLM和CogVLM模型。2024年,视频模型CogVideoX、 语音模型GLM-4-Voice等的推出标志着智谱多模态模型矩阵的形成。 ⚫ 2025年至今:专注基模Coding以及Agent能力的提升。基座模型方面,智谱已 从2024年1月发布的GLM-4迭代至最新的GLM-5,推理、编程以及Agent能力持 续升级,稳居国内外大模型第一梯队。在编程领域,GLM-5使用体感已接近全球顶 尖模型Claude Opus 4.5。智能体方面,智谱推出了AutoGLM及企业级Agent CoCo, 持续探索AI在手机端侧及企业场景的落地。2026年3月发布了面向OpenClaw场 景深度优化的基座模型GLM-5-Turbo,模型从训练阶段就针对工具调用、指令遵循、定时与持续性任务、长链路执行等核心能力进行增强,在自研基准测试ZClawBench 中取得国产模型第一的成绩。2026年4月,智谱发布其最智能的旗舰模型GLM-5.1, 在业内最具代表性的三个代码评测基准中取得全球模型第三、国产模型第一、开源 模型第一。
1.2 团队:创始人清华系出身,行业领军人物
核心管理团队均拥有清华大学学术背景,学术积累深厚。联合创始人唐杰博士是科技情 报大数据挖掘与服务系统平台AMiner的创始人,该系统在学术研究、企业情报分析等场 景中得到广泛应用,具备较强行业影响力。刘德兵博士在计算技术领域拥有近18年从业 经验,曾任职于特艺科技北京研究所的研究工程师及清华大学高级工程师,负责公司的 战略规划、业务方向等。CEO张鹏专注于知识图谱和大规模预训练模型,是GLM模型系 列及AMiner的核心贡献者,主要负责公司业务发展、研发及日常的运营管理。
公司核心管理人员持股约30%。公司前五大股东分别为慧惠、北京链湃、智登、君联资 本和唐博士,合计持股35.14%。其中,北京链湃由其普通合伙人刘德兵博士持有约92.70% 的股权,慧惠与智登是公司的员工持股平台。智谱的一致行动人包括北京链湃、慧惠、 唐博士、智登及公司部分核心人员,合计持股30.22%。
1.3 模型产品:模型发展脉络清晰,MaaS驱动商业化发展
智谱自发布GLM-4.5以来,其模型的发展脉络逐步清晰:高参数效率、高性价比、强 化编码及智能体能力、对标全球顶尖模型Anthropic Claude系列。 ⚫ GLM-4.5(2025年7月):首次在单个模型中实现将推理、编码和智能体能力原 生融合,满足智能体应用的复杂需求。GLM-4.5总参数量355B,仅为DeepSeek R1的1/2、Kimi-K2的 1/3。在真实代码智能体的人工对比评测中,达到国内最 佳。在编码性能方面,接近全球顶尖模型 Claude Sonnet 4,但价格仅为该模型的 1/7 ,性价比优势显著。⚫ GLM-4.6(2025年9月):总参数量355B,Coding能力较GLM-4.5提升27%。 在真实编程、长上下文处理、推理能力、信息搜索、写作能力与智能体应用等多个 方面实现全面提升。在公开基准与真实编程任务中,GLM-4.6 的代码能力已对齐 Claude Sonnet 4。 ⚫ GLM-4.7(( 2025年12月):总参数355B,面向Coding场景强化了编码能力、长 程任务规划与工具协同,在编程、推理与智能体三个维度实现突破。在全球百万用 户参与盲测的专业编码评估系统,GLM-4.7位列开源第一、国产第一,超过GPT-5.2。 在主流基准测试表现中,GLM-4.7的代码能力对齐Claude Sonnet 4.5。在价格方面, Claude Sonnet 4.5输入价格为3-6美元/百万token,输出价格为15美元/百万token。 GLM-4.7 的输入价格在 2-4 元/百万 token,输出价格在 8-16 元/百万 token,整体 价格约为Claude Sonnet 4.5的1/10。 ⚫ GLM-5(2026 年 2 月):总参数 744B(激活 40B), 预训练数据从 23T 提升至 28.5T。在Coding 与Agent能力上,取得开源SOTA表现,在真实编程场景的使用 体感逼近 Claude Opus 4.5,擅长复杂系统工程与长程 Agent 任务。在 Artificial Analysis 榜单中,GLM-5 位居全球第四、开源第一。在价格方面,GLM-5的输入价 格在4-6 元/百万 token,输出价格在 18-22元/百万 token,整体价格约为 Claude Opus 4.5的1/10。截至2026年4月,GLM-5系列模型已包括GLM-5、GLM-5-Turbo、 GLM-5V-Turbo、GLM-5.1四款模型。
MaaS平台通过模型能力驱动正向飞轮。先进的模型是构建MaaS平台的核心基础,客 户和开发者可以通过平台访问公司最新的模型和智能体产品。全面的模型组合赋能客户 解决各类通用任务的基础能力,广泛的智能体工具(如场景模板和插件库)进一步推动 模型的快速定制化和应用开发,客户可根据特定领域或场景构建专属模型和解决方案, 从而超越传统人工智能企业的项目制模式,实现更优的运营效率与规模经济。MaaS平台 还支持无缝接入部署多种Agent功能以解决独特需求、优化工作流程、满足多元部署要求,助力企业和开发者全面实现人工智能转型。强大的模型能力能够吸引更多客户开发 者的使用,活跃的客户群体能够反哺模型及智能体能力,形成MaaS平台的正向飞轮。
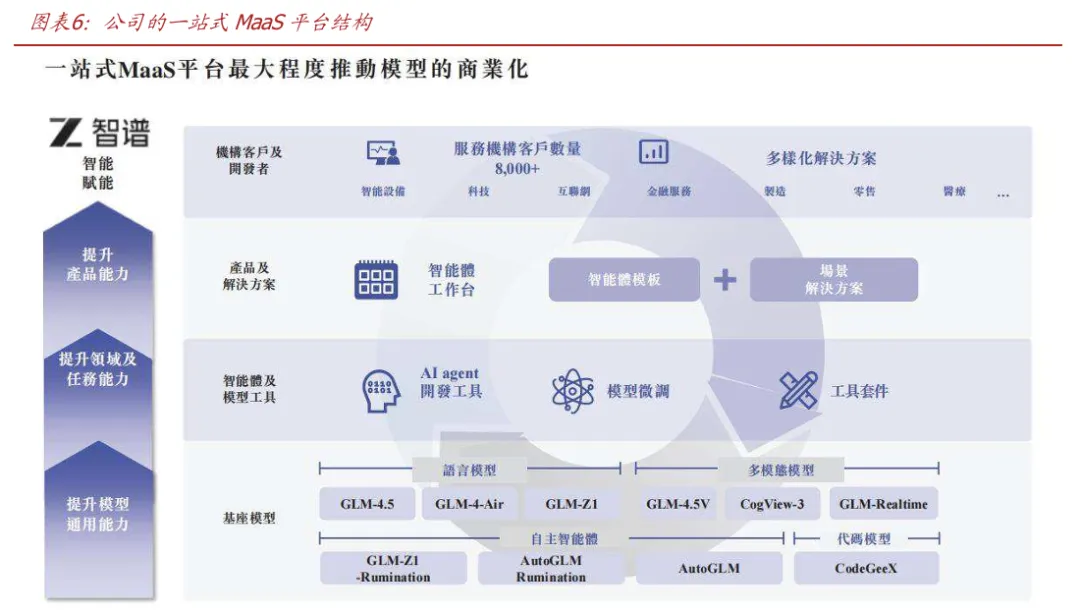
基于MaaS 平台,智谱为客户提供本地化部署与云端部署两种方案,以满足企业在不同 应用场景下的多样化需求: ⚫ 本地化部署模式(2025年收入占比74%):将模型部署并运行于客户自有基础设 施环境中,支持客户基于其专有或敏感数据构建私域专属模型。该模式下,客户对 模型性能调优及基础设施配置具有较高自主权,适用于对安全性、稳定性及专业化 程度要求较高的应用场景。本地化部署定价通过模型类型与规模、纳入的计算资源 量及实施成本厘定。该套餐价格可按一次性计费或按年计费,收入在大模型及相关 服务交付至客户指定地点并完成验收时确认。截至2025H1,智谱服务的本地化部署 机构数为95家。 ⚫ 云端部署模式(2025年收入占比26%):将模型托管于可扩展的云端基础设施中, 为客户提供标准化模型服务。该模式有助于降低客户前期基础设施投入,缩短部署 周期,适用于对部署效率及灵活性要求较高的应用场景。云端部署提供客户根据 token 消耗量计费、以及定价由订阅时长、模型类型与规模及纳入的计算资源量厘 定的基于订阅的合约。在收入确认方面,订阅制合同根据合同期内履约进度按比例 确认收入,按使用量计费的合同则根据客户实际资源使用情况在服务提供期间确认 收入。截至2025H1,智谱云端部署的客户数达3061家。
1.4 财务:收入增长迅速,研发保持高强度投入
收入增速高企,本地化部署贡献当前多数收入、云端部署快速增长。2022–2025年公司 收入分别为0.6/1.2/3.1/7.2亿元,年复合增长率超过130%,整体增速与模型、商业化 落地节奏匹配。具体来看,2025年本地化部署与云端部署收入分别为5.3/1.9亿元,占 总收入的比例为74%/26%。收入结构表明公司收入当前主要来自企业客户,大模型产 品在企业级应用场景中具备更明确的需求和更强的商业落地能力。根据公司招股书的信 息,按行业垂直领域划分,2025H1本地化部署的客户主要来自互联网与科技和公共服务 两大领域,分别占比38.3%/29.4%,合计占比接近总收入的7成。电信、传统企业(零 售、媒体和咨询)、消费电子和其他分别占比13.6%/11.5%/5.7%/1.5%。
本地化部署毛利稳定,云端受行业及市场策略影响承压。从毛利率表现来看,2022年至 2024年,公司整体毛利率始终保持在50%以上。2025年毛利率下滑至41.0%,主要由 于低毛利的云端收入占比提高以及本地化部署毛利的阶段性下降。公司的毛利润主要来 源于高毛利的本地化部署业务,但随着推理效率、算力规模扩张及模型价格端的增加, 云端业务毛利率正逐步优化,从2024年的3.4%提升至2025年的18.9%。此前云端部署毛利率的下滑,主要受行业竞争加剧和通过价格策略加速市场渗透、抢占客户及生态 位的影响。
公司经营开支显著上升,主要源于对研发投入及市场拓展的战略性加码。具体来看: ⚫ 销售及营销费用:2022–2025年公司销售及营销费用为0.15/1.01/3.87/3.91亿元, 占收入比重的26.4%/81.3%/124.0%/54.0%,主要系为抢占新兴市场、提升品牌认 知度并推进生态合作伙伴建设而加大相关投入。公司正采用更有针对性的营销方式, 降低获客成本、优化营销效率。2025年销售及营销费用率显著下降,从2024年同 期的124.0%降至54.0%。 ⚫ 一般及行政费用:2022–2025年公司一般及行政费用为0.32/0.66/1.34/5.05亿元, 占收入比重的56.3%/53.2%/42.8%/69.8%。费用率阶段性回升主要由于公司为扩 充管理与研发团队、吸引并留住核心人才,并于2024年末至2025年初实施股份激 励计划。 ⚫ 研发费用:研发是大模型厂商的立足之本,智谱在研发团队、基座模型迭代以及算 力基础设施的投入力度持续加大。2022–2025年研发费用为0.84/5.29/21.95/31.80 亿元,占收入比重的147.0%/424.7%/702.7/439.1%。根据公司披露的2025H1研 发费用明细,算力服务费 投入占比持续上升,2025 年 H1 占研发费用比例已高达 71.8%。展望未来,公司将通过优化模型训练与推理流程、协同合作伙伴设计基础 设施提升算力使用效率,并依托MaaS平台能力增强,加快规模效应释放与盈利拐 点的到来。
公司尚处在战略投入期,市场更应关注长期空间。2025年公司归母净亏损进一步扩大至 47.2亿元,剔除股权激励费用及金融工具公允价值变动等非经常性因素后,Non-GAAP 口径下归母净亏损为31.8亿元。亏损扩大主要由于公司仍处于战略投入与业务扩张阶 段,一方面持续加大研发投入,研发团队扩张及模型训练对算力资源的高强度需求推升 成本;另一方面,为把握新兴市场机遇,公司同步加强销售与营销团队建设,带动销售 及营销费用整体维持高位。
2、行业分析:模型范式持续迭代,MaaS需求快速扩张
2.1 模型创新:推理能力、长记忆、计算效率
2.1.1 推理能力演变:强化学习与长思维链
随着OpenAI推出GPT-o1等推理模型,大语言模型行业进入了推理阶段。2024年9 月发布的o1模型通过引入大规模强化学习算法,增强了模型的推理链条,提升了错误识 别和修正能力。技术的关键变化在于从“预训练扩展”向“测试时计算”的转变,使得 模型具备了更加深入的推理和自我优化能力。在科学、数学、编码等领域中,o1模型的 推理能力有了显著突破。例如,在国际数学奥林匹克资格考试中,GPT-4o仅能解决13% 的问题,而o1 则达到了 83%的正确率。这标志着AI已经从称单的对话场景扩展至科 学、代码、数学等复杂领域。 DeepSeek R1的推理能力成为AI界关注的焦点。2025年初,中国大模型公司深度求 索DeepSeek发布并开源了R1模型,模型采用纯深度学习的方法,并发现AI自发涌现 出推理能力。DeepSeek R1-Zero模型通过完全依赖强化学习而非监督微调(SFT),实现 了“自我反思”和“错误发现”等高级认知行为,标志着大模型真正理解了问题背后的 逻辑结构。虽然DeepSeek R1-Zero 在可读性和语言流畅性上存在一定问题,但通过引 入冷启动数据和多阶段训练流程,R1模型成功保持了推理能力并优化了表达方式,且其 训练成本仅为OpenAI o1模型的1/10,两者性能却相当。
思维链为提升模型推理能力的常用手段。思维链可划分为短思维链与长思维链:前者以 浅层、线性的推理为特征,侧重于解决逻辑单一、定义明确的基础问题;而长思维链则 通过构建“深度推理、探索与反思”的整合框架,确保每个逻辑环节在复杂结构下均能 严密执行,并鼓励模型挖掘非显性的潜在路径,同时引入迭代分析机制对结论进行动态 重估与修正。这种从线性到演进式逻辑的转变,使得长思维链在处理高难度问题时具备 更强的精确度、稳健性以及逻辑挖掘深度。
推理大语言模型在长思维链演进中呈现出六大关键行为特征:1)涌现现象,长思维能力 并非凭空产生,而是通过回溯、自检等行为激活;2)推理边界,任务复杂度超越模型逻 辑容量阈值会导致准确率下降;3)过度思考,揭示了推理长度与精度并非线性正相关, 需防范错误累积;4)推理侧扩展,证明通过增加推理时的计算投入能显著提升逻辑上限; 5)在训练范式上,模型面临过程监督与结果监督的路径选择,需平衡监督细粒度与奖励 作弊风险;6)模型在强化学习中会产生顿悟时刻,需通过维持(“ 策略熵”来防止思维收 敛导致的推理崩塌。
智谱采用交错式思考+保留式思考+轮级思考。交错式思考下,模型会在每次响应和工 具调用前都会进行思考,提高了指令遵循和生成质量。保留式思考更侧重编程智能体场 景,模型会自动在多轮对话中保留所有思维块,复用现有的推理过程而非从头重新推导。 减少了信息丢失和不一致性,适合长期且复杂的任务。而轮级思考支持模型在会话内对 每个轮次的推理进行控制,对轻量级请求禁用思维以降低延迟/成本,对复杂任务启用思 维以提高准确性和稳定性。
2.1.2 长记忆突破:Engram与嵌套学习领衔最新进展
报告全文可扫描下方图片二维码进入星球社群查阅下载

(报告来源:国盛证券。本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)