


财报电话会这件事,很多人都听说过。
但大多数量化研究,处理它的方式其实很粗。
做法往往是把整场电话会当成一大段文本,算一个平均情绪分,然后去看这个分数和股价有没有关系。
这篇 2026 年 4 月新鲜出炉的 arXiv 论文,问了一个更聪明的问题:
同样一句乐观的话,如果是 CEO 说的,和如果是分析师问出来的,信息含量真的一样吗?
作者把这个问题做得很彻底。他们用 FinBERT 扫了 2015 到 2025 年、16428 场标普 500 财报电话会、约 650 万个句子,然后不再把整场会当成一个整体,而是拆成四类说话人:
1. 分析师 2. CFO 3. 其他核心高管,比如 CEO、COO、CTO 4. 其他参与者
最后他们得出的结论很直接:
真正最能推动财报后收益率差异的,不是“整体情绪”,而是“不同说话人的情绪,应该按不同权重去算”。
而且最有信息量的声音,居然是分析师。
这篇论文到底在做什么
先把问题翻译成人话。
财报电话会里,管理层会先讲准备好的稿子,然后进入问答环节。这个场景里混着两类完全不同的信息。
一类是“硬信息”,比如营收、利润、指引。
另一类是“软信息”,比如语气、自信程度、闪躲、犹豫、追问的锋利程度。
软信息:不是财报表格里那种能直接抄进 Excel 的数字,而是隐藏在措辞、语气和互动方式里的信息。就像两家公司都说“下季度前景乐观”,一个说得笃定,一个说得飘,你直觉上会给它们不同分数。
这篇论文的核心想法,就是把“软信息”从一锅粥里分离出来。
作者不是问“整场会偏正面还是偏负面”,而是问:
哪一类人的情绪,最值得市场认真听。
为什么“谁在说”比“说了什么”更重要
这篇论文最有价值的地方,不是又跑了一个文本模型。
而是它抓住了一个很容易被忽略、但其实非常符合常识的点:
不同角色,说同样的话,可信度和信息密度并不一样。
你想一下这个场景。
CEO 在开场白里说,公司战略势头很好、执行很强、未来很有信心。这些话可能是真的,但也可能带着明显的管理层修饰。
分析师在问答环节里的风格就不同了。他们通常会追问库存、毛利率、订单可持续性、客户砍单、资本开支、定价压力。这些问题不是给公司做 PR 的,而是为了替市场试探管理层的底牌。
FinBERT:一个专门处理金融文本情绪的语言模型。你可以把它理解成“看过大量财报、研报、电话会记录”的 BERT,它比普通情绪词典更懂金融语境。
信息含量:不是一句话听起来多热闹,而是它能不能帮助你更准确地预测后面的市场反应。
论文的意思其实很朴素:
市场不是没在听电话会,而是过去的量化做法没把“发言人身份”这个维度用好。
他们是怎么做的
方法并不花哨,但很干净。
第一步,作者把每一句话按说话人归类。
第二步,用 FinBERT 给每个句子打情绪分。
第三步,不是简单平均,而是先在训练样本里看,哪一类说话人的情绪,对财报后 1 日收益率的预测力最强。
这个预测力用的是 Information Coefficient,也就是 IC。
Information Coefficient,IC:可以粗略理解成“信号排序能力”。如果情绪分越高的股票,后面收益通常越高,那 IC 就更高。量化里常把它看成一个信号到底有没有用的基本体检指标。
然后他们把权重定出来:
1. 分析师:49% 2. CFO:30% 3. 高管:16% 4. 其他:5%
这组权重很有意思。
它几乎是在说:
如果你想从财报电话会里提炼可交易的信息,最该听的是分析师,其次是 CFO,而不是 CEO 的整场主旋律。
最关键的结果是什么
先看最核心的一条。
如果你把整场电话会按普通方式做平均,信号的 IC 大概是 0.081。
如果你按这篇论文的方法,按说话人重要性去加权,IC 提升到 0.119。
这是 46% 的提升。
这已经不是“小修小补”的改善了。
它说明过去把电话会文本一股脑平均掉,确实在系统性地丢信息。
更重要的是,这个结果并不只是样本内好看。
论文把 2022 年底之前当训练期,把 2023 年起作为冻结权重后的样本外测试期。结果反而更强:
1. 样本内 section-weighted IC:0.115 2. 样本外 section-weighted IC:0.142
这个结果很少见。
通常文本信号一到样本外就会衰减,甚至塌掉。这里不但没塌,反而增强了。
作者的解释是,这套“谁更重要”的层级关系,可能不是短期数据噪声,而是财报电话会这个信息环境里比较稳定的结构。
对交易最有吸引力的地方
如果你是做资产定价或者做事件驱动,这篇论文最抓人的不是 IC,而是组合收益。
他们把股票按情绪分成五组,做最正面减最负面的多空组合。
结果是:
按 section-weighted 情绪排序,Q5 减 Q1 的单日收益差达到 2.263%。
这个数很猛。
哪怕你不直接拿它当可执行策略,只把它当“信息分层”的证据,也已经相当强。
更进一步,作者用 Fama French 五因子模型去做时间序列回归,发现这个多空组合还有 2.03% 的月度 alpha,t 值 6.49。
Alpha:剔除常见风险因子之后,策略还剩下的超额收益。可以把它理解成“不是市场、规模、价值这些老因素解释掉的那一部分”。
论文还把样本切成不同阶段去看。
1. 训练期,也就是 2023 年前,月度 alpha 是 1.56% 2. 测试期,也就是 2023 年后,月度 alpha 是 2.77%
这说明一个问题:
这个信号不是只会在论文里发光,它在更靠近现实的样本外阶段,仍然保持了很强的解释力。
论文原图能说明什么
下面这张图,本质上是在看一个问题:
市场消化电话会情绪,到底是立刻完成,还是会拖一阵子。
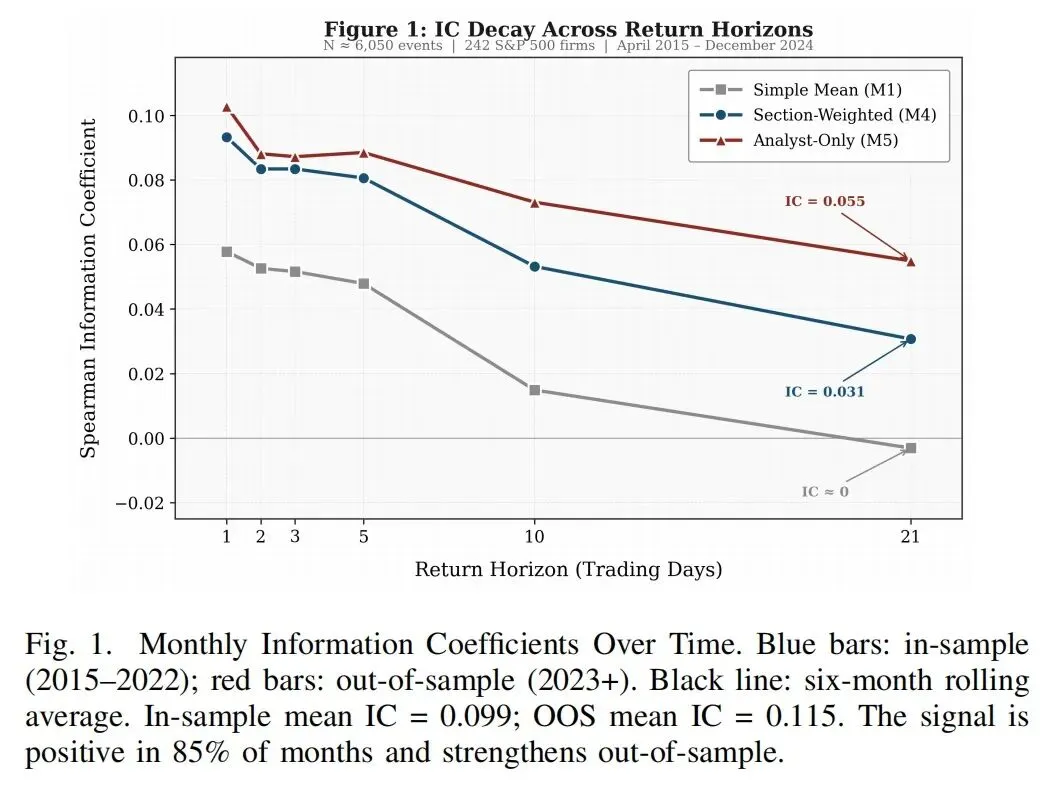
从论文的描述看,这个信号在 1 日窗口最强,之后逐步衰减,半衰期大约是 6 到 7 个交易日。
这件事非常关键。
它说明电话会里的软信息,不是开完会后一秒钟就被彻底定价了。
市场会吸收,但吸收得不够快。
这正是很多后财报漂移研究关心的核心问题。
再看第二张图。
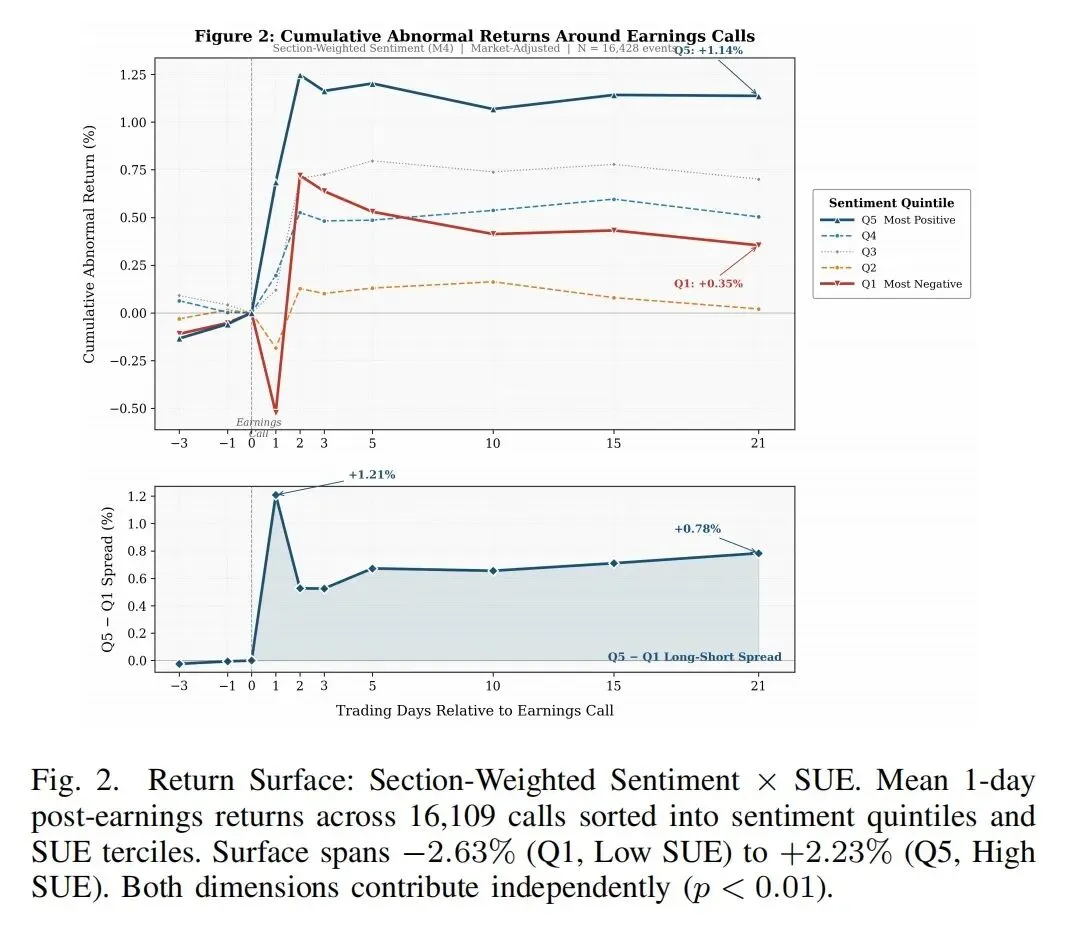
这张图对应的是累计异常收益的“扇形展开”。
最正面的组和最负面的组,会在后续交易日里越来越分开,总体分化大约 3%。
这不是瞬时跳一下就结束,而是持续拉开。
你可以把它理解成:
电话会给市场提供了一层额外线索,但市场对这层线索的反应是迟缓的。
它和传统情绪词典比,强在哪里
论文还做了一个很重要的对照。
以前金融文本情绪分析里,很多人会用 Loughran McDonald 词典,也就是 LM 词典。
这种做法的优点是透明、简单、便宜。
但问题也很明显,它是“见词不见句子”。
LM 词典:把词分成正面、负面、不确定等类别,再根据词频算情绪。它的问题在于看不懂上下文,比如“down 24% from strong performance last year”里有 strong,但整句话显然不是正面。
这篇论文做了正面对决。
结果是:
1. FinBERT 在所有聚合方式上都优于 LM 2. 在 section-weighted 方法上,FinBERT 的 IC 是 0.119,LM 是 0.075 3. 在 analyst-only 方法上,FinBERT 的 IC 是 0.141,LM 是 0.062
更狠的是联合回归。
单独放的时候,FinBERT 和 LM 都显著。
一起放进去以后,FinBERT 依然显著,LM 基本失去显著性。
这背后的意思很明确:
上下文理解能力,不只是“锦上添花”,而是会直接决定你能不能真正抓住金融语言里的有效信息。
这篇论文最聪明的一刀,其实不是 NLP
很多人看到 FinBERT,会本能地把这篇文章归类成“NLP 在金融里的又一个应用”。
但我觉得这不是重点。
真正聪明的一刀,是它把“角色异质性”正式搬进了信号构建。
这件事听起来像常识,但研究里常常没人认真做。
因为一旦你把整份电话会压成一个数字,模型是干净了,现实却被你抹平了。
这篇论文相当于说:
文本不是只有内容维度,还有说话人维度。
这跟很多现实世界的问题其实是相通的。
同样一句话,医生说、销售说、审计师说、创始人说,可信度当然不同。
如果模型不区分身份,只做平均,它就会把最值钱的结构性信息直接洗掉。
这篇论文有什么局限
论文很强,但也不是没有边界。
我觉得至少有三个点要记住。
第一,它只看了 S&P 500。
大盘股的信息环境更成熟,分析师覆盖也更完整。这个结果能不能平移到小盘股,还不能直接下结论。
第二,样本外虽然漂亮,但测试窗口其实还是偏短,主要集中在 2023 到 2025。
这足够说明它不是简单过拟合,但还不足以宣告“永远有效”。
第三,论文展示的是强统计显著性,不等于你真实交易里可以原样拿走同样收益。交易成本、容量、执行延迟、盘前盘后可交易性,这些问题它都没有细做。
所以更稳妥的理解方式是:
它非常有力地证明了信息存在,但没有完全证明这份信息能被无摩擦地搬运成真实利润。
对我们真正的启发是什么
如果你做研究,这篇论文最大的启发是:
在多角色文本里,先问“谁在说”,再问“说了什么”。
如果你做投资,这篇论文最大的启发是:
财报电话会最该听的,可能不是准备好的管理层台词,而是问答里那些让管理层不得不临场应对的瞬间。
如果你做 AI 应用,这篇论文最大的启发是:
好的模型,不只是更会分类情绪,而是更会保留现实结构。
这篇论文把“说话人身份”保留下来了,所以信号才从噪音里冒出来。
我觉得这也是它最值得反复回味的地方。
不是它用了多新的模型。
而是它终于认真对待了一个长期被平均值掩盖的问题:
市场里,不同的人,说话分量本来就不一样。
一句话总结
这篇论文真正告诉我们的,不是“情绪可以预测收益”。
这个结论大家早就知道一点了。
它更进一步告诉我们:
在财报电话会里,最有价值的不是平均情绪,而是带着身份权重的情绪。分析师最重要,CFO 第二,高管再次。
当你开始认真区分“谁在说”,市场里的很多噪音,才会第一次显出结构。
论文信息
题目:Which Voices Move Markets? Speaker Identity and the Cross-Section of Post-Earnings Returns
作者:Karmanpartap Singh Sidhu, Junyi Fan, Maryam Pishgar
链接:https://arxiv.org/abs/2604.13260