



AI科普馆部分垂类内容转移至?
【长三角人工智能联盟】公众号,快点进去瞧瞧!
2022年3月,一段伪造乌克兰总统泽连斯基呼吁士兵投降的视频传遍互联网。
它的质量并不高——口型不对,语音失真,专业人士几秒内就能识别。但它依然引发了短暂的恐慌,乌克兰官方不得不专门发布真实视频来应对。
这个案例被清华大学的报告引用来解释一个核心问题:AI谣言的威胁,不在于它能持续骗很久,而在于它能在很短时间内造成真实后果。
这不是孤例。2023年5月,五角大楼"爆炸"假图在社交平台扩散,引发短暂金融市场波动;2024年初,美国有人用AI克隆拜登声音打自动电话,试图劝阻新罕布什尔州选民投票;香港警方披露,同期有Deepfake视频会议诈骗单笔损失超2.4亿港元。
这些案例勾勒出一个正在升级的威胁图景——而驱动它升级的,是底层技术的结构性跃迁。
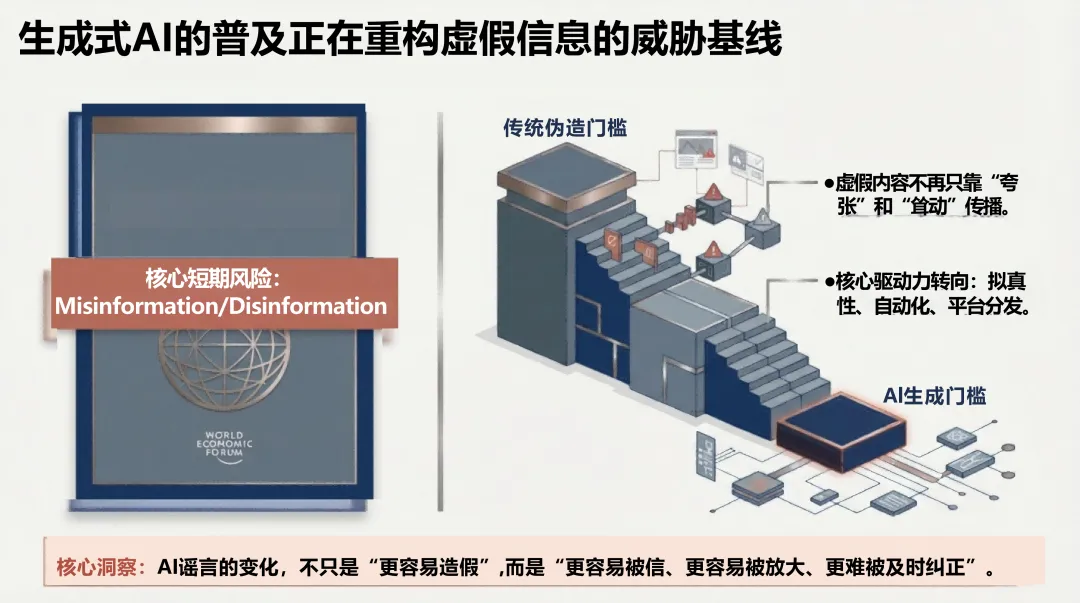
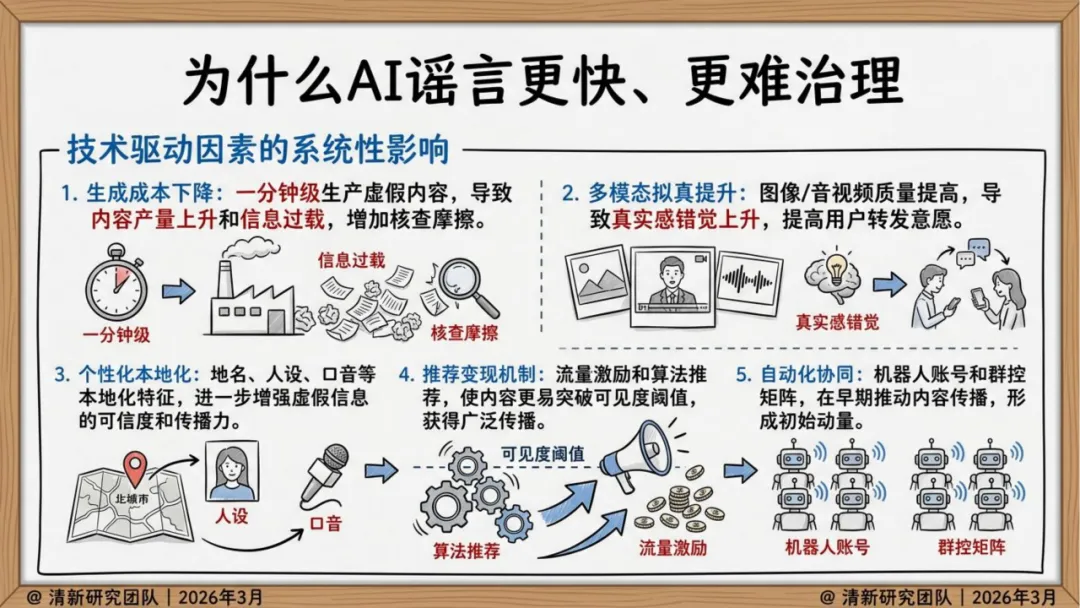
AI谣言的本质,已经和以前不一样了
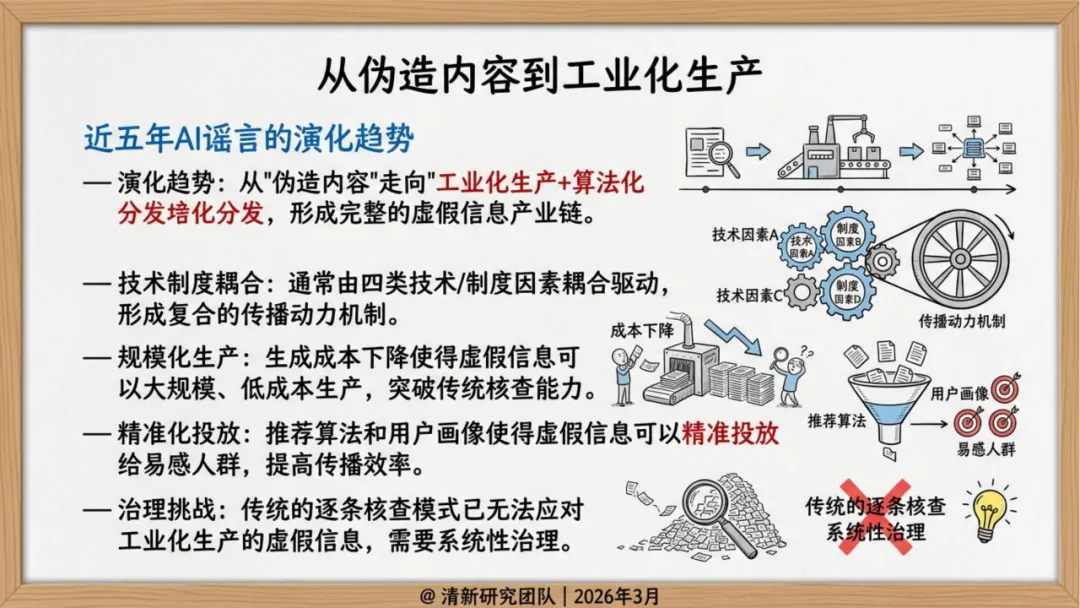
传统谣言的生产模式是人工编造、批量改写,依赖情绪煽动和社交网络自然扩散。内容粗糙、逻辑断裂,辟谣相对容易找到切入点。
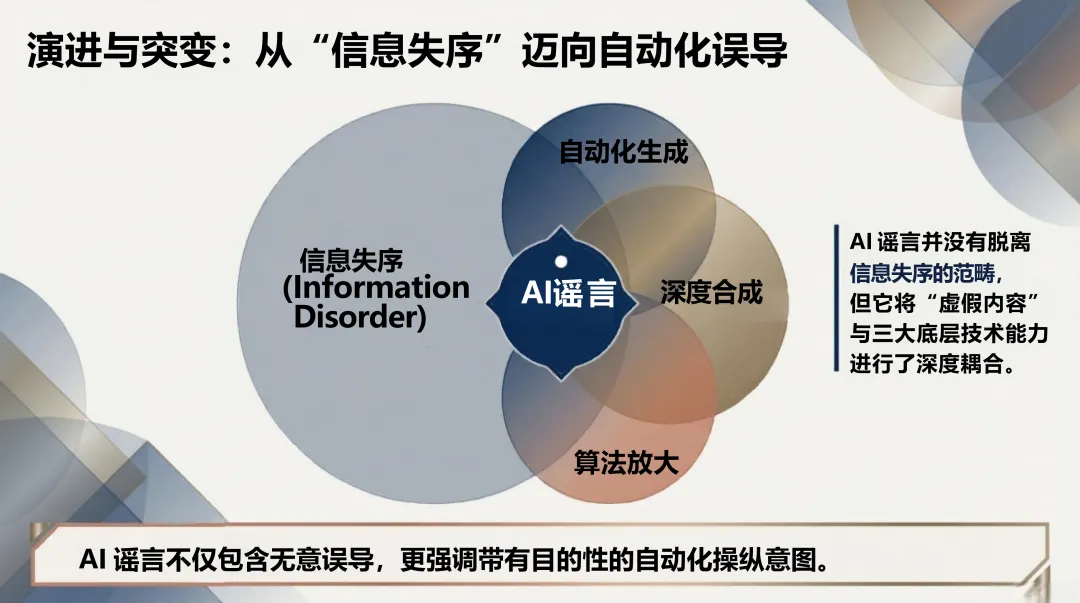
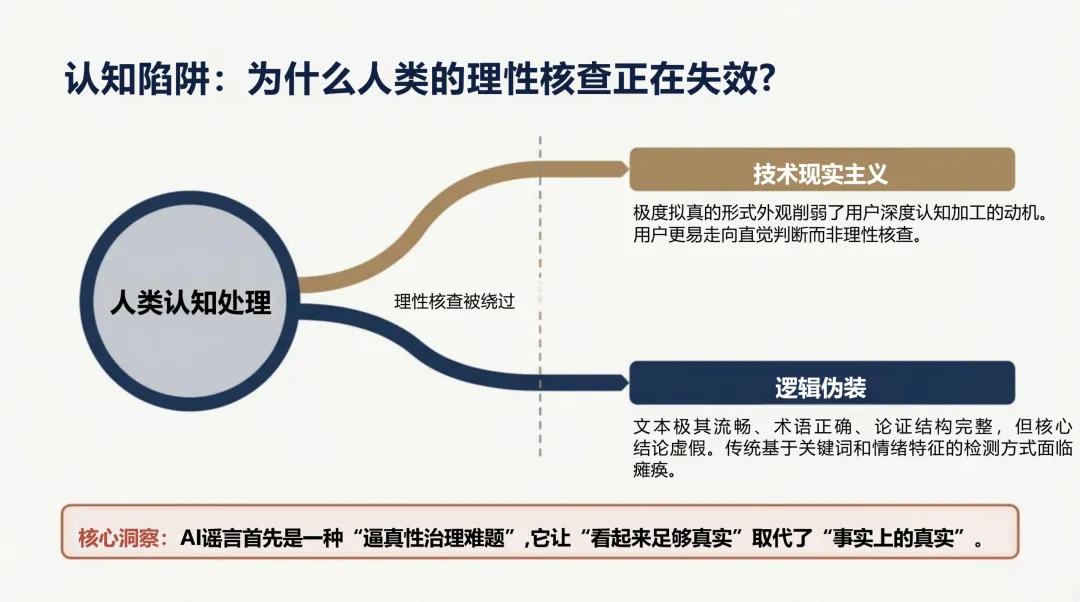
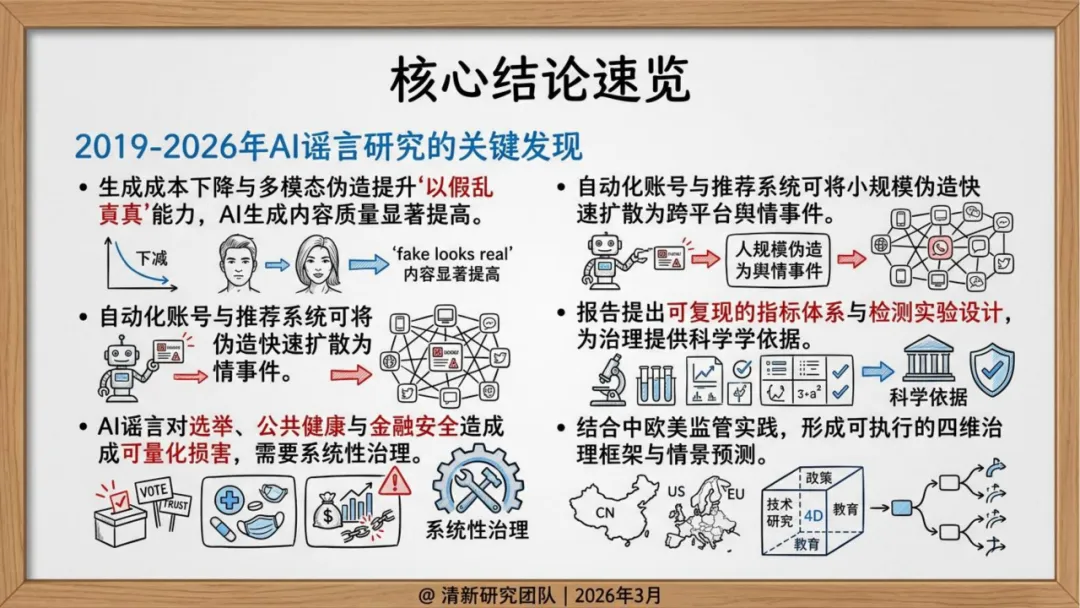
生成式AI改变了一切。清华报告的核心判断是:"假得更像真",而不是"假得更多"。
具体变化体现在三个层面:
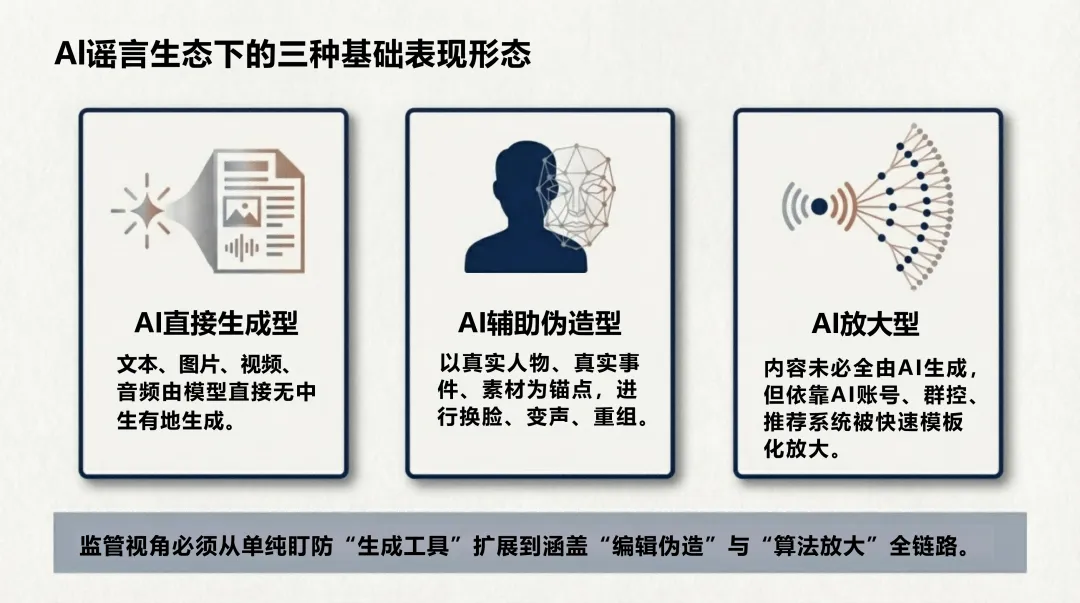
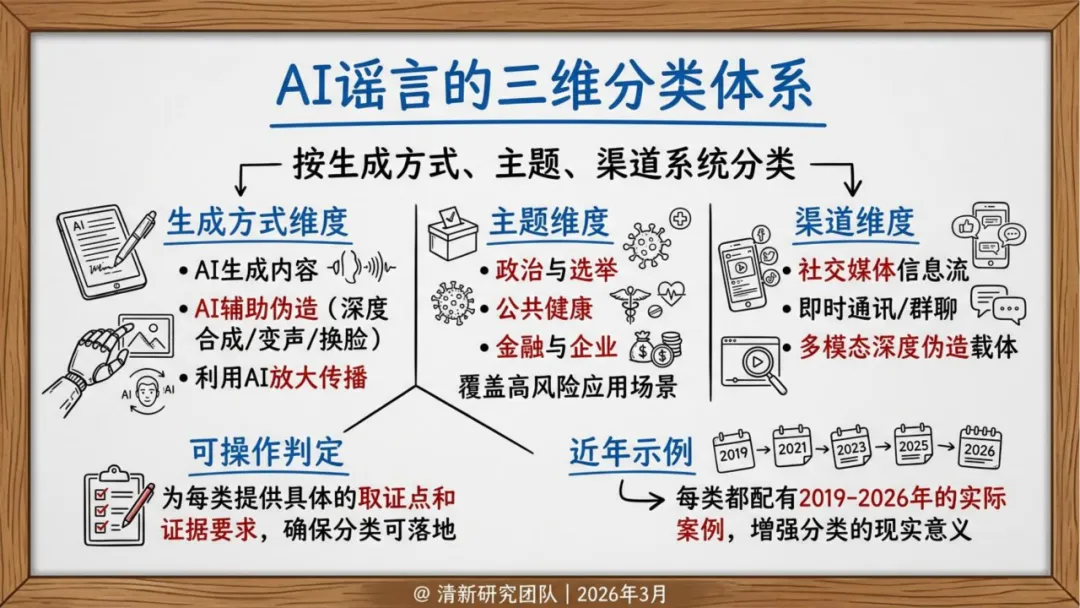
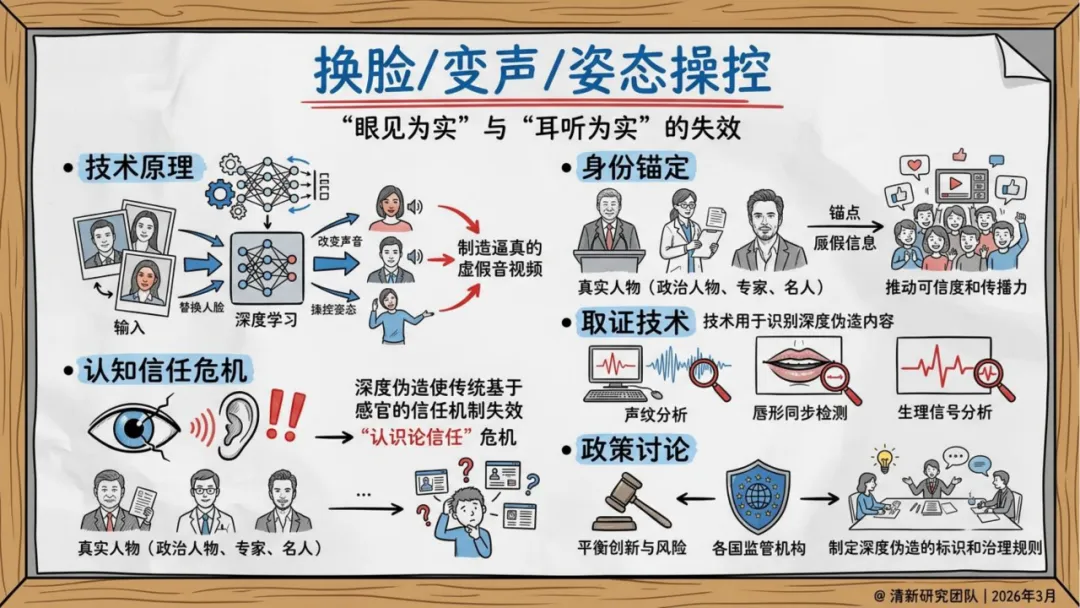
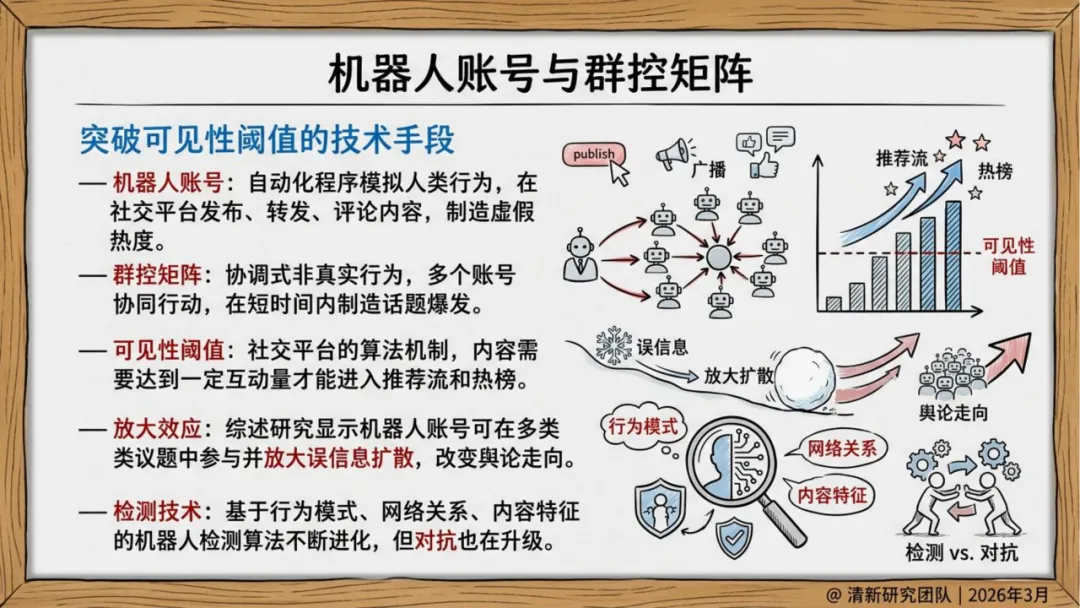
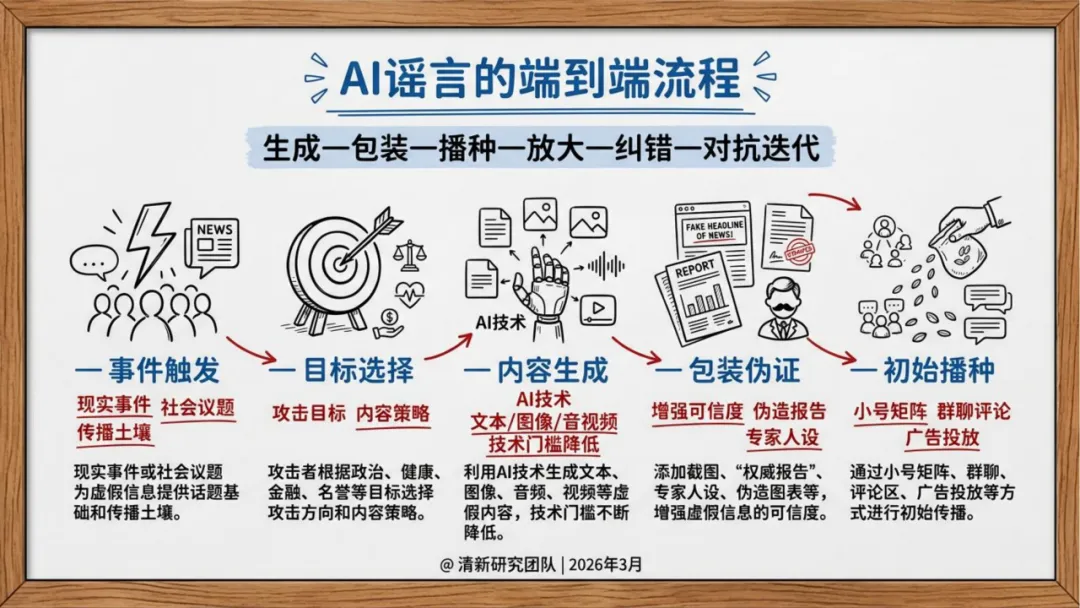
生产侧,AI谣言不再是"无中生有",而是精准锚定真实人物、事件和素材,进行换脸、变声、重组。形式高度拟真,语义流畅,论证结构完整——传统基于关键词和情绪特征的检测方式面临瘫痪。
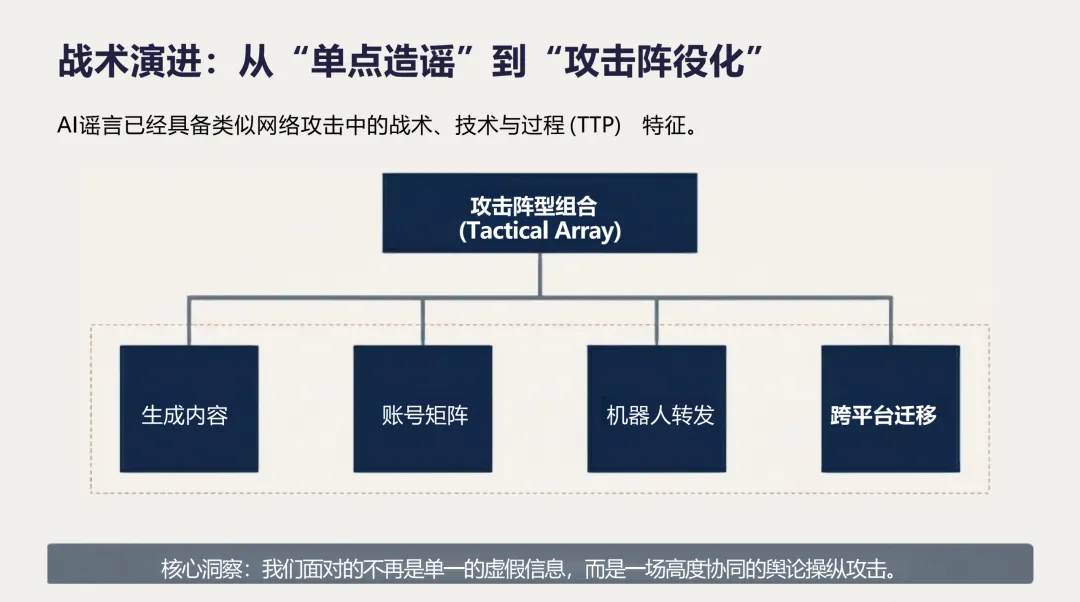
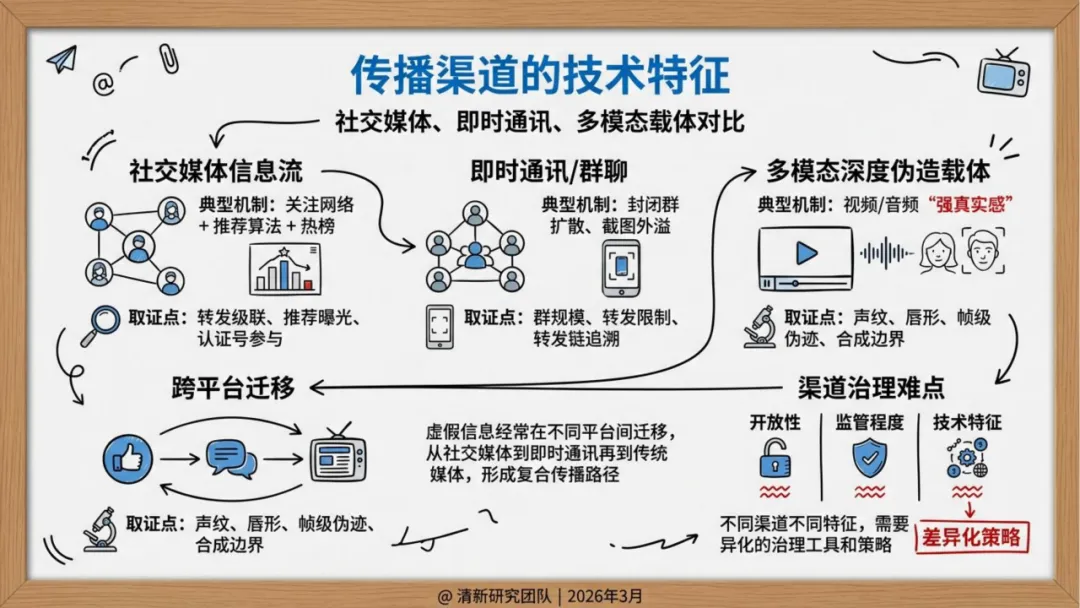
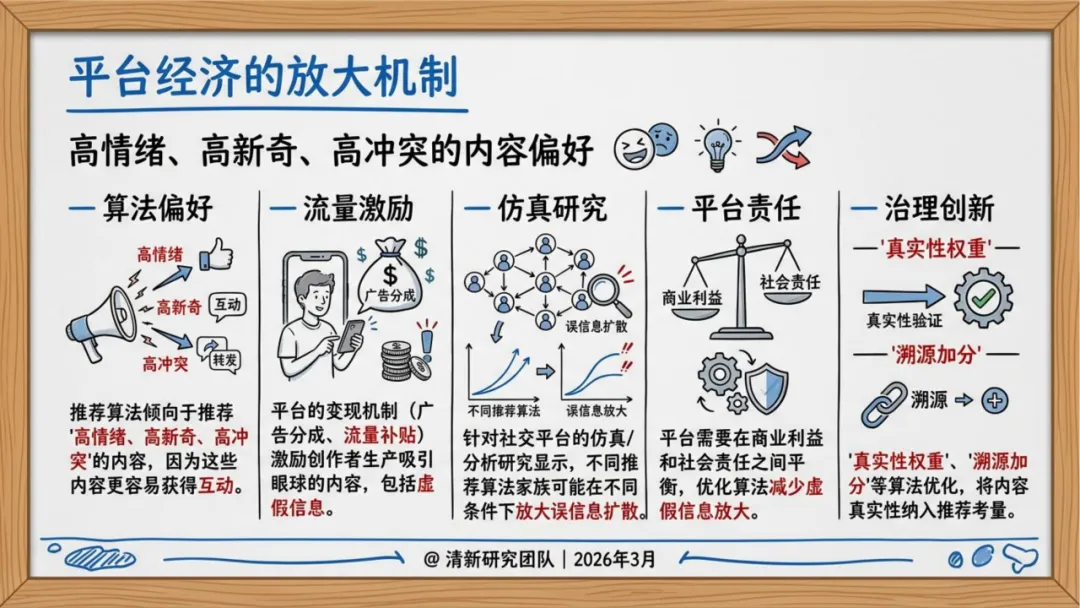
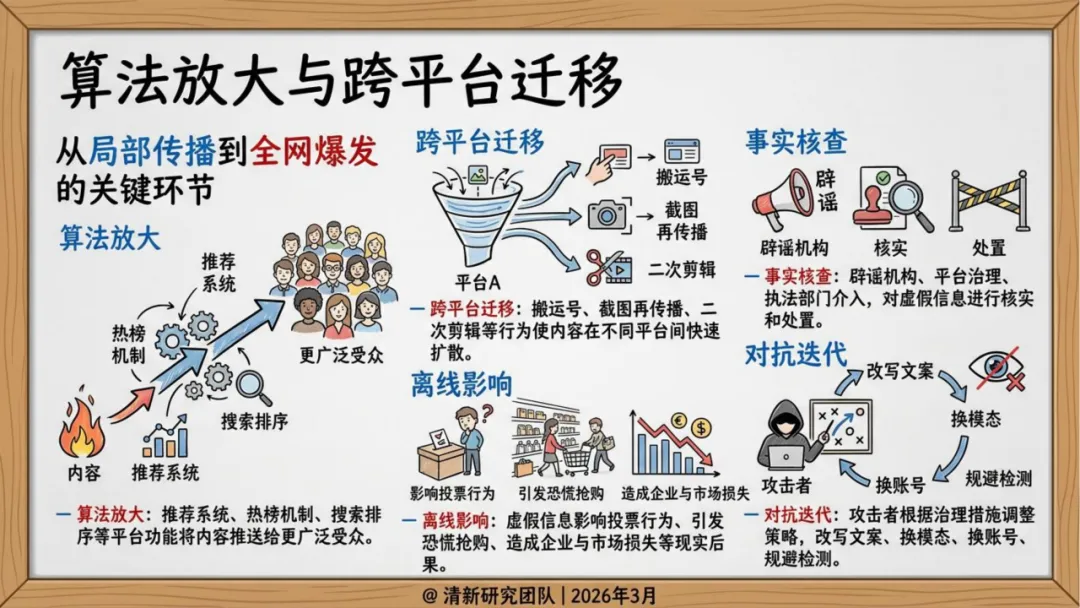
传播侧,不再依赖自然扩散,而是"生成—包装—播种—放大—迁移"的完整操作链。社交机器人账号矩阵负责维持热度,推荐算法天然偏好高冲突、高情绪强度内容,两者叠加形成系统性加速。
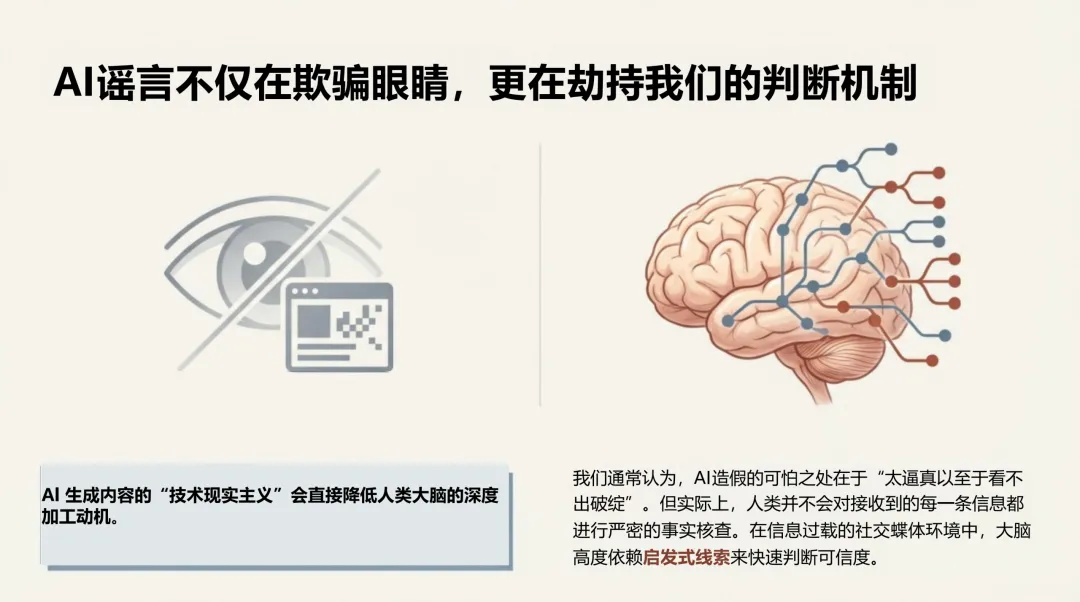
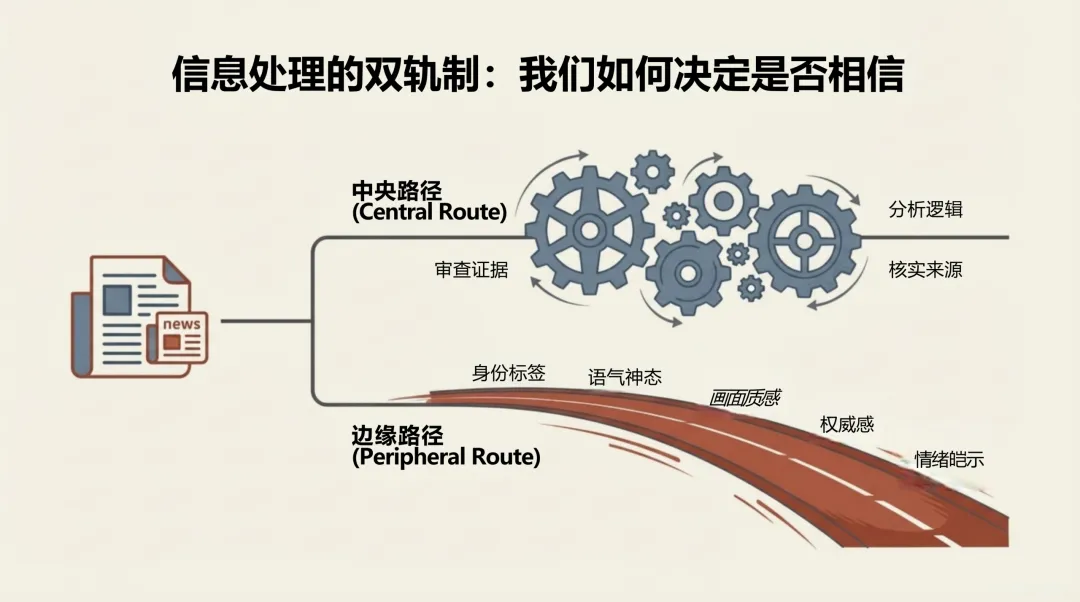
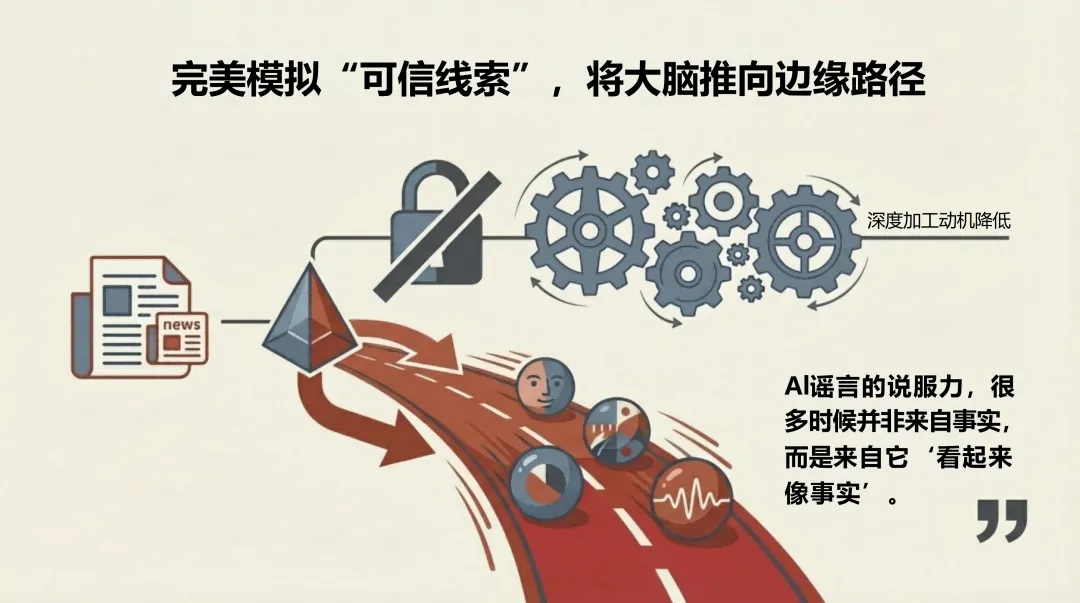
最关键的变化在认知层面。报告引用认知心理学研究指出:人类在信息过载的环境中,依赖直觉而非深度核查来判断内容可信度。AI谣言恰恰在模拟这个判断过程中最依赖的"边缘线索"——画面质感、权威感、流畅的语气。它绕过的不是眼睛,而是判断机制本身。
报告将这个机制称为"认知资源劫持":极度拟真的形式外观,削弱了用户深度认知加工的动机,让未经核实的直觉直接替代了审查后的判断。
更深的悖论在于"说谎者红利":当全社会意识到视频可以轻易造假,真实的视频也可能被当事人反向指控为AI伪造。泽连斯基的假视频被识破了,但它留下的怀疑会渗透到下一个真实视频的传播过程中。
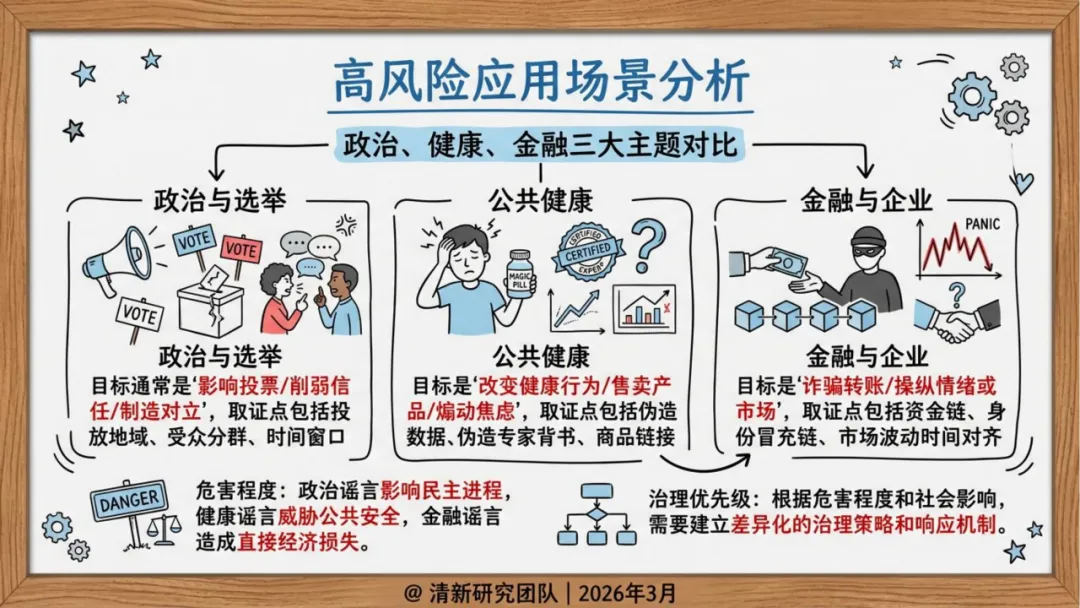
高风险主题:政治、健康、金融
报告指出,AI谣言的威胁并非均匀分布,而是集中在几个高价值目标领域。
报告将高风险主题归纳为三类:政治选举、公共健康、金融企业,并分别建立了对应的感染模式模型。
政治选举是进展最快的领域。2024年拜登AI语音电话事件之后,美国FCC正式确认AI生成语音属于监管范围内的"人工或预录音",并对策划者处以罚款。这个案例的标志性意义在于:AI谣言已经从"内容误导"演变为对民主程序的直接干预。
公共健康领域长期是谣言重灾区,AI介入后复制成本大幅降低,情绪化内容更容易穿透圈层。
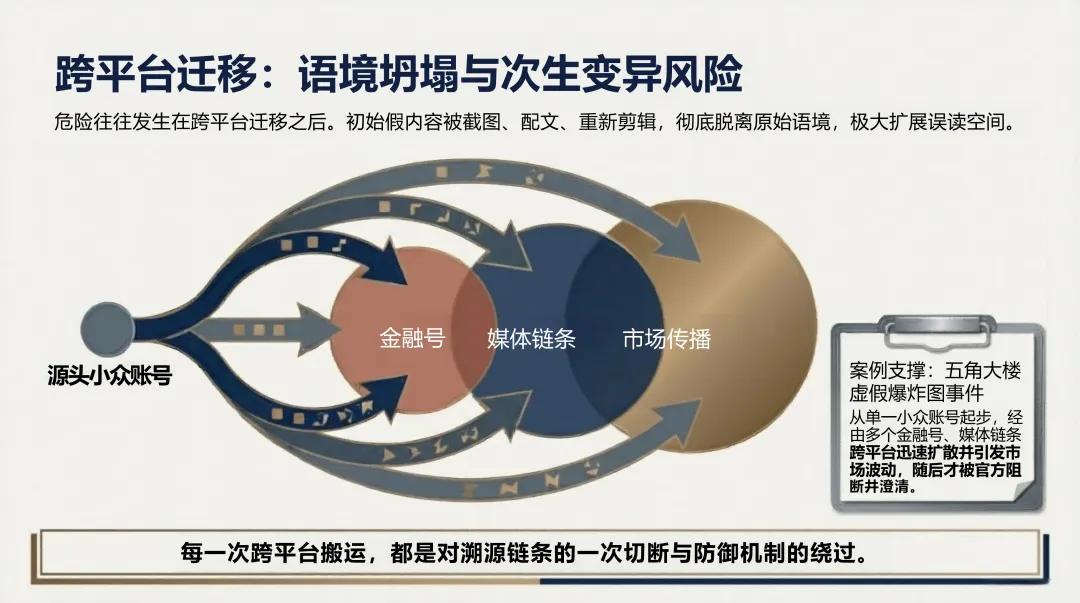
金融领域则是破坏力最直接的——五角大楼假图引发市场短期波动,说明一条AI生成的图片配上突发新闻的叙事框架,可以直接触发市场反应。
香港的Deepfake视频会议诈骗则揭示了另一个趋势:受害者的门槛在上升。受害者不再只是缺乏辨别能力的普通网民,而是深谙企业流程的专业人员。AI实时换脸加语音克隆,可以在视频会议中冒充同事或上级下达指令,这种场景在传统认知里被认为是"可信的"。
一个被忽视的治理盲区
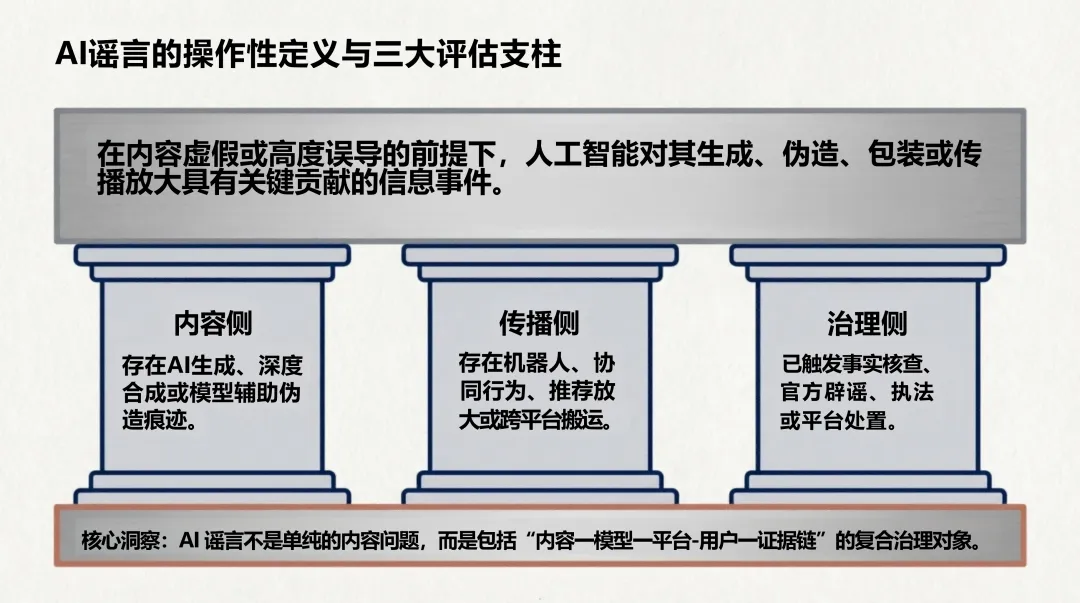
报告花了大量篇幅讨论一个被低估的问题:现有治理体系的对象错了。
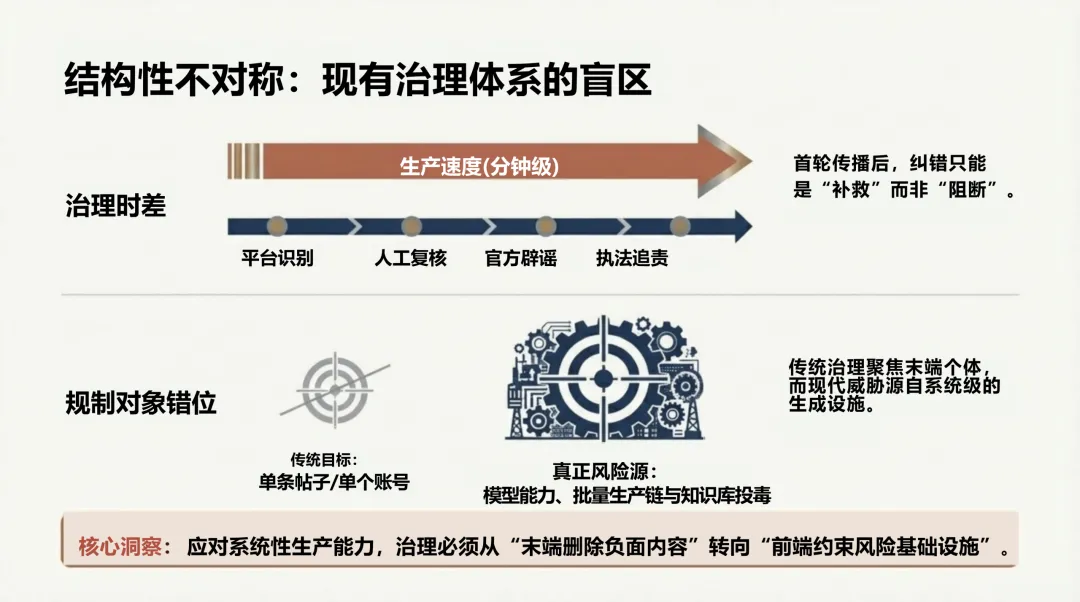
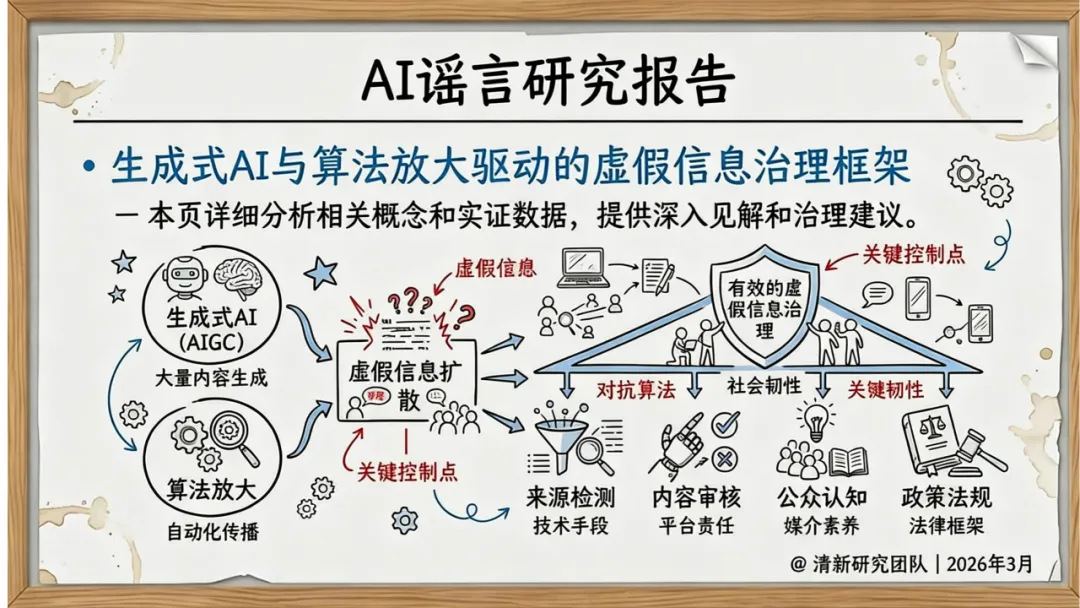
传统谣言治理的目标是单条帖子、单个账号、末端删除。但AI谣言的威胁是系统级的——它的真正风险源是模型能力、批量生产链与知识库投毒。
具体来说,治理存在三重盲区:
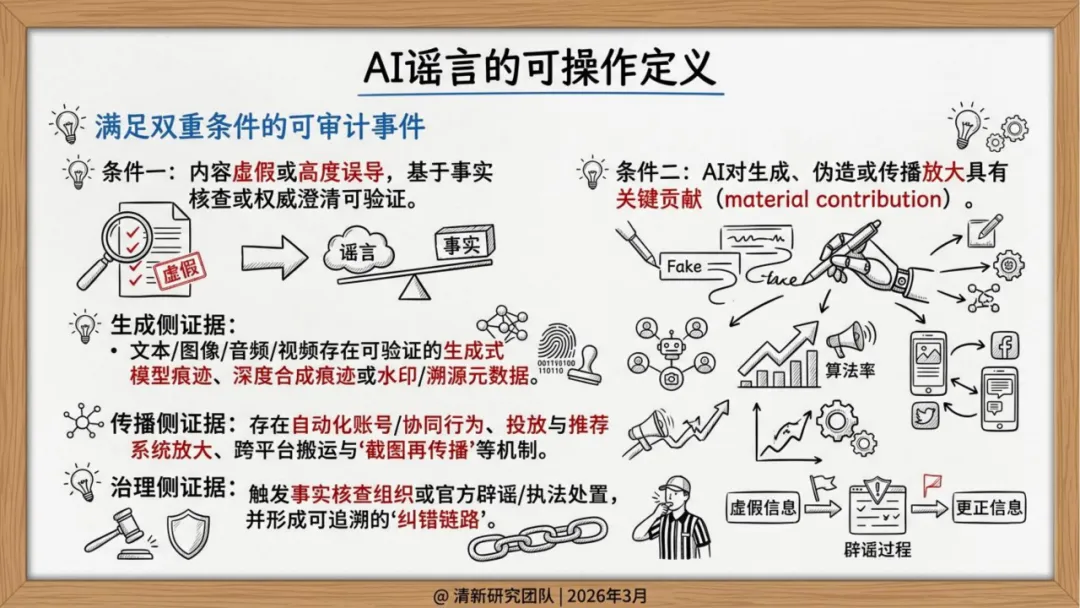
结构性时差。 AI谣言可以在分钟级生成,平台识别需要时间,官方辟谣需要走完流程,执法追责需要证据保全。每一步都是滞后的,首轮传播后的纠错只能是"补救"而非"阻断"。
规制对象错位。 传统治理盯防的是"恶意用户输入",但下一代的真正风险在于:用于核查的模型本身,在出厂前就可能被污染。报告专门讨论了两个系统性漏洞——预训练数据投毒(仅替换0.001%的训练令牌即可造成不可见的永久偏见)和RAG知识库污染(向企业向量数据库注入恶意文档,使AI以高置信度输出虚假辟谣)。这两者的可怕之处在于:系统级漏洞远比输入端欺骗更难根除。
元数据断裂。 C2PA等数字签名标准在技术上是成熟的——Google Pixel 10已在拍摄瞬间硬绑定元数据(GPS、时间戳),相当于给图片建立"出生证明"。但问题出在分发端:平台出于带宽和隐私考量强制重新编码,不可篡改的加密签名随之失效。溯源链在离开生成端的那一刻就断了,而大多数普通用户根本没有能力查验原始证据链。
治理的重心必须前移
面对这套基础设施,末端删帖辟谣已经不够用了。治理的重心必须从"真假之辩"转向"速度之战"。
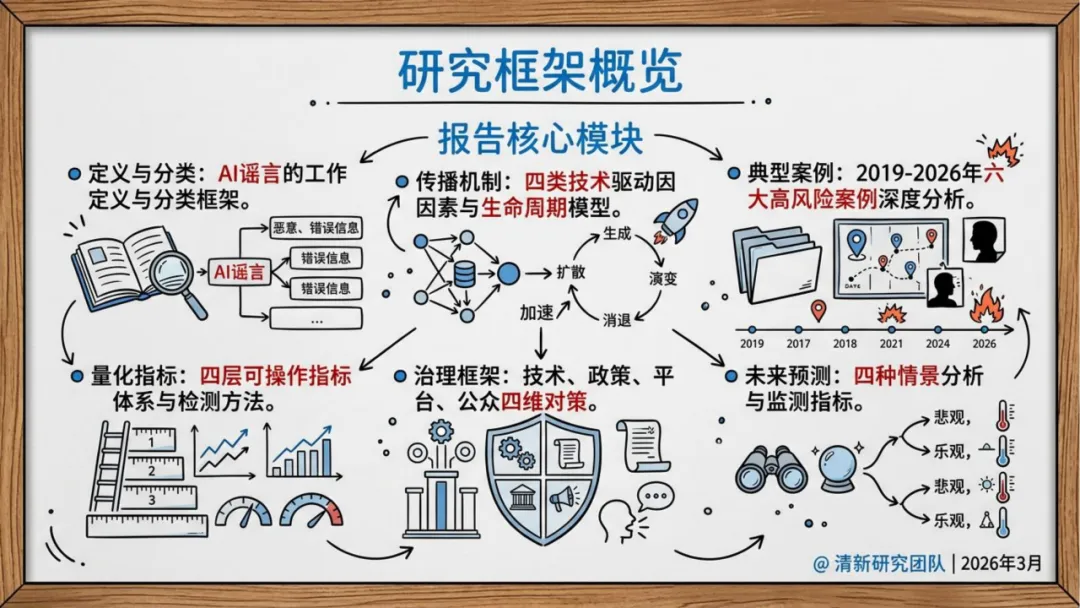
报告提出了一套内容—主体—传播三维风险评估框架,试图将AI谣言的治理从经验判断转化为可量化的风险指标。
内容层检测生成概率(Pgen)、伪迹强度(A_artifact)和溯源可验证性(V_prov),回答"内容像不像AI伪造"。主体层追踪账号可信度(Tactor)和机器人概率(Bbot),回答"是谁在推、怎么在推"。传播层量化传播速度、级联规模、放大因子和辟谣滞后时间,回答"扩散得有多快、多广、多难纠正"。
这三层指标的分数综合成RiskScore,对应低/中/高三档响应策略:低分添加上下文提示标签,中分启动算法干预限流,高分触发跨部门联动并保全证据。
报告也从另一个角度提出框架:技术、政策、平台、公众四维协同。短期强化溯源水印与媒介素养教育,中期推动深度伪造防御标准化和平台算法责任落实,长期建立跨平台溯源协同和全球治理公约。
两者有一个共同指向:从被动辟谣走向主动防御。"捕捉AI语言指纹,建模攻击者TTPs实现前瞻预警",同时"建立多利益相关方协同治理体系"。
AI谣言的威胁基线已经抬升。 以前它是一个内容问题,现在它是系统级的社会工程攻击。以前我们对付的是单点造谣,现在要应对的是工业化生产加攻击阵役化。以前我们假设公众有判断能力,现在要承认这个假设正在被动摇。
治理思路必须跟着变——不是修修补补,是从末端追着跑到前端构建防线,从单纯检测内容到同时监控生成设施本身。
以下是内容节选↓↓↓ 文末点击链接免费下载pdf,扫二维码加入交流群













AI科普馆:打开AI世界之窗

