


引言:深度解析本体存储的战略意义
在企业数字化转型步入“深水区”的当下,核心挑战已从数据的“获取与堆砌”转向对数据“深层语义的理解与复用”。数据孤岛与知识碎片化本质上是业务逻辑在底层技术实现中的断裂。传统的ETL模式往往将业务知识硬编码于管道之中,导致数据资产难以随着业务逻辑的演进而动态生长。在此背景下,本体作为可编程数字孪生(Programmable Digital Twin),成为连接原始异构数据与业务核心逻辑的“枢纽层”。本体存储引擎的性能、一致性与操作化能力,直接决定了企业知识库是停留在“静态档案”阶段,还是能够进化为驱动决策的“业务大脑”。
本报告通过对Palantir Foundry等顶尖架构的解构,结合2024—2026年业界与学术前沿进展,系统阐述构建未来就绪(Future-ready)本体底座的技术路径,为决策者提供从选型、架构到演化治理的全景视角。
图1.1 Palantir Foundry 解构说明
Palantir Foundry 本体系统:一种“数据即代码”的架构典范
Palantir的核心战略价值在于其倡导的“数据即代码”理念。它彻底打破了传统的“存储—查询”被动模式,将本体定义纳入严密的版本控制体系,实现了业务逻辑的工程化治理。这一理念的本质是将本体视为“可运行的数据”,其Schema、关系约束与操作逻辑像代码一样可审查、可分支、可回溯、可协同。
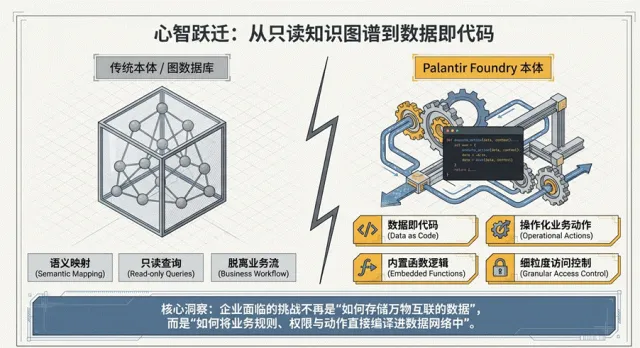
图 1.2 Data as code
分层架构评估:从数据底座到业务执行
Palantir架构通过四层解耦,确立了语义一致性与权限控制的工业标准:
- 原始数据层:支持Parquet/Delta等高效列式格式,并利用零拷贝技术直接挂载Snowflake或BigQuery。该层通过物理隔离确保了海量数据的吞吐能力。
- 本体对象数据层:由Object Storage V2(OSv2)引擎支撑。OSv2在2023年全面替代了代号为Phonograph的初代引擎(OSv1),标志着其从简单的对象存储进化为支持百亿级规模、毫秒级响应的混合存储平台。
- 本体元数据层:作为系统的“大脑”,由OMS管理。其技术栈底层采用PostgreSQL配合JSONB存储Schema,并利用GiST索引极大加速复杂Schema的查询,确保了本体定义的Git式版本演进与分支管理。
- 应用接口层:通过统一的Action API将本体从“只读查询”升级为“双向操作”。该层实现了细粒度的权限管控,确保业务人员在操作对象时,其动作逻辑与数据权限始终保持语义同步。
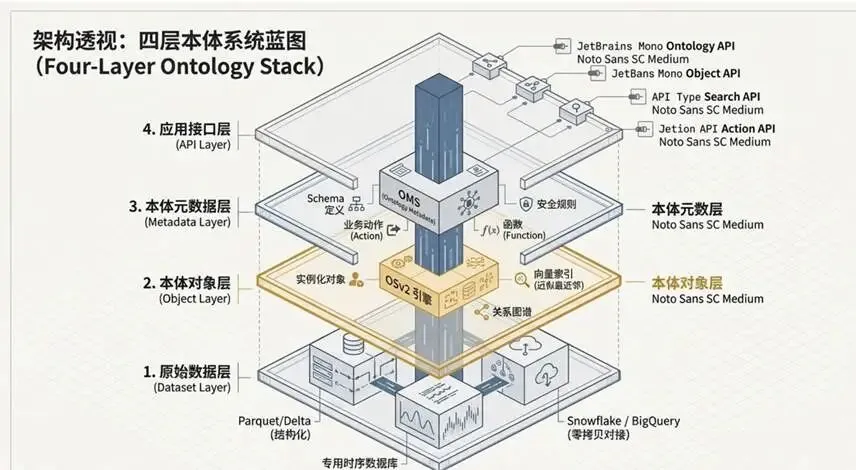
图 1.3 Palantir Ontology Stack
OSv2 混合存储引擎深挖:彻底打破“图与分析”的界限
传统的企业架构中,往往需要 Neo4j 负责图遍历,Snowflake 负责列式分析。这种分裂导致了数据搬运的巨大开销。OSv2 通过**“三合一”模型**彻底化解了这一矛盾:
列式存储与分析性能 :利用Apache Arrow内存格式实现向量化执行,这使得 OSv2 在处理涉及数百万个对象的属性聚合分析时,能够达到亚秒级的响应速度。
高性能图存储模型 :基于 邻接表(Adjacency List)专利级 Search-Around 算法 ,OSv2 能够支撑10 跳(Hops)以上 的超深度关系遍历,这在金融洗钱网络探测中具有决定性优势。
语义检索集成 :原生集成HNSW与DiskANN算法,支持 768 至 1536 维的高维向量索引。这赋予了本体系统处理非结构化语义、实现“概念级搜索”的能力。在事务与一致性 方面,OSv2 采用多版本并发控制(MVCC)与逻辑时钟。其单笔事务可支持 万级(10,000+)对象 的同时修改,并提供 Serializable 级别的隔离,为关键业务的操作化提供了坚实的技术保障, 参看图1.4
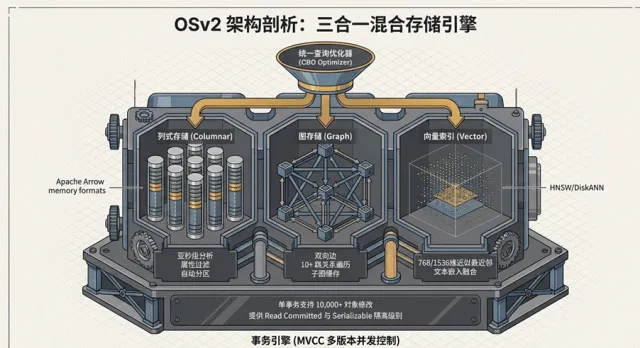
图1.4Osv2 混合存储引擎架构
技术选型多维度横向对比:OSv2 vs. Triplestore vs. Neo4j vs. Neptune
不同的技术路径背后是不同的哲学取向:标准优先(Triplestore) 、 性能与易用性平衡(Neo4j) 、 云原生弹性(Neptune) ,以及 操作性能巅峰(OSv2),参看图1.5:
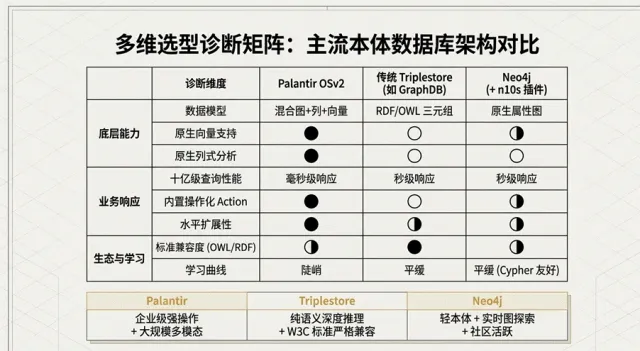
图1.5 多维选型对比矩阵
关键差异诊断
性能跨度对比 :在百亿级对象规模下,OSv2 凭借分层索引与向量化执行,能实现 毫秒级响应;而 Neo4j 在同等规模下的深度遍历往往退化至 秒级 甚至更高。这种千倍量级的差异,决定了 OSv2 能支撑实时业务系统,而其他方案更多处于离线分析阶段。
语义标准 vs. 业务闭环 :Triplestore 在OWL 推理 上具有不可逾越的学术严谨性,适合跨组织的语义标准对接。然而,Palantir 的核心护城河在于其Action/Function 架构 ,它直接定义了数据在改变时应触发的业务逻辑,真正实现了从“看数据”到“做业务”的闭环。
企业级本体建模实践与性能优化策略
本体建模不仅是架构师的技术作业,更是对业务核心逻辑的深度萃取。
建模方法论:三大核心支柱
业务驱动原则 :建模必须以“业务动作”为终点。架构师应首先识别 核心 Action(如:批准信贷、调整库存),倒推所需的本体对象类型,避免陷入过度设计的泥潭。
渐进式演进原则(MVO) :遵循**最小可行本体(Minimum Viable Ontology, MVO)**策略。利用 OMS 的分支管理能力,确保 Schema 能够随业务需求快速迭代,而非试图在首个版本中穷尽所有属性。
数据血缘原则 :建立本体对象到原始数据集的透明映射。利用 Foundry级别的血缘追踪,确保本体层的每一个属性变更都具备端到端的可追溯性,参看图1.6:
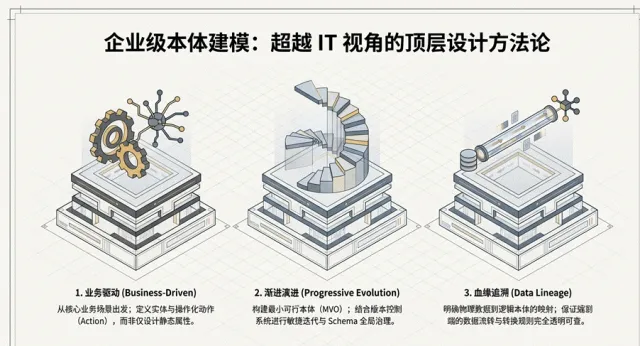
图1.6 企业本体建模方法论
性能优化“处方”:分层存储策略
根据访问频度与业务时效性,架构师应指导实施分层优化策略:
热数据层 (Hot Tier) :存放于NVMe SSD ,采用行式与列式的混合布局,并配合Roaring Bitmap索引压缩技术,确保高并发下的点查性能。
温数据层 (Warm Tier) :存放于SATA SSD ,采用纯列式Parquet格式,针对大规模扫描与统计分析进行优化,支持谓词下推(Predicate Pushdown)。
冷数据层 (Cold Tier) :存放于S3 或 GCS ,主要用于时间旅行查询(Time-travel Query)与审计回溯,通过智能预取机制平衡存储成本与响应能力,参看图1.7.
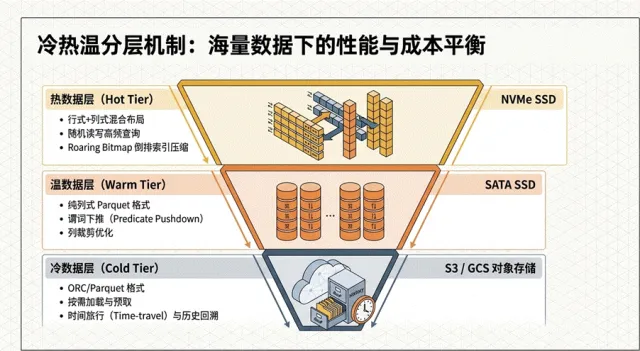
图1.7 三层数据分类
总结与决策建议:构建未来就绪的本体底座
本体存储市场正从“功能碎片化”转向“多模态融合”。企业在选型时必须警惕平台锁定风险,同时确保底层引擎具备足够的演进空间。
选型决策矩阵
推荐方案:Palantir Foundry (OSv2 架构类)
适用场景 :金融反欺诈、全球供应链实时优化、政府公共卫生监测。
核心优势 :极致的操作化能力与百亿级扩展性,支持三合一查询模式。
推荐方案:Amazon Neptune / Neo4j Aura
适用场景 :云原生优先、快速原型开发、社交关系分析。
核心优势 :托管服务运维成本低,开发者社区活跃,具备良好的弹性。
推荐方案:GraphDB / Stardog
适用场景 :学术研究、跨国组织标准对标、复杂知识推理。
核心优势 :严格遵循 W3C 语义标准,OWL 推理能力无出其右 ,参看图1.8.
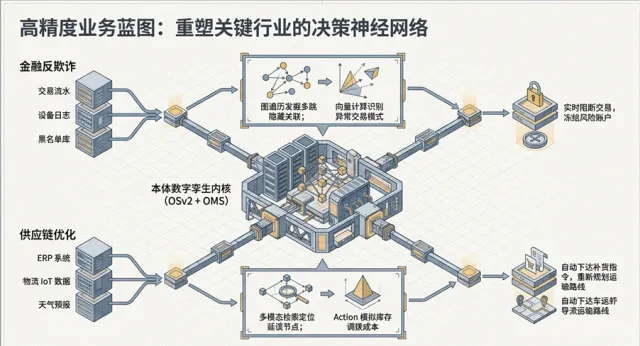
图1.8 企业决策神经系统
前沿趋势与演化方向(2026—2028)
- 多模态深度融合:未来的本体引擎将把时序、向量、图、列式存储融为一体,彻底消除数据搬运。向量与图协同的检索能力已得到多项研究验证,支持语义相似度与结构关系的双重索引与混合检索。
- 大语言模型与语义自动化:大语言模型(LLM)将直接在本体层进行语义映射,实现“自然语言到本体查询”的自动转化,显著降低非技术人员的使用门槛。最新工作显示,将形式化本体知识(如OpenMath)与LLM推理结合,可提升可靠性,但检索质量将直接影响效果。
- 神经符号融合:将本体公理与规则作为神经网络的逻辑约束与可解释层,成为提升可解释性、鲁棒性与数据效率的关键路径。典型范式包括符号知识注入、逻辑约束优化与混合架构等。
- Serverless与存算分离:存储与计算的极致分离将成为标配,本体系统将具备根据查询复杂度自动扩缩容的能力,显著优化运营成本。对象数据漏斗等微服务架构进一步解耦索引与查询子系统,利于横向扩展。
- 时序与双时序建模:时间知识图谱(Temporal KG)与双时序(有效时间+事务时间)引擎的重要性快速上升,支持“某天CEO是谁”“过去已知与现在已知”的时点回溯与演进推理。Kronroe等新一代嵌入式时序图数据库已将双时序事实作为一等公民,原生支持矛盾检测与置信度衰减。
- 联邦知识图谱:在医疗、金融等数据孤岛场景,通过联邦学习实现多机构协同建模,在保证隐私的前提下共享关系嵌入或扩散模型,降低通信成本并提升隐私保护。典型算法包括FEDR、HFKG-RFE、PerFedKG、DFedKG等,针对统计异质性与模型漂移提出对比学习、知识蒸馏与扩散去噪等机制。
- 安全与韧性:在勒索软件与网络攻击加剧的背景下,企业存储需具备端到端防勒索能力,包括不可变快照、基于AIOps的异常检测与行为分析、多域管控与零信任访问等。
总结与决策建议:构建未来就绪的本体底座
Operational Ontology” 意为可操作化的本体,即不仅仅是描述世界的知识结构,还能直接驱动实际的业务动作,形成一个“感知-决策-行动”的闭环,参看图1.9。
知识图谱/本体论(Ontology)技术的一次重要进化:
从 “静态图谱”(只存知识、只支持查询)
→ 跃迁到 “操作化本体”(知识即代码、知识可直接驱动执行)。它特别适合复杂业务场景,例如:供应链管理(查询瓶颈 + 自动补货),智能制造,金融风控
任何需要“感知世界 + 实时行动”的企业级AI系统。
简单来说,这是一个让知识图谱“活起来”,从“会说”变成“会做”的智能系统架构。
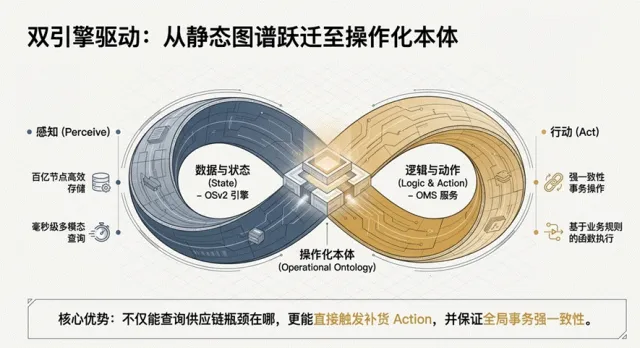
图1.9操作化本体
演进路线与治理建议
- 分阶段迁移:从POC与MVO开始,采用分批迁移与多环境共存的稳妥路径。优先选择对业务影响小、数据质量高的对象类型进行OSv2迁移,建立监控与回滚机制。
- 治理与版本控制:建立类似Git的Schema分支与合并流程,确保Schema变更可审查、可回溯,并通过OMS进行集中治理。
- 分层落地与成本优化:根据热、温、冷策略制定存储分层方案,结合生命周期管理自动归档,平衡性能与成本。
- 安全与合规:将数据安全与访问控制内建到本体层,包括标签与标记、行/列级权限、审计日志与不可变快照,符合行业合规要求。
- 技能建设与跨团队协作:建立由领域专家、数据工程师与本体工程师组成的跨职能团队,共同完成业务动作识别、本体建模与数据血缘管理。
结语:十年维度的战略博弈
CDO/CIO在决策时应具备十年以上的视角。选择一个能够承载企业“数字孪生”愿景的本体存储引擎,不仅是技术选型,更是对企业长期数字资产化能力的战略博弈。在多模态融合、神经符号协同、时序感知、联邦隐私保护与Serverless演进的多重驱动下,本体存储架构的进化才刚刚开始。从理解世界到计算世界,企业级本体系统正从静态知识图谱迈向可操作、可推理、可演化的“企业认知操作系统”,参看图2.0
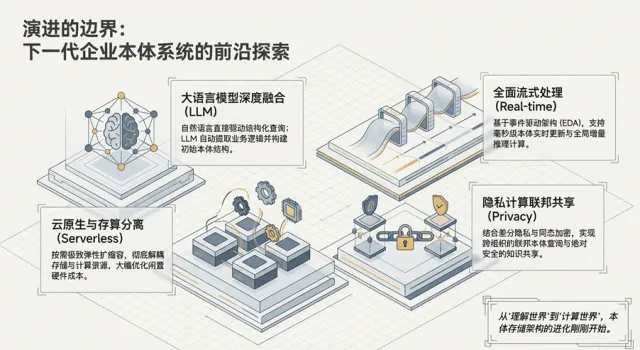
图 2.0, 下一代本体系统蓝图
