


今天真正掐住AI算力中心喉咙的,已经不只是芯片、散热和土地,而是电。
过去十多年,数据中心扩容的底层逻辑一直很朴素:业务上来了,就多配电、多上UPS、多留冗余。只要最坏情况下不断电,供电系统就算合格。这套方法在传统IT时代基本成立,因为负载是分散的、异步的、缓慢变化的。大量服务器各自起伏,彼此抵消,供电系统面对的是一个相对平滑的平均负载。

但AI改写了这一切。国际能源署在2025年报告中指出,全球数据中心用电量2024年约为415TWh,到2030年将增至约945TWh,增幅超过一倍,而AI是这一增长的最重要驱动因素。更关键的是,AI优化型数据中心不是一般意义上的“更耗电”,而是“更集中、更同步、更剧烈地耗电”。
这就是今天算力中心能源问题最容易被误判的地方:真正危险的,不是总电量,而是用电方式。
传统数据中心的问题,是“负载大”;AI算力中心的问题,是“负载像脉冲武器一样工作”。Google在2025年公开披露,其大规模同步ML集群已经出现“数十兆瓦级”的集群功率波动,功率上升几乎是瞬时的,可以每几秒重复一次,并持续数周乃至数月。这不是普通峰值,而是持续发生的高频功率冲击。
一旦把这个问题看清楚,你就会发现,AI时代的数据中心已经不再是“更大的IT机房”,而是“带着极端脉冲负载特征的新型工业电力装置”。
GPU、TPU乃至各类xPU的供电特性,本身就极端苛刻。AnalogDevices的公开技术文章指出,在某些AI加速卡应用中,xPU供电已要求在低于1V的核心电压下提供超过1000A的电流,且AI工作负载会产生极高的di/dt和持续数微秒的电压瞬态,负载功率尖峰可达到其热设计功耗目标的2倍以上。对这类器件来说,平均功率从来不是问题,瞬态供电才是问题。芯片真正害怕的不是“长期没电”,而是“在几十微秒到几毫秒内,电压掉了一下”。这会沿着整条供电链路放大成系统级危机。
先是板级VRM。AI训练和推理的高并行、高同步特性,让GPU板卡出现比传统服务器更陡峭的电流爬升。哪怕多相VRM已经做到很高带宽,只要负载跳变足够快,板上电容总会先被抽空,然后才轮到稳压器追上,电压瞬时跌落就不可避免。再往上,到了PSU、机柜母线和UPS,问题会被进一步放大。UptimeInstitute在2025年指出,大规模AI训练会让GPU功耗在极短时间内冲击到其名义热设计功耗甚至绝对功率上限,持续的热冲击会伤害显卡本身,也会伤害板上VR、焊点和电容。也就是说,今天AI供电问题已经不是“会不会断电”,而是“会不会在持续的瞬态冲击下慢性失效”。
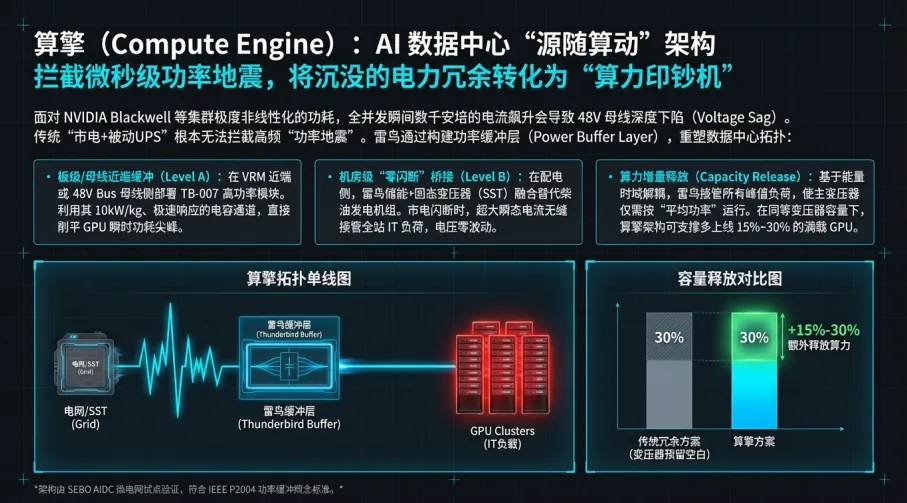
再往上推,整个机柜开始变成一个同步功率源。NVIDIA的官方文档显示,满载的GB200NVL72机柜总功率约120kW。请注意,这不是一整排,而是一柜。它意味着今天的数据中心机柜已经不再只是配电单元,而是高功率密度、强同步、强脉冲特性的电力节点。过去一个机柜5kW、10kW时,供电系统还有缓冲余地;当一个机柜本身就到120kW,任何“几秒内的同步爬升”都会直接打在母线、电源和冷却系统上。
于是,传统“峰值兜底”逻辑开始失灵。“峰值兜底”的底层思路,是为了极少数最坏场景,长期保留大量闲置能力。为了几百毫秒、几秒钟甚至某些短暂工作阶段的尖峰,把UPS、变压器、母线、线缆、冷却系统和配电空间全部按极端峰值配置。这种方法在负载变化慢、峰值不常出现的时代还说得过去;在AI时代,它越来越像一种昂贵而低效的防御性本能。因为你今天面对的已不是偶发峰值,而是高频重复、同步集群、长时存在的波峰波谷。它要求的不是更高静态容量,而是更强动态调节能力。
这正是为什么“用电规模”不是第一性问题,“用电方式”才是第一性问题。
如果负载是一条平滑曲线,超配是有效的;如果负载是一连串尖峰脉冲,超配本身就会变得笨重、昂贵且不可靠。它不仅压低资产利用率,还会把本该用于部署更多算力的CAPEX,浪费在长期闲置的配电冗余上。更重要的是,哪怕你超配了,也未必真能解决问题,因为AI负载挑战的是供电系统的“变化率”,不是“最大值”。

所以,AI算力中心需要的不是“更大电源”,而是“更快电源”;不是“更厚备用层”,而是“更聪明缓冲层”;不是单纯兜底,而是连续调频。
这里所说的“连续调频”,不是电网发电侧传统意义上的AGC调频,而是指:在数据中心供电链路中引入一层毫秒级甚至更快响应的功率缓冲层,让供电系统不再被动追随负载,而是主动整形负载波形。负载冲高时,这层缓冲先顶上;负载回落时,这层缓冲再吸收;主供电、UPS和上级电网看到的,不再是GPU的原始脉冲曲线,而是被平滑之后的功率曲线。
一句话概括:把尖峰留在缓冲层,把稳定留给母线,把确定性留给芯片。
Google2025年披露的full-stackpowershaping已经给出了强有力的方向证明。通过在编译器和系统层面对ML工作负载进行功率塑形,Google把集群级功率波动幅度压低了近50%,把单芯片热点温度波动从约20℃降到约10℃,而性能代价小于1%。这件事的意义极大。它说明AI电力问题不是纯电源问题,也不是纯软件问题,而是典型的“负载侧塑形+供电侧缓冲+系统级调度”协同问题。
这也揭示出未来算力能源架构的三个层次。
第一层,是芯片近端供电层。这里解决的是亚微秒到毫秒级瞬态,包括VRM带宽、板级电容、低阻抗供电路径、垂直供电和未来可能出现的封装内缓冲。AnalogDevices的分析已经说明,AI加速卡的核心挑战不是普通PoL稳压,而是如何在>1000A、<1V、极高di/dt条件下压住瞬态电压偏移。谁能把这层做好,谁就能直接提升sustainedFLOPS,而不是只停留在datasheetFLOPS。
第二层,是机柜与母线侧功率缓冲层。这里要解决的是秒级以内的集群同步波动。未来的高密度AI机柜,不该只配PSU,而必须配“高速功率缓冲器”。它的职责不是在市电断电时撑十分钟,而是在GPU同步拉升时先放、在GPU同步回落时再收,让主供电看到的是经过塑形后的平滑负载。这一层,才是“连续调频供电”的主战场。
第三层,是系统级能源编排层。这里解决的是源-荷-储协同。谁来决定何时让负载更平滑?何时让储能充、何时让储能放?何时让任务错峰?何时让电源按更平缓的斜率爬升?这一层不再只是传统EMS,也不再只是电池BMS,而是算力调度系统和能源调度系统的融合层。Google提到的功率感知工作负载分配、水冷、垂直供电和编译器级塑形,本质都在往这一层走。
所以,未来的数据中心电力系统会从“事故型供电架构”变成“运行型供电架构”。
传统UPS和BBU的核心价值是事故应对:掉电了,顶住;市电断了,接管。但AI时代真正需要的是运行时持续参与的功率缓冲资产。今天如果储能仍然只是备份电源,那它就只是一个昂贵的保险箱;只有当它参与连续调频、削峰填谷、瞬态支撑和负载塑形,它才真正成为算力中心的一部分。
这一点,对设施投资逻辑的冲击远比多数人想象得大。
在“峰值兜底”模式下,电力系统是成本中心;
在“连续调频”模式下,电力系统开始变成生产工具。
前者的目标是“不出事”,后者的目标是“多出算力”。前者追求的是极端安全边界,后者追求的是在安全边界内把持续算力推到更高。前者的思路是多花钱买冗余,后者的思路是用动态调节换效率。
这不是同一个问题。
把问题说得更尖锐一点:未来算力中心最贵的,不会是电费,而是“被供电方式浪费掉的算力”。
当GPU因瞬态压降而降频,当主供电因同步尖峰而必须长时超配,当UPS因频繁误触发而寿命缩短,当机柜因母线波动而被迫限制上限时,你损失的不是几度电,而是整座算力工厂的有效产出。真正的隐性成本,来自算力没能以应有的方式持续输出。
这也是为什么“能源供给侧革命”这个说法并不夸张。
它首先是一场电源工程革命:供电系统必须从以稳态容量为核心,转向以动态调节能力为核心。它也是一场架构革命:算力、储能、母线和调度必须被当作一个系统来设计,而不是分属于不同部门、不同设备、不同采购包。它更是一场经营革命:未来的数据中心竞争,不只是谁拿到更多电力指标,而是谁能把同样的电力指标转成更多稳定算力。
因此,真正的结论不是“AI数据中心将消耗更多电”,而是:AI数据中心正在迫使整个能源系统改写自己的响应逻辑。
谁还把供电看成后台配套,谁就会被AI的功率脉冲拖垮。谁先完成从“峰值兜底”到“连续调频”的跃迁,谁就会真正掌握下一代算力基础设施的统治力。
未来的算力中心,只会分成两类。一类,仍然停留在传统思维中,把AI当成“更大一点的IT负载”,于是继续用更粗的线缆、更大的UPS、更高的母线冗余去死扛脉冲波动。这类系统短期能跑,但会越来越贵、越来越重、越来越脆弱。另一类,则会承认一个新现实:AI芯片不是普通负载,GPU集群不是普通机柜,供电系统也不能再只是“备用系统”。
它们会把功率缓冲层做成实时运行资产,把工作负载塑形做成调度系统的一部分,把储能从事故备份变成连续调频单元,把电力系统从静态配置改写为动态控制系统。
那时,供电不再只是给芯片“供电”,而是在给算力“做节奏管理”。这就是为什么,AI算力中心的下一场真正革命,不在算力侧,而在能源供给侧。这不是一个辅助命题,而是决定AI基础设施上限的主命题。未来算力中心之间的竞争,表面上看是模型之争、芯片之争、集群之争,底层上看,首先是“谁能把电化成算力”的能力与效率之争。而这场竞争的分水岭,就是今天开始,从“峰值兜底”转向“连续调频”的范式之变。
作 者:AITony
审 核:王海霞
编 校:张 芳