


极致带宽需求 分布式训练集群需要在数万个加速器间移动海量数据,对网络吞吐量的要求远超传统工作负载。这也是我们星球中之前就说NV不会大规模使用CXL的原因之一(在GTC之前,市场就有人在传GTC上老黄要提CXL)。 高可靠性要求 在包含 5 万+光链路的大规模网络中,单个模块故障在统计上不可避免。但每一次故障都可能导致价值数百万美元的训练任务中断,造成计算资源的严重浪费和网络资源碎片化。 液冷集成需求 现代 AI 加速器产生的热负载已超出传统风冷能力。液冷正在成为超大规模 AI 数据中心的基础设施标配,这对每个机架内的组件都提出了严格的热设计约束。关于XPO的液冷,目前市场上讨论的人还不多,因为目前光模块跟液冷并没有啥关系,可能很多人还并不知道XPO里面是有冷板的。 功耗效率压力 高密度机架运行在有限的功耗预算内,网络消耗的每一瓦都意味着计算资源的减少。光学互连必须实现显著更低的每比特功耗。 密度瓶颈 物理空间是数据中心的稀缺资源。当前 OSFP 标准每 1U 仅支持 32 个模块,密度不足迫使网络架构师部署更大、更复杂的多层网络拓扑,增加了延迟、成本和布线复杂度。
实现 204.8Tbps 交换容量需要 4 个机架单元
无法高效集成液冷系统
功耗和密度的矛盾日益突出
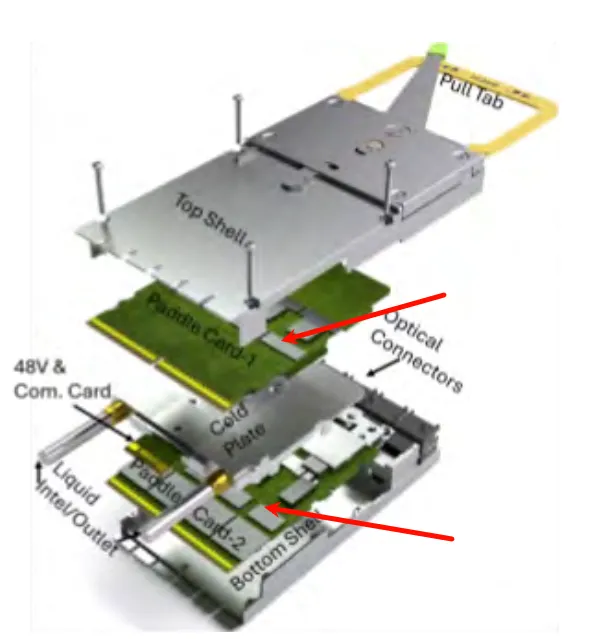
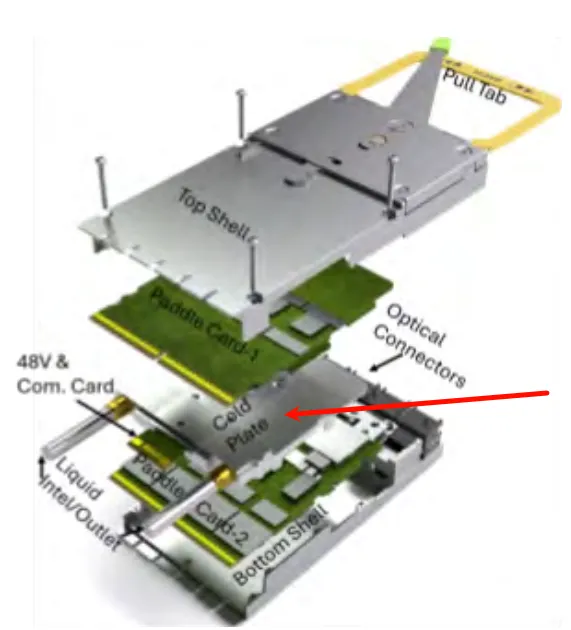
高速发送(Tx)和接收(Rx)信号分离到桨板卡的相对侧,最小化串扰
提供优化的线性信道,非常适合线性驱动可插拔光学(LPO)
功率和低速控制信号(I2C/I3C、复位、中断)通过完全独立的专用卡边连接器路由
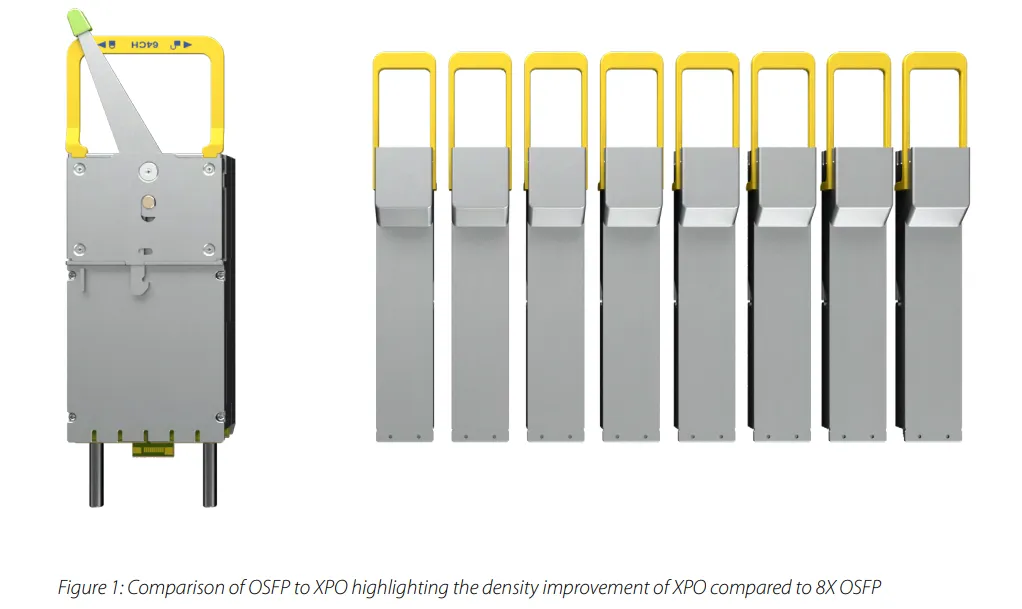
用 OSFP 的话,机架总带宽是 1.6 Pbps,能装 8 台 204.8T 交换机,整个机架功耗 32kW。
换成 XPO 呢?机架总带宽飙到 6.5 Pbps,能装 32 台交换机,功耗 128kW。带宽密度直接翻了 4 倍。
400MW AI 数据中心
支持 128,000 个 XPU(GPU 或其他加速器)
Scale-up 网络:12.8Tbps/XPU
Scale-out 网络:1.6Tbps/XPU
三层 Clos 拓扑

知识星球
