


从收藏夹吃灰到主动沉淀
之前一直是有需求才整理材料,虽然看了很多内容,但一直没有很好的沉淀形式,很多内容往往都躺在了文件夹/收藏夹里。
去年开始有意识地保持一个习惯:看到值得记录的AI行业内容——论文、深度文章、行业动态——会写下自己的判读,整理到相关的文档里。
不跟着 FOMO 走
这个行业每天都有人喊革命、喊颠覆、喊泡沫。有用的做法不是跟着FOMO情绪走,而是回到几个基本问题:
· 任务口径是什么?
· 需求场景是什么?
· 评测怎么设计的?
· 数据从哪来?
· 结论的适用边界是什么?
最大收获:判断框架,不是知识量
这个积累的过程,最大的收获不在于"懂了多少模型知识",而是做着做着学会了怎么在信息过载的环境里建立自己的判断框架。
早年在公司内网博客上写过两篇关于"怎么看第三方数据"和"怎么读研究报告"的文章,核心就四句话:看利益结构、看方法支撑、看口径偏差、看适用边界。
这个思路放到今天看AI行业的各种论文、报告、产品发布,依然够用。所以这个仓库与其说是"资料库",不如说是一个人持续训练判断力的过程记录。
做这套东西的初衷
AI领域的信息太多了,但大部分信息的半衰期不超过两周。
真正有价值的不是跟上每一条新闻,而是形成自己可复用的判断框架——知道什么值得关注、什么可以忽略、什么需要持续跟踪。
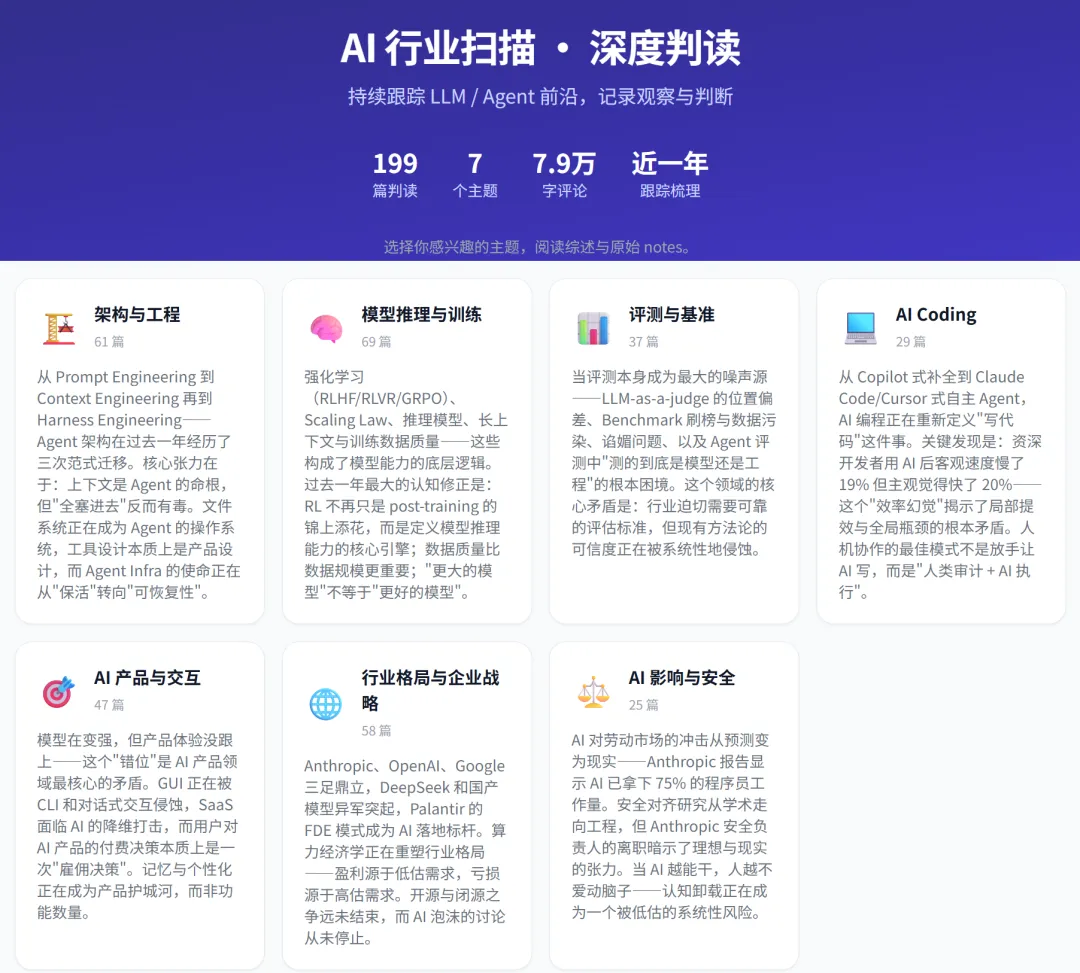
内容索引
所有内容按主题做了综述和展开,建议按兴趣挑着读。涵盖:Agent与上下文工程、评测与Benchmark、商业化与SaaS、模型能力与训练范式、公司与竞争格局、安全与治理等主题。
在线阅读地址:
https://blackshady1130-jpg.github.io/AI-knowhow-kit/
原始信息更新地址:
https://docs.qq.com/sheet/DYVFybXVvTk1YZm5B
如果你也在关注 LLM 的落地、评测、Agent 工程化这些方向,欢迎一起讨论。