


Arista Networks 近期发布了XPO 白皮书,内容涵盖了行业背景、技术痛点到 XPO 架构细节(机械、散热、电气)及系统级对比。
一、摘要
The explosive growth of Artificial Intelligence (AI) workloads is fundamentally reshaping the requirements for data center infrastructure. Next-generation AI clusters demand dramatically higher bandwidth density, improved thermal management, and greater system-level reliability than traditional cloud data centers were designed to support. To address these challenges, Arista Networks, together with an ecosystem of more than 45 industry partners, introduces eXtra-dense Pluggable Optics (XPO). XPO represents a new class of optical pluggable module designed specifically for next-generation AI data center fabrics. Each XPO module delivers 12.8Tbps of bandwidth using 64 electrical lanes and incorporates an integrated liquid-cooled cold plate capable of supporting 400W+ module power consumption.
中文翻译:
人工智能(AI)工作负载的爆炸式增长正在从根本上重塑数据中心基础设施的需求。与专为支持传统云数据中心而设计的标准不同,下一代 AI 集群需要极高的带宽密度、改进的热管理能力以及更高的系统级可靠性。为了应对这些挑战,Arista Networks 联合超过 45 家行业合作伙伴生态系统,推出了超密集可插拔光学模块(XPO)。XPO 代表了一类专为下一代 AI 数据中心架构设计的全新可插拔光模块。每个 XPO 模块利用 64 条电气通道提供 12.8Tbps 的带宽,并集成了液冷冷板,能够支持超过 400W 的模块功耗。
二、AI 基础设施需求增长
The exponential growth of artificial intelligence (AI) and machine learning workloads is fundamentally reshaping data center architecture. This transformation is placing unprecedented pressure on network infrastructure, pushing existing interconnect technologies far beyond their original design limits. The core challenge stems from a simple reality: AI data centers require orders of magnitude more bandwidth than traditional cloud data centers. This dramatic increase in required throughput cannot be addressed through incremental improvements alone; it requires a fundamental re-evaluation of interconnect technologies.
中文翻译:
人工智能(AI)和机器学习工作负载的指数级增长正在从根本上重塑数据中心的架构。这种变革给网络基础设施带来了前所未有的压力,将现有的互连技术推向了其原始设计极限之外。核心挑战源于一个简单的现实:AI 数据中心所需的带宽比传统云数据中心高出几个数量级。这种所需吞吐量的急剧增加无法仅通过渐进式的改进来解决;它需要对互连技术进行根本性的重新评估。
三、AI 网络光互连的五大关键需求
- Extreme Bandwidth: Training large-scale AI models across distributed clusters of accelerators requires significantly higher network bandwidth than traditional data center workloads.
- High Reliability: In large-scale AI fabrics comprising tens of thousands of optical links, component failures become statistically inevitable. A single failure can disrupt or halt a multi-million-dollar training job.
- Liquid Cooling: The immense computational density of modern AI accelerators generates thermal loads that exceed the capabilities of traditional air cooling.
- Power Efficiency: Every watt consumed by the network is a watt unavailable for revenue-generating compute resources.
- Unprecedented Density: The density limitations of current standards present a significant barrier; for example, OSFP supports only 32 modules per 1U.
中文翻译:
- 极致带宽: 在分布式加速器集群上训练大规模 AI 模型,所需的网络带宽远高于传统数据中心的工作负载。
- 高可靠性: 在包含数万个光链路的大规模 AI 架构中,组件故障在统计学上变得不可避免。单点故障可能会中断或停止耗资数百万美元的训练任务。
- 液冷支持: 现代 AI 加速器的巨大计算密度产生的热负载,已经超过了传统风冷的能力极限。
- 能效比: 网络消耗的每一瓦特电力,都意味着用于产生收益的计算资源少了一瓦特。
- 前所未有的密度: 当前标准的密度限制构成了重大障碍;例如,OSFP 每 1U 机架单元仅支持 32 个模块。

图1:XPO与8个OSFP光模块对比图,展示XPO密度的显著提升
四、解决方案概览 - Arista XPO 可插拔光模块
The Arista XPO module is a purpose-built solution designed from the ground up to address the unique challenges of hyperscale AI data centers.
- Bandwidth: Each XPO module delivers 12.8Tbps of bandwidth, configured as 64 channels at 200Gbps.
- Density: XPO delivers 8× the bandwidth of OSFP, 4× front panel density of OSFP, enabling up to 204.8Tbps of switching throughput per Open Rack Unit (1OU).
中文翻译:
Arista XPO 模块是一个专用的解决方案,是从零开始设计的,旨在解决超大规模 AI 数据中心的独特挑战。
- 带宽: 每个 XPO 模块提供 12.8Tbps 的带宽,配置为 64 个通道,每个通道 200Gbps。
- 密度: XPO 提供 OSFP 8 倍的带宽,以及 OSFP 4 倍的前面板密度,使得每个开放机架单元(1OU)能够实现高达 204.8Tbps 的交换吞吐量。
五、机械架构
To achieve an 8x increase in bandwidth per module compared to standard 1.6Tbps OSFP, XPO abandons traditional single-PCB layouts.
Dual Paddle Cards: Inside the module shell, the XPO architecture contains two separate 32-channel printed circuit boards (PCBs), referred to as paddle cards.
Belly-to-Belly Layout: These two identical cards are arranged in a “belly-to-belly” configuration, facing inward toward a shared central element.
Ejector Mechanism: The XPO module utilizes a mechanical ejector with a release pull tab that provides a 1:11 mechanical leverage to assist operators during insertion.
中文翻译:
为了实现比标准 1.6Tbps OSFP 高出 8 倍的单模块带宽,XPO 放弃了传统的单 PCB 布局。
- 双桨卡设计: 在模块外壳内部,XPO 架构包含两个独立的 32 通道印制电路板(PCB),被称为桨卡。
- 背靠背布局: 这两个相同的卡以“背靠背”的方式排列,面向内侧朝向一个共享的中心元件。
- 弹出机构: XPO 模块采用机械弹出器,带有释放拉片,提供 11:1 的机械杠杆比,辅助操作员在插入时省力操作。
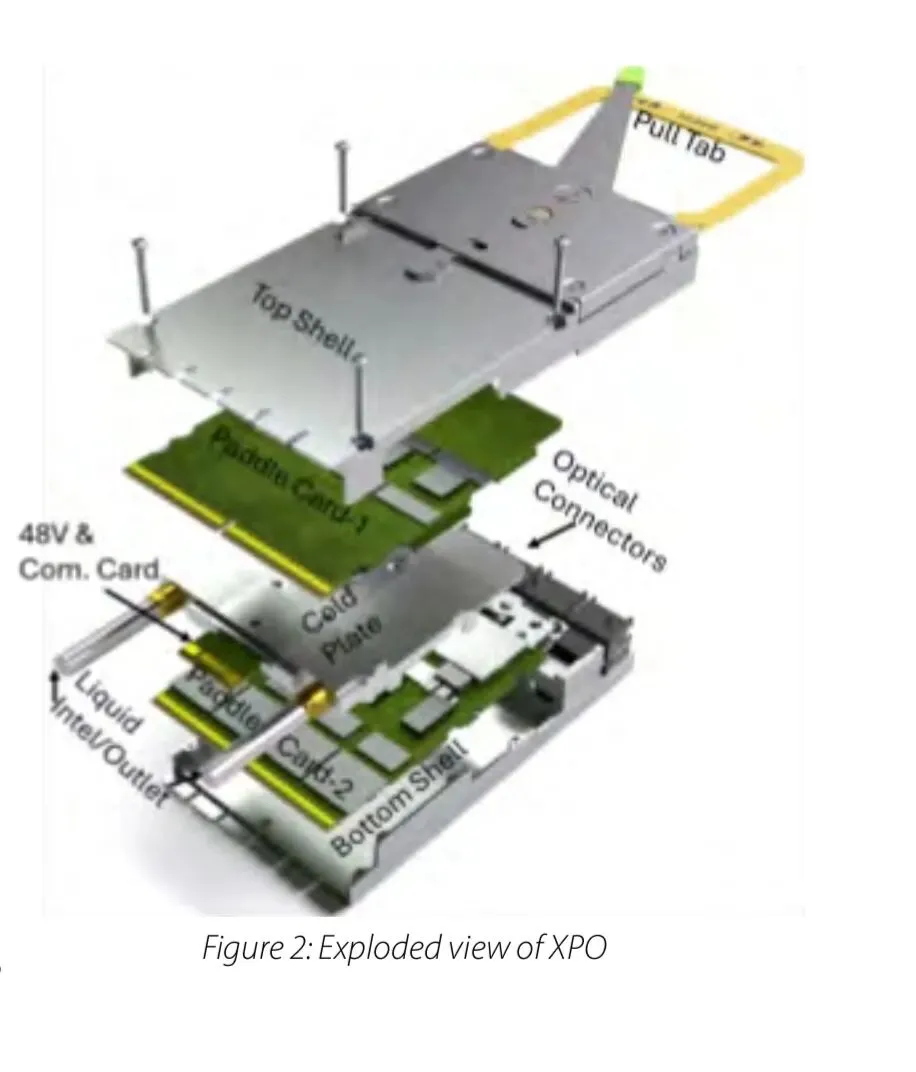
六、集成液冷技术
A defining innovation of the XPO module is its native liquid cooling.
Central Cold Plate: A liquid cold plate is physically sandwiched between the "hot" sides of the two paddle cards, cooling both circuit boards simultaneously.
Thermal Capability: This design efficiently removes heat from high-power modules exceeding 400W. By utilizing 40-45℃ warm-water liquid cooling, XPO keeps component temperatures 20℃ to 25℃ lower than air-cooled equivalents.
Fluid Interface: The module features integrated fluid channels and connects to the host system's cooling manifold via blind-mate, quick-disconnect liquid connectors.
中文翻译:
XPO 模块的一个定义性创新在于其原生液冷设计。
- 中心冷板: 液冷冷板物理上被夹在两个桨卡的“热”侧之间,同时冷却两块电路板。
- 散热能力: 该设计能高效地从超过 400W 的高功耗模块中移除热量。通过利用 40-45℃ 的温水液冷,XPO 使组件温度比同等的风冷方案低 20℃ 至 25℃。
- 流体接口: 模块具有集成的流体通道,并通过盲插式快断液连接器连接到主机系统的冷却歧管。
七、电气接口与 50V 供电
- Clean Linear Channel: High-speed Transmit (Tx) and Receive (Rx) signals are separated onto opposite sides of the paddle cards to minimize crosstalk, providing an optimized linear channel ideal for Linear drive Pluggable Optics (LPO).
- Dedicated Power/Control Connector: Power and low-speed control signals are routed through a completely separate, dedicated card-edge connector located in the center of the module.
- 50VDC Architecture: XPO introduces a 46V to 53V DC input (nominally 48V or 50V) directly from the rack's bus bar. This high-voltage input significantly reduces the required current rating and the physical size of the power connectors.
中文翻译:
- 纯净线性通道: 高速发射(Tx)和接收(Rx)信号被分离到桨卡的相对两侧,以最大限度地减少串扰,提供优化的线性通道,非常适合线性驱动可插拔光学(LPO)技术。
- 独立电源/控制连接器: 电源和低速控制信号通过位于模块中心的完全独立的专用板边连接器进行路由。
- 50V 直流架构: XPO 引入了直接来自机架母线排的 46V 至 53V 直流输入(标称 48V 或 50V)。这种高压输入显著降低了所需的电流额定值以及电源连接器的物理尺寸。
八、对比分析
Comparative Analysis: Quantifying the XPO Advantage Over OSFP
To fully appreciate the architectural impact of the XPO module, a direct, data-driven comparison with the incumbent OSFP standard is essential. This analysis evaluates the performance differences at both the individual module level and the rack level, illustrating how innovations at the component level translate into system-wide efficiency gains.
At the most fundamental level, XPO delivers a significant increase in front-panel bandwidth density. To achieve a total switching throughput of 204.8Tbps, an XPO-based system requires only one-quarter of the rack space compared to an equivalent OSFP-based deployment. This represents a clear 4× density improvement over OSFP, enabling network architects to build substantially more powerful fabrics within the same physical footprint.

图3:204.8T交换机选用XPO和OSFP显示出XPO有4倍的密度受益
When this density advantage is applied at the system level within a standard ORv3 (HPR) liquid-cooled rack [4], the benefits become even more significant. The following table compares a fully populated rack based on each optical standard. This comparison reveals an important insight into total cost of ownership (TCO). Liquid cooling infrastructure represents a substantial capital investment, and to justify this expense, rack deployments must typically target 120 kW or higher power density.
An OSFP-based rack, with a maximum power draw of approximately 32kW, significantly underutilizes the available cooling infrastructure. In contrast, an XPO-based rack, operating at approximately 128kW, fully leverages the rack's liquid-cooling capability. This allows the cooling and power delivery infrastructure to be efficiently amortized across a much larger computational payload. This is summarized in Table 1.
Table 1: Rack level comparison between OSFP and XPO
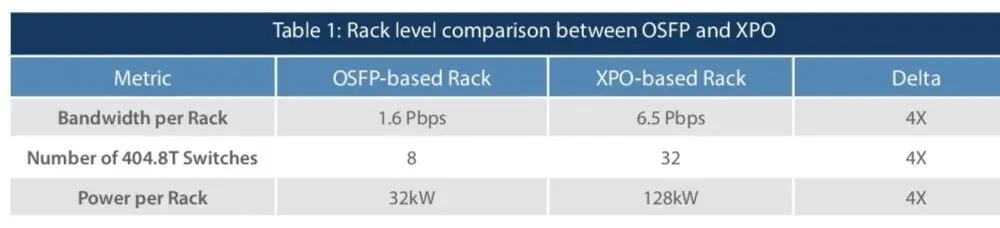
As a result, XPO enables data center operators to deliver 4× greater network capacity within the same infrastructure footprint. By dramatically increasing usable payload within the rack, the relative cost of supporting infrastructure—such as power delivery, cooling systems, and rack space—is effectively reduced. This improvement extends beyond component-level efficiency and begins to reshape the overall economics of large-scale AI data center deployments.
中文翻译:
为了充分了解 XPO 模块的架构影响,必须与现有的 OSFP 标准进行直接的、基于数据的对比。该分析评估了模块级别和机架级别上的性能差异,展示了组件级别的创新如何转化为全系统的效率提升。
在最基本层面,XPO 实现了前面板带宽密度的显著增加。为了达到 204.8Tbps 的总交换吞吐量,基于 XPO 的系统相比同等的基于 OSFP 的部署,仅需四分之一的机架空间。这代表了相比 OSFP 明确的 4 倍密度提升,使网络架构师能够在相同的物理空间内构建功能更强大的网络结构。
当这种密度优势应用于标准的 ORv3 (HPR) 液冷机架的系统层面时,其优势变得更加显著。下表比较了基于每种光学标准的满配机架。该对比揭示了关于总拥有成本 (TCO) 的重要见解。液冷基础设施代表了巨大的资本投入,为了证明这笔开支的合理性,机架部署通常必须以 120 kW 或更高的功率密度为目标。
基于 OSFP 的机架,最大功耗约为 32kW,这极大地未充分利用了现有的冷却基础设施。相比之下,基于 XPO 的机架在约 128kW 下运行,充分利用了机架的液冷能力。这使得冷却和供电基础设施能够有效地分摊到更大的计算负载上。总结如表 1 所示。
表 1:OSFP 与 XPO 的机架级别对比
因此,XPO 使数据中心运营商能够在相同的基础设施空间内提供 4 倍的网络容量。通过大幅增加机架内的可用负载,支撑基础设施(如供电、冷却系统和机架空间)的相对成本得以有效降低。这一改进超越了组件级别的效率,开始重塑大规模 AI 数据中心部署的整体经济性。
九、重新定义数据中心封装尺寸、成本
The true value of an architectural innovation such as XPO is realized when component-level improvements translate into system-level benefits across the data center. The 4× density advantage fundamentally alters data center design by enabling significant reductions in physical footprint, capital expenditure, deployment time, and operational complexity.
Consider an Al cluster of 512 XPUs(e. g,GPUs or other accelerators) connected in a scale-up domain. Assuming 25.6Tbps of bandwidth per XPU, this scale-up domain would require 64 switches with 204.8Tbps capacity each. Using the incumbent OSFPtechnology, which provides 204.8Tbps per 4 rack units, the network would require eight switch racks to deliver the necessary connectivity. In contrast, an XPO-based architecture can support the same cluster using only two switch racks, since XPO enables204.8Tbps switching capacity within a single rack unit, delivering a 4x density improvement.
At hyperscale, this efficiency gain has profound implications. Consider a400 MWAI data center supporting 128,000XPUs. In this scenario, we assume a scale-up network with 12.8Tbps per XPU and a scale-out network with 1.6Tbs per XPU, with the accelerators interconnected through a three-tier Clos topology. Under these conditions, the switching capacity per rack is approximately1.64Pbps with OSFP compared to 6.55Pbps with XPO, reflecting the substantial density advantage provided by the XPO architecture.

图4:从OSFP到XPO,机柜空间降低75%的示意图
This analysis indicates approximately a 75% reduction in required switch rack footprint, along with corresponding reductions in electrical infrastructure, cooling capacity, and plumbing requirements. The impact on capital expenditure can therefore be substantial. For hyperscale Alfacilities requiring billions of dollars in construction costs, such improvements could significantly reduce the number of required buildings or enable far greater compute capacity within the same facility footprint.
Alternatively, operators with existing data centers can leverage this density advantage to increase accelerator density per building,maximizing the utilization of existing infrastructure and real estate. In addition, the higher-radix switches enabled by XPO allow for simpler scale-out network topologies with fewer tlers and lower round-trip latency, directly improving the performance and efficiency of large-scale Al training workloads.
中文翻译:
像 XPO 这样的架构创新的真正价值,在于组件级别的改进转化为数据中心层面的系统级收益时得以实现。4 倍的密度优势通过显著减少物理占地面积、资本支出、部署时间以及运营复杂性,从根本上改变了数据中心的设计。
考虑一个由 512 个 XPU(例如 GPU 或其他加速器)组成的 AI 集群,它们连接在一个纵向扩展(Scale-Up)域中。假设每个 XPU 的带宽为 25.6Tbps,这个纵向扩展域将需要 64 台容量为 204.8Tbps 的交换机。使用现有的 OSFP 技术(每 4 个机架单元提供 204.8Tbps),网络需要 8 个交换机机架才能提供必要的连接性。相比之下,基于 XPO 的架构仅需 2 个交换机机架即可支持相同的集群,因为 XPO 在单个机架单元内实现了 204.8Tbps 的交换容量,实现了 4 倍的密度提升。
在超大规模(Hyperscale)下,这种效率提升具有深远的影响。考虑一个支持 128,000 个 XPU 的 400 MW AI 数据中心。在这种情况下,我们假设纵向扩展网络每个 XPU 为 12.8Tbps,横向扩展(Scale-Out)网络每个 XPU 为 1.6Tbps,加速器通过三级 Clos 拓扑结构互连。在这种条件下,OSFP 的每机架交换容量约为 1.64Pbps,而 XPO 为 6.55Pbps,反映了 XPO 架构提供的巨大密度优势。
该分析表明,所需的交换机机架占地面积减少了约 75%,同时相应减少了电力基础设施、冷却能力和管道设施的需求。因此,这对资本支出的影响可能是巨大的。对于需要数十亿美元建设成本的超大规模 AI 设施而言,这种改进可以显著减少所需建筑物的数量,或者在相同的设施占地面积内实现更大的计算能力。
或者,拥有现有数据中心的运营商可以利用这种密度优势来提高每栋建筑的加速器密度,从而最大限度地利用现有的基础设施和房地产。此外,XPO 支持的高 radix(高端口数)交换机允许采用更简单的横向扩展网络拓扑结构,减少层级并降低往返延迟,直接提高大规模 AI 训练工作负载的性能和效率。
十、核心创新和平台灵活性
XPO’s value stems from a series of engineering decisions that optimize its mechanical, thermal, and electrical design for the specific demands of hyperscale AI data centers, while maintaining broad compatibility with existing and future industry standards.
1. Use of Existing Technology: XPO supports increased capacity per module by leveraging existing photonic and silicon chipset technologies. This approach reduces adoption risk and allows the ecosystem to build upon mature, reliable, and cost-effective manufacturing processes.
2. Integrated Cold Plate: XPO incorporates native liquid cooling through a cold plate embedded between two paddle cards arranged in a belly-to-belly configuration. This design enables highly efficient heat transfer from the optical components and DSPs directly to the liquid cooling system.
3. Clean Linear Channel: Superior signal integrity is achieved using CPC fly-over cables and an optimized edge-connector pin-out. This clean, low-loss electrical channel reduces the need for power-intensive digital signal processing (DSP), contributing to lower overall power consumption.
4. Power Efficiency: In addition to enabling a linear channel architecture, XPO improves power delivery efficiency by utilizing the 50V DC bus-bar voltage directly as the module supply, minimizing power conversion losses within the system.
5. Improved Reliability: Reliability is enhanced through a combination of factors, including reduced component count, lower operating temperatures enabled by the integrated cold plate, minimized temperature variations, and improved signal integrity through the optimized electrical channel.
6. High Density: The XPO module density is achieved by optimizing the module’s physical dimensions for maximum optical density using MPO-16 connectors. This configuration also aligns with the highest density available in high-speed electrical system connectors, enabling efficient routing and packaging. This pragmatic physical design is a key factor in achieving the 4× density improvement over OSFP.
In addition to these core innovations, the XPO platform was designed for maximum flexibility, allowing it to adapt to evolving optical technologies and future industry standards.
中文翻译:
XPO 的价值源于一系列工程决策,这些决策优化了其机械、热和电气设计,以满足超大规模 AI 数据中心的特定需求,同时保持与现有和未来行业标准的广泛兼容性。
1. 利用现有技术: XPO 通过利用现有的光子和硅芯片组技术来支持每个模块的容量增加。这种方法降低了采用风险,并允许生态系统建立在成熟、可靠且具有成本效益的制造工艺之上。
2. 集成冷板: XPO 通过嵌入在两个“肚皮对肚皮”配置的桨卡之间的冷板,结合了原生液冷技术。这种设计实现了从光学组件和 DSP 到液冷系统的高效热传递。
3. 纯净线性通道: 使用 CPC 飞线电缆和优化的边缘连接器引脚排列,实现了卓越的信号完整性。这种纯净、低损耗的电气通道减少了对高功耗数字信号处理 (DSP) 的需求,有助于降低总体功耗。
4. 电源效率: 除了支持线性通道架构外,XPO 还通过直接利用 50V 直流母线电压作为模块电源来提高电源传输效率,从而最大限度地减少系统内的电源转换损耗。
5. 改进的可靠性: 可靠性通过多种因素得到增强,包括减少组件数量、通过集成冷板实现的更低工作温度、最小化的温度变化以及通过优化的电气通道实现的改进信号完整性。
6. 高密度: XPO 模块密度通过使用 MPO-16 连接器优化模块的物理尺寸以实现最大光学密度来实现。这种配置也与高速电气系统连接器中可用的最高密度相匹配,实现高效的布线和封装。这种务实的物理设计是实现比 OSFP 提升 4 倍密度的关键因素。
除了这些核心创新之外,XPO 平台还被设计为具有最大的灵活性,使其能够适应不断发展的光学技术和未来的行业标准。
十一、结论: 使能下一代AI网络
The rapid expansion of artificial intelligence workloads is redefining the performance requirements for modern data center networks. AI clusters demand unprecedented bandwidth, higher reliability, efficient liquid cooling integration, improved power efficiency, and significantly greater front-panel density than traditional optical interconnect technologies were designed to deliver. These emerging requirements are difficult to meet using conventional pluggable solutions such as OSFP.
The XPO architecture addresses these challenges through a purpose-built pluggable module optimized for hyperscale AI infrastructure. By combining a dual-paddle mechanical architecture, integrated liquid-cooling cold plate, clean linear electrical channel, and high-voltage power delivery, XPO dramatically increases optical density while maintaining the operational flexibility and serviceability advantages of pluggable optics.
With 12.8Tbps per module and up to 204.8Tbps per 1OU switch, XPO delivers a 4× improvement in front-panel density compared to OSFP, enabling approximately 75% reduction in switch rack footprint while significantly lowering infrastructure cost and network complexity. At hyperscale, these improvements translate into substantial gains in capital efficiency, operational simplicity, and overall system performance.
By rethinking optical module architecture from the ground up, XPO provides a scalable foundation for next-generation AI networking infrastructure, enabling data center operators to build higher-capacity, more efficient, and more reliable networks capable of supporting the rapidly growing demands of artificial intelligence.
中文翻译:
人工智能工作负载的快速增长正在重新定义现代数据中心网络的性能要求。AI 集群需要前所未有的带宽、更高的可靠性、高效的液冷集成、改进的电源效率以及比传统光学互连技术设计目标大得多的前面板密度。这些新出现的要求很难通过 OSFP 等传统可插拔解决方案来满足。
XPO 架构通过专为超大规模 AI 基础设施优化的定制可插拔模块解决了这些挑战。通过结合双桨卡机械架构、集成液冷冷板、纯净线性电气通道和高压电源传输,XPO 在保持可插拔光学器件的运营灵活性和可维护性优势的同时,大幅增加了光学密度。
凭借每个模块 12.8Tbps 和每 1OU 交换机高达 204.8Tbps 的性能,XPO 相比 OSFP 实现了 4 倍的前面板密度提升,实现了交换机机架占地面积减少约 75%,同时显著降低了基础设施成本和网络复杂性。在超大规模下,这些改进转化为资本效率、运营简单性和整体系统性能的实质性提升。
通过从头开始重新思考光学模块架构,XPO 为下一代 AI 网络基础设施提供了一个可扩展的基础,使数据中心运营商能够构建容量更高、效率更高且更可靠的网络,以支持人工智能迅速增长的需求。