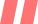从体检报告到企业级AI:我的Skill封装与落地心法
在医疗健康领域,体检报告的解读一直是一个耗时耗力的工作。传统流程中,大夫需要手动阅读数百页的PDF报告,逐一识别异常指标,撰写风险提示和就医建议。这个过程不仅效率低下,而且容易出现遗漏或解读不一致的问题。近期,我们通过WorkBuddy平台,成功将这个复杂的业务场景封装成了一个可复用的AI Skill,实现了从“手工解读”到“智能生成”的跨越。- PDF文本提取 :体检报告是扫描件或PDF格式,需要OCR识别
- AI智能分析 :需要识别异常指标,生成专业的风险提示
- 跨平台兼容 :同事使用Windows系统,需要跨平台支持
- 业务规则约束 :HRA报告不解读,不含运动饮食建议等
体检报告PDF → OCR文本提取 → AI分析 → Word文档生成 → 健康解读报告
- OCR引擎 :RapidOCR(跨平台)+ macOS Vision(备选)+ Tesseract(兜底)
- AI模型 :Ollama本地模型(qwen2.5:7b)或OpenAI API
- 跨平台支持 :Python + Node.js,Windows/macOS/Linux通用
我们首先快速搭建了一个MVP版本,验证核心流程的可行性:# 步骤1:OCR提取python3 parse_pdf.py 体检报告.pdf > ocr.json# 步骤2:AI分析python3 analyze_report.py ocr.json > analysis.json# 步骤3:生成报告node generate_docx.mjs analysis.json 解读报告.docx
- ✅ RapidOCR对中文识别效果优秀,适合体检报告场景
- ✅ Ollama本地模型完全可用,无需依赖外部API
- 明确业务规则 :不解读HRA报告、不提供运动饮食建议、只保留医学异常的解读
- 报告格式标准化 :严格按照模板格式,使用楷体等中文字体
- 跨平台兼容 :从macOS专属的Vision框架改为RapidOCR,支持Windows/macOS/Linux三平台
最关键的一步是将这个解决方案封装成可复用的Skill:health-report-generator/├── SKILL.md # Skill主文件├── scripts/ # 可执行脚本│ ├── ocr_engine.py # OCR引擎│ ├── parse_pdf.py # PDF解析│ ├── analyze_report.py # AI分析│ └── generate_docx.mjs # Word生成└── references/ # 技术文档 └── README.md
| 维度 | SKILL化前 | SKILL化后 |
|---|
| 脚本管理 | 散落在项目目录 | 集中管理 |
| 环境配置 | 手动配置 | 标准化流程 |
| 文档 | 与代码分离 | 内聚在一起 |
| 分享 | 难以分享 | 一键打包 |
# 1. 安装依赖pip install rapidocr-onnxruntime pdf2imagenpm install docx# 2. 启动LLMollama pull qwen2.5:7bollama serve# 3. 生成报告python3 parse_pdf.py 报告.pdf | python3 analyze_report.py | node generate_docx.mjs - 解读报告.docx
或更简单的方式:直接在WorkBuddy中,导入我生成的skill技能,问:- 经验显性化 :将大夫的解读经验固化到AI prompt中
| 指标 | 人工解读 | AI生成 | 提升 |
|---|
| 单份报告耗时 | 30分钟 | 2分钟 | 15倍 |
| 一致性 | 依赖大夫经验 | 标准化输出 | 显著提升 |
| 可扩展性 | 受限于人力 | 弹性扩展 | 无限制 |
基于体检报告Skill的成功经验,可以快速复制到其他场景:只需修改AI分析prompt和报告模板,底层OCR和文档生成能力完全复用。- 标准目录结构(scripts/references/assets)
- 技术封装 :将复杂的AI能力封装成易用的Skill包
数字化转型不是一蹴而就的,而是通过一个个具体场景的AI应用逐步实现的。体检报告生成器的案例告诉我们: 从AI辅助到标准化产品,从单点突破到规模化落地,WorkBuddy Skill为我们提供了一个清晰的路径。通过Skill化封装,我们将复杂的技术能力转化为可复用的企业资产,真正实现了“用AI赋能业务,让数据创造价值”。