



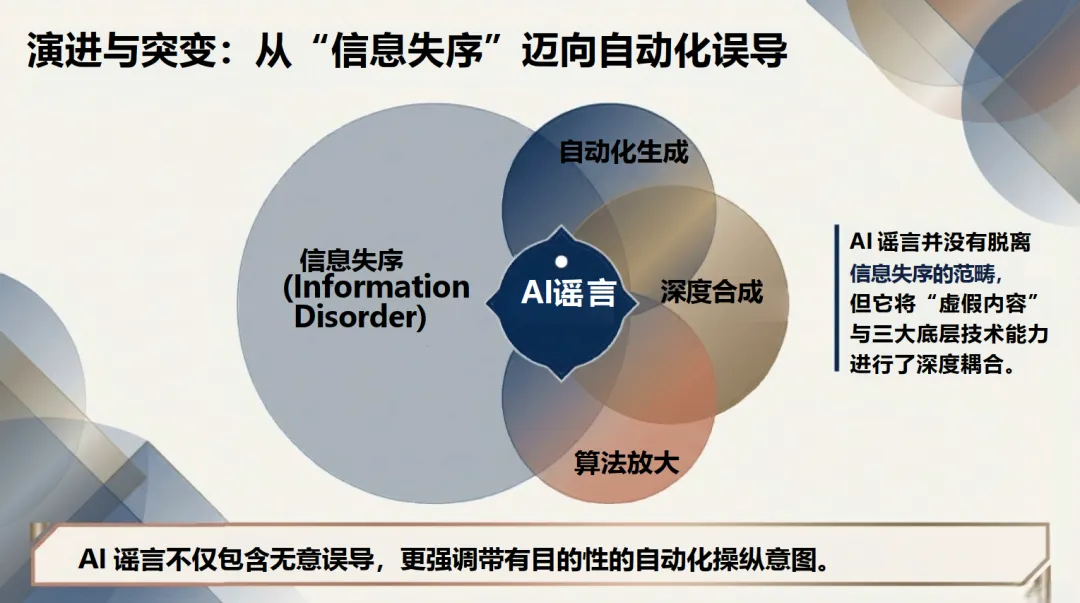
“AI谣言深度研究报告”由清华大学发布。报告系统性地研究了2020至2026年间由生成式AI、深度伪造与算法放大共同驱动的虚假信息现象。报告指出,AI谣言的核心威胁已从“更容易造假”演变为“更容易被信、更容易被放大、更难被及时纠正”,标志着从“信息失序”迈向“自动化误导”的范式转移。
本报告共计:62页。完整版PDF电子版报告下载方式见文末。
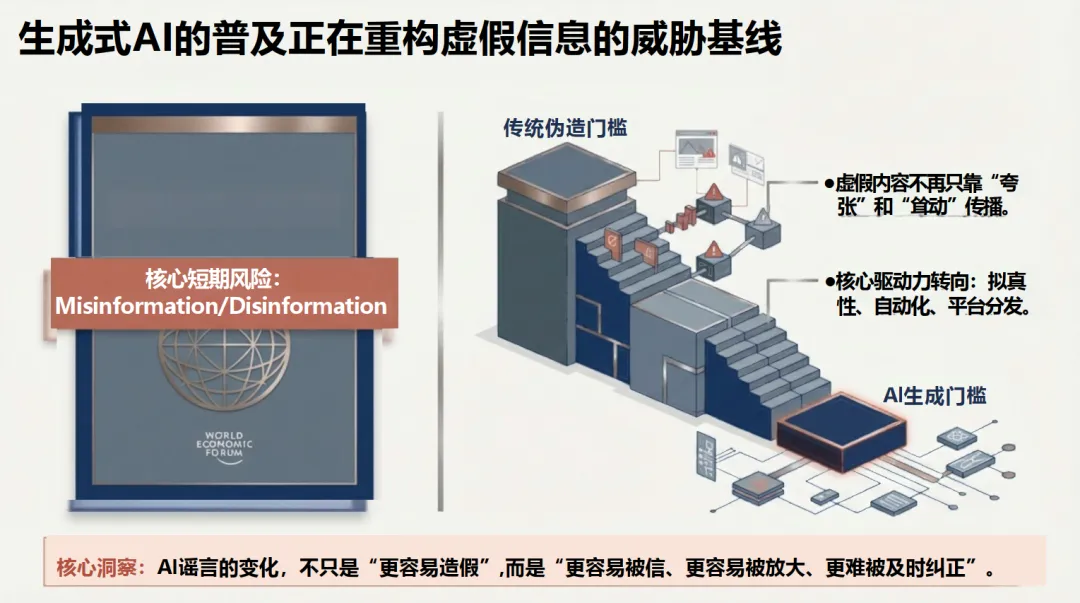
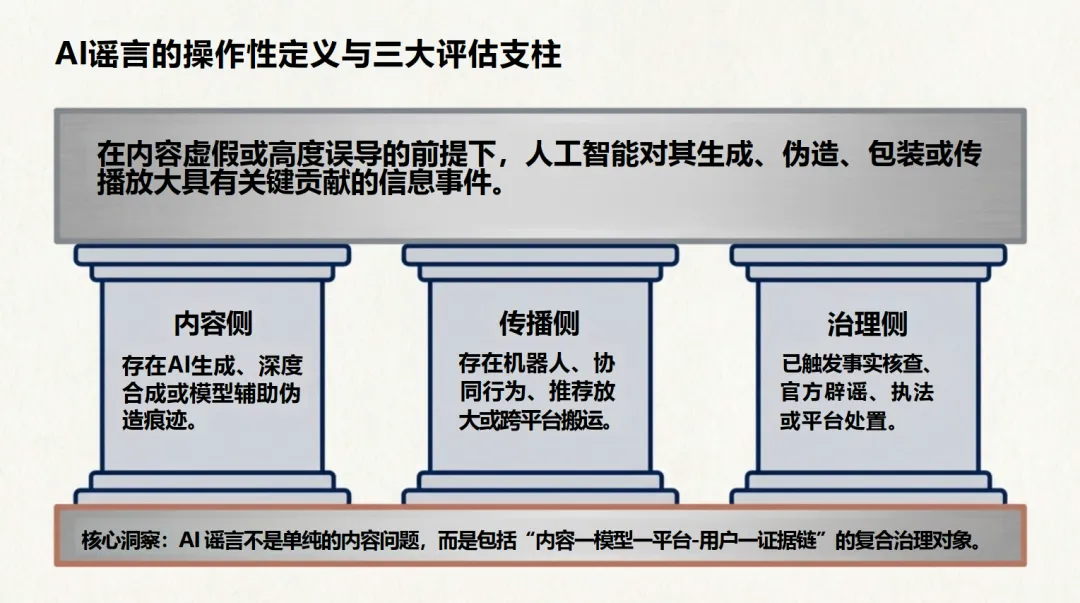
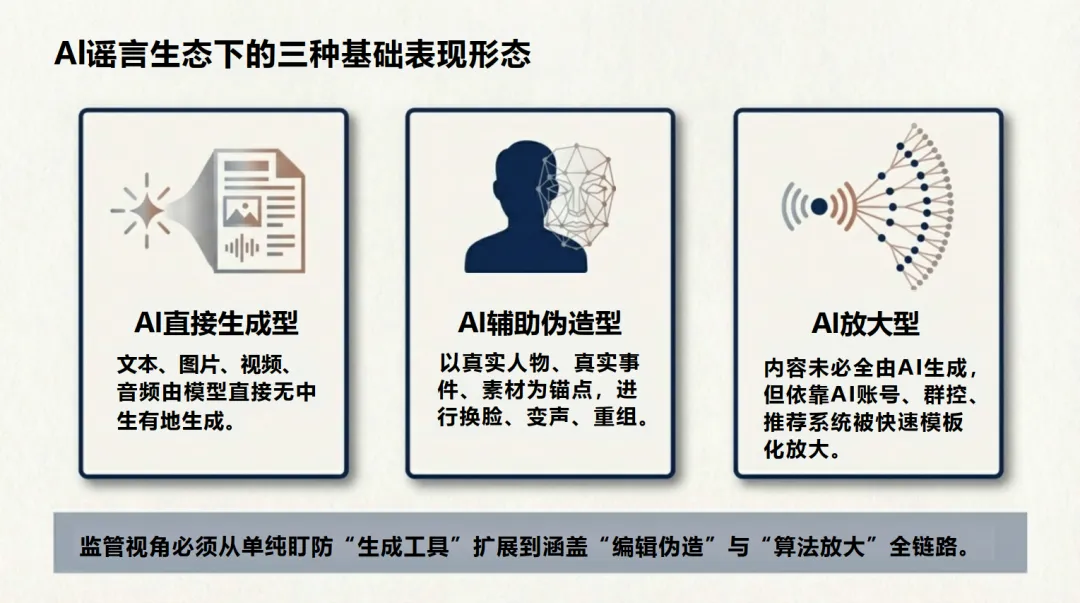
报告将“AI谣言”操作性地定义为:在内容虚假或高度误导的前提下,人工智能对其生成、伪造、包装或传播放大具有关键贡献的信息事件。与传统谣言相比,AI谣言在生成机制(依赖生成模型与风格模仿)、内容质量(语义流畅、画面拟真)和传播模式(依赖算法分发与社交机器人)上均发生质变,其最大危害在于“假得更像真”。
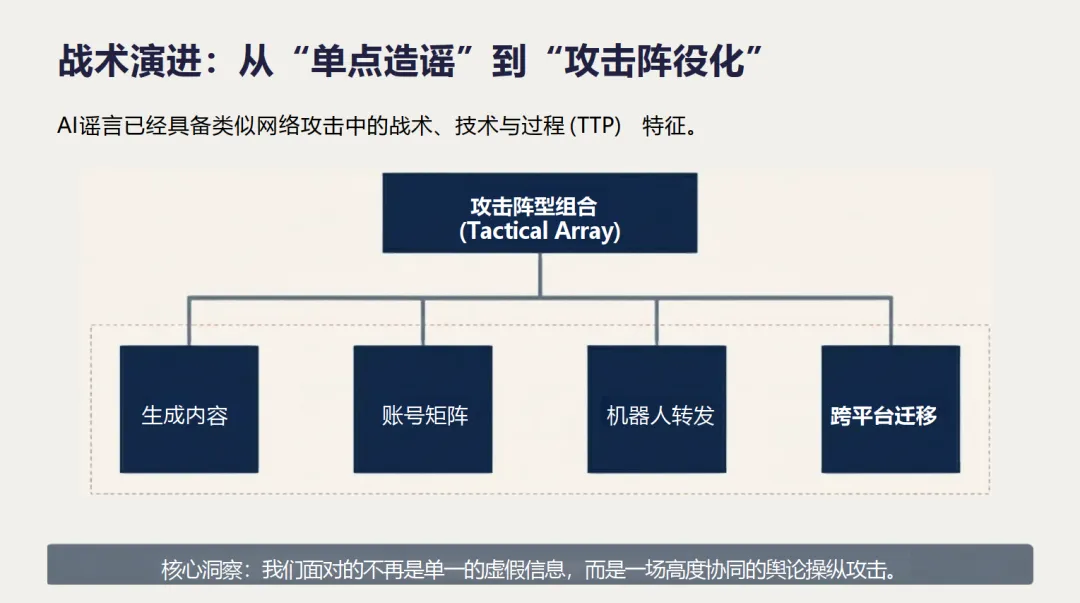
通过对泽连斯基深度伪造视频(2022)、五角大楼爆炸假图(2023)、AI语音克隆干预美国大选(2024)及香港深度伪造诈骗(2024)等一系列典型案例的分析,报告揭示了AI谣言威胁的升级路线:从制造舆论混乱,到触发金融市场波动,再到直接干预民主程序和组织欺诈,其攻击日益“阵役化”和“系统化”。
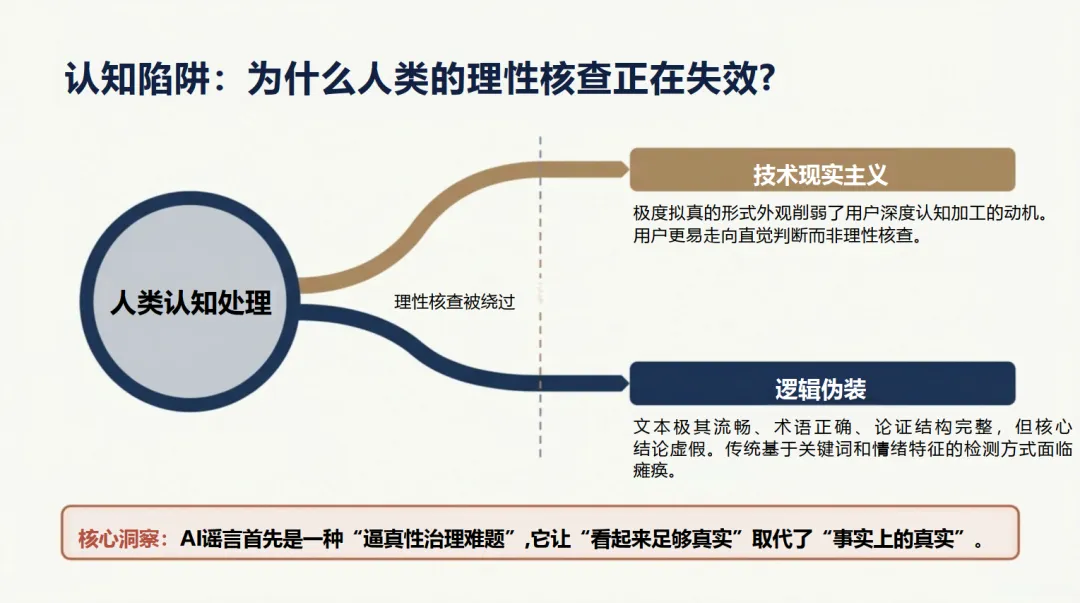
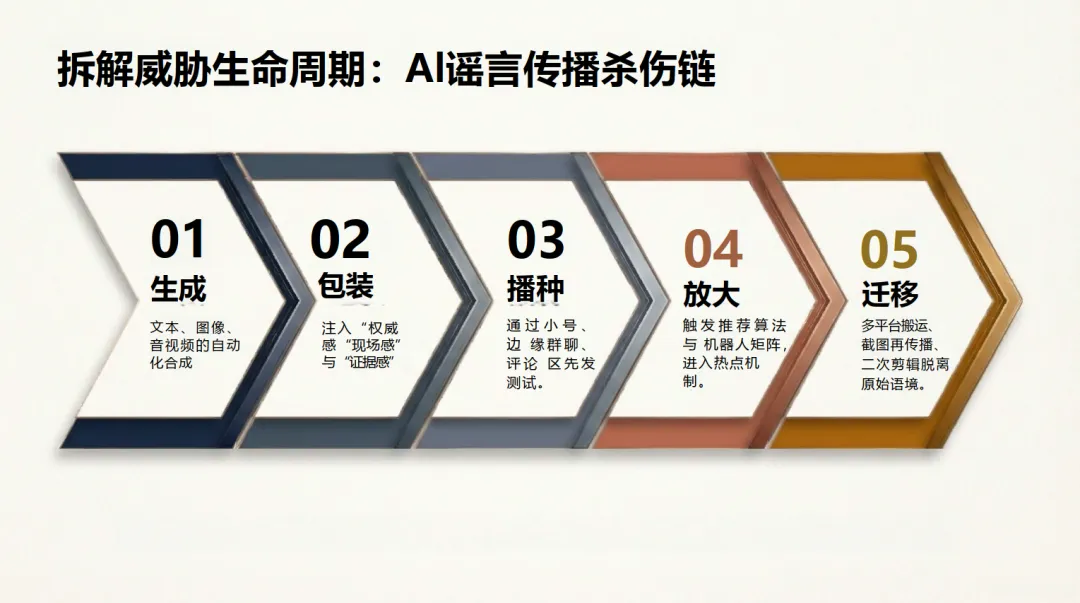
报告深入剖析了AI谣言得以成功的心理机制,即“认知资源劫持”:AI生成内容的“技术现实主义”完美模拟了可信线索,降低了人们深度加工的动机,使直觉替代了理性判断,形成“说谎者红利”。其传播依赖于议题高危化、证据直观化、爆发瞬时化、证伪不对称四大底层法则。
为应对挑战,报告构建了一个涵盖内容层(研判AI伪造特征)、主体层(追踪传播节点与异常行为)和传播层(量化级联效应与辟谣滞后)的三维风险评估架构,并倡导建立基于量化分数的阶梯式应急响应机制。在技术防御上,报告主张告别单一的“神奇检测器”思维,转向构建多路证据交叉验证的网络,并引入“认知-交互-行为”三层检测思路,结合类似RumorCone的先进模型穿透深层语义伪装。
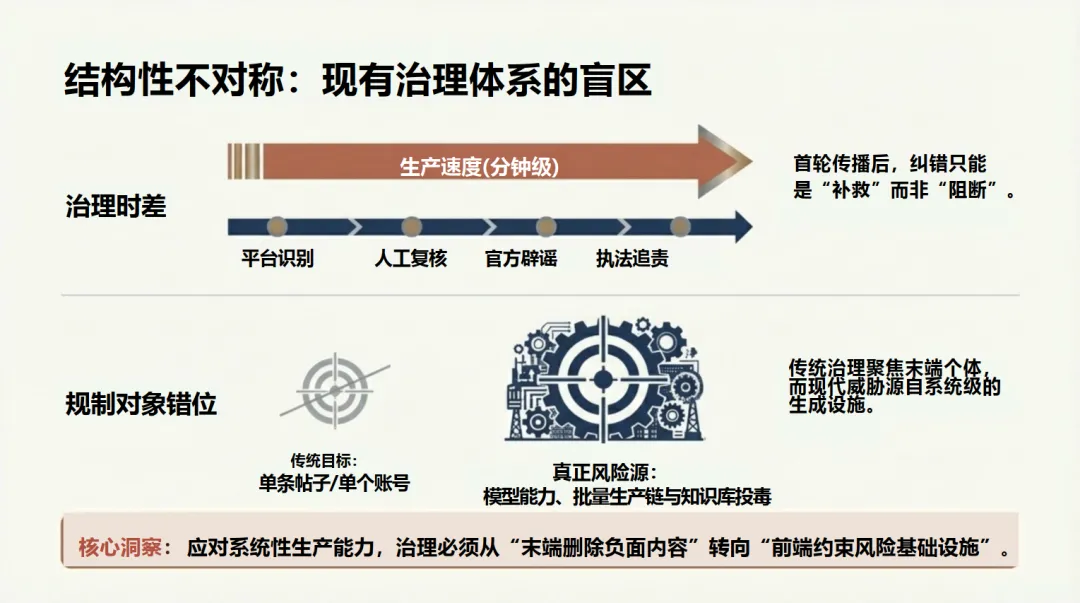
报告最后警示了下一代威胁:针对大模型预训练数据的投毒和对外挂知识库的污染,这可能导致事实核查系统本身被“收买”。因此,治理必须从末端的“事后删除”转向前端的“风险预控”和全链路的动态防御,结合法律、技术、认知与社会协同,以应对这场已演化为系统性社会工程攻击的长期博弈。
幻影视界整理分享报告原文节选如下:





 戳“阅读原文”下载报告。
戳“阅读原文”下载报告。