


技术双刃剑下,我们如何应对“以假乱真”的信息时代?
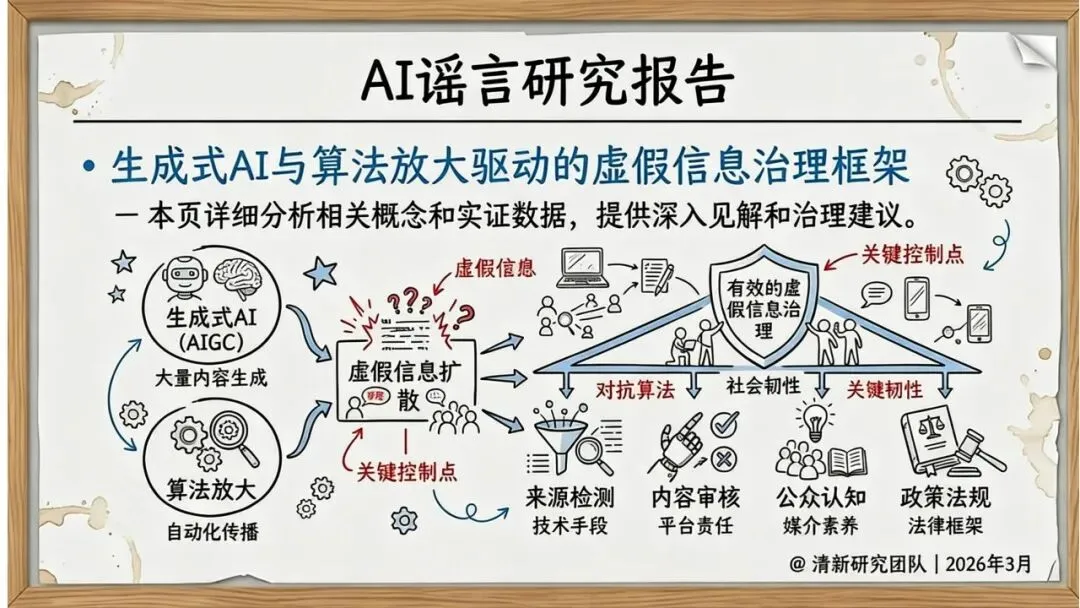
近日,清华大学新闻学院/人工智能学院双聘教授沈阳领导的清新研究团队发布了《生成式AI与算法放大驱动的虚假信息治理框架》研究报告。这份覆盖2019-2026年的研究报告,为我们揭示了AI谣言生成与传播的全貌,并提出了一套可操作的治理框架。
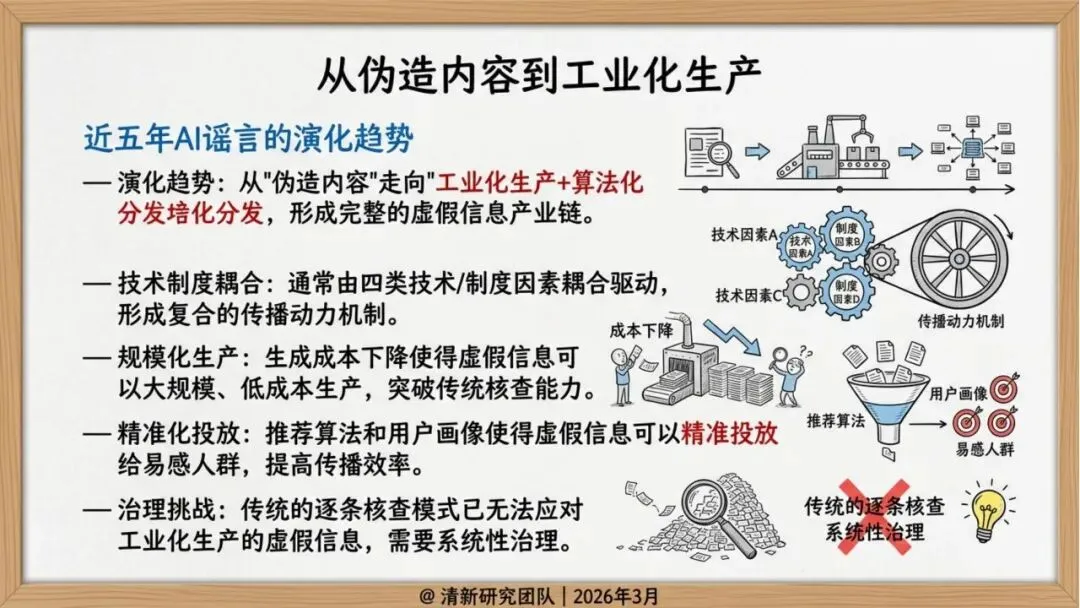
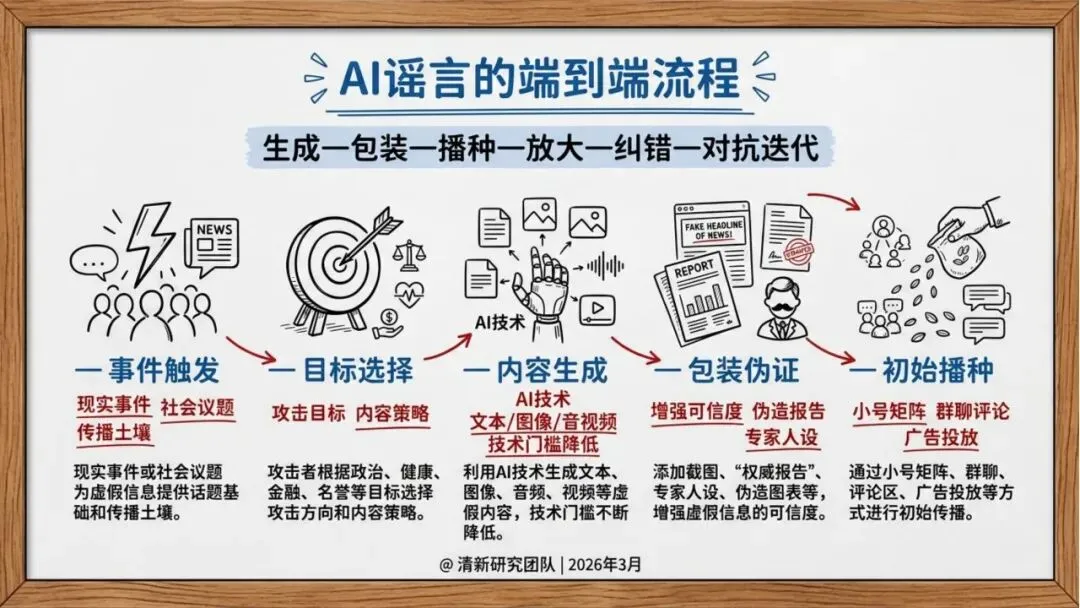
AI谣言:成本下降,逼真度飙升
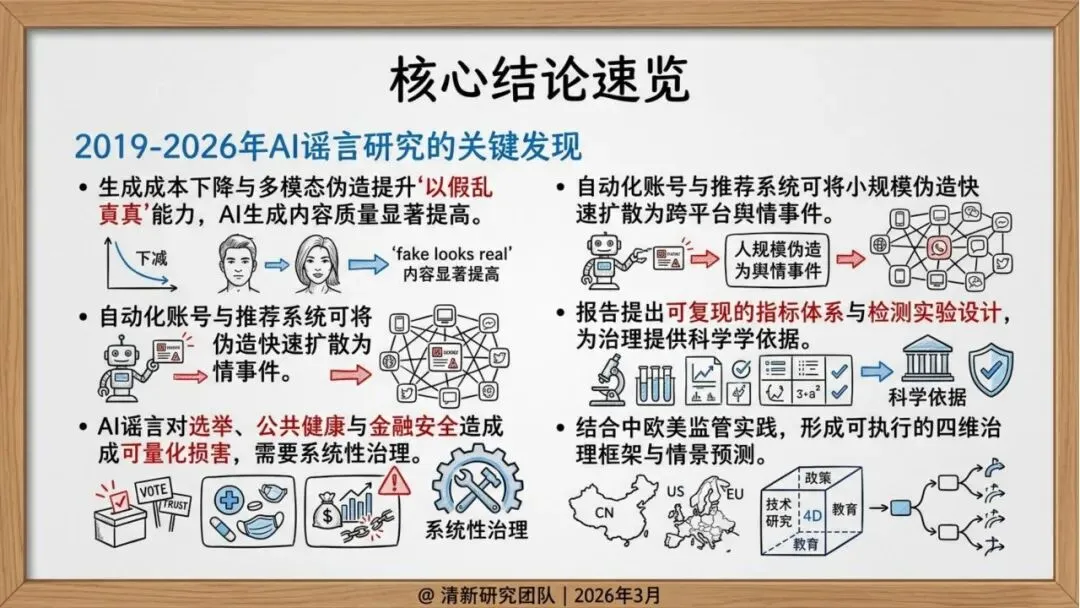
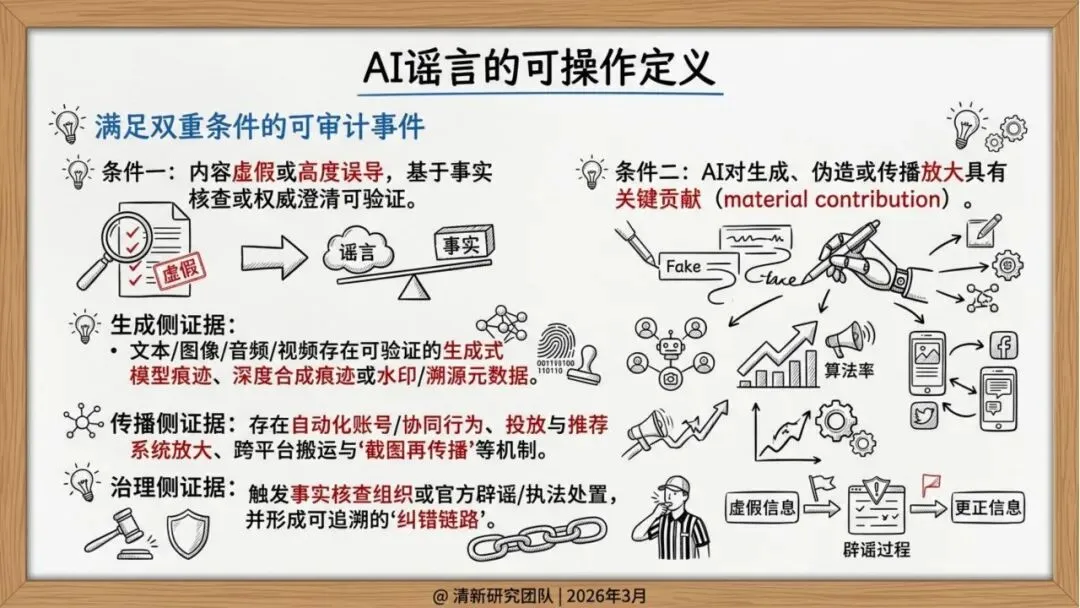
报告显示,从GPT-3到GPT-4,从DALL-E到Sora,生成式AI在文本、图像、视频多模态领域取得突破性进展。生成高质量虚假信息的成本从专业团队降到个人可承受范围,技术民主化带来风险的同时,AI生成内容在视觉、听觉、逻辑上越来越接近真实,普通用户难以分辨。
世界经济论坛已将“AI强化的误导信息”列为突出的短期社会风险,强调其在选举年对社会信任的冲击。
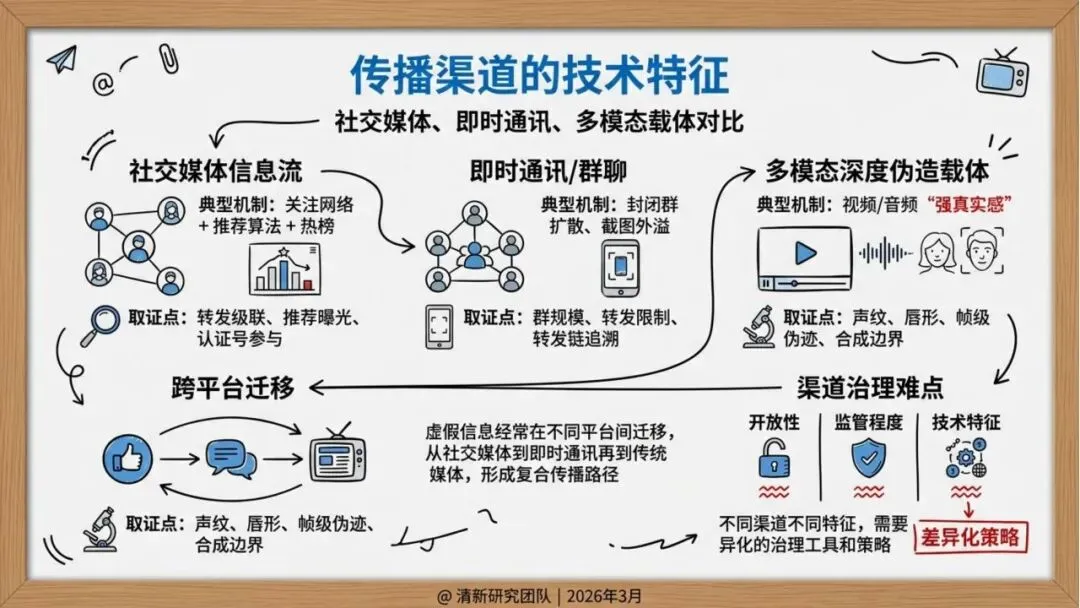
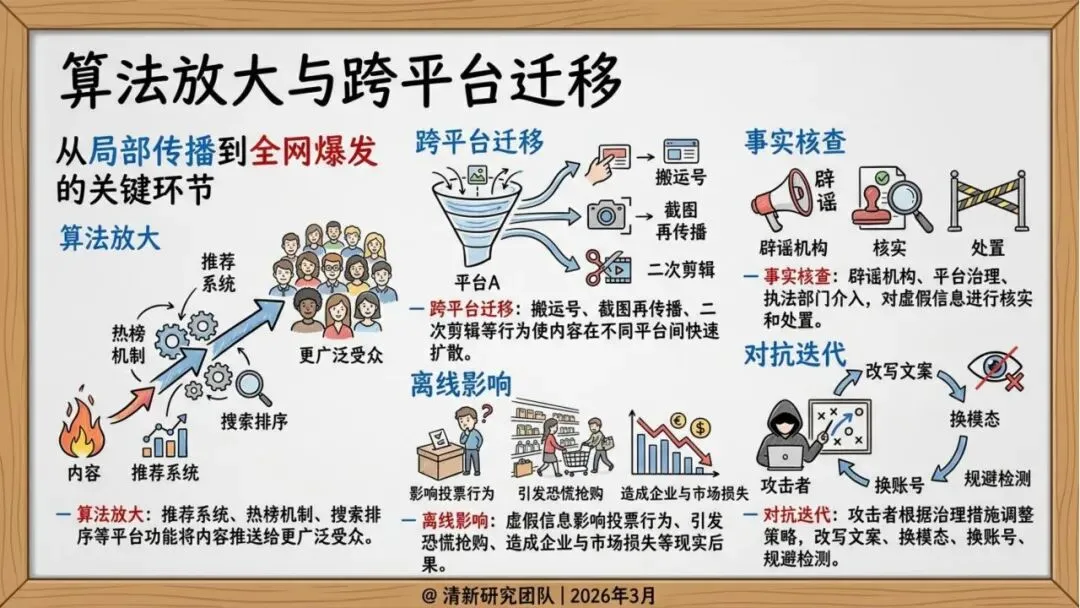
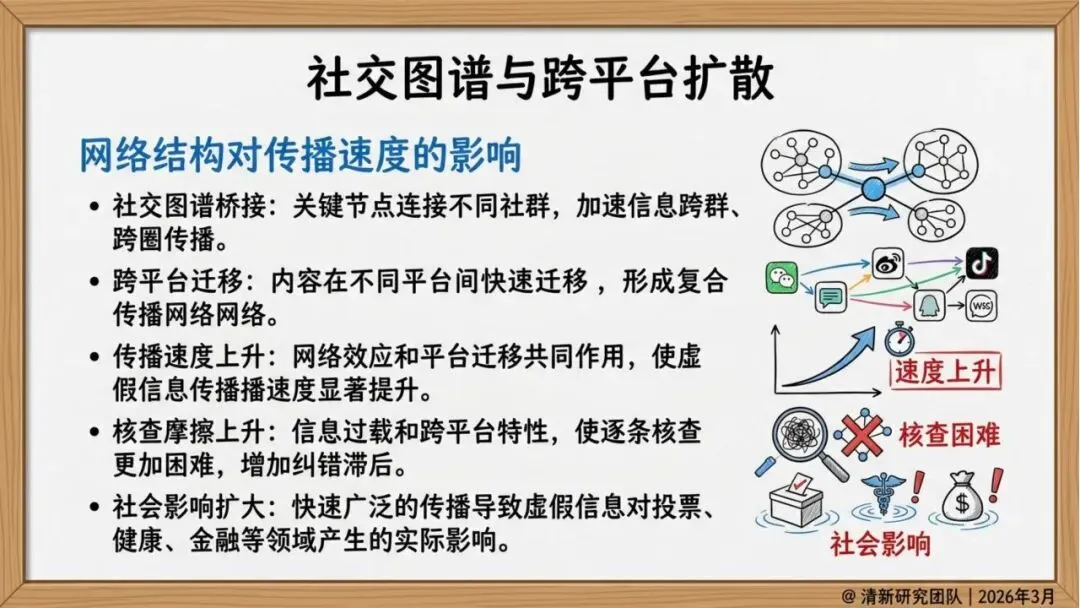
传播机制:算法放大与跨平台迁移
研究发现,虚假信息的传播呈现出明显的技术驱动特征:
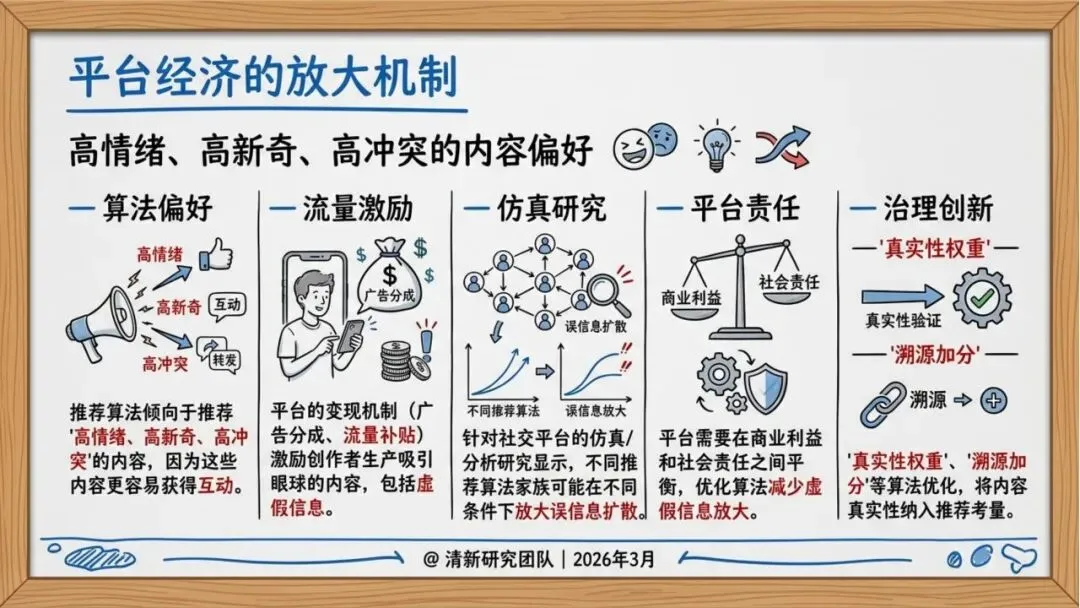
推荐算法偏好:平台算法倾向于推荐“高情绪、高新奇、高冲突”的内容,因为这些内容更容易获得互动。
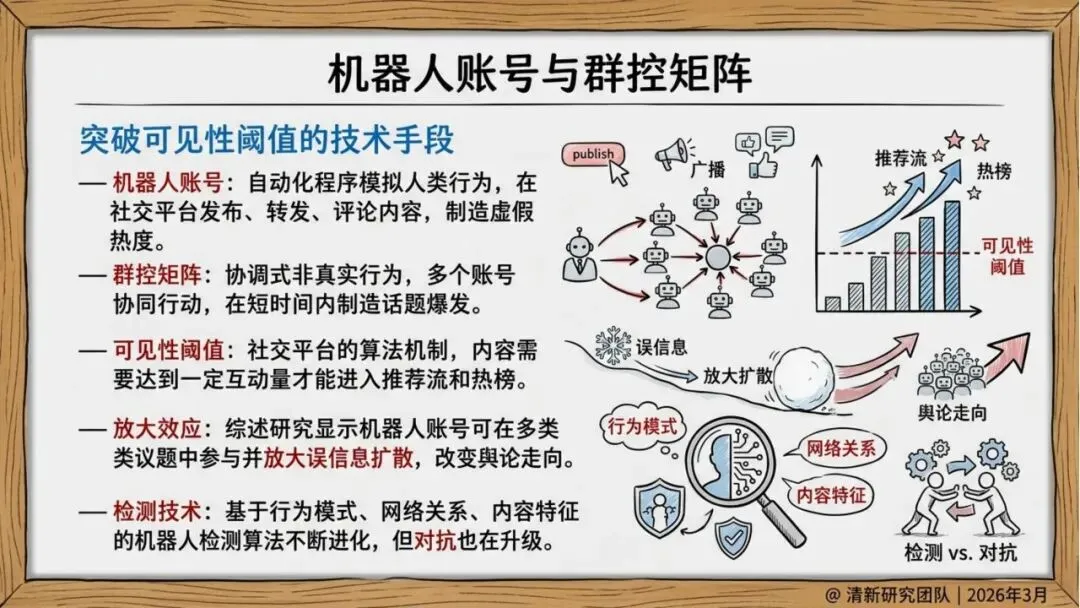
自动化协同:机器人账号和群控矩阵在早期推动内容传播,形成初始动量。
跨平台迁移:搬运号、截图再传播、二次剪辑等行为使内容在不同平台间快速扩散,从局部传播演变为全网舆情事件。
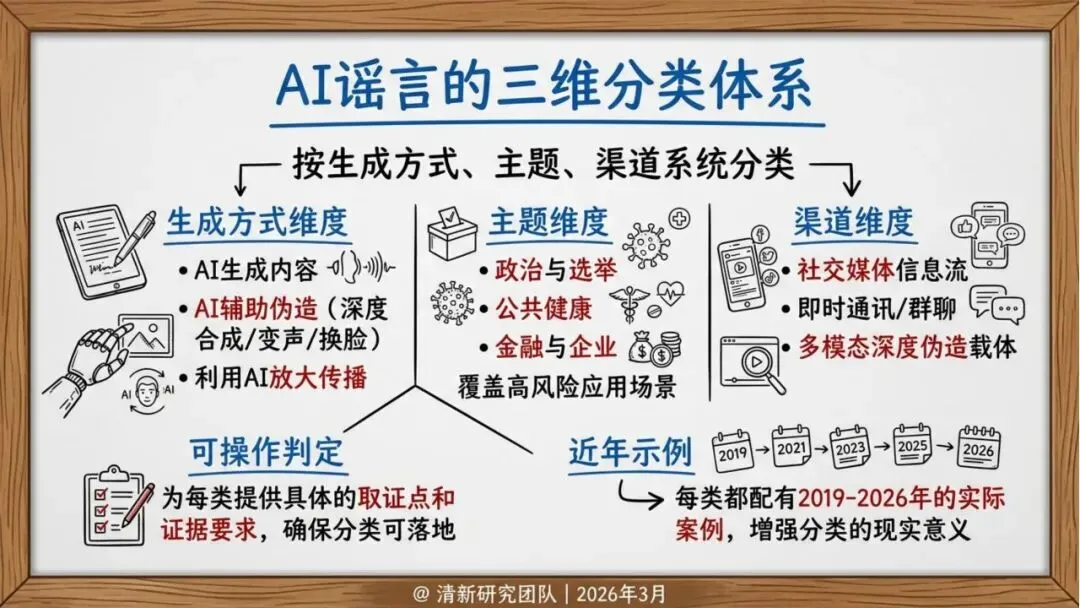
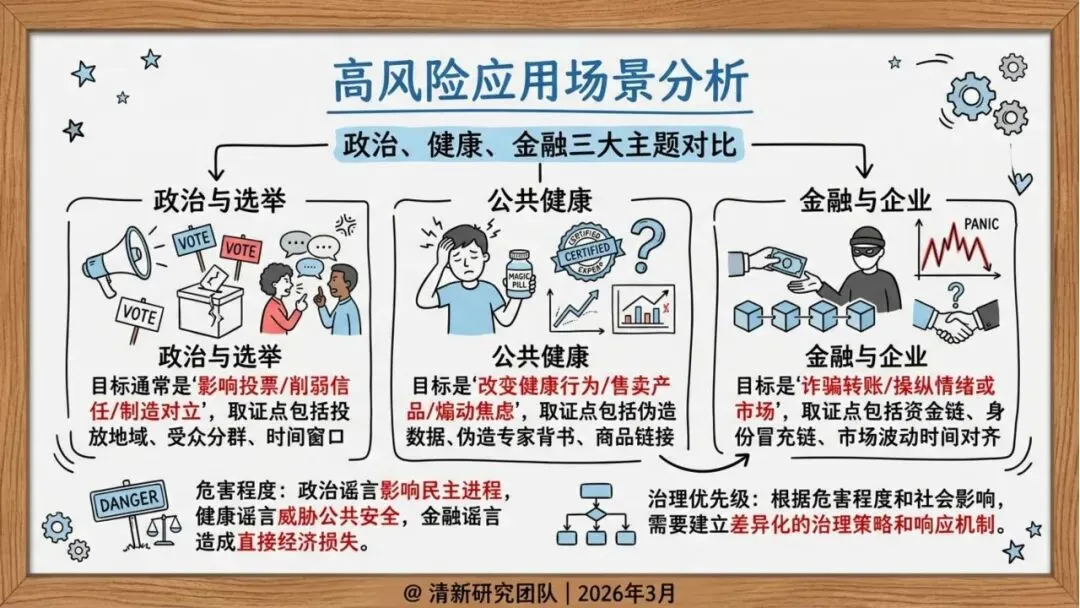
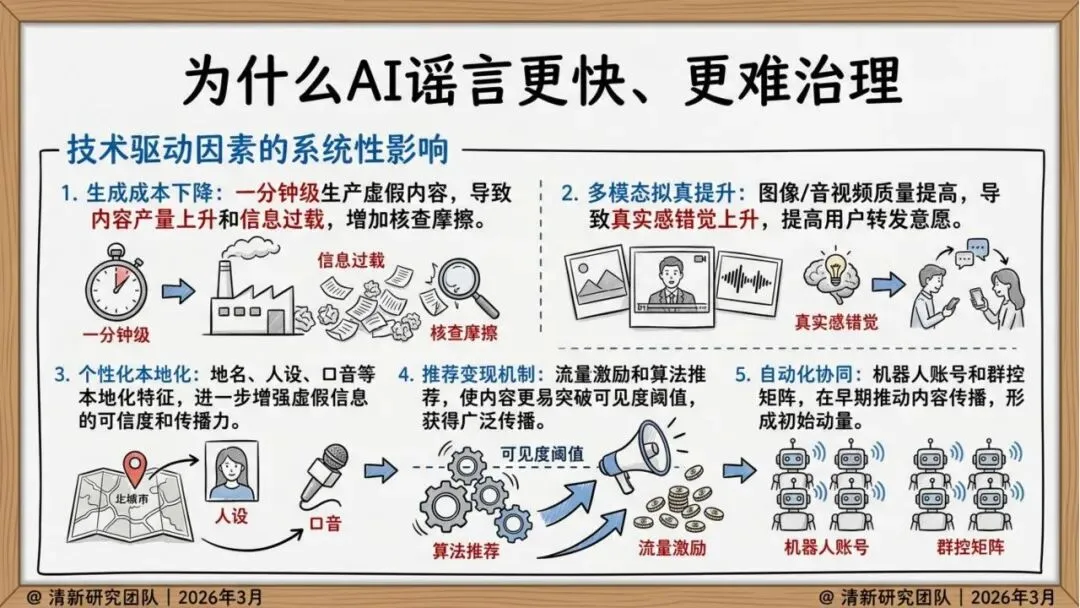
治理挑战:为什么AI谣言更快、更难治理?
报告指出了五大技术驱动因素:
生成成本下降:分钟级生产虚假内容,导致内容产量上升和信息过载
个性化本地化:地名、人设、口音等本地化特征增强可信度
推荐变现机制:流量激励使内容更易突破可见度阈值
自动化协同:机器人账号群控推动早期传播
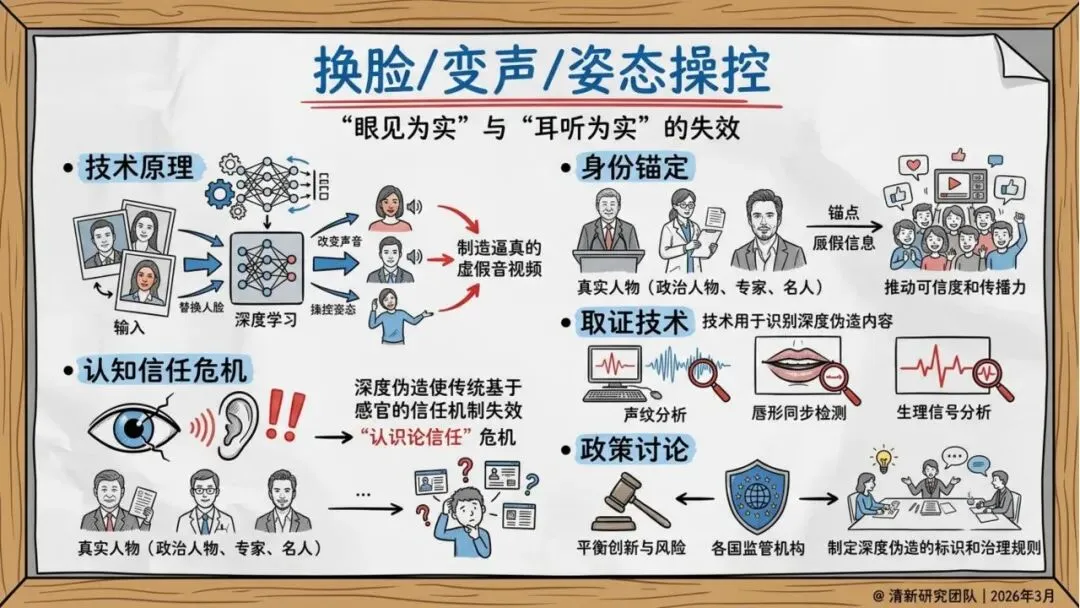
多模态拟真:眼见为实、耳听为实的传统认知失效
四维治理框架:技术、政策、平台、公众协同
研究团队提出了可落地的四维治理框架:
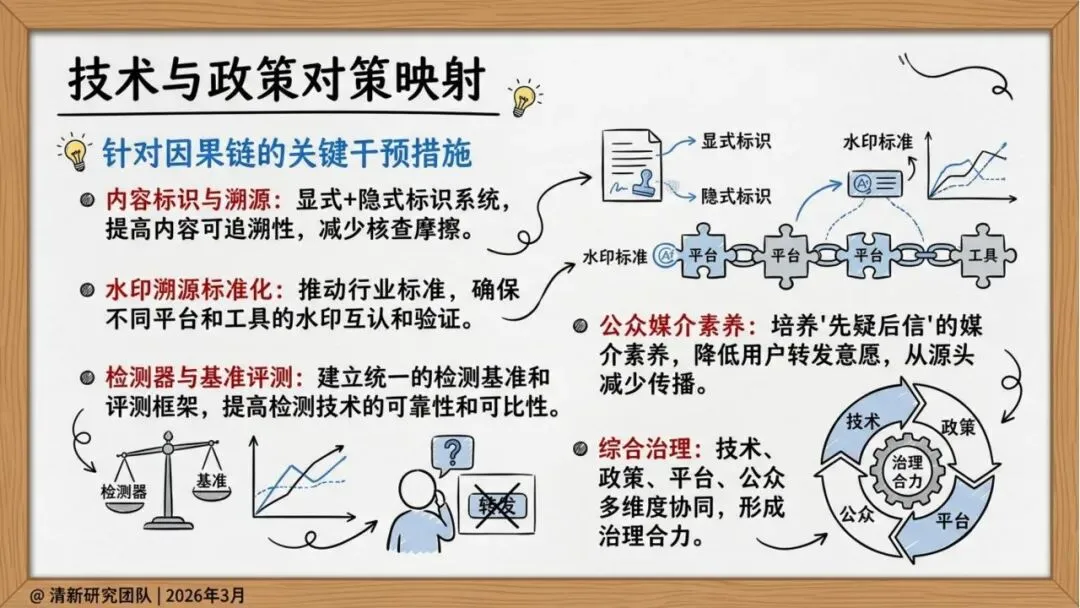
技术维度:内容标识与溯源、水印标准化、检测器与基准评测
政策维度:借鉴中欧美监管实践,制定分级处置标准
平台维度:优化推荐算法,将“真实性权重”“溯源加分”纳入考量
公众维度:培养“先疑后信”的媒介素养,降低转发意愿
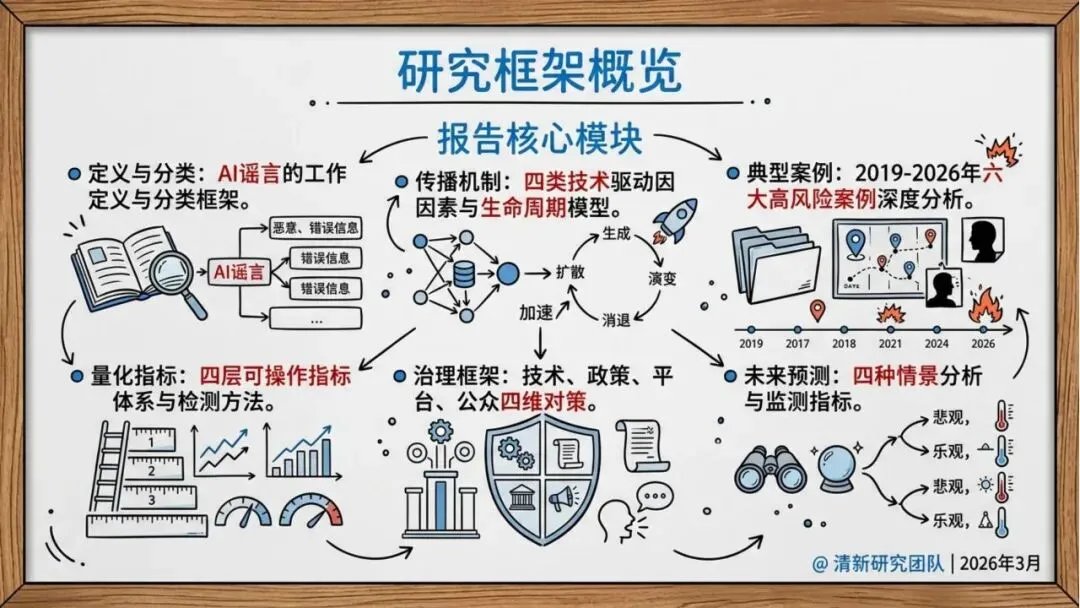
可量化的指标体系
报告设计了四层可操作指标框架:
内容层:可证明的溯源证据
主体层:账号行为特征分析
传播层:病毒系数(K-factor)、传播速度、用户覆盖度
受众层:用户接受与转发意愿
未来展望:四种可能情景
研究团队预测了四种未来演化情景:
情景一:溯源普及与互认形成主防线
情景二:检测—对抗“持久拉锯”,治理靠组合拳
情景三:高冲击事件触发监管与平台紧急升级
情景四:从“骗公众”转向“骗模型”的信息战
结语
在AI技术快速演进的今天,虚假信息治理已从“一对一验证”的传统模式,转向应对“工业规模虚假信息”的系统性挑战。报告强调,技术、政策、平台、公众多维度协同,形成治理合力,才是应对AI谣言的根本之道。
面对即将到来的更多技术融合风险(AI与生物技术、脑机接口、量子计算等),前瞻性研究与应急预案的建立刻不容缓。




阅读全文,免费下载报告
点击 ↓ 链接,下载文档
更多清华信息,点击 ↓ 链接
清华大学2025人工智能治理年度报告迈向可衡量的AI治理19页.pdf
清华大学2025年AIGC发展研究报告4.0版152 页.pdf
清华大学&华为:AI终端白皮书-AI与人协作、服务于人.pdf
更多相关清华内容信息,点击 ↓ 小程序,搜索:清华