


财报前夜的焦虑与机会
英伟达财报敲警钟,AI算力的泡沫要破?还是你的机会窗口正在打开? 兄弟们,最近是不是被英伟达财报的消息刷屏了?华尔街在猜泡沫会不会破,咱们AI圈的人却在想:"管它破不破,算力需求是确定的,先把算力拿到手再说!"毕竟,没有算力,再牛的模型也是纸上谈兵。美东时间周三盘后,英伟达要公布财报,市场盯着它看AI热潮是否退烧——但对咱们中国玩家来说,更重要的是:哪些算力还能拿到?

算力缺口下的"甜蜜点"
当华尔街还在纠结财报数字,AI行业早就为算力抢破头了。美国禁售B300/B200,H200成了眼下能摸到的最高端算力之一。2026年训练算力缺口突破2万E FLOPS,H200的141GB HBM3e显存刚好卡在"能用且够用"的甜蜜点——万亿参数模型训练?没问题!国产芯片在追赶,但成熟度和生态还差那么点意思。算力卡脖子,国产在奔跑,H200是你眼下能抓的最实在稻草!而今天,我们拿到了仅14台超微H200服务器现货——这可能是你今年离高端算力最近的一次!

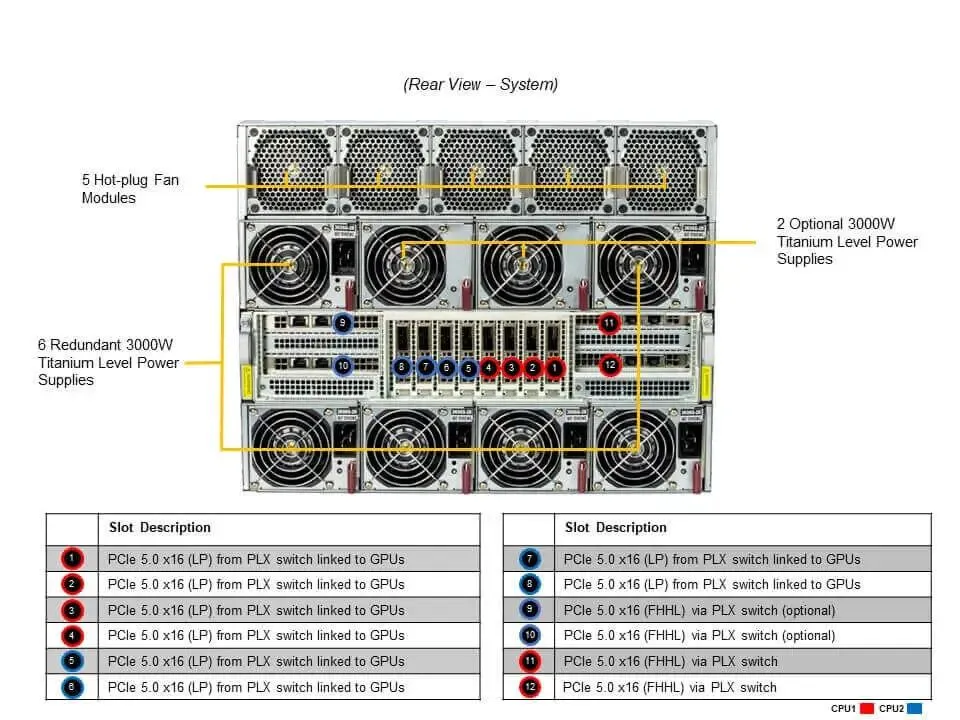
超微H200硬参数拆解
这14台超微H200到底有多能打?咱先看硬参数,再拆核心亮点!
超微H200服务器配置表

核心亮点拆解
1. H200 GPU:大显存才是硬道理!兄弟们,8*141GB HBM3e显存可不是盖的!以前用H100跑Llama-2-70B,上下文到32K就开始掉帧,现在H200直接拉到64K都流畅——KV缓存瓶颈?不存在的!4.8TB/s的带宽让数据传输像坐火箭,训练万亿参数MoE模型时,再也不用频繁换显存,效率直接拉满!
2. 内存堆到顶:32条DDR5不是闹着玩!32条64GB DDR5-5600内存,总容量2048GB!这是什么概念?相当于给服务器装了一个超级大脑,处理多任务时丝毫不卡,无论是训练还是推理,都能轻松应对大规模数据吞吐,这波涨价潮内存翻了几倍,占整机越来越高。
3. 网络接口拉满:8个200GbE让集群飞起来!8个NVIDIA ConnectX-7 200GbE接口,意味着你的服务器集群互联速度快到飞起。训练大模型时,跨节点通信延迟降低50%,集群效率直接提升30%——这就是高速网络的威力!

为什么值得抢?
咱说句实在的:技术上,H200的算力、能效、通信都能打,尤其是适合大规模MoE模型训练和长上下文推理;经济上,TCO比B系列低不少,性价比超高;生态上,NVIDIA的软件栈成熟,可靠性没话说。141GB大显存+4.8TB/s带宽,训练速度提40%,推理延迟降30%! ,春节前后H200进关寥寥无几,这14台实属难得。光说H200好不够,咱们和其他型号掰掰手腕!
对比:H200 vs 竞品
看到没?H200虽然比B200弱一点,但B200禁售与停产啊!和H100比,H200显存多61GB,带宽高1.45TB/s,推理吞吐量提升40%——这就是眼下最香的选择!
应用场景:落地才是王道
1. 万亿参数MoE模型训练用这台超微H200组建集群,训练万亿参数MoE模型时,显存足够支撑模型分片,不用频繁换数据,训练周期缩短20%——这就是大显存的爽感!
2. 长上下文推理客服机器人处理长对话?没问题!64K上下文长度让机器人能记住整个对话历史,回答更准确,用户体验直接升级!
3. 多模态训练图像+文本+语音的多模态模型训练,需要大量显存存储数据,H200的141GB显存刚好能hold住,训练效率提升30%!
抢现货,别犹豫!
14台现货,手慢无,算力机会不等人!兄弟们,英伟达财报的泡沫焦虑是华尔街的事,咱们的事是抢到算力!这14台超微H200服务器,是你今年最该抢的硬货——错过这次,下次不知道要等多久!
关注**【鑫思沃】公众号,后台私信免费获取【英伟达高端GPU-最全&最新参数速查表】!点击【发消息】→【参数速查】即可!还能获取百余份GPT&DeepSeek资料:点击【发消息】→【GPT&DS】!欲咨询价格或购买,加微信:lieversong & AI-xsw2024!


兄弟们,评论区聊聊:你觉得H200能解决你的算力焦虑吗?
免责申明:文章信息来源于产品方官网/网点/客户经理或者第三方公开信息平台,最终数据以产品方发布为准,本文中价格及数据和图片仅作参考,最终以实际发生为准。本公众号只做信息整合免费分享,如涉及侵权等问题,请与我们公众号联系删除,非常感谢!