






字节跳动发布Seedance 2.0
-电子行业跟踪报告-
本报告发布于2026年2月24日



投资要点:
事件:2026年2月12日,字节跳动正式发布了新一代音视频创作模型Seedance 2.0,该模型采用统一的多模态音视频联合生成架构,支持文字、图片、音频、视频四大模态输入,集成了当前业界领先的多模态内容参考与逻辑理解能力。
Seedance系列模型是字节跳动在多模态音视频生成领域的核心战略布局,技术迭代脉络清晰。2024年9月,字节跳动旗下火山引擎在深圳AI创新巡展上,正式发布PixelDance、Seaweed两款AI视频生成大模型。2025年5月,字节跳动完成PixelDance与Seaweed两大模型的深度技术融合,推出视频模型Seedance 1.0 lite。2025年6月公司正式发布Seedance 1.0系列模型。同年12月,迭代至Seedance 1.5 Pro版本,采用原生音视频联合生成架构,显著提升复杂场景与专业镜头的创作能力。2026年2月,Seedance 2.0全量发布,进一步强化了公司在多模态内容生成领域的技术壁垒与商业化落地能力。
Seedance 2.0采用统一的多模态音视频联合生成架构,支持文本、图像、音频、视频多模态输入,具备业内领先的内容理解、参考与编辑能力。1)Seedance 2.0凭借出色的运动稳定性和物理还原能力,多主体交互及复杂运动场景下的视频生成可用率达到业界 SOTA(State of the Art)水平。2)Seedance 2.0指令遵循与一致性表现全面提升,支持混合模态输入,用户可同时输入最多9张图片、3段视频和3段音频,有效拓展创作素材边界。3)Seedance 2.0支持稳定可控的视频延长与编辑功能,显著降低创作门槛。4)该模型可输出15秒高质量多镜头音视频内容,并配备双声道音频能力,实现高度拟真的视听效果。相较于Sora 2 Pro、Veo 3.1、Kling系列等主流产品,Seedance 2.0在运动逻辑、指令遵循、画面质感、视听一致性及长脚本理解上均具备明显优势,模型对参考内容的还原精度、编辑任务响应完整性,以及主体形象、特效风格、剧情叙事的一致性表现突出。
当前全球AI音视频大模型行业已进入技术快速迭代、商业化加速落地的爆发期,海内外头部厂商密集发布旗舰产品,形成百花齐放的多元竞争格局。海外市场以OpenAI Sora系列、Google DeepMind Veo 3.1为两大核心标杆。其中Sora系列凭借DiT架构实现行业技术破局,迭代版本补齐原生音画同步、物理模拟精度核心短板,完成产品力全面跃升。Veo 3.1则以免费普惠、极速生成的核心优势,在易用性与商业化适配性上实现突破。国内市场本土模型加速崛起,2026年2月全新上线的快手可灵Kling 3.0以原生音画一体化为核心迭代方向,实现音频生成能力全维度升级,与字节跳动Seedance 2.0形成国内市场双强领跑的格局,共同构建起本土模型差异化竞争的行业生态。
投资建议:字节跳动发布了新一代旗舰AI音视频大模型Seedance 2.0,实现原生音画一体化多模态生成领域的关键技术突破,行业已进入技术迭代与商业化落地加速期。我们预计多模态大模型的持续升级将会带动数据处理规模的加速提升,这将进一步加强对上游AI基建的需求。建议关注AI音视频生成应用放量带动下的上游AI基建核心赛道投资机会,包括光模块,存储,PCB等重点领域。
风险提示:1)技术迭代不及预期风险;2)行业竞争加剧风险;3)政策监管合规风险。
1. 字节跳动发布新一代音视频创作模式Seedance 2.0
事件:2026年2月12日,字节跳动正式发布了新一代音视频创作模型Seedance 2.0,该模型采用统一的多模态音视频联合生成架构,支持文字、图片、音频、视频四大模态输入,集成了当前业界领先的多模态内容参考与逻辑理解能力。

1.1 Seedance发展史梳理
2024年9月24日,字节跳动旗下火山引擎在深圳AI创新巡展上,正式发布PixelDance、Seaweed两款AI视频生成大模型,同步面向企业市场开启邀测,为后续Seedance大模型的落地完成了核心技术奠基。
2025年4月,字节跳动完成组织架构调整,将AI Lab团队整体并入Seed团队,实现了视频生成技术研发力量的全面整合。次月,字节跳动完成PixelDance与Seaweed两大模型的深度技术融合,推出视频模型Seedance 1.0 lite。
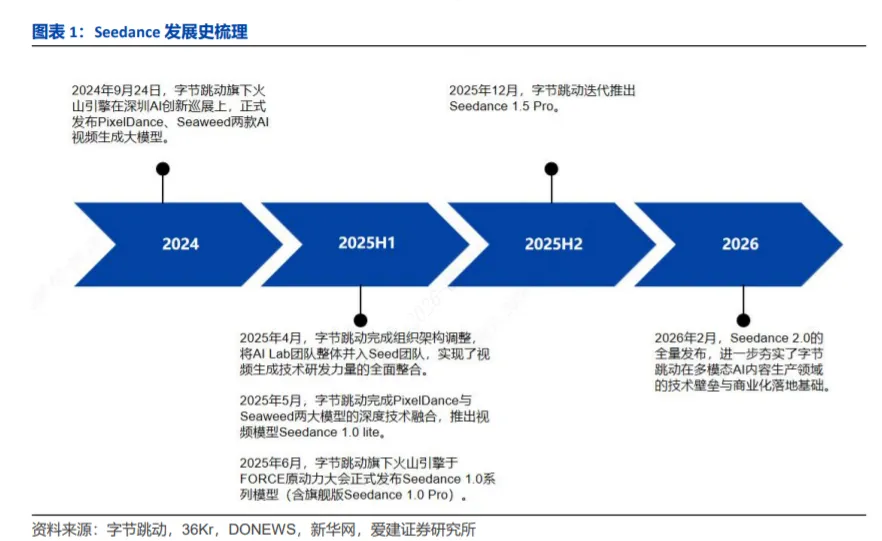
2025年6月,字节跳动旗下火山引擎于FORCE原动力大会正式发布Seedance 1.0系列模型(含旗舰版Seedance 1.0 Pro),为用户提供高效、高质量的视频创作解决方案。2025年12月,字节跳动迭代推出Seedance 1.5 Pro,该版本采用原生音视频联合生成架构,可精准响应复杂专业镜头指令,不仅能生成高自然度的视频画面,还可同步生成匹配叙事的原生音频,实现音画一体的视频成品快速创作。
2026年2月,Seedance 2.0的全量发布,进一步夯实了字节跳动在多模态AI内容生产领域的技术壁垒与商业化落地基础。


1.2 Seedance 2.0支持文字、图片、音频、视频模式输入
Seedance 2.0采用统一的多模态音视频联合生成架构,支持文字、图片、音频、视频四种模态输入,集成了目前业界最全面的多模态内容参考和编辑能力。
Seedance 2.0核心亮点在于:1)Seedance 2.0凭借出色的运动稳定性和物理还原能力,在多主体交互及复杂运动场景下的视频生成可用率达到业界SOTA(State of the Art)水平。2)Seedance 2.0指令遵循与一致性表现全面提升,支持混合模态输入,用户可同时输入最多9张图片、3段视频和3段音频,有效拓展创作素材边界。3)Seedance 2.0支持稳定可控的视频延长与编辑功能,显著降低创作门槛。4)Seedance 2.0可输出15秒高质量多镜头音视频,具备双声道音频能力,能够实现高度拟真的视听效果。依托全面的参考与编辑能力,产品可大幅降低影视、广告、电商、游戏等场景的内容制作成本。
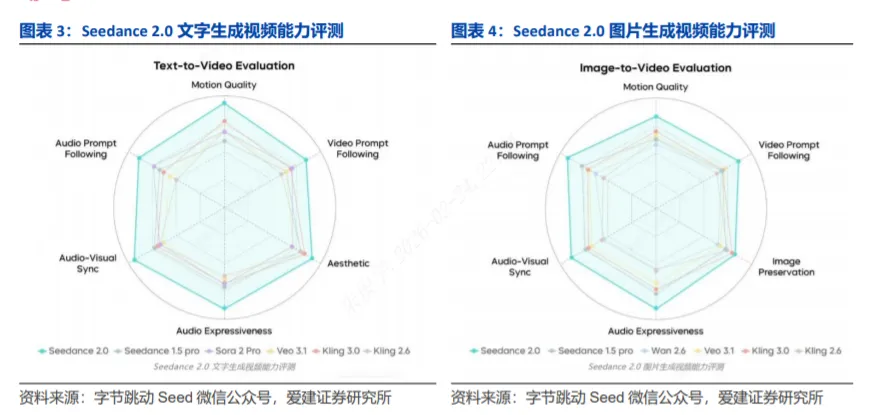
相较于Sora 2 Pro、Veo 3.1、Kling系列等主流音视频大模型,Seedance 2.0在相关测试中表现领先。
1)视频维度,Seedance 2.0在运动稳定性、指令遵循度与画面美感上显著提升。Seedance 2.0有效改善结构失真与画面崩坏问题,复杂动作流畅细腻,可精准呈现高张力动作与微表情,支持专业运镜与叙事节奏控制,对长脚本及开放指令响应较好。
2)音频维度,Seedance 2.0双声道效果层次丰富,可匹配场景音效与旋律,视听一体化体验更强。
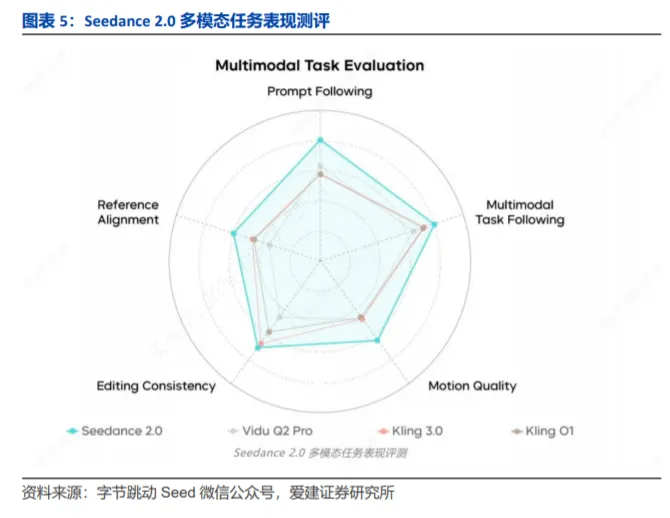
3)Seedance 2.0覆盖的参考任务类型更全面,支持多模态参考生成、视频编辑、视频延续等多种创作场景。同时,模型对参考内容的理解深度和响应精度具备优势,在编辑任务中指令响应更完整,生成画面真实度更高。在一致性表现上,模型在主体形象与声音还原方面表现较好,尤其在动作逻辑、特效风格及剧情叙事的参考一致性上优势显著。


1.3 全球音视频大模型百花齐放
当前全球AI音视频大模型行业已进入技术快速迭代、商业化加速落地的发展阶段。海外以OpenAI Sora系列(含初代Sora及迭代旗舰版Sora 2)、Google Veo 3.1为核心标杆,国内市场则以快手可灵Kling 3.0、字节跳动Seedance 2.0等为代表的本土模型快速崛起,形成差异化竞争格局。
1.3.1 OpenAI Sora及Sora 2
2024年2月16日,OpenAI发布首个文本生成视频模型Sora。Sora采用Diffusion Transformer深度融合架构(将扩散模型与Transformer深度结合的创新架构,简称DiT架构),旨在提升从文本到视频的生成效果。其依托自注意力机制、动态学习策略及面向视频生成任务优化的架构设计,可增强生成视频的帧间连贯性,同时提升视觉内容与文本语义的匹配精准度。
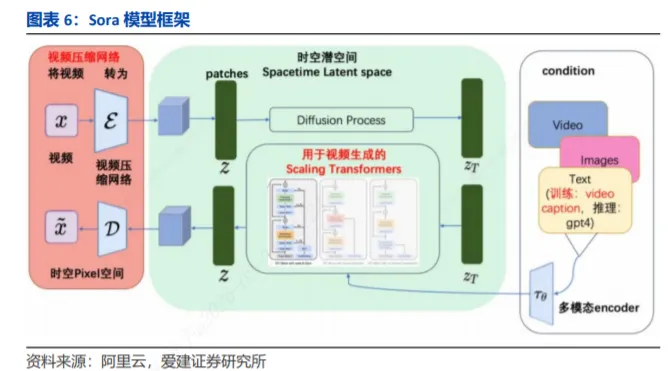
相较于Gen-2、Lumiere、MoonValley等视频生成模型,Sora具备在视频时长、多模态生成覆盖度、技术架构的时序一致性等方面展现出显著优势。具体而言,1)Sora视频生成时间长,远超Gen-2(18秒)、Lumiere(5秒)、MoonValley(6秒)的时长上限,能承载更具叙事性或完整性的创作需求;2)生成类型上,它不仅覆盖T2V(文生视频)、I2V(图生视频)、V2V(视频生视频),还额外支持VFI(视频插帧),多模态创作的丰富度更全面。3)技术架构层面,Sora依托Diffusion Transformer 架构,时序一致性表现更佳,可减少画面闪烁、物体运动不连贯等问题,使动态视觉效果更贴近真实场景。
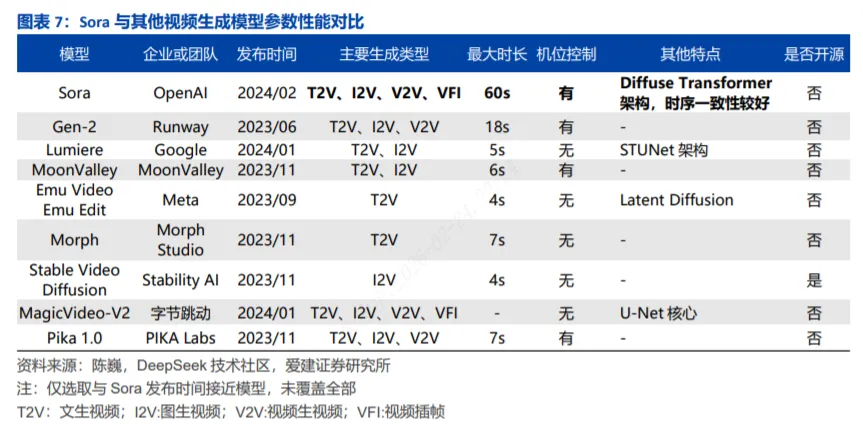
但作为初代文本生成视频模型,Sora仅能生成完全无声的视频,用户需在后期手动为其添加音频。这一额外操作不仅会打断连贯的创作流程,还大幅增加了内容制作的时间成本与人力成本。为解决这一核心痛点,OpenAI于2025年9月30日推出新一代模型Sora 2。
相较于初代Sora,Sora 2首先解决无声局限,实现原生音视频同步。创作者只需输入关键词,即可生成包含音效的完整影片,无需后期额外配音。从具体场景来看,初代Sora在人物说话、奔跑、海浪拍岸等场景中均无音效,而Sora 2能针对不同场景自动生成贴合场景的声音。
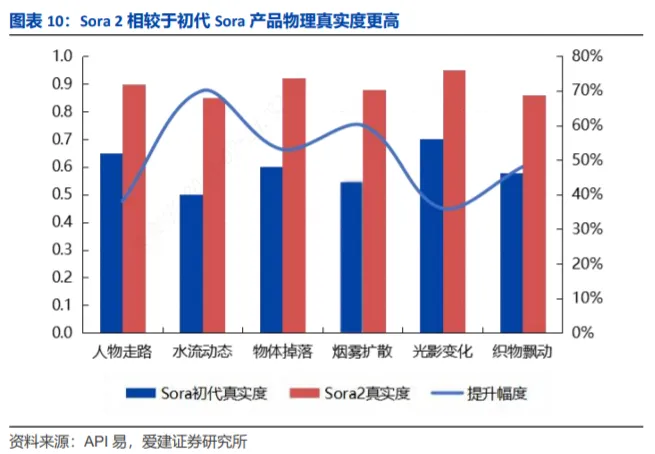
Sora 2在物理模拟精度上实现了对初代Sora的突破性升级。针对初代“水流方向不自然”的问题,Sora 2升级了水、烟雾等流体的模拟精度,使其运动轨迹与形态更贴近现实物理规律;针对初代存在的重力效果错误(如物体飘浮)与碰撞反馈不真实问题,它能通过精准模拟重力、惯性、摩擦力进行修正;针对人物动作僵硬、不流畅的缺陷,它还能让人物动作严格符合人体工学。

从对比测试结果来看,Sora 2在人物走路、水流动态、物体掉落等场景的真实度,相较于初代均有明显提升,提升区间为36%-70%,其中水流动态场景提升最显著,达70%。
此外,Sora 2还引入了“Cameo”功能。借助该功能,用户只需完成一次短暂的视频与音频采集,就能将自己或朋友的形象与声音注入模型;后续在任意场景中,这一角色都能以高度保真的方式呈现。这一设计有效拓展了角色互动的可能性,丰富了用户的使用体验。
1.3.2 Google Veo 3.1
2025年10月,Google发布由DeepMind研发的Veo 3.1视频生成模型,在生成质量、时序一致性与多模态可控性上实现关键升级。
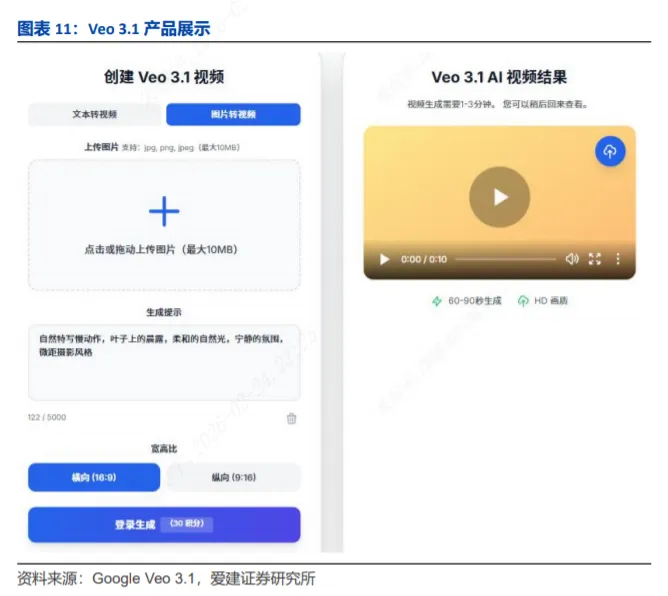
该模型支持文本、图像提示生成高清视频,具备原生音频生成能力,可同步生成对话、音效与环境音,标志着AI视频“无声时代”的结束。同时它通过参考图像指导、运动控制等功能,实现对相机运动、角色一致性、场景扩展与对象操作的精确创意控制,并凭借逼真的物理效果、纹理及更高提示遵循度提升真实感。此外,模型内置SynthID水印、内容过滤与安全评估机制,以防范有害内容与滥用。
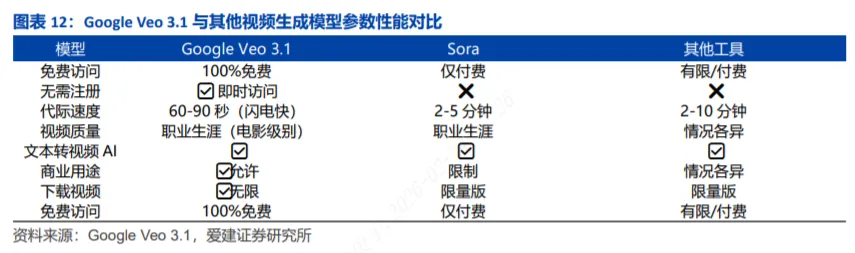
相较于Sora及其他同类工具,Google Veo 3.1提供100%免费访问与免注册即时使用,代际速度仅需60-90秒,远快于Sora的2-5分钟及其他工具的2-10分钟,在易用性与生成效率上形成了明显优势。
1.3.3 快手可灵Kling 3.0
2026年2月5日,快手科技正式全球上线Kling 3.0及系列AI视频生成模型,产品以“All in One, One for All”为核心理念。Kling 3.0搭载全新智能分镜系统,支持最高1080p分辨率、单次最长15秒视频生成,该版本以原生音画一体化为核心迭代方向,实现了音频生成能力的全维度产业级升级。其显著增强的原生音频(Native Audio)端到端生成能力彻底打破了AI视频行业长期存在的“默片模式”瓶颈,将AI视频创作从传统单视觉生成模式升级为全沉浸式的视听一体化内容产出范式。

模型具备全场景多语种语音生成能力,可在单一画面中同时协调最多三个不同角色的独立对话,精准适配多角色交互场景,解决了行业多角色场景下语音混淆、口型错位的核心痛点。同时Kling 3.0可实现环境音效与视觉画面的帧级精准对齐,生成与人物动作、场景变化高度匹配的全品类环境音效,实现音频效果与画面节奏、情感基调的深度统一。

2. 市场行情回顾

2.1SW一级行业涨跌幅一览
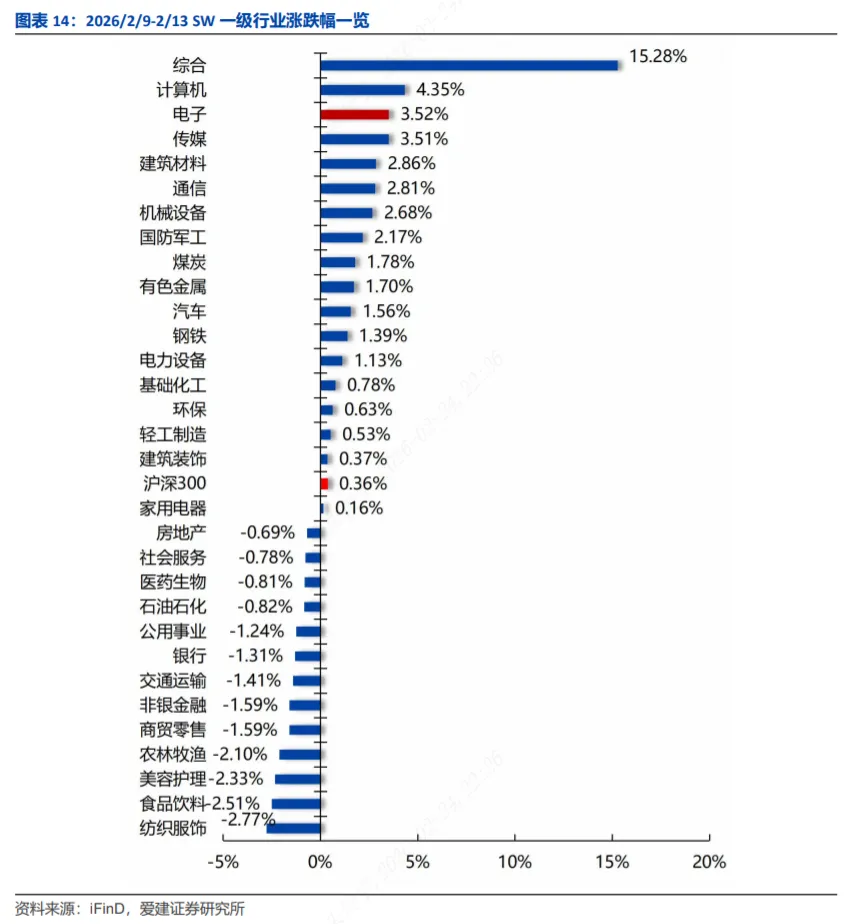
2026年2月9日-2月13日,SW电子行业指数(+3.52%),涨跌幅排名3/31位,沪深300指数(+0.36%)。SW一级行业指数涨跌幅前五分别为:综合(+15.28%),计算机(+4.35%),电子(+3.52%),传媒(+3.51%),建筑材料(+2.86%),涨跌幅后五分别为:纺织服饰(-2.77%),食品饮料(-2.51%),美容护理(-2.33%),农林牧渔(-2.10%),商贸零售(-1.59%)。


2.2 SW电子三级行业市场表现
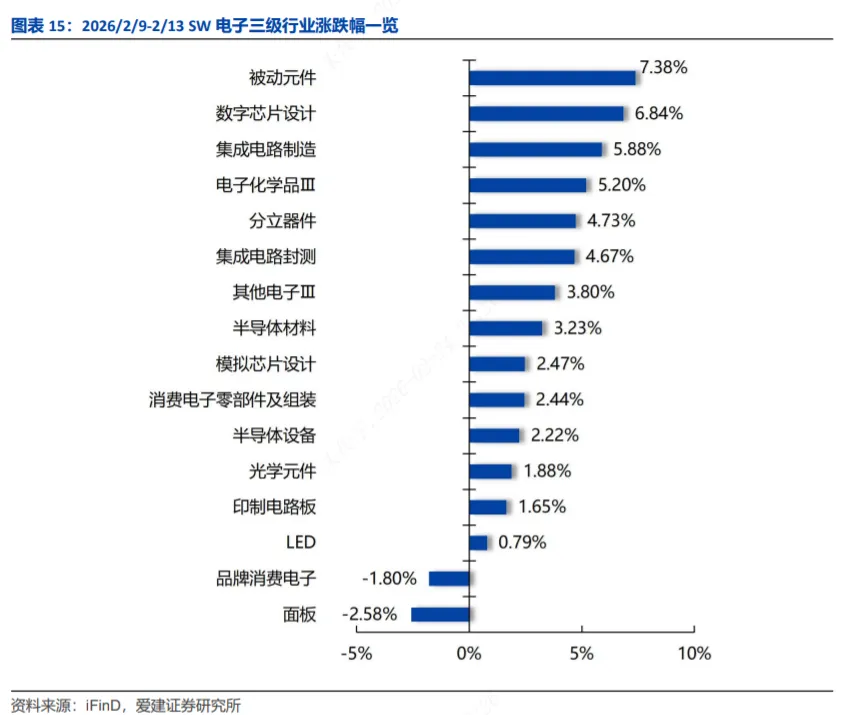
2026年2月9日-2月13日SW电子三级行业指数涨跌幅前三分别是:被动元件(+7.38%),数字芯片设计(+6.84%),集成电路制造(+5.88%),涨跌幅后三分别是:面板(-2.58%),品牌消费电子(-1.80%),LED(+0.79%)。


2.3 SW电子行业个股情况
2026年2月9日-2月13日SW电子行业涨跌幅排名前五的股票分别是:芯原股份(+43.71%),南亚新材(+32.67%),盛科通信(+31.73%),德邦科技(+29.88%),易天股份(+28.77%)。
涨跌幅排名后五的股票分别是:可川科技(-15.93%),翰博高新(-14.11%),奥尼电子(-10.84%),联建光电(-10.43%),信维通信(-7.87%)。
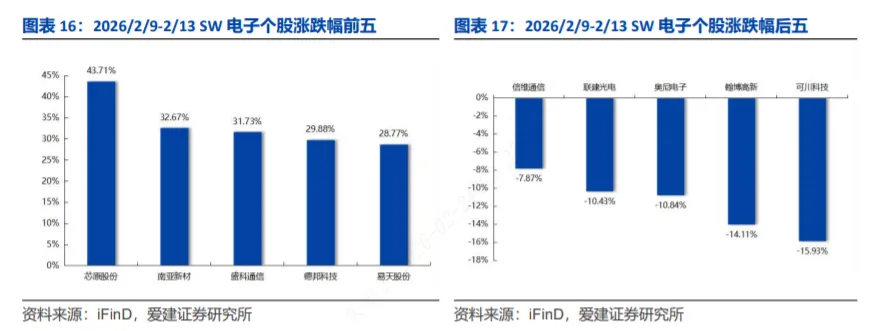


3.4 科技行业其他市场表现
2026年2月9日至2月13日,费城半导体指数(SOX)涨跌幅为+1.11%,同期恒生科技指数涨跌幅为+0.27%。
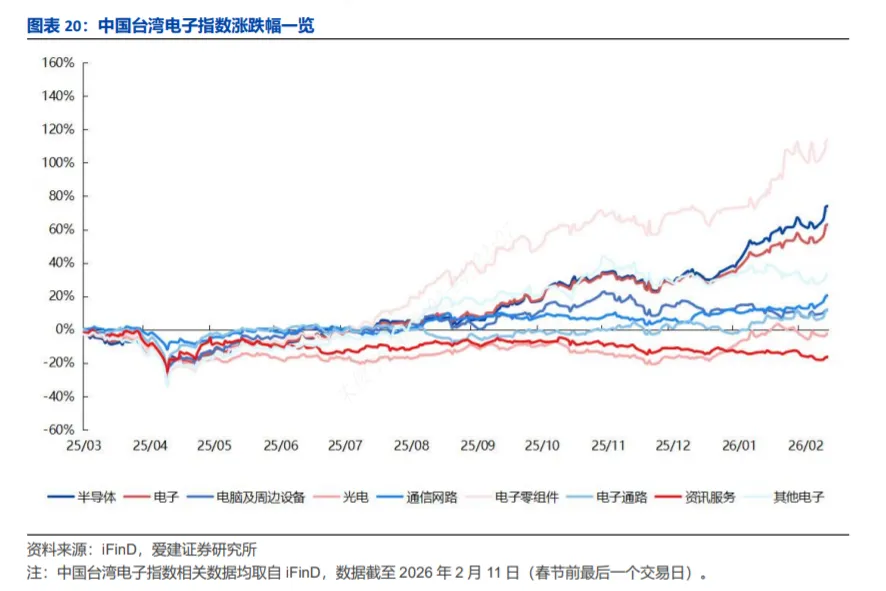
截至2026年2月11日(中国台湾股市春节前最后一个交易日),中国台湾电子指数各细分板块上周涨跌幅分别为:半导体(+6.47%)、电子(+4.98%)、电脑及周边设备(+0.94%)、光电(-1.28%)、通信网路(+4.60%)、电子零组件(+0.82%)、电子通路(+2.44%)、资讯服务(-0.51%)、其他电子(+1.85%)。

3.风险提示
1)技术迭代不及预期风险:AI音视频大模型作为前沿生成式AI技术,迭代过程中面临核心算法突破难度大、技术路线被颠覆的风险,未来技术发展存在不确定性。
2)行业竞争加剧风险:全球AI音视频大模型赛道已吸引海内外头部科技企业密集布局,市场参与者持续增加,行业竞争日趋激烈。
3)政策监管合规风险:AI音视频生成属于生成式AI重点监管领域,海内外相关监管政策仍在持续完善。


文章来源
本文节选自:2026年2月24日发布的《电子行业跟踪报告:字节跳动发布Seedance 2.0》
分析师:许亮
执业证书编号:S0820525010002
邮箱:xuliang@ajzq.com
联系人:朱俊宇
执业证书编号:S0820125040021
邮箱:zhujunyu@ajzq.com
如需全文,请联系爱建电子团队或对口销售。
免责声明
爱建证券有限责任公司(下称“爱建证券”)已获中国证监会许可的证券投资咨询业务资格,本订阅号不是爱建证券研究报告发布平台,所载内容均节选自于爱建证券已正式发布的研究报告,所推送观点和信息仅供爱建证券研究服务客户参考,完整的投资观点应以爱建证券研究所发布的完整报告为准。若您非爱建证券研究服务客户,请勿订阅、接受、转载或使用本平台中的任何信息。爱建证券不会因订阅本平台的行为或者收到、阅读本公众号推送内容而视为客户。任何未经爱建证券同意或授权而对本平台内容进行复制、转发或其他类似不当行为均被严格禁止。对于使用本平台包含信息所引起的后果,爱建证券概不承担任何责任。
本平台报告是基于已公开信息撰写,但本公司不保证该等信息的准确性或完整性。报告所载的资料、意见及预测仅反映本公司于发布本报告当日的判断,且预测方法及结果存在一定程度局限性。在不同时期,本公司可发出与本报告所刊载的意见、预测不一致的报告,但本公司没有义务和责任及时更新本报告所涉及的内容并通知客户。
在任何情况下,本公众号所载信息、意见不构成任何投资建议,所述证券或金融工具买卖的评级、目标价、估值、盈利预测等分析判断亦不构成对证券或金融工具在具体价位、时点、市场表现的投资建议。对任何直接或间接使用本公众号所载信息和内容或者据此进行投资所造成的任何一切后果或损失,爱建证券及其关联人员均不承担任何形式的法律责任。
法律声明
本平台为爱建证券有限责任公司研究所(下称“爱建研究”)依法设立、运营的唯一官方订阅号。根据《证券期货投资者适当性管理办法》,本微信平台所载内容仅供爱建证券客户中专业投资者参考使用。若您非爱建证券客户中的专业投资者,为控制投资风险,请勿订阅、接受、转载或使用本平台中的任何信息。爱建证券不会因接收人收到本内容而视其为客户,且由于仅为研究观点的简要表述,客户需以爱建证券研究所发布的完整报告为准。
市场有风险,投资需谨慎。在任何情况下,本微信平台所载信息或所表述的意见并不构成对任何人的投资建议。在任何情况下,本公司不对任何人因使用本微信平台中的任何内容所引致的任何损失负任何责任。
本微信号及其推送内容的版权归爱建证券所有,爱建证券对本微信号及其推送内容保留一切法律权利。未经爱建证券事先书面许可,任何机构或个人不得以任何形式转载、翻版、复制、刊登、发表、修改、仿制或引用本订阅号中的内容。版权所有,违者必究。

点击蓝字,关注我们