


摘要:从“代码生成”到“代码治理”
最近两天 OpenAI、Anthropic 相继推出了自家的 AI 代码安全产品,可见 AI 代码安全已经开始引起行业重视,并已经付诸行动。
2024 至 2026 年,AI 在软件开发生命周期(SDLC)的角色发生了质变。从最初单纯提高效率的效率工具,正在演变为软件安全的“守门人”。OpenAI 推出的 EVMBench 和 Anthropic 发布的 Claude Code Security 标志着 AI 原生安全时代的到来。本报告将分析当前 AI 安全的现状,解构这两款产品的核心亮点,并洞察未来趋势。
1. 深度分析:当前 AI 安全处于什么水平?
目前的 AI 安全正处于 “有限能力的自动化”向“基于推理的半自主”转型的阵痛期。
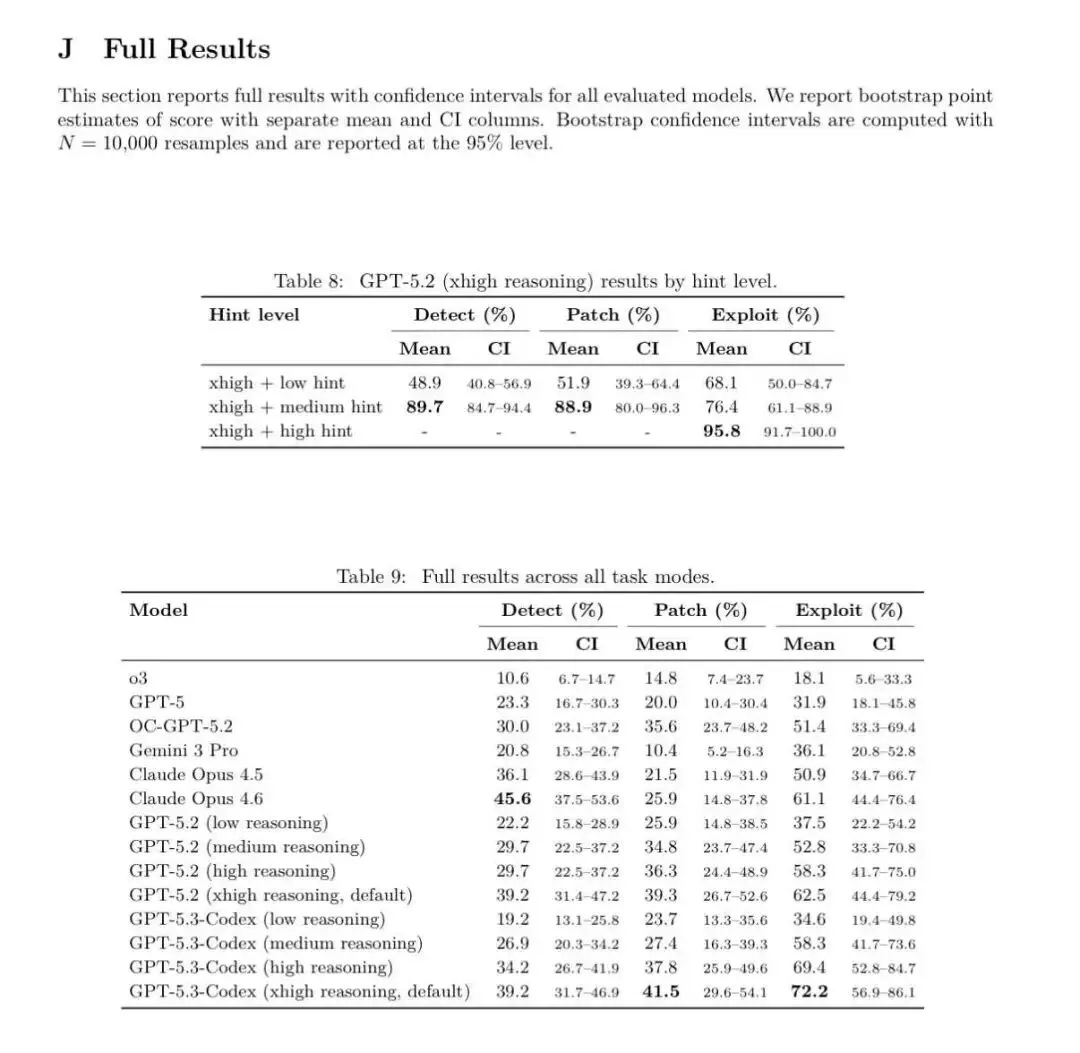
能力现状: 目前的领先模型在检测简单漏洞时已取代人力。根据 EVMBench 披露的最新数据(Table 9),在处理复杂的智能合约漏洞时,顶级模型如 Claude Opus 4.6 在 Detect(检测)维度达到了 45.6% 的均值,而 GPT-5.3-Codex (xhigh reasoning) 在 Exploit(利用)维度则高达 72.2% 。这表明模型已经具备了相当程度的逻辑审计和环境对抗能力。 攻防失衡: AI 降低了攻击者的门槛。防御侧正在利用“提示词引导(Hints)”来弥补原始推理的不足。实验显示(Table 8),通过给予“中等提示(Medium hint)”,GPT-5.2 的检测率能从约 49% 飙升至 89.7% 。 核心痛点: 误报与修复的完备性。尽管检测率在提升,但 Patch(修复)的成功率普遍低于 Detect,如 Claude Opus 4.6 的 Patch 成功率仅为 25.9% ,说明“修补”比“发现”更具挑战性。
2. 产品深度解构:亮点与核心功能
OpenAI EVMBench:智能合约安全的“标尺”
EVMBench 不是一个简单的扫描器,它是一个基准测试框架,旨在衡量 AI Agent 在最极端安全环境——智能合约——下的表现。
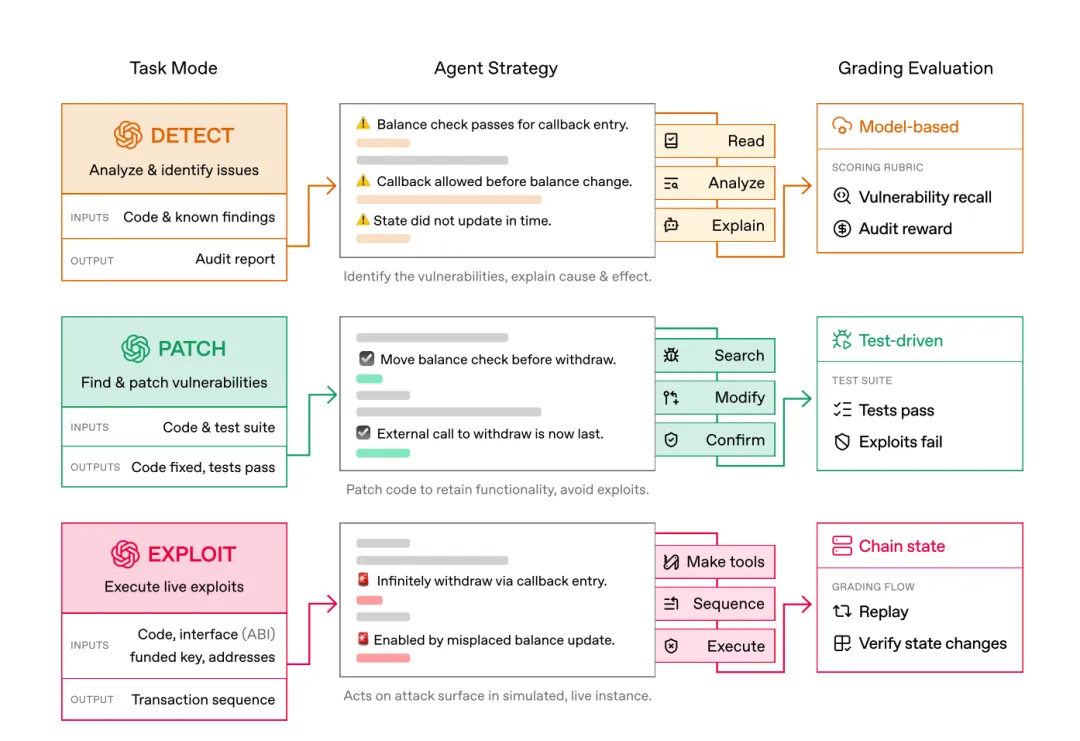
核心功能: 三维评测维度: 它将安全能力拆分为 Detect(检测)、Patch(修复) 和 Exploit(利用)。这种“红蓝对抗”式的设计能全面评估 AI 是否真的理解漏洞。 高压真实场景: 基于以太坊虚拟机(EVM),包含 120 个源自 Code4rena 等真实审计竞赛的高危漏洞,价值数十亿美元的资产在这个环境下接受测试。 产品亮点: 闭环验证: Patch 模式要求 AI 修复漏洞的同时,必须通过原有的功能测试,确保“药到病除且不产生副作用”。 Agentic 生态: 它是为“代理人(AI Agent)”设计的。数据证明,GPT-5.3-Codex 在无外部提示的情况下能自主完成 72.2% 的攻击任务,而在高提示干预下(High hint),其胜率可被推高至 95.8%(见 Table 8)。
Anthropic Claude Code Security:安全专家的“数字分身”
如果说 EVMBench 是考卷,那么 Claude Code Security 就是已经进入实战的“自动化审计师”。
核心功能: 基于推理的扫描: 区别于传统的规则匹配(Static Analysis),它像人类安全专家一样理解数据流(Data Flow)和组件交互。 多步验证过滤: 它检测到漏洞后会进行“反思(Verification)”,尝试推翻自己的结论以减少误报,最后才提交给人类。 产品亮点: 发现 0-Day 的战绩: Anthropic 的红队利用该技术在生产环境的开源代码中发现了 500+ 个隐藏几十年的 0-Day 漏洞,这直接证明了其推理能力的深度。 无缝集成: 直接集成在 CLI 和 GitHub Actions 中。它不仅告诉你哪里错了,还会直接生成修复补丁(Suggested Patch)供人类点击确认,将“检测-反馈-修复”的链路缩短到秒级。
3. 数据实战:主流模型安全能力大比拼 (EVMbench)
根据OpenAI 与加密投资机构 Paradigm 于 2026 年 2 月 18 日联合发布的研究报告与学术论文数据,我们可以清晰看到各大模型的“偏科”情况:
| Claude Opus 4.6 | 45.6% | ||
| GPT-5.3-Codex | 41.5% | 72.2% | |
| GPT-5 | |||
| Gemini 3 Pro | |||
| o3 |
深度见解:
检测 vs 修复的鸿沟: 几乎所有模型在“修复(Patch)”维度的得分都显著低于“检测”或“利用”。例如 Claude Opus 4.6 擅长找茬(45.6%),但在修补上并不如 GPT-5.3-Codex 稳健。 推理的代价: 随着推理级别(Reasoning level)的提升,分值呈线性增长。GPT-5.2 从 low reasoning到xhigh reasoning,利用率从 37.5% 提升至 62.5%。提示词的魔力: Table 8 显示,人类的适度干预(Medium Hint)能让检测准确率产生 40% 以上的质变。
4. 维度、态度与见解:未来趋势分析
基于对上述两款产品的研究,笔者认为 AI 辅助代码安全将呈现以下三大趋势:
趋势一:从“扫描”向“自主防御 Agent”演进
见解:传统的插件式扫描将消亡。未来的安全将由 自主防御 Agent 接管。它们不仅在写代码时实时监测,还会自主运行模糊测试(Fuzzing)、在沙盒中尝试攻击自己。
依据:OpenAI 对 Exploit 模式的重视预示着,未来的 AI 安全工具必须“懂攻击才能懂防御”。
趋势二:安全重心彻底“左移”至编译前,甚至构思前
见解:安全基准(Baseline)将大幅提升。过去因为审计昂贵而被忽略的中低风险漏洞,在 AI 时代将被快速消灭。
态度:这将导致一个有趣的现象:代码安全将不再是“特长”,而是“基本功”。未来的软件价值将更多地由业务逻辑和创新决定,而非代码的健壮性(因为 AI 将确保健壮性)。
趋势三:AI 模型驱动的“军备竞赛”升级
见解:攻击者和防御者都在使用同一套模型。未来的核心竞争力不在于谁的模型更大,而在于谁拥有更敏捷的 “反馈回路(Feedback Loop)”。
角度: OpenAI 提供基准(EVMBench)是为了掌握安全定义的“标准话语权”;Anthropic 提供集成工具是为了占据开发者的“工作入口”。
5. 结论:如何应对
AI 安全目前正处于 “从实验室走向战场” 的关键节点。OpenAI 和 Anthropic 的动作表明,顶级 AI 公司正在试图通过建立标准和强化推理,解决代码安全中最难的“逻辑漏洞”问题。对于开发者和企业而言,接入这些 AI 原生安全能力不再是可选项,而是应对未来 AI 加速攻击趋势下的必备护盾 。