


或许在备考时最折磨人的5分钟——遇到一道眼熟的真题,翻《白皮书》找了半天没找到。
“到底是这本书上没有这道题,还是刚才翻太快漏掉了?”
为了尽可能减少这种不确定性,我们试着做了一个程序。
“仅核实一道题到底是不是《白皮书》的原题或变体”
如果有,输出例题题号以及必要的解释;
如果没有,则可以安心停止翻书,去想别的办法。
1.原理简述:
程序主要运用“云端私人数据库”技术。
以及两个AI:矿工和审查员
对于每一道真题:
矿工负责拿着真题去白皮书里找原题,
并输出一份调查报告
审查员对矿工的报告给出评分;
>85,则输出结果
≤85,则打回并给出修改建议,让矿工重找。
一个循环结束
(此循环至多重复三轮)

注:
1.为简便,评分原则仅为矿工找出来的这道例题是否与真题高度相关(若矿工断言此题超纲,分数仍记为0)
2.矿工与审查员分成两个独立AI是有必要的,否则事实上会自我包庇。
2.成果演示
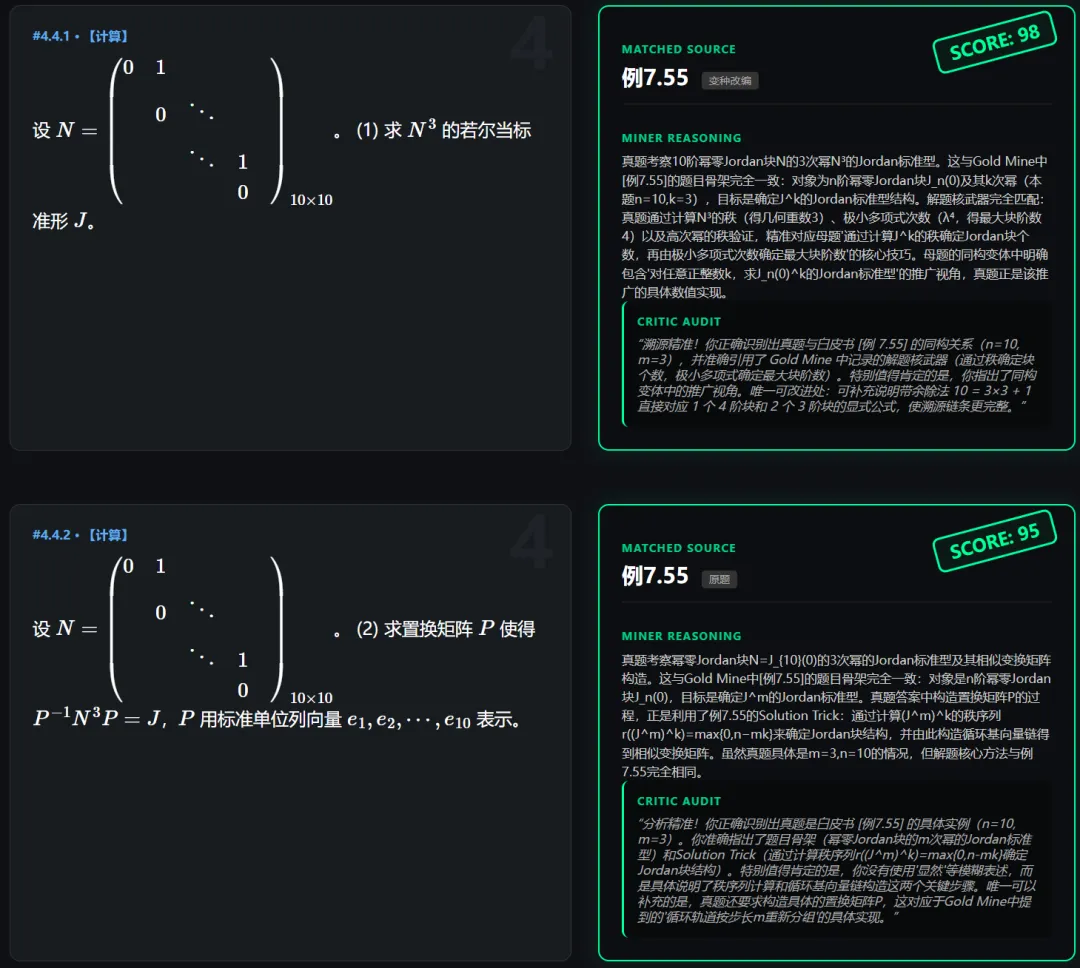
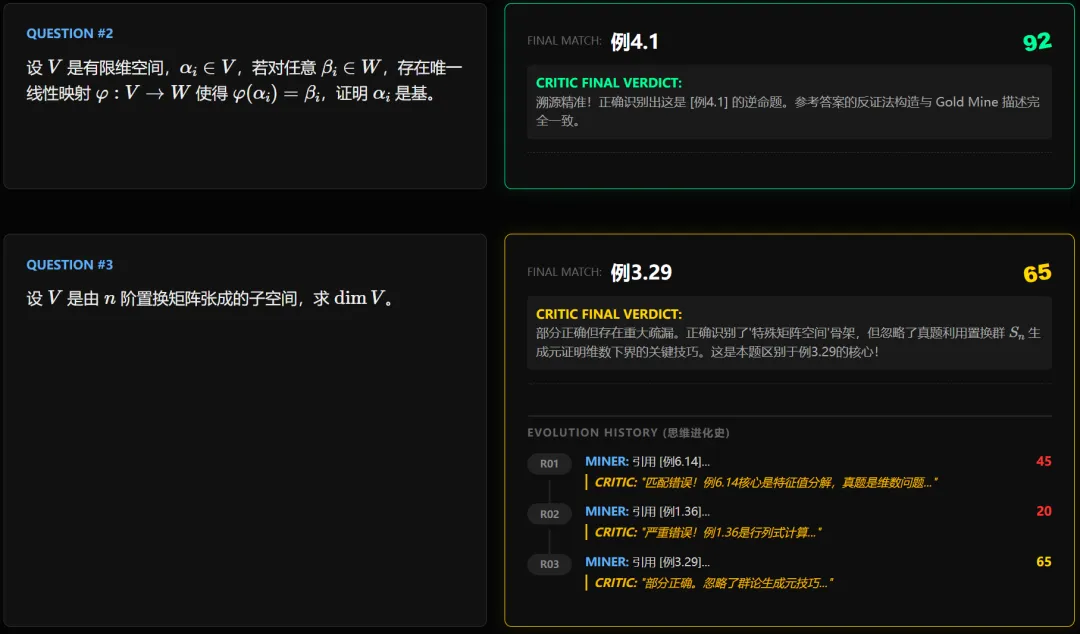
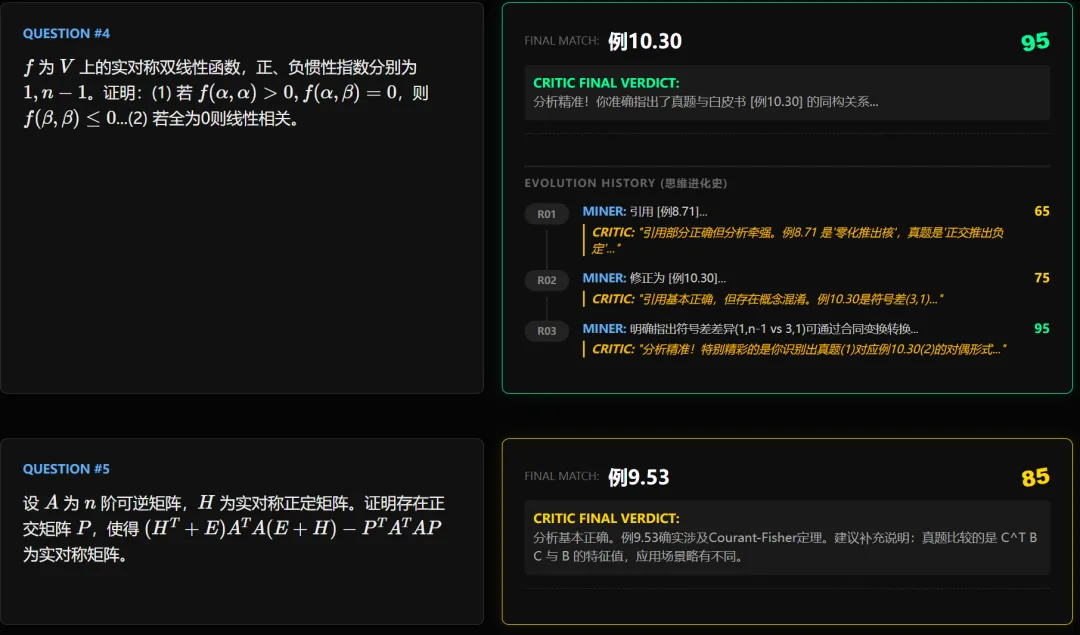
1.直接找到原题的:
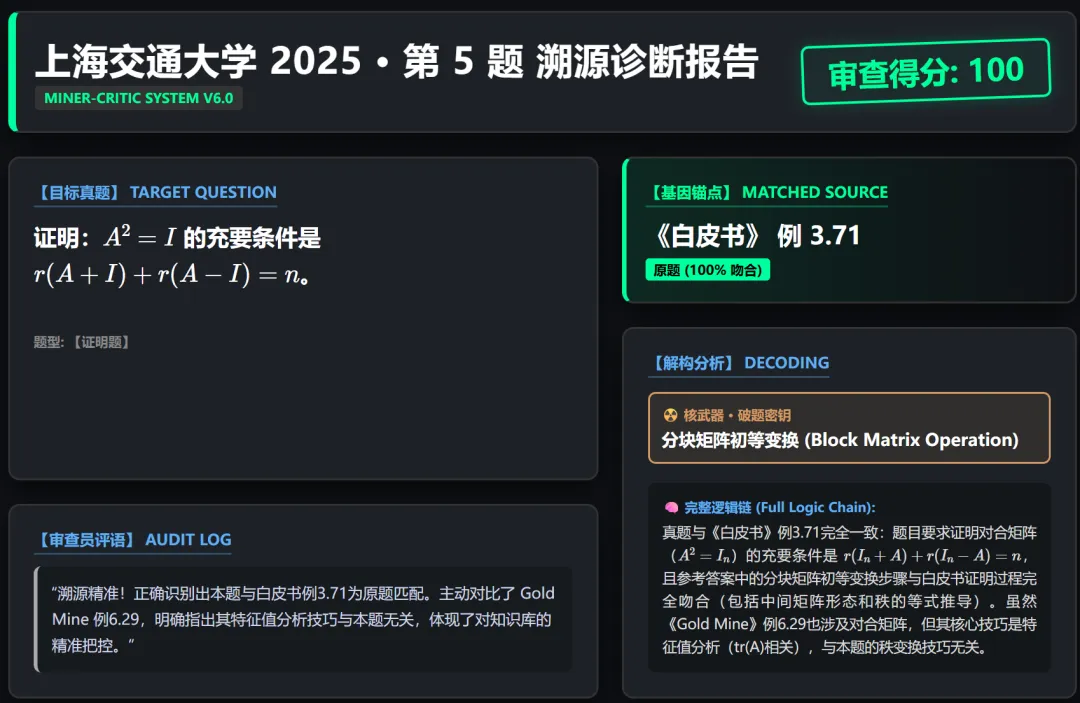

可以看到确实是原题。
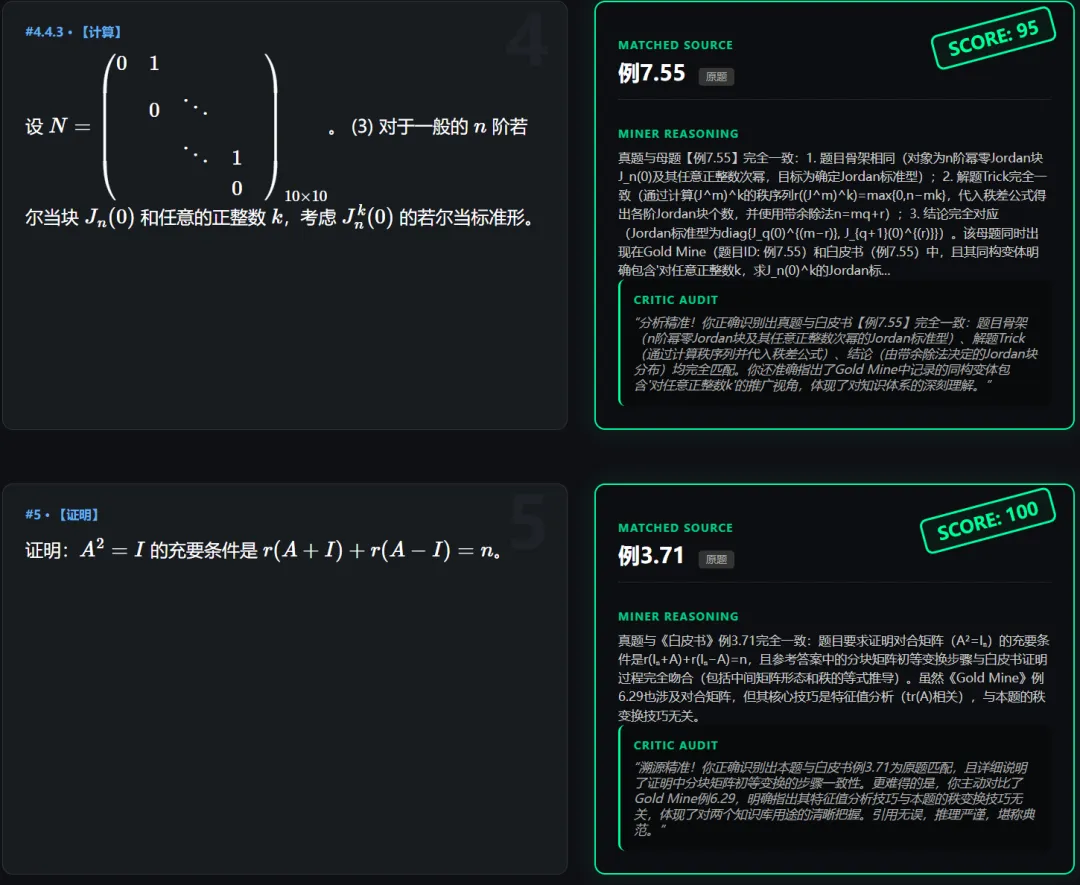
2.白皮书上(大概率)不存在原题的
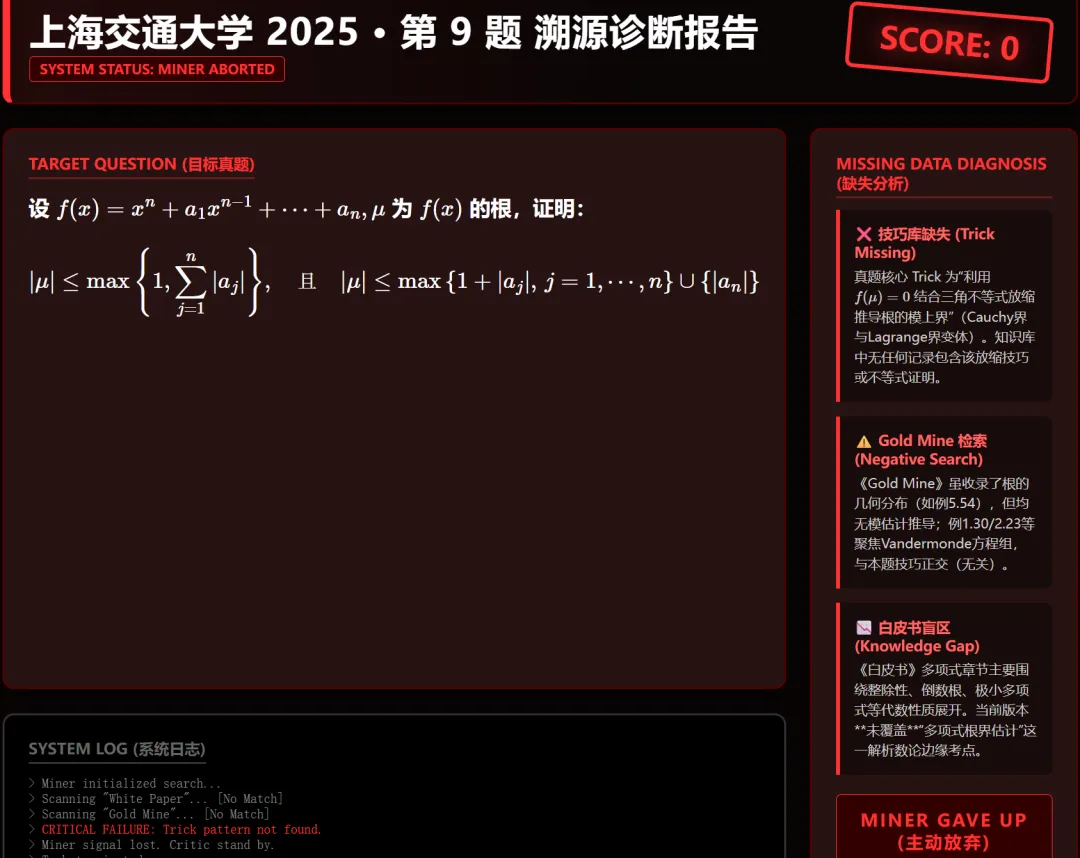
我们的程序会如实输出,并不会强行抽一道例题出来说这是原题。
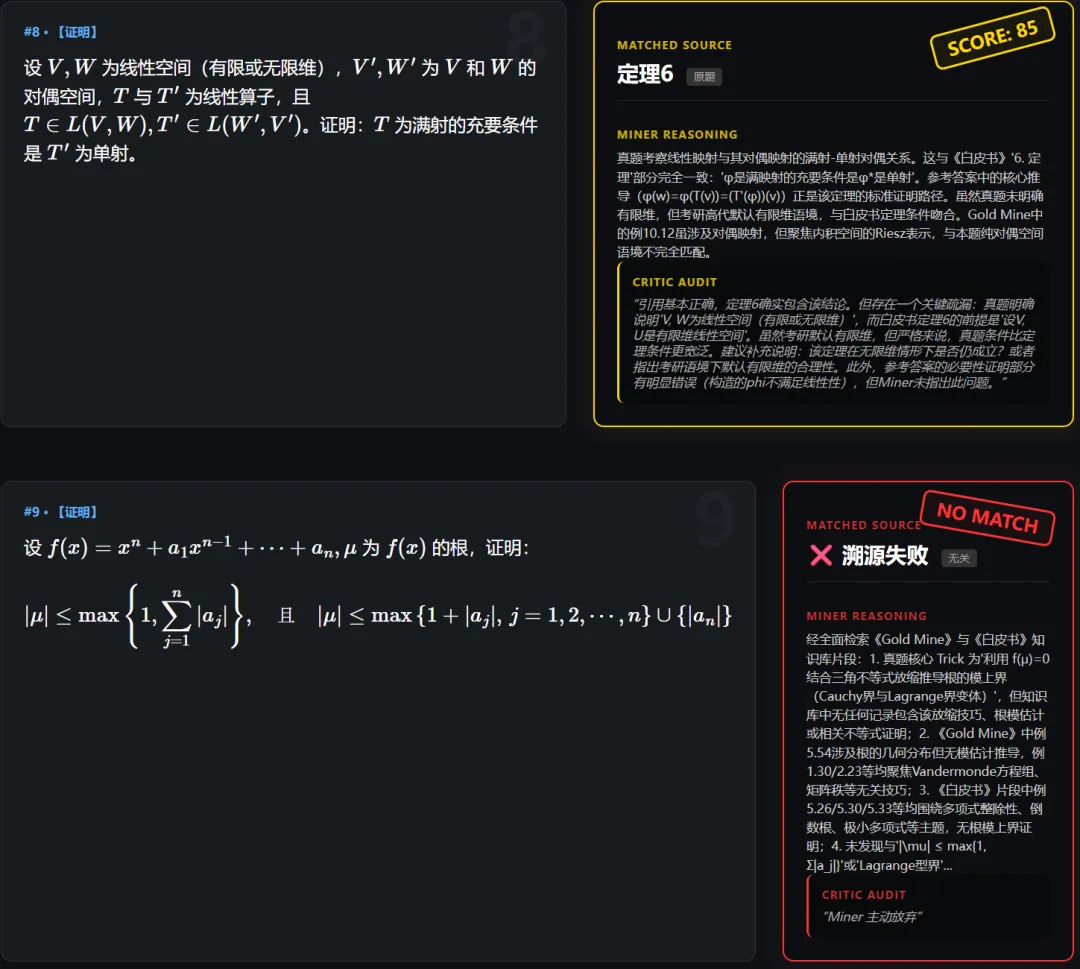
3.其他类

如图,审查员拦住了矿工的三次错误输出,保证了输出数据的纯净性(此题实际有群论背景,在白皮书里确实可能不好找到直接出处)。
实际上,至少测试中的大部分考研真题还是能在白皮书里找到出处的
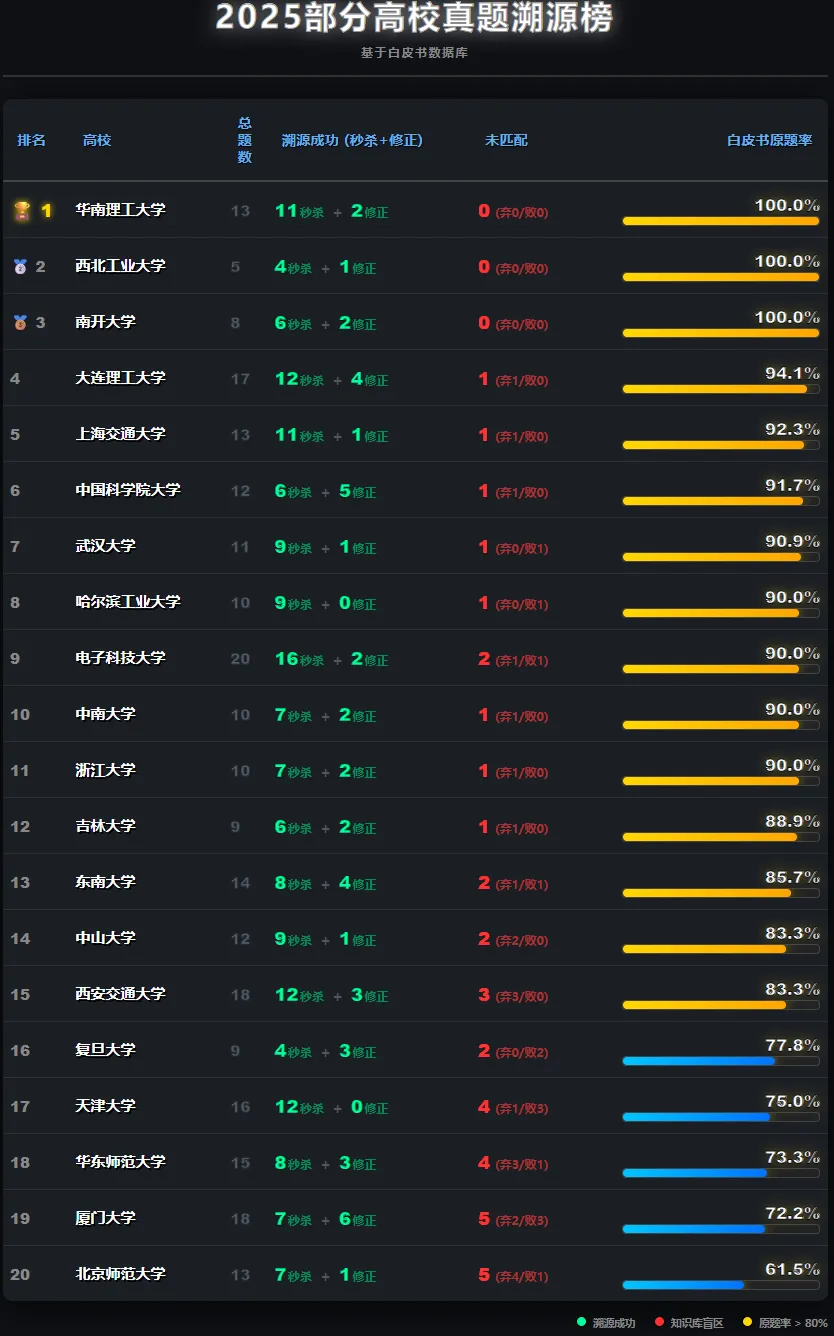
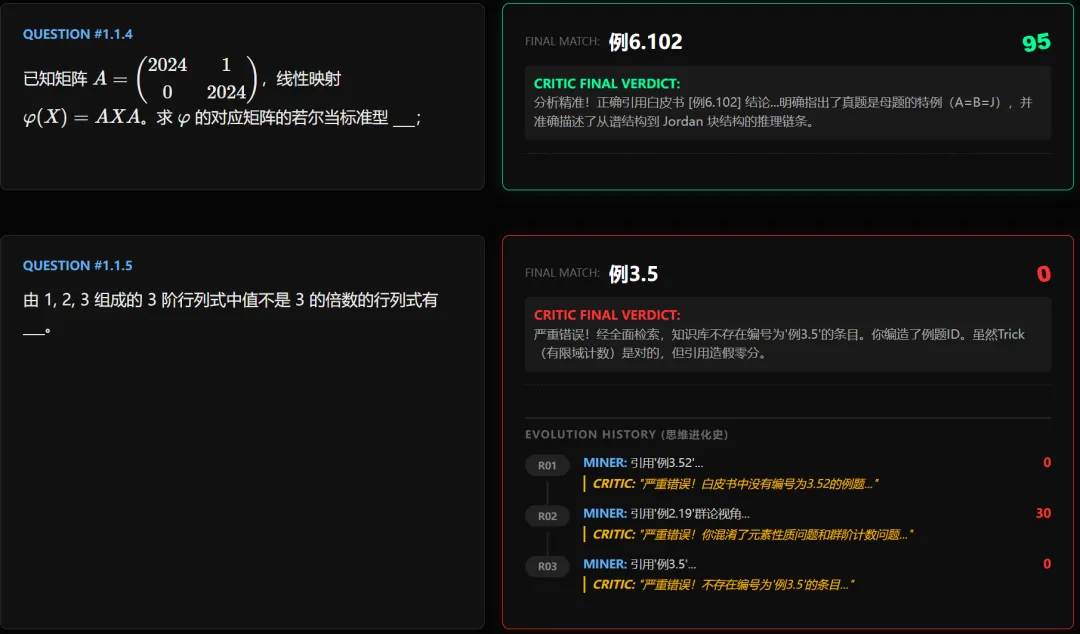
其中:
“秒杀”是指矿工第一次就找到原题了,
“修正”是指矿工在三次循环中找到原题,
“放弃”是指矿工自己断言白皮书里没有原题,
“失败”是指其余各种原因,最终导致未能找到原题。
如果一道大题里有两个小题,这两个小题独立搜索并统计。
3.使用的主要工具展示
1.云端私人知识库:
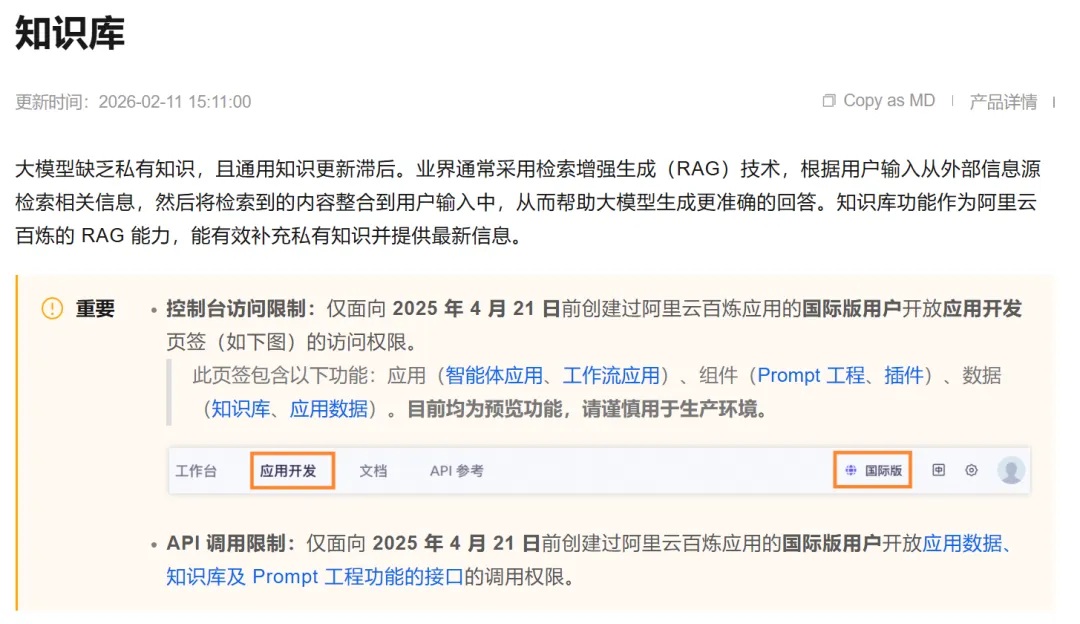

知识库完整介绍链接:
https://www.alibabacloud.com/help/zh/model-studio/rag-knowledge-base
这是一项成熟且仍在不断发展的技术,事实上,各种AI客服都是基于此技术。
2.Gemini3.0 pro与Python
(下面的观点可能存在主观性):
现在的Gemini已经可以稳定输出三四百行的代码且不报错(指python本身不报错,但是程序运行的结果仍有可能不理想)
对于完全不懂编程的人,Python其实反而比一些视觉拖拽式工作流编程更友好一些,(在AI的辅助下)。
这是因为:视觉拖拽式工作流编程往往存在一些没有明说的操作细节。
如下操作:“将一个大模型成功拖进循环中”
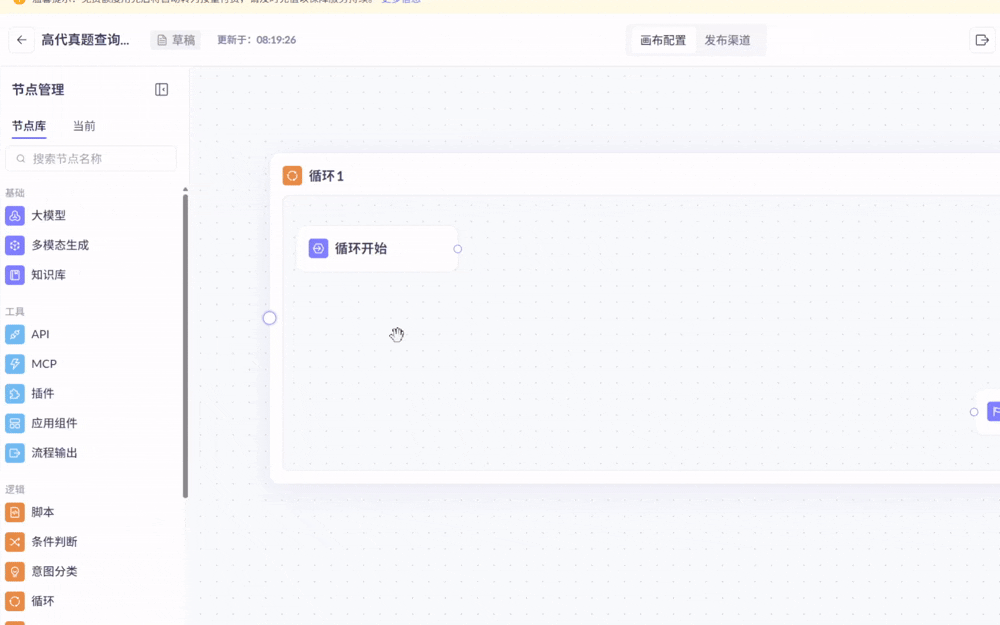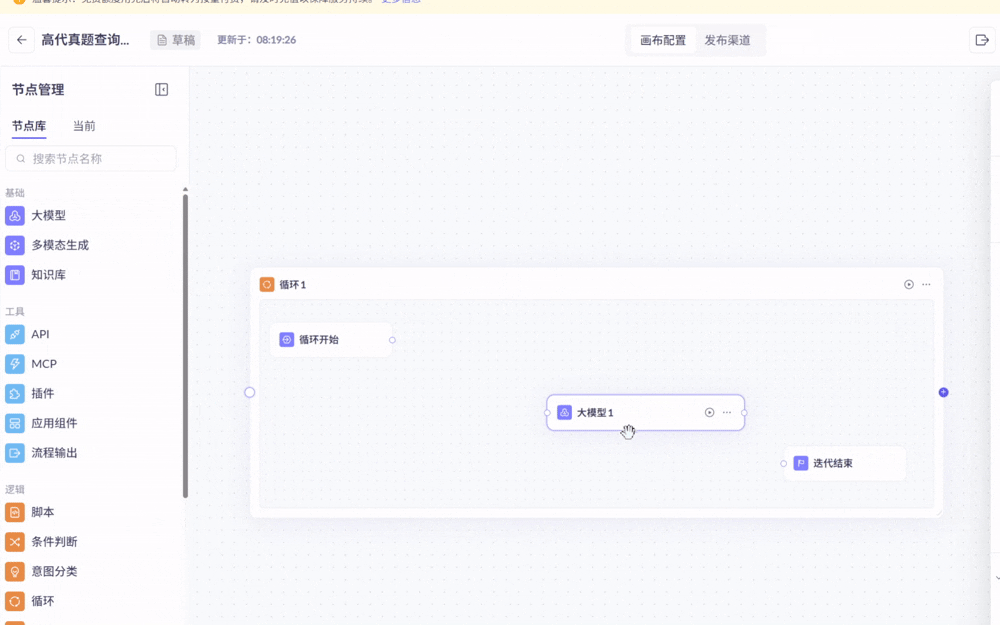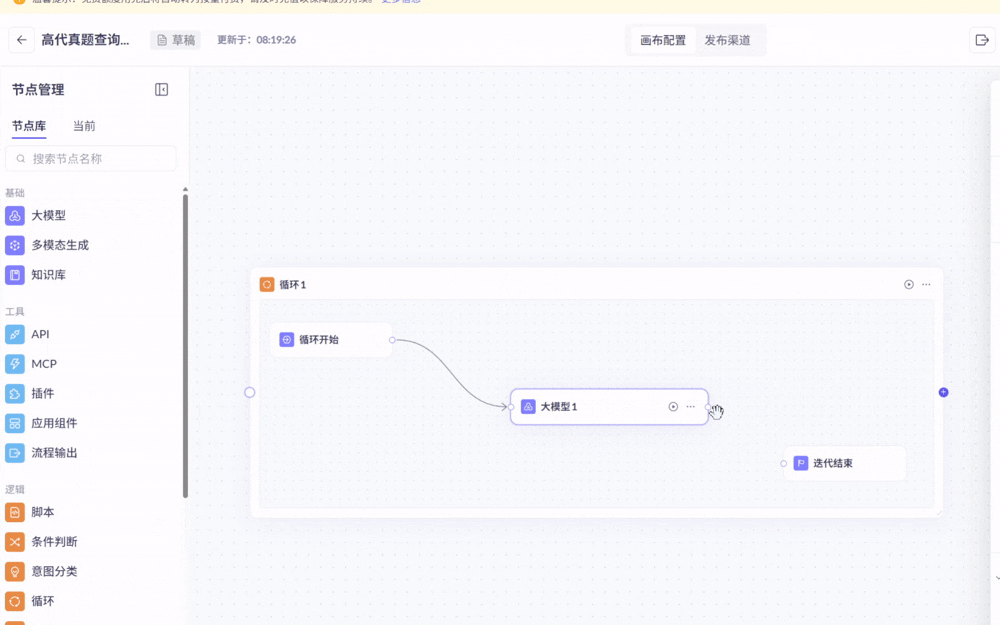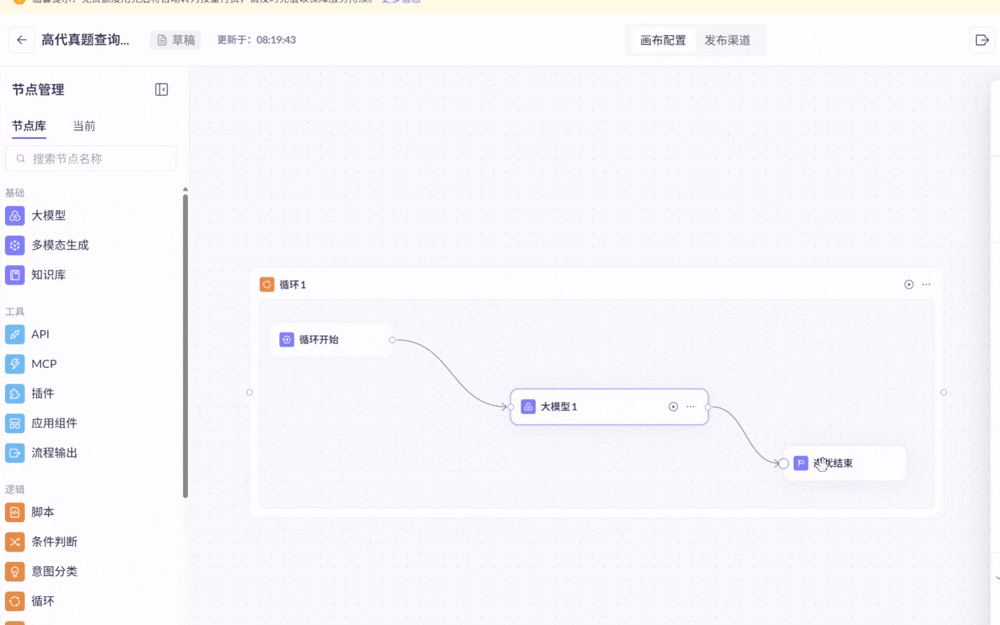
上面第一个动图是成功了的(“循环开始”与“大模型1”成功相连)
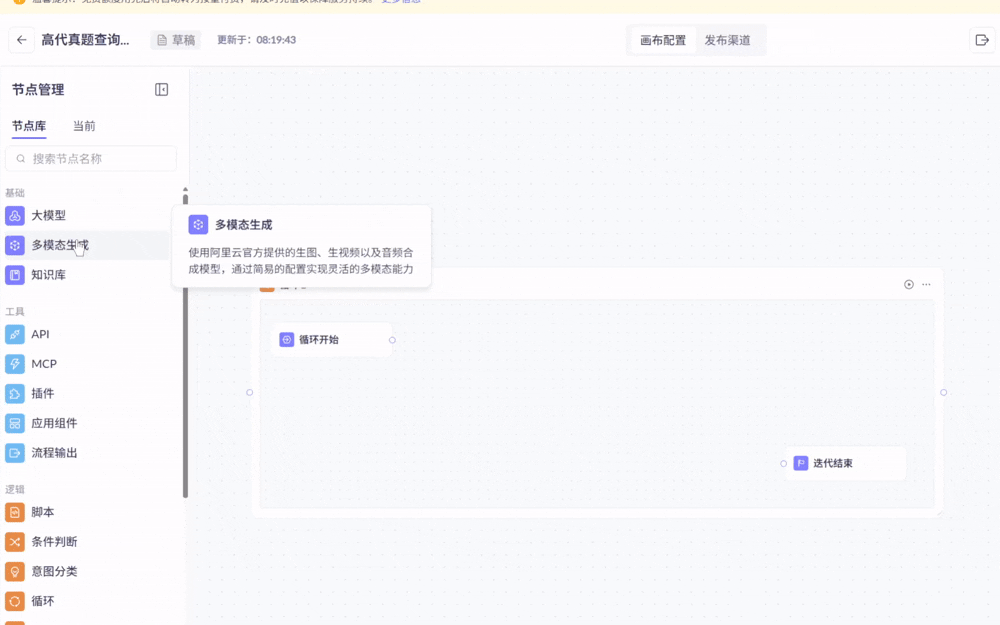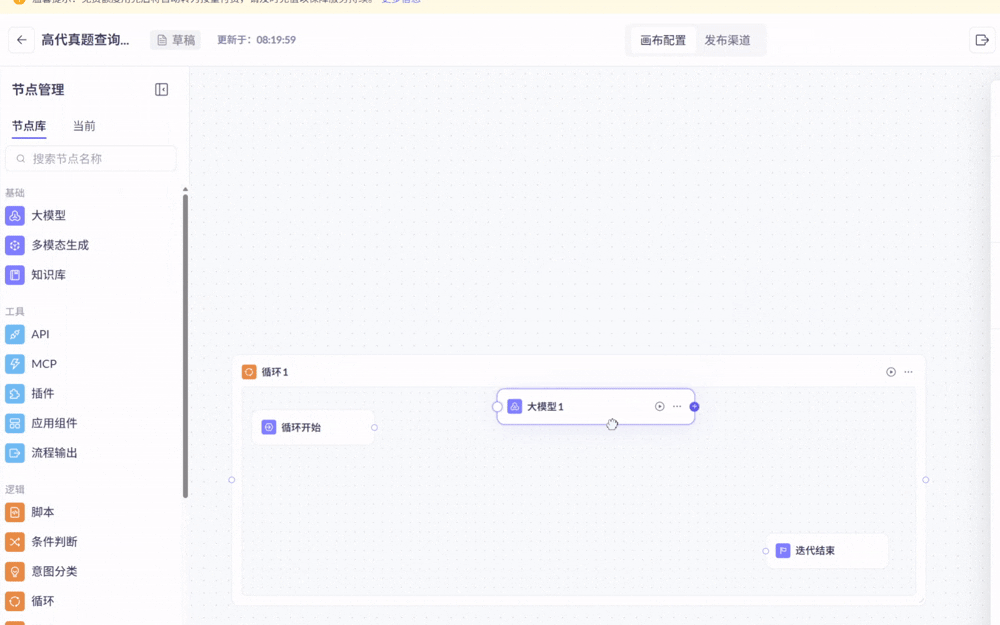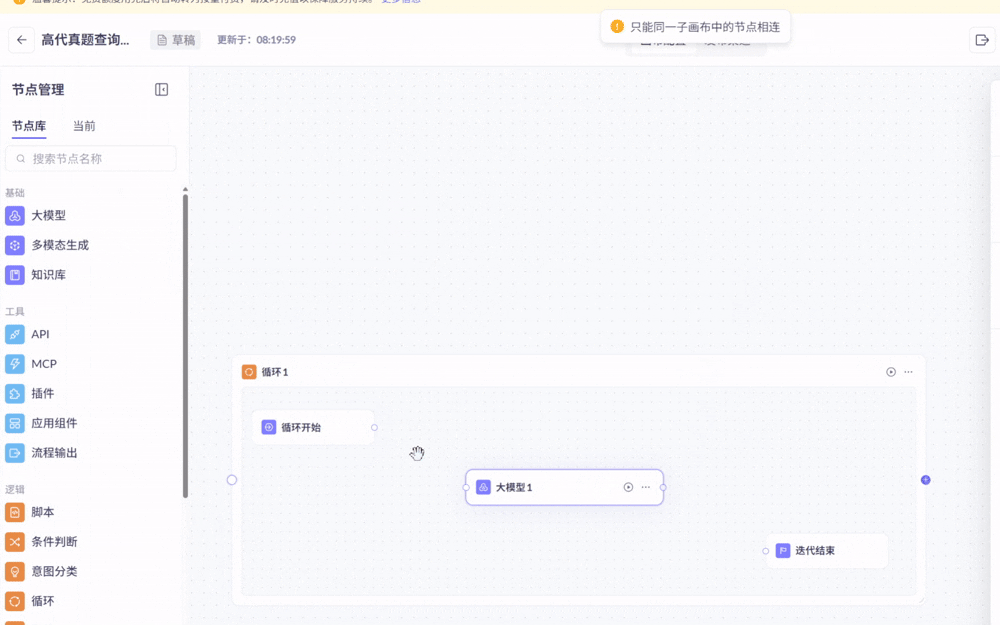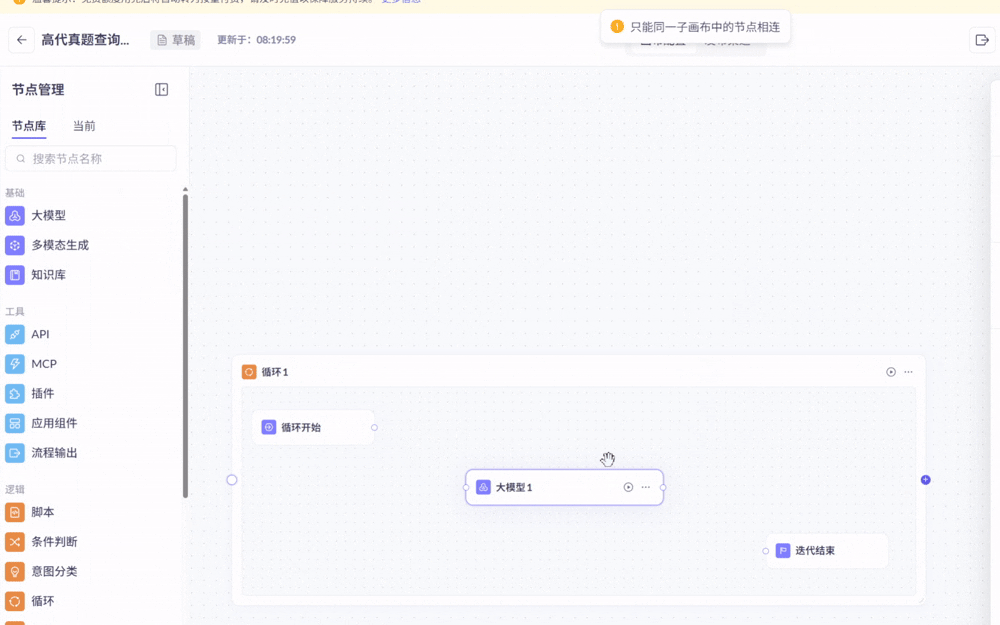
第二个动图就失败了(循环开始”与“大模型1”无法相连,系统认为这个大模型实际上并不在循环里)
原因在于:想拖进循环的大模型,必须从左侧的节点库直接一次拖入(如果第一次先拖到循环外,第二次拖到循环内就会失败)
还有很多别的隐含的操作细节,且稍微复杂一点的循环操作就会有很繁琐且严苛的连线。
而Python至少在Gemini pro的辅助下,即使只会复制粘贴,也可以有比较良好的操作体验。
(因为其报错有完整且规范的日志输出,使AI可以较准确查明错误原因)
4.目前仍面临的部分主要困难
1.因部分教材缺乏高质量PDF文件,导致云端私人知识库的局限性
(事实上,PDF格式并不天生适合AI阅读,适合AI阅读的格式有Markdown,Latex等,所以通常需要先对PDF做OCR光学识别)
很幸运,白皮书存在高质量PDF文件。
但是部分教材如裴礼文的大部分PDF质量都不高。
我们努力在闲鱼,z-library等多个平台找到的多个裴礼文PDF质量都不够高。
即使如图中785.7MB的PDF

仍然有大量下标或小标不清楚

虽然这一题可以人工根据上下文判断出来,
但是OCR扫出来大概率是有问题的,
而且这种后期修复起来工作量也很大(因大量原始信息丢失),
我们目前还没有找到可行性较高的方案,可能是需要更高精度的扫描件,或者是换别的教材或文件。
5.补充说明
1.我们目前的程序仍有较大限制,
例如单题查询时需要同时输入题目和答案,
这是因为目前我们强制要求“矿工”只去找输入的题目在白皮书的出处,明确要求它不要自己解题,否则它通常的输出效果不太好
且目前程序尚未能导出(微信公众号与钉钉机器人都不太适配)
2.很多人类独有的顶尖数学直觉,仍是目前向量检索不可企及的,故现在AI只能填补繁琐检索的空白。
3.目前使用的AI创作平台是阿里云百炼:
https://bailian.console.aliyun.com/
实际体验较好,官方有各种操作教程文档,可直接丢给Gemini
且平台客服是真人,服务态度挺好的。
此外:字节系的对应AI云创作平台为“扣子”:
https://www.coze.cn/腾讯系的对应AI云创作平台为“元器”:
https://yuanqi.tencent.com/
扮演矿工和审查员的AI均为Qwen3-max,为目前阿里系最强的推理模型,且调用方式均为API(需付费,输入0.0025元/千tokens,输出0.01元/千tokens,属于实惠的价格)
实际上新账号注册3个月内,每个模型输入输出各有100万tokens的免费额度,此外如图
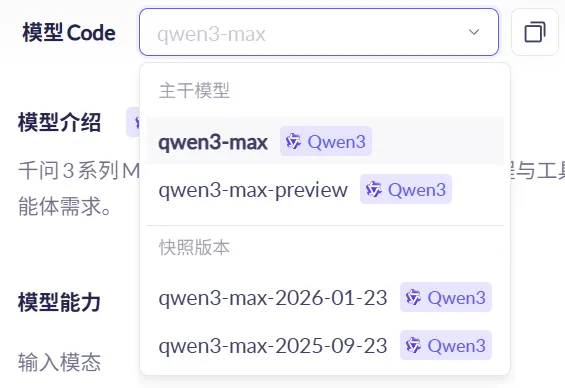
但Qwen3-max有好几个版本,且这些模型的免费额度是独立计算的。
此外云端私人知识库的租用需付费(可试用1个月,之后21.6元/月)。
试用时间和额度还是比较宽裕的
4.Gemini pro现在还是有健忘的现象,可以要求AI主动指出生产出来的重要文件,然后手动保存,若再经过较长对话后可主动发给它。
使用对话框的AI通常已经被添加好了一些提示词,
因此在探索阶段可以主动要求AI“不要迎合我的观点,你应该引导我正确思考,让我少走弯路”
5.任何一个有高清PDF的资料理论上都可以使用上述方法(转成Markdown格式后),加入知识库,被AI有效检索。
6.AI的幻觉总是存在的,但适当的操作后或许可以降到相对可以接受的频率。
7.上文部分截图中提到的“Gold Mine”,是一个专为知识库检索构建的高等代数结构化私有知识库 。它由AI从《白皮书》中提取生成,剥离了具体数字,专门记录题目的抽象拓扑骨架、核心解题技巧(Trick)及同构变种。
简单地说就是记录了每题的关键词,旨在尽可能辅助系统进行高精度的真题溯源
附录
(程序的真实运行结果为json文件,这是 AI 和 Python脚本 之间最完美的通用语言)
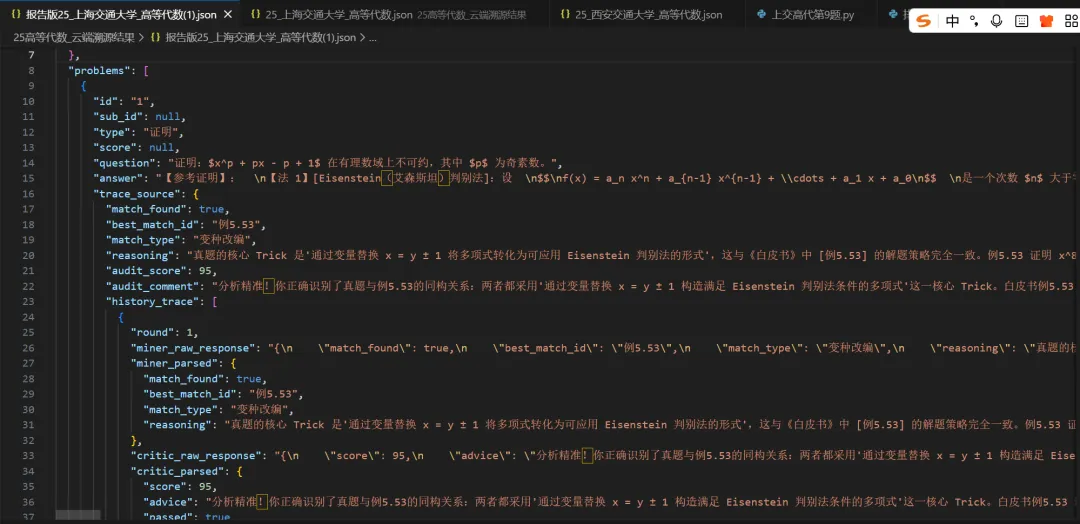
(下面的报告是我们根据上述json文件做的可视化结果)
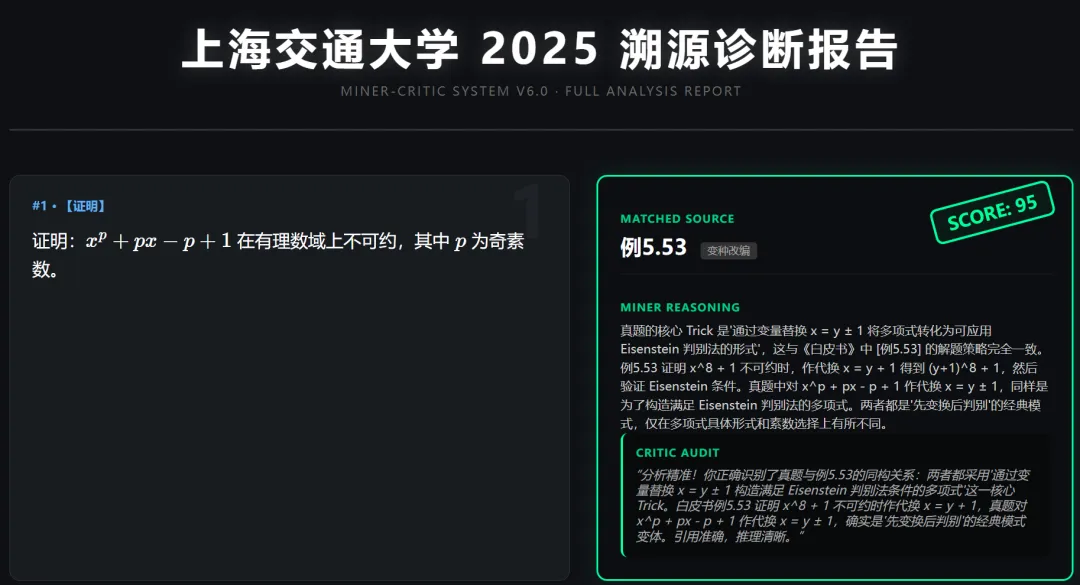
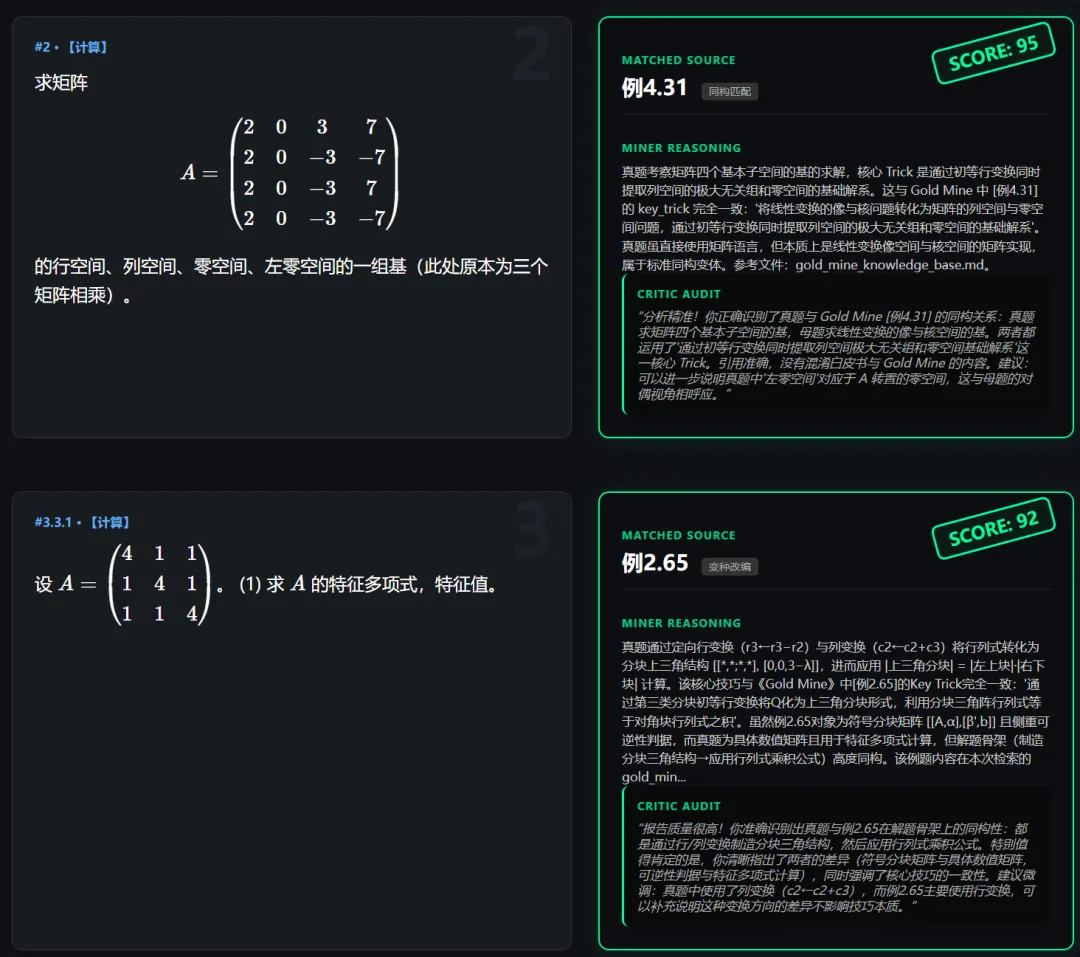



非常感谢你能耐心读到这里
文中难免写得有辞不达意的地方,且由于这是非专业程序员的摸索,如果在技术上有走了弯路的地方,恳请您在评论区不吝赐教。
在这样的一个技术日新月异的时期,
可能某一天,以前的“玩具”突然就变成“工具”了
到底应该怎么用AI工具更好地辅助我们学习,这篇文章中使用的思路,是我们的初步探索,我们也不知道最正确高效的解法是什么。
在早期探索时期,
我们曾直接将PDF版教材直接发给对话式AI,然后问某一道题的出处,效果很不好。(这是因为PDF版需要AI先OCR识别,这个会大量消耗AI算力,而平台分给一个用户一次使用的算量一般是有限的,结果就是AI幻觉严重)
之后我们将PDF转化为Markdown格式(也就是直接给AI识别好的结果)之后发给对话式AI,效果只能说确实好了一点。
之后我们才了解到业界内查询的惯用手法,
一般以下面帖子中,介绍的这项技术为起点:

下文中的“代理”就是Agent,通常就是AI


上面列举的这些行业都是对准确性要求较高。
纯数学领域或许也能从这项技术里获益。
可以看到可靠性还是有保证的。

原文章网址:https://www.vellum.ai/blog/agentic-rag (需科学上网)
未来展望
此外,上面这篇文章已经是1年前的文章了,现在已经衍生出了更多新技术
如:

其中,让AI调用外部计算工具去解决复杂计算,应该是一条可行的路
这篇架构是真实存在的,且有对应论文:https://arxiv.org/abs/2510.12350(需科学上网)
下面是论文中演示的一个具体例子:

(如下图,这个例子确实在文中真实存在的)

实际这个证明的难度就是本科难度

但它生动演示了
“AI猜一个思路,然后AI自己调用外部工具验证思路”
的可行性
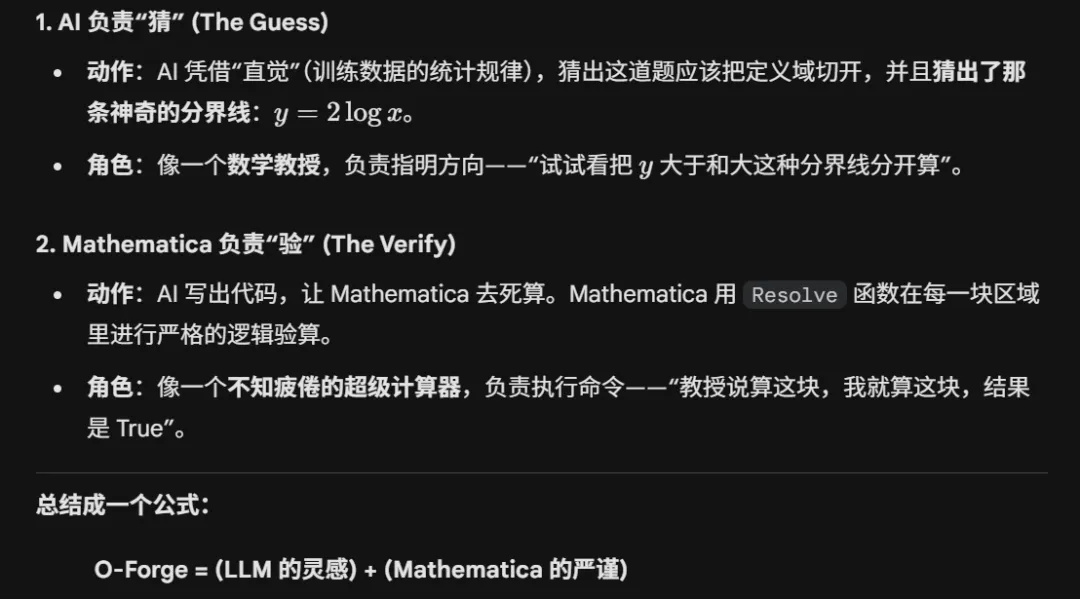
这也是我们目前的探索方向。还有很多待解决的问题:
1.例如什么复杂程度的计算需要调用Mathematica,
2.若就用Python做中转站,具体操作起来可行性怎么样。
非常感谢您的阅读