


上次测完 MiniMax Agent Desktop,我就一直在想一个问题:这些所谓"本地运行"的 Agent,真的在本地跑吗?
毕竟"隐私安全"这四个字,是最好卖也最难验证的噱头。说是本地处理,暗地里全上传云端,用户根本无从知晓。
所以这次测 Skywork Desktop Agent,我给它设了一个局。
英伟达 2025 年度财报,47.7MB,高清图表和密集财务数据。我把它放在本地文件夹,让 Skywork 去读取分析,全程开着流量监控。如果它偷偷把文件传到云端,这47.7MB 的数据量,在资源监视器里是藏不住的。
文档链接:
https://investor.nvidia.com/financial-info/annual-reports-and-proxies/default.aspx
1.2GB 的安装包,和一下午的折腾
先说安装。
下载包 1.2GB,这个体积就挺能说明问题——本地跑肯定要带不少东西。下载时间比较长,装完之后需要初始化,也要等一会儿。
到这里都还正常。
但接下来的事情,差点让我放弃这篇测评。
昨天下午,我准备直接发评测的。结果环境问题折腾了一整个下午,一直卡在虚拟机初始化阶段,死活启动不了。
启动后初始化一直转
查了半天才搞明白:国际版 Skywork 需要全局加 TUN 模式才能正常启动。
这里补充一个技术细节——Skywork 为了确保安全,是在 Linux 虚拟机里运行的。这意味着你的电脑里实际上跑着一个小型 Linux 系统,所有文件处理都在这个"沙盒"里完成。设计思路是好的,但对网络环境的要求也高。如果你的环境不支持 TUN 模式,那它就会一直卡在初始化阶段,连报错信息都没有,只能干等着。
今天早上换了个支持全局和 TUN 的环境,重新来过。这次桌面版还提示更新,索性重新下载安装。
初始化成功,登录账号,开测。
功能概览:Skills 是个亮点
Skywork 有一个我挺喜欢的设计——Skills 集成。
它内置了很多可以手动安装的 Skills,覆盖面挺广:文档处理、代码编写、数据分析、网络搜索、图像生成、任务自动化、邮件管理、日程安排等等。用的时候按需安装就行,不用的也不占资源。
这个设计比较灵活,不像有些 Agent 把所有功能一股脑塞给你,用不用得上另说。
模型选择方面有个区别:
桌面端:不能手动选模型,系统会根据任务自动匹配 Web 端:可以选 Claude 或 Gemini等模型
桌面端不给选模型,我能理解他们的考量——普通用户不需要操心这个,让系统自动判断更省心。但对于想要精细控制的用户来说,还是有点不够灵活。
为什么要用 47.7MB 财报做"钓鱼执法"
好,说回最重要的部分:隐私安全验证。
Skywork 声称的隐私保护逻辑,其实是 RAG(检索增强生成)的混合模式。说人话就是:
肉烂在锅里,汤端给客人。
具体怎么理解?
当你让 Skywork 读取本地文件夹里的一份文档,它会在你电脑的 Linux 虚拟机里,把文档切碎、建立索引。这一步不需要联网,文件不会被上传。
然后当你问"总结一下第三章",它会从本地索引里只提取第三章那几百个字的文本,发送给云端大模型(Claude/Gemini)做总结。
云端模型拿到的只是几百个字,不是你的整份文件。
这就是"真本地"和"假本地"的区别。
真本地:原文件留在硬盘,只把必要的碎片给云端。 假本地:嘴上说本地,实际全部上传云端处理。
但这套逻辑到底是不是真的?
我决定用数据说话。
流量监控抓到了什么
测试文件:英伟达 2025 年度财报 文件大小:47.7MB 内容特点:高清图表、密集财务数据

测试方法是这样的:
我先把这份 PDF 放到本地文件夹里,然后让 Skywork 选择这个文件夹。接着给它一个提示词:
请读取当前文件夹里的 NVIDIA-2025-Annual-Report.pdf,帮我深度分析一下"Risk Factors"(风险因素)章节,特别是关于"Geopolitics"(地缘政治)和供应链的部分,列出核心要点。
发送之后,我同时打开了资源监视器,一边看 Agent 界面的处理进度,一边盯着网络流量。全程截图记录。
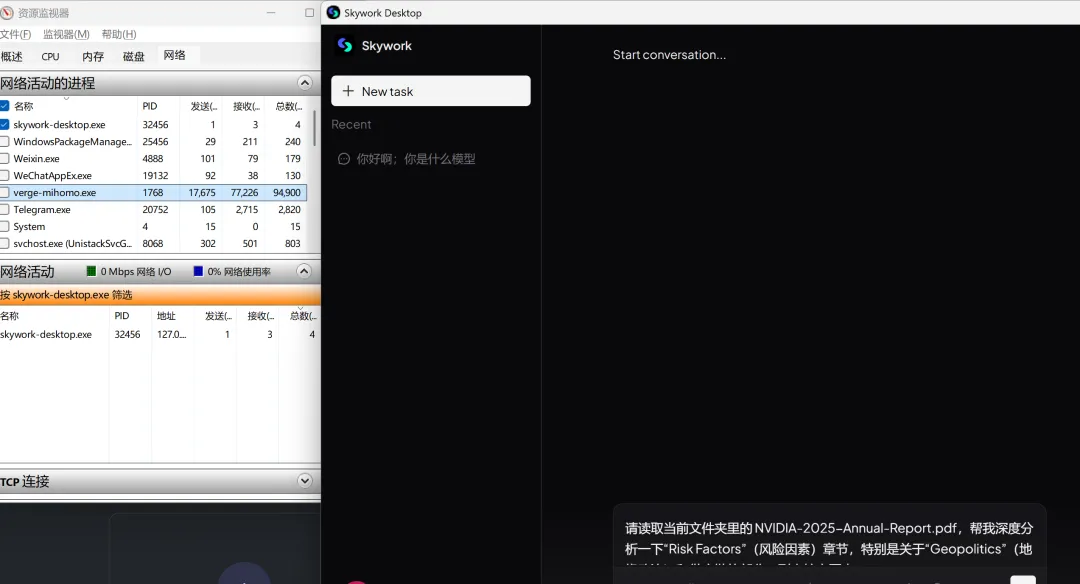
发送前截图
测试逻辑很简单:如果 Skywork 真的是在本地处理文件,那网络流量应该很小,因为它不需要把整个文件传到云端。但如果它偷偷把文件传走了,47.7MB 的数据量,在流量监控里是藏不住的。
实际观察到的情况:
互联网出口(verge-mihomo.exe)的发送速度
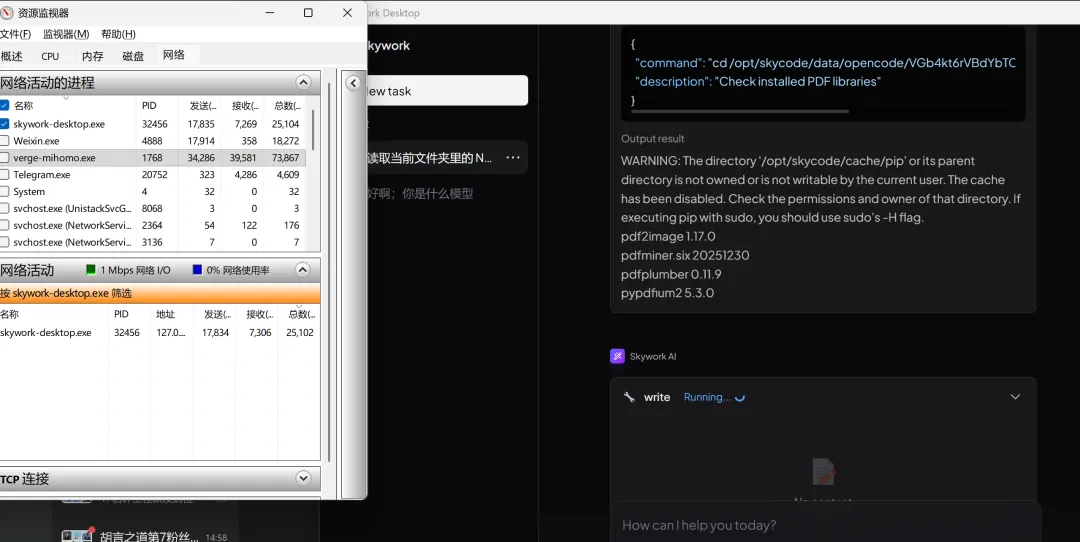
始终维持在 30-40 KB/s。
这是什么概念?这点流量,也就是正常的网络心跳和少量数据交互。跟 47.7MB 的文件完全不是一个量级。
唯一的波动出现在最后阶段,
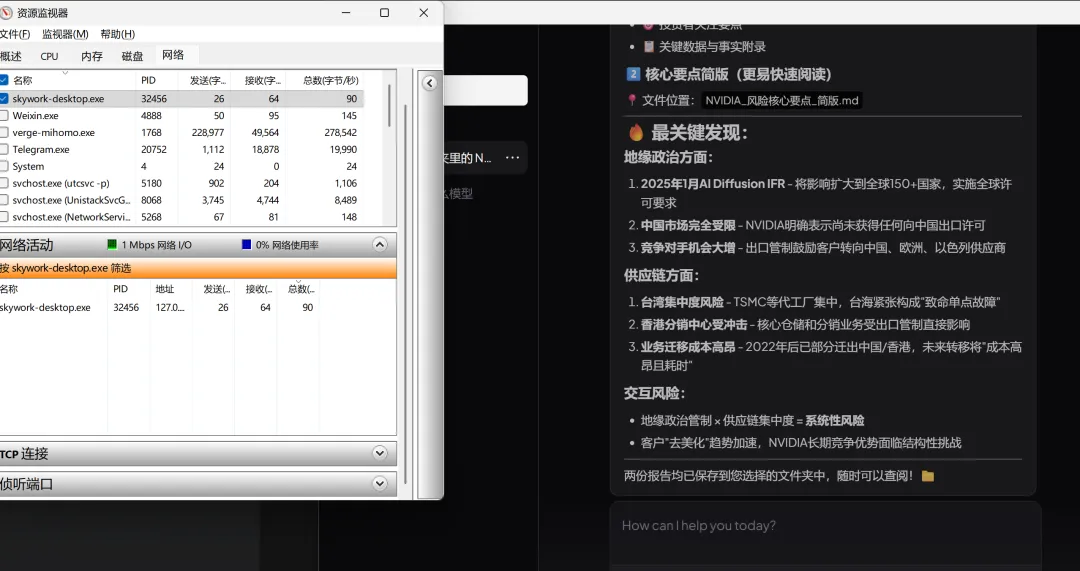
短暂跳到了 228KB/s
这 228KB/s 是什么?是 Agent 把本地提取出来的"风险因素"文本片段,发给云端模型做总结和润色。
228KB vs 47MB,这就是隐私保护的本质——原文件没动,只有提取出来的碎片出去了。
本地回环的"疯狂内卷"
流量监控还捕捉到另一个有意思的现象。
skywork-desktop.exe 的发送流量,飙升到了 835KB/s,甚至一度达到 1.6MB/s。
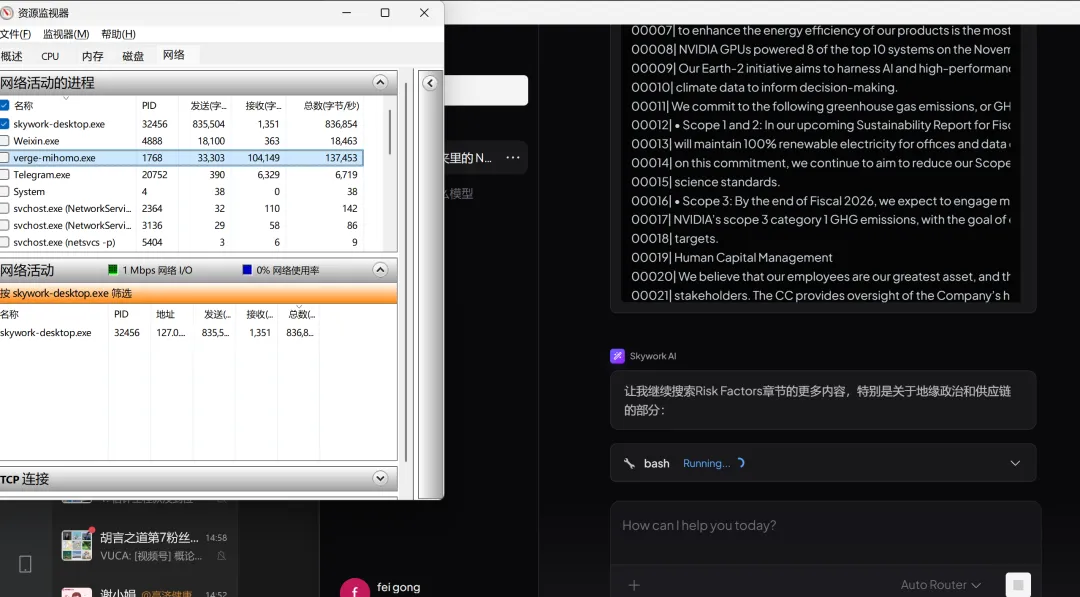
但地址列显示的是 127.0.0.1——Localhost。
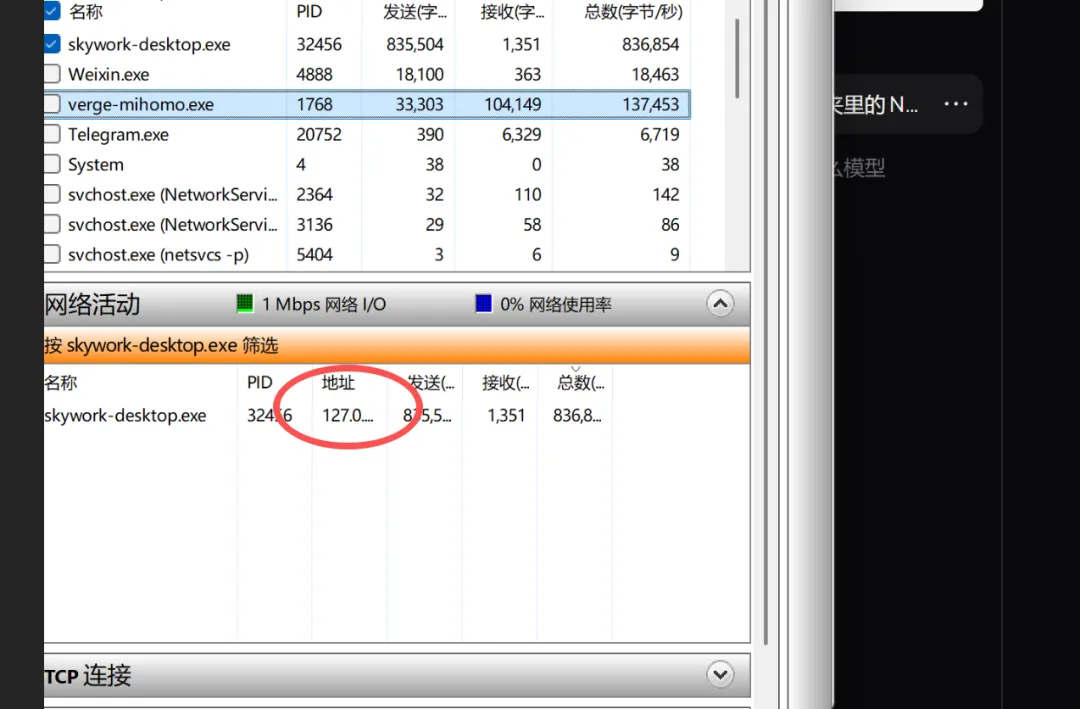
这意味着什么?
Skywork 的前端界面,在跟后台本地 Linux 虚拟机疯狂传输数据。它在你电脑内部"左右互搏",把文件拆解、切片、建索引。
这些巨大的流量,连网卡都没出,全在内存里消化了。
不是上传给云端,而是在你的电脑里左右互搏。
这个超时报错,反而证明了它的清白
还有一个意外发现。
Skywork 在处理这份 47.7MB 财报时,直接运行了一段 Python 代码:import pdfplumber,page.extract_text()。
用 Python 库在本地暴力读取 PDF 的文本。
然后,任务超时报错了:timeout 60000 ms。
实话说,看到这个报错的时候,我反而放心了。
为什么?
云端服务器算力强,解一个 PDF 很快。只有在本地电脑上,跑大文件全量分析才会因为资源限制而超时。
这个报错是"真本地"的勋章。
如果是云端处理,根本不会超时。正是因为在你自己的电脑上跑,用的是你自己的 CPU 和内存,才会因为算力不足而超时。
测试结论:真本地,但有边界
综合流量监控、本地回环、代码执行三个证据,我的判断是:
✅ Skywork 确实是真本地处理(Hybrid Local RAG 模式)
原文件(47.7MB PDF):100% 留在硬盘里,没有上传 云端交互:仅在最后阶段,发送提取出的几千字文本(KB 级别)给云端模型润色
不是完全离线,但也不是把你的文件全盘托出。
这个设计是合理的——纯本地跑不了大模型,但至少保证了原始文件不外泄。
我为什么愿意用它,又为什么不敢完全信任它
先说做对了什么。
Skywork 在隐私保护这件事上,确实用心了。虚拟机隔离、本地切片、只传碎片——这套组合拳,比很多"口头承诺本地处理"的产品靠谱得多。我用流量监控实测过,数据不会骗人。
如果你有敏感文件需要 AI 处理,比如公司财报、合同、客户资料,Skywork 是目前我测过的、能真正信任的选项之一。
但我也不敢完全放心,因为还有这些问题:
初始化太慢了。 第一次启动要等很久,尤其是虚拟机初始化阶段。急性子用户可能会以为程序卡死了。
环境要求高。 国际版需要全局 + TUN 模式,这对很多普通用户来说是门槛。我昨天折腾了一下午就是栽在这上面。
本地算力是硬伤。 处理 47.7MB 的大文件会超时,这不是 Skywork 的问题,是本地运行的天然局限。如果你经常要处理超大文档,可能还是得考虑云端方案。
我的使用边界是:
敏感文件、机密文档 → 用 Skywork 超大文件、需要快速处理 → 考虑其他方案 日常普通文件 → 看心情,哪个顺手用哪个
给你的建议:先免费试,别急着充会员
最后说几句掏心窝子的话。
现在的 AI 模型和通用 Agent 发展真的日新月异。今天的"最强",下个月可能就变成"平庸"。
所以我的建议是:
看到新 Agent 出来,先别急着充很长时间的会员 可以先免费试用,一般刚出来的 Agent 都有额度让你体验 如果实在有需求,先搞一个月的 因为后面肯定会有其他更好的 Agent 出来,到时候再换也不迟
未来通用 Agent 大战肯定会持续下去,直到最后剩下几个大的寡头。在那之前,我们作为用户,最好的策略就是保持灵活,不要被任何一家绑死。
Skywork 在隐私保护这件事上做得不错,值得一试。但它也不是完美的——初始化慢、环境要求高、本地算力有限,这些都是真实的局限。
如果这篇对你有一点帮助,点个赞或收藏一下就好 ?我会持续更新自己真实用过的 AI 工具和方法。