


字数 7242,阅读大约需 37 分钟
自动驾驶算法范式演进深度研究报告:从规则解耦到世界模型的认知飞跃
1. 智驾技术栈的认识论重构
自动驾驶技术的演进史,在本质上是一部人工智能试图理解并预测物理世界的认识论进化史。从早期的模块化规则堆叠,到如今的生成式大模型与端到端架构,智驾系统正在经历一场从“工程师定义规则”向“数据定义行为”的深刻范式转移(Paradigm Shift)。这种转变不仅重塑了车载软件栈(Software Stack)的架构,更根本地改变了算力需求、数据闭环逻辑以及人机共驾的交互本质。
本文将基于深度技术研究,详尽剖析当前自动驾驶领域的四大核心技术范式:传统CNN感知+规则规控、基于BEV的融合感知+规则规控、完整端到端智驾模型,以及基于大模型的VLA与世界模型方案。这四个阶段并非简单的线性替代,而是体现了系统对环境不确定性处理能力的指数级提升——从确定性的几何计算,迈向概率性的场景推理。
本文将深入解构每一范式背后的技术哲学、架构原理及局限性,并选取Tesla、Mobileye、理想、小鹏、华为及学术界(如UniAD、Wayve)的典型模型作为案例,结合参数规模与硬件约束(如Scaling Law验证、显存带宽瓶颈),并进行详尽技术分析。
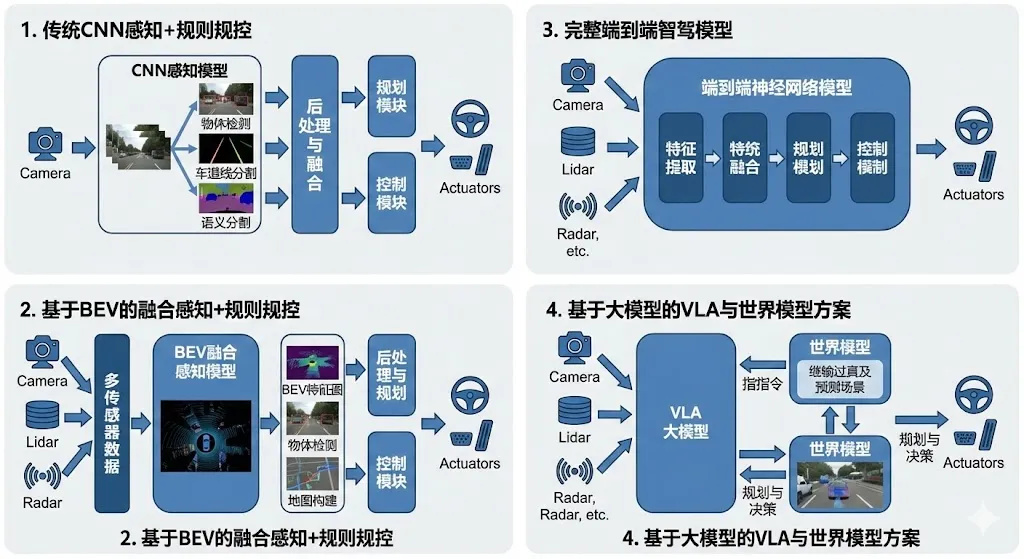
2. 第一范式:传统 CNN 感知 + 规则规控
在深度学习介入自动驾驶的初期(约2015年至2020年),行业的主流架构呈现出显著的“模块化解耦”特征。这一时期的核心设计哲学是将复杂的驾驶任务分解为一系列可独立定义、可测试的子问题:感知(Perception)、定位(Localization)、预测(Prediction)、规划(Planning)和控制(Control)。神经网络(主要为卷积神经网络CNN)的应用局限于感知前端,而系统的“大脑”——规控模块,则完全由人工编写的规则代码(Heuristics)主导。
2.1 技术架构与运行机理
2.1.1 2D 图像空间的特征提取
在该范式下,视觉感知主要在各自独立的2D图像空间(Image Space)内完成。每一个摄像头(前视、侧视、后视)被视为独立的传感器,分别运行目标检测(Object Detection)和语义分割(Semantic Segmentation)算法。
• Backbone选择:早期的主干网络多采用ResNet(残差网络)、VGG或轻量级的MobileNet。其目标是提取图像的纹理和边缘特征。 • 后融合(Late Fusion)策略:由于缺乏统一的3D空间表达,多传感器融合通常发生在“目标级”(Object Level)。即视觉模块输出一个目标列表(List of Objects),雷达输出另一个列表,系统通过卡尔曼滤波(Kalman Filter)或匈牙利算法(Hungarian Algorithm)在后处理阶段对这些目标进行匹配和状态估计。
2.1.2 规则驱动的“防御性”规控
规划与控制模块是这一范式的瓶颈所在。工程师需要预设海量的if-else逻辑来应对交通场景。
• 有限状态机(Finite State Machine, FSM):用于决策层的状态流转(如:跟车状态 -> 换道状态)。 • 优化算法:如EM Planner(Expectation-Maximization),在Frenet坐标系下通过二次规划(QP)求解最优路径曲线。这种架构的致命缺陷在于信息损耗(Information Drop)和误差累积(Error Propagation)。感知模块将丰富的像素信息压缩为稀疏的3D边界框(Bounding Box),导致规控模块丢失了场景的语义上下文(如前车的刹车灯亮起、行人的姿态倾向),不得不依赖极其保守的规则来保证安全。
2.2 典型模型与方案代表
2.2.1 Tesla Autopilot (Early HydraNet Era / Pre-FSD Beta)
在FSD Beta发布之前(约2018-2020年),Tesla Autopilot是CNN感知加规则规控的集大成者。
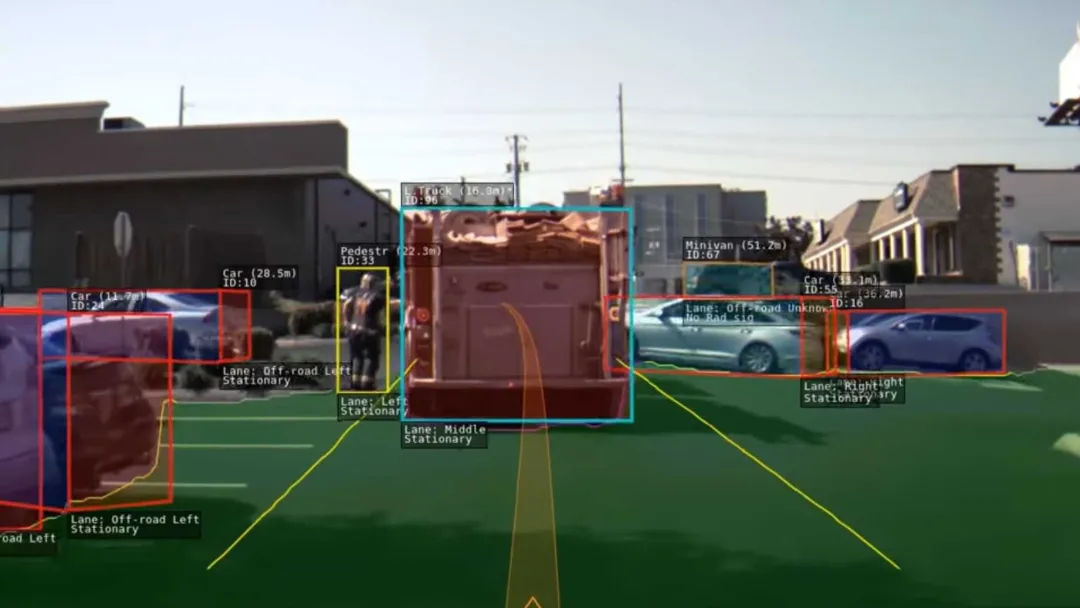
• 模型架构:HydraNet(九头蛇网络) • Shared Backbone:为了在有限的硬件资源(如HW2.5的NVIDIA GPU或HW3.0早期)上运行多任务,Tesla引入了HydraNet架构。它使用一个共享的主干网络(早期为修改版ResNet-50,后演进为RegNet [1])来提取基础特征。 • Multi-Heads:在共享特征之上,生长出多个特定任务的“头”(Heads)。每个头负责不同的感知任务,如车道线检测、车辆分类、交通灯识别等。这种多任务学习(Multi-Task Learning)策略大幅降低了重复计算量。 • 参数量与算力背景: • 参数规模:虽然Tesla从未公开具体数字,但根据同类ResNet-50及其变体推算,早期Backbone参数量约在2,500万至5,000万之间。加上数十个轻量级的Heads,整个HydraNet的参数规模预计在5,000万至1亿量级。 • 规控代码:此时的Autopilot包含了超过30万行C++控制代码 [3],用于处理感知输出后的逻辑判断。这些代码是“硬编码”的驾驶策略。
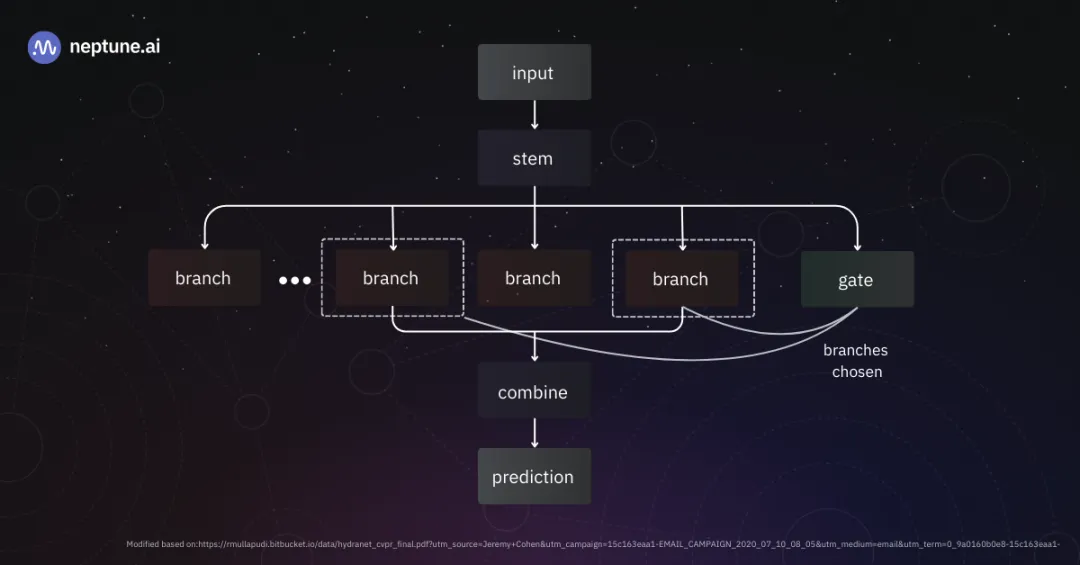
2.2.2 Mobileye EyeQ4 视觉感知栈
Mobileye是这一范式下最成功的Tier 1供应商,其EyeQ系列芯片定义了L2辅助驾驶的行业标准。
• 模型架构:Deep Layered Networks (DLN) • Mobileye的算法并非运行在通用的GPU上,而是紧耦合于EyeQ芯片的异构计算单元(VMP/PMA/MPC)。其核心算法是高度定制化的CNN与传统计算机视觉(CV)技术的混合体 [4]。 • 深度分层网络:EyeQ4运行着多个针对特定几何任务优化的轻量级网络。例如,专门用于车道线边缘拟合的网络,其结构并非标准的各种卷积层堆叠,而是包含大量硬化的算子。 • 参数量与性能: • 极致能效:EyeQ4(2018年量产)仅提供2.5 TOPS算力,功耗约3W [4]。为了在这种算力下实现高精度感知,其模型参数被极致压缩,推测核心感知网络的有效参数量仅在数百万(<10M) 级别。 • 局限性:这种“黑盒”交付模式使得车企无法修改内部算法,且基于2D感知的测距精度高度依赖摄像头的安装标定和地面平整度假设。
2.2.3 Baidu Apollo (早期版本 3.0 - 5.0)
百度Apollo作为开源自动驾驶平台,其早期架构是模块化设计的教科书案例。
• 模型架构: • 感知层:采用MobileNet-SSD或YOLO系列进行视觉检测,结合PointPillars处理激光雷达点云 [6]。视觉与雷达采用后融合策略。 • 预测层:使用LSTM(长短期记忆网络)或RNN处理障碍物的历史轨迹,预测未来几秒的路径。 • 参数量: • 考虑到车载部署的实时性(通常基于工业PC或Nvidia Drive PX2),Apollo感知模型的参数量通常被剪枝量化到1,000万左右。 • 高精地图依赖:为了弥补感知能力的不足,该阶段的Apollo系统极度依赖高精地图(HD Map)提供的先验信息,这本质上是将感知的压力转移到了离线地图制作上 [8]。
3. 第二范式:基于BEV的融合感知 + 规则规控
随着Transformer在计算机视觉领域的引入(ViT),以及对多传感器时空对齐需求的爆发,自动驾驶感知在2021年前后经历了一次彻底的维度升级——从2D图像空间向 3D鸟瞰图(Bird's Eye View, BEV) 空间的统一。这一范式解决了传统视觉测距不准、多视角拼接困难及遮挡问题,但下游的规控模块在很长一段时间内依然保留了规则驱动的内核。
3.1 技术变革:空间与时间的统一
3.1.1 视角转换(View Transformation)
BEV感知的核心挑战是如何将透视视图(Perspective View)的特征无损地转换到正交视图(Orthographic View)。
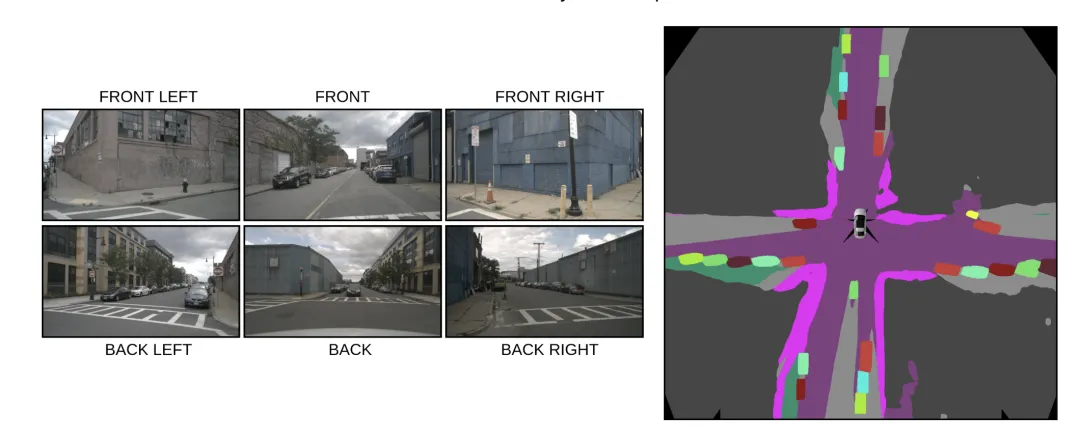
• LSS (Lift-Splat-Shoot):通过预测图像像素的深度分布,将其“提升”为3D点云,再“拍扁”到BEV平面。 • Transformer (如BEVFormer):利用Cross-Attention机制,在BEV空间构建Query(查询向量),主动去各个摄像头的特征图中“查询”对应的信息。这种方法不依赖显式的深度预测,对多视角融合更加鲁棒。
3.1.2 特征级融合与时序记忆
• 特征级融合(Feature-Level Fusion):激光雷达的点云特征和摄像头的图像特征在BEV空间下可以直接拼接或叠加,实现了真正的前融合(Early Fusion),大幅提升了对异形障碍物的检出率。 • 时序模块(Temporal Module):引入时间维度,利用历史帧的BEV特征(通过自车运动补偿对齐)来构建4D时空空间。这使得车辆能够拥有“记忆”,解决短暂遮挡和速度估计问题。
3.2 典型模型与方案代表
3.2.1 Tesla FSD Beta (v11 / Occupancy Network Era)
Tesla在FSD Beta的迭代中,彻底重构了其感知栈,也是BEV+Transformer架构的工业界先驱。
• 模型架构:RegNet Backbone + BiFPN + Transformer + Occupancy Network • HydraNet的进化:虽然仍保留了HydraNet的多头结构,但中间层引入了巨大的Transformer模块用于时空融合。 • Occupancy Network(占用网络):这是v11的核心突破。传统的检测网络输出的是物体类别和方框(Whitelists),而占用网络将3D空间划分为微小的体素(Voxels),预测每个体素被占用的概率(Occupancy Grid) [9]。这意味着车辆可以识别从未见过的物体(如侧翻的卡车、路面掉落的轮胎),实现了对通用障碍物(General Obstacles)的感知。 • Lane Neural Network:采用Transformer解码器,以自回归的方式预测车道线拓扑图,解决了车道分叉和汇入的复杂连接关系 [9]。 • 参数量与硬件适配: • 算力极限优化:这些复杂的网络运行在算力仅为144 TOPS的HW3.0芯片上。为了塞进有限的SRAM和DRAM,Tesla对模型进行了极致的量化和结构优化。 • 参数估算:据社区与技术分析,FSD Beta v11中核心的感知Transformer及占用网络参数量总和约为3亿至6亿(300M - 600M)。这相比云端大模型虽小,但在边缘端已是巨无霸 [10]。 • 规控层:尽管感知已经非常先进,v11的规控层依然依赖蒙特卡洛树搜索(MCTS)和大量的C++启发式规则(如只有在特定条件下才允许变道)。
3.2.2 Xpeng XNet 1.0 / 2.0 (小鹏汽车)
小鹏汽车是国内首家量产BEV+Transformer架构的车企,其技术路径与Tesla高度对标。
• 模型架构:XNet 深度视觉神经网络 • XNet 1.0:引入多相机多帧的时序融合,利用Transformer将视频流转换为BEV视角下的动态目标和静态道路结构。其核心在于用一个大模型替代了以前多个独立的小模型,实现了感知的端到端训练 [11]。 • XNet 2.0 (XOS 5.1.0 Tianji):引入了2K纯视觉占用网络。相比Tesla早期的占用网络,XNet 2.0强调高分辨率(2K网格),能够重构高保真的3D世界,感知范围扩大至1.8个足球场大小 [12]。 • 参数量与云端协同: • 车端模型:运行在NVIDIA Orin-X(254/508 TOPS)上。推测车端推理模型的参数量在**数亿(100M - 500M)**级别。 • 云端训练:小鹏强调其云端基础模型参数量高达720亿(72B) [15]。这是一个重要的趋势:车端的小模型是由云端的大模型通过知识蒸馏(Knowledge Distillation)和剪枝得到的。云端大模型利用海量数据学习通用特征,然后“教”车端模型如何高效感知。
3.2.3 Huawei ADS 2.0 (GOD + RCR)
华为ADS 2.0以“无图智驾”为核心卖点,其技术架构是对BEV感知的进一步深化。
• 模型架构:BEV + GOD (General Obstacle Detection) + RCR (Road Cognition & Reconstruction) • GOD网络:华为版本的占用网络。它不依赖物体分类白名单,而是基于几何占用来判断障碍物。这直接解决了“异形障碍物”识别难题,是无图方案安全性的基石 [16]。 • RCR网络:道路拓扑推理网络。在没有高精地图的情况下,RCR网络实时推理路口的复杂拓扑结构(如左转待转区、潮汐车道),实际上是实时生成了一张局部高精地图。 • 技术参数: • 运行平台为华为MDC(基于Ascend芯片)。 • GOD网络是一个参数量巨大的感知模型,据称其训练数据量和网络深度远超ADS 1.0。虽然具体参数未公开,但从其能够处理复杂城中村场景的能力来看,其感知网络的复杂度处于行业顶尖水平(预计数亿参数规模)。
4. 第三范式:完整端到端智驾模型
第三范式标志着自动驾驶从“模块化拼装”走向了“整体性涌现”。端到端(End-to-End, E2E) 的核心定义是:输入原始传感器数据(Photon),直接输出控制指令(Control)或可微的规划轨迹,中间不再有人工设计的规则接口。这一范式移除了作为信息瓶颈的“中间件”(如目标列表),允许梯度从最终的控制误差反向传播回感知层,实现全局最优。
4.1 技术哲学:数据驱动的“直觉”
端到端模型本质上是模仿人类的“直觉驾驶”(System 1 Thinking)。人类司机在驾驶时,并不会在大脑中画出3D边界框或计算曲率,而是基于视觉输入直接产生肌肉反应。端到端模型通过模仿学习(Imitation Learning),从数百万小时的人类驾驶视频中学习这种“输入-输出”的映射关系。
4.2 典型模型与方案代表
4.2.1 Tesla FSD v12 (Neural Planner / Photon-to-Control)
FSD v12是工业界首个大规模量产的端到端自动驾驶模型,被认为是自动驾驶的“ChatGPT时刻”。
• 模型架构:End-to-End Neural Network • 规则代码移除:Elon Musk透露,v12移除了超过30万行C++控制代码。以前用于判断“谁先走”、“如何避让”的显式规则,全部被神经网络的隐式权重替代 [3]。 • 单一网络流:输入8个摄像头的视频流和导航指令,直接输出转向、加速和制动指令(或极短期的微观轨迹)。虽然内部可能仍有分层的特征提取(RegNet/ResNet Backbone -> Transformer -> Head),但整个链路是打通的,不存在不可导的模块。 • 训练策略:Video Pre-training (视频预训练) + Imitation Learning。Tesla只使用“五星级”人类驾驶数据(甚至去除了急刹车等不良行为)进行训练,让模型学习丝滑的博弈和交互 [3]。 • 参数量与硬件约束: • 参数估算:尽管外界猜测纷纷,但考虑到其必须在HW3.0(144 TOPS,有限内存带宽)上运行,FSD v12的模型参数量不可能像LLM那样巨大。社区分析和技术推测认为,其参数量可能在**10亿至20亿(1B - 2B)**之间 [19]。 • 计算密度:这个参数量对于实时视频处理(36fps x 8 cameras)来说,计算密度极高。HW3.0在该版本下已接近满载,这也是为何Tesla急于推出AI5芯片的原因。
4.2.2 UniAD (Unified Autonomous Driving) - 学术界标杆
UniAD是CVPR 2023的最佳论文(Best Paper),它展示了如何在保留模块化可解释性的同时,实现端到端的全局优化。
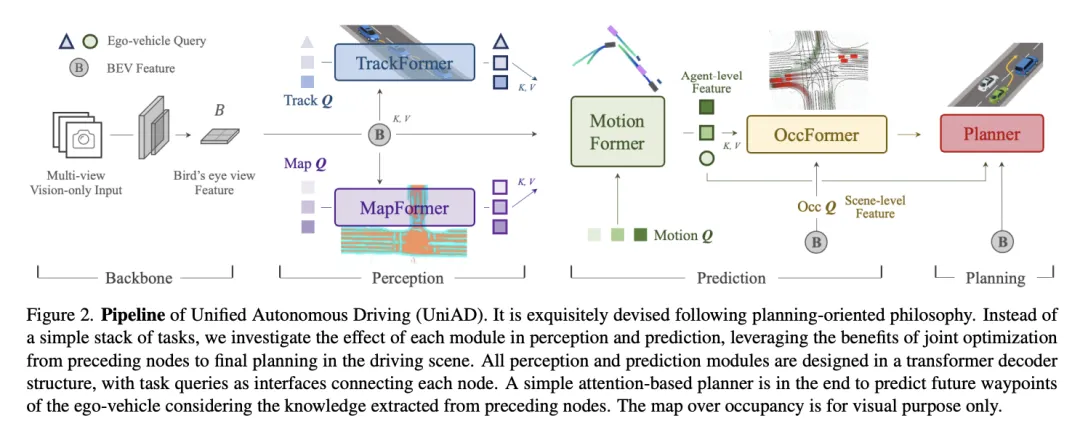
• 模型架构:Planning-oriented Philosophy (以规划为导向) • Query-based Design:UniAD并未将系统做成一个不可解释的黑盒,而是将感知(Tracking, Mapping)、预测(Motion)、规划(Planning)整合在一个Transformer架构中 [21]。 • 统一接口:利用Query(查询向量)连接各个模块。例如,TrackFormer输出的物体Query直接作为MotionFormer的输入。这种设计使得下游规划的需求可以指导上游感知关注什么(Task-driven Perception)。 • 参数量与性能: • UniAD通常使用ResNet-101作为Backbone,加上多个Transformer Decoder层。 • 整个模型的参数量大约在**2亿至5亿(200M - 500M)**级别。 • SOTA表现:在nuScenes数据集上,其规划碰撞率仅为0.31%,大幅优于传统模块化方案,证明了多任务联合优化的有效性 [24]。
4.2.3 Huawei ADS 3.0 (GOD + PDP)
华为在2024年发布的ADS 3.0,宣称实现了架构的端到端化,去除了BEV网络,全面转向GOD大网。

• 模型架构:GOD大网 + PDP (Prediction-Decision-Planning) 网络 • GOD大网:将原本的BEV感知和GOD网络融合,形成一个参数量更大、深度更深的感知网络。它不仅输出障碍物占用,还深度理解场景语义 [25]。 • PDP网络:这是ADS 3.0的核心变革。它将预测、决策和规划三个原本独立的模块合并为一个神经网络(预决策规划网络)。这使得系统能够实现多条轨迹的动态规划,实现“所见即所行” [16]。 • 技术演进:PDP网络的引入标志着华为正式去除了大量的规则规控代码。华为称其为“类人思考”的驾驶网络,能够处理从车位到车位的全场景连贯驾驶。虽然具体参数未公开,但考虑到华为MDC的高算力(通常在200-400 TOPS范围),其端到端网络规模应与Tesla FSD v12处于同一量级(1B左右)。
5. 第四范式:基于大模型的VLA或者WorldModel方案
这是目前自动驾驶技术的最前沿(State-of-the-Art),旨在将**大语言模型(LLM)的通用推理能力(Reasoning)和世界模型(World Model)的未来预测能力引入智驾系统。这一范式试图解决端到端模型“不可解释”和“缺乏常识”的顽疾,向具身智能(Embodied AI) 迈进。
5.1 技术哲学:系统1与系统2的融合
诺贝尔奖得主丹尼尔·卡尼曼提出的“快思考(System 1)”和“慢思考(System 2)”理论被广泛应用于此范式:
• System 1(端到端模型):负责毫秒级的直觉反应(如车道保持、紧急避让)。 • System 2(VLA/VLM):负责需要逻辑推理的长尾场景(如理解复杂的路牌文字、应对交警手势、处理从未见过的交通事故现场)。
5.2 典型模型与方案代表
5.2.1 Li Auto (理想汽车) - End-to-End + VLM (Dual System)
理想汽车在2024年发布的双系统架构,是这一范式最典型的量产实践。
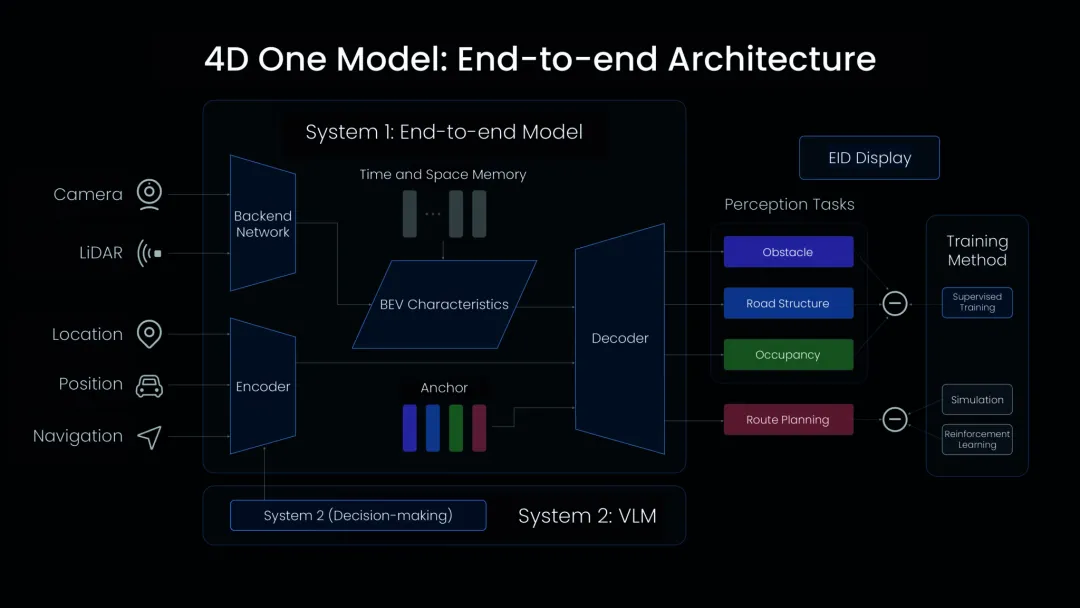
• 模型架构:System 1 (E2E) + System 2 (VLM) • System 1 (端到端模型):处理95%的常规驾驶场景。它是一个单一模型,输入传感器数据,输出轨迹。参数量约为3亿(300M),响应速度极快(几十毫秒),运行在NPU上 [27]。 • System 2 (VLM - Vision Language Model):处理5%的复杂长尾场景。它具备视觉和语言的对齐能力,能够“看懂”环境并进行逻辑推理。其参数量约为22亿(2.2B),响应时间约为300毫秒,运行在GPU上 [27]。 • Mind GPT-3o:理想自研的车载多模态大模型,不仅用于座舱语音交互,也为智驾提供认知支持 [30]。 • 硬件挑战:在车载芯片(如Orin-X)上运行2.2B参数的模型对显存带宽(Memory Bandwidth)是巨大挑战。理想通过量化和算子优化实现了这一部署。
5.2.2 Wayve GAIA-1 & LINGO-1
英国初创公司Wayve是生成式AI自动驾驶的领军者,其技术路径完全跳出了传统的判别式AI。
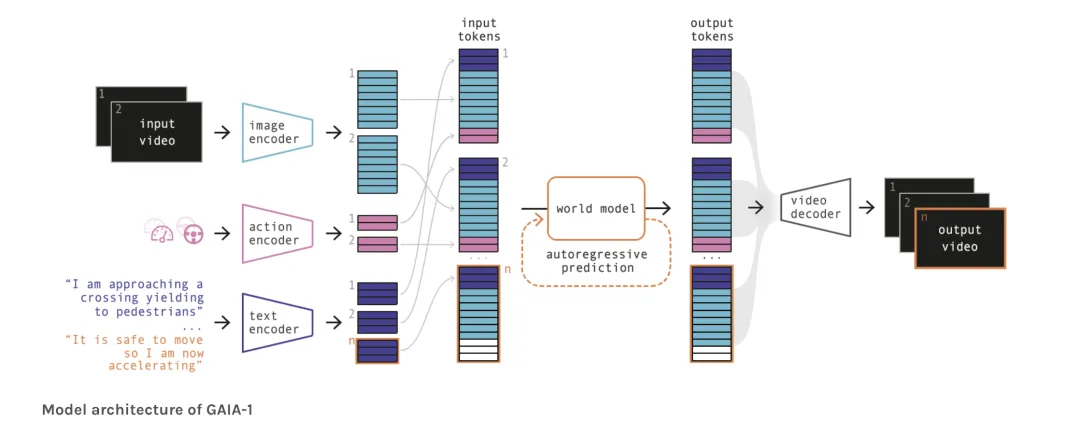
• 模型架构: • GAIA-1 (Generative AI for Autonomy):一个生成式世界模型。它输入视频、文本和动作,能够自回归地预测下一帧视频(Next Token Prediction)。它证明了模型如果能生成逼真的未来视频,也就理解了物理世界的规则 [32]。 • LINGO-1:视觉-语言-动作模型(VLAM)。它可以一边开车,一边用自然语言解释自己的行为(例如:“我正在减速,因为前方有一辆车在倒车”)。这提供了极强的可解释性,是通往可解释AI的重要一步 [34]。 • 参数量: • GAIA-1:参数量高达90亿(9B)。其中World Model部分65亿,Video Decoder部分26亿 [32]。这种规模的模型目前主要在云端运行,用于生成合成数据(Synthetic Data)来训练车端模型,或者作为离线仿真器。
5.2.3 Tesla World Model (FSD Unsupervised / Robotaxi)
虽然Tesla主要宣传其端到端能力,但其背后的训练和验证体系严重依赖世界模型技术。
• 技术逻辑:Tesla利用其全球车队采集的数十亿英里视频数据,训练了一个通用的世界模型。这个模型不仅用于FSD的“大脑”,还用于构建这就能够生成极端角点案例(如有人突然冲出、外星人入侵街道等)的Gen-AI Simulation系统 [35]。 • 参数与Scaling Law: • Scaling Law验证:Waymo和NVIDIA的研究均表明,智驾模型的性能(如轨迹预测准确率)与计算量、数据量和参数量呈**幂律(Power Law)**关系 [36]。 • 参数推测:随着Tesla AI5芯片(预计算力数千TOPS)和Dojo超级计算机的投入,未来的FSD模型(用于Robotaxi)参数量可能会激增至**100亿(10B+)**级别,真正实现对物理世界的通用理解。
6. 模型参数与算力需求横向对比表
为了直观展示自动驾驶从感知智能向认知智能跨越过程中的模型规模膨胀,下表对各范式的典型模型进行了参数量和硬件需求的对比:
| I. 传统CNN+规则 | Tesla HydraNet (Early) | ~50M - 100M | |||
| Mobileye EyeQ4 | < 10M | ||||
| Baidu Apollo (Early) | ~10M - 20M | ||||
| II. BEV融合+规则 | Tesla FSD Beta (v11) | ~300M - 600M | |||
| Xpeng XNet 1.0 | ~100M - 500M | ||||
| Huawei ADS 2.0 | ~300M - 500M | ||||
| III. 端到端模型 | Tesla FSD v12 | ~1B - 2B | |||
| UniAD (Base) | ~200M - 500M | ||||
| Huawei ADS 3.0 | ~1B | ||||
| IV. 大模型/VLA | Li Auto System 2 (VLM) | 2.2B | |||
| Wayve GAIA-1 | 9B | ||||
| NVIDIA Alpamayo | ~10B+ |
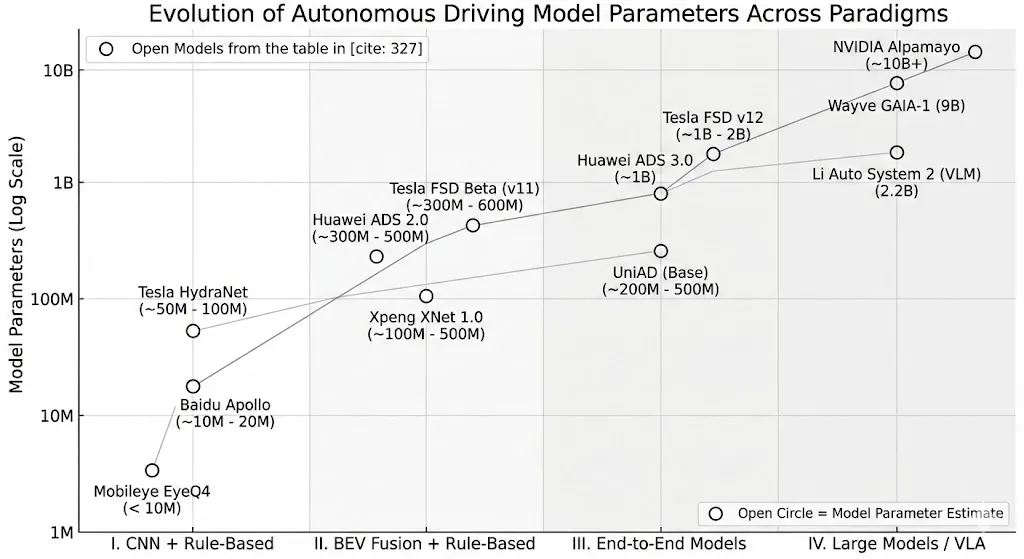
(注:部分参数量为基于芯片SRAM/DRAM带宽限制及社区技术拆解的估算值,厂商通常将其视为核心机密不予公开。)
7. 深度洞察与未来技术展望
7.1 内存墙(Memory Wall)成为新瓶颈
在CNN时代,瓶颈往往是算力(TOPS);而在Transformer和大模型时代,瓶颈彻底转移到了显存带宽(Memory Bandwidth)。
• KV Cache压力:Transformer在推理时的KV Cache机制对显存占用和读取速度要求极高。Li Auto的2.2B VLM在车载运行已经是极限操作。 • 硬件演进:这也解释了为何NVIDIA Thor芯片和Blackwell架构如此强调显存带宽和FP4/FP8低精度推理能力 [38]。未来的智驾芯片将更像是一个“带轮子的H100”。
7.2 Scaling Law 在智驾领域的验证
Waymo最新的研究证实,自动驾驶模型的性能(如Motion Forecasting准确率)与计算量、数据量和参数量呈现严格的幂律关系(Power Law) [36]。
• 这意味着,只要持续堆叠算力和数据,端到端模型的上限远未到来。这为行业巨头(Tesla, Waymo, Huawei)继续加大投入提供了理论依据,也为中小玩家竖起了难以逾越的壁垒。
7.3 从“感知世界”到“想象世界”
世界模型(World Model)的引入,让自动驾驶从“被动反应”进化为“主动预测”。通过在潜空间(Latent Space)中模拟无数种未来的可能性(Counterfactual Reasoning),车辆可以在毫秒间预演并选择最安全的路径。这种基于模型的强化学习(Model-based RL)是通往L4/L5级完全自动驾驶的必经之路。
8. 结论
自动驾驶技术已经完成了从几何计算(CNN+规则)到空间认知(BEV+Transformer),再到行为拟合(端到端)的跨越。当前,行业正站在认知智能(Cognitive AI) 的门槛上,VLA和世界模型正在赋予车辆以常识和推理能力。这一进程不仅是算法的胜利,更是数据闭环、算力基础设施和芯片架构协同进化的结果。随着FSD v12的规模化落地和VLM的上车应用,我们有理由相信,一个具备通用物理世界理解能力的自动驾驶系统正加速驶来。
参考
1. Self-Driving Cars With Convolutional Neural Networks (CNN) - Neptune.ai, https://neptune.ai/blog/self-driving-cars-with-convolutional-neural-networks-cnn 2. Tesla's Self Driving Algorithm Explained - Towards AI, https://towardsai.net/p/l/teslas-self-driving-algorithm-explained 3. Tesla FSD v12 shifts away from 'rules-based' approach - Teslarati, https://www.teslarati.com/tesla-full-self-driving-12-rules-based/ 4. Mobileye EyeQ4 Vision Processor Family - System Plus Consulting; - Yole Group, https://medias.yolegroup.com/uploads/2019/04/SP19462-YOLE-Mobileye-EyeQ4-Vision-Processor-Family_sample.pdf 5. The Evolution of EyeQ - Mobileye, https://www.mobileye.com/technology/eyeq-chip/ 6. Towards Robust LiDAR-based Perception in Autonomous Driving: General Black-box Adversarial Sensor Attack and Countermeasures - USENIX, https://www.usenix.org/system/files/sec20_slides_sun.pdf 7. Data Driven Prediction Architecture for Autonomous Driving and its Application on Apollo Platform - arXiv, https://arxiv.org/pdf/2006.06715 8. China's 4-Stage Approach to End-to-end Autonomous Driving | by Shuai Chen | Medium, https://schen583.medium.com/chinas-4-stage-approach-to-end-to-end-autonomous-driving-b018b3c706ec 9. Tesla AI Day - The Gala of Autonomous Driving - MagicHub, https://magichub.com/tesla-ai-day-the-gala-of-autonomous-driving/ 10. AI & Robotics | Tesla, https://www.tesla.com/AI 11. XNet, XPENG's next-generation neural network-based perception architecture, https://www.xpeng.com/news/01840adee4c382358a5f2c9e246a0367 12. xpeng launches industry's first ai-powered in-car os, promoting ai-enabled smart driving experience, https://www.xpeng.com/news/018f968985698f616d3f2c9e8f720154 13. XPeng rolls out AI-OS with neural networks and 2K pure vision, https://electrek.co/2024/05/20/xpeng-rolls-out-ai-powered-os-neural-network-2k-pure-vision-ev/ 14. XPENG launches China's first mass-produced end-to-end large model, https://www.metal.com/en/newscontent/102764529 15. XPeng Motors Launches 720 Billion Parameter 'XPeng World' Base Model - AI NEWS, https://news.aibase.com/news/17129 16. What changes have occurred in Huawei ADS from 3.0 to 4.0? - EEWorld, https://en.eeworld.com.cn/news/qcdz/eic695593.html 17. Huawei Qiankun ADS 3.0 announced, brings intelligent driving upgrade - Car News China, https://carnewschina.com/2024/04/24/huawei-qiankun-ads-3-0-announced-brings-intelligent-driving-upgrade/ 18. End to End FSD : r/TeslaLounge - Reddit, https://www.reddit.com/r/TeslaLounge/comments/1fciidr/end_to_end_fsd/ 19. Tesla claim it would soon be releasing FSD model 10 times the parameter - Reddit, https://www.reddit.com/r/RealTesla/comments/1nebgfw/tesla_claim_it_would_soon_be_releasing_fsd_model/ 20. Tesla HW4 vs. HW3: How to Identify Your Tesla's Version? - Yeslak, https://www.yeslak.com/blogs/tesla-guide/tesla-hardware-4-vs-hardware-3 21. Planning-oriented Autonomous Driving - arXiv, https://arxiv.org/abs/2212.10156 22. Planning-Oriented Autonomous Driving - CVF Open Access, https://openaccess.thecvf.com/content/CVPR2023/papers/Hu_Planning-Oriented_Autonomous_Driving_CVPR_2023_paper.pdf 23. UniAD: Foundational Model for End-to-End Autonomous Driving - Medium, https://medium.com/axinc-ai/uniad-foundational-model-for-end-to-end-autonomous-driving-aa593496eb53 24. OpenDriveLab/UniAD: [CVPR 2023 Best Paper Award] Planning-oriented Autonomous Driving - GitHub, https://github.com/OpenDriveLab/UniAD 25. Huawei ADS 3.0 is the first end-to-end solution in China to open up the era of intelligent driving for all - EEWORLD, https://en.eeworld.com.cn/news/qcdz/eic679083.html 26. Huawei Intelligent Driving, the Behind-the-Scenes Winner of Auto Guangzhou - BitAuto, https://www.bitauto.com/global/news/100196169663.html 27. Transcript: Why Li Auto is revving up its smart driving efforts, chasing ..., https://kr-asia.com/transcript-why-li-auto-is-revving-up-its-smart-driving-efforts-chasing-tesla 28. End-to-End Autonomous Driving Research Report, 2025 - ResearchInChina, http://www.researchinchina.com/Htmls/Report/2025/77076.html 29. Li Auto advances in self-driving tech, aiming to close the gap with Tesla's FSD - KrASIA, https://kr-asia.com/li-auto-advances-in-self-driving-tech-aiming-to-close-the-gap-with-teslas-fsd 30. Analysis on Li Auto's Layout in Electrification, Connectivity, Intelligence and Sharing, 2024-2025 - Research and Markets, https://www.researchandmarkets.com/reports/6060292/analysis-on-li-autos-layout-in-electrification 31. Analysis on Li Auto's Layout in Electrification, Connectivity, Intelligence and Sharing, 2024-2025 - ResearchInChina, http://www.researchinchina.com/Htmls/Report/2025/77053.html 32. Scaling GAIA-1: 9-billion parameter generative world model for autonomous driving - Wayve, https://wayve.ai/thinking/scaling-gaia-1/ 33. Introducing GAIA-1: A Cutting-Edge Generative AI Model for Autonomy - Wayve, https://wayve.ai/thinking/introducing-gaia1/ 34. LINGO-1: Exploring Natural Language for Autonomous Driving - Wayve, https://wayve.ai/thinking/lingo-natural-language-autonomous-driving/ 35. Tesla's FSD Redefines Autonomous Driving - Veltyx, https://www.veltyx.de/en/post/tesla-s-fsd-redefines-autonomous-driving 36. New Insights for Scaling Laws in Autonomous Driving - Waymo, https://waymo.com/blog/2025/06/scaling-laws-in-autonomous-driving 37. Scaling Laws of Motion Forecasting and Planning - Waymo, https://waymo.com/research/scaling-laws-of-motion-forecasting-and-planning/ 38. Jetson Thor | Advanced AI for Physical Robotics - NVIDIA, https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-thor/ 39. NVIDIA Orin vs Thor: The Generational Leap in Edge AI Computing - twowin technology, https://twowintech.com/nvidia-orin-vs-thor-the-generational-leap-in-edge-ai-computing/