


多目标强化学习的范式演进与理论根基
在现代人工智能的演进过程中,强化学习(RL)已成为解决复杂决策问题的核心技术。然而,传统的单目标强化学习框架通常假设存在一个单一的标量奖励信号,这种简化在处理具有内在冲突特征的现实任务时日益显露出局限性1。为了应对速度与安全、效率与公平、性能与能耗之间的权衡,多目标强化学习(MORL)应运而生,并于2023至2025年间在算法理论与工业应用领域取得了突破性进展3。
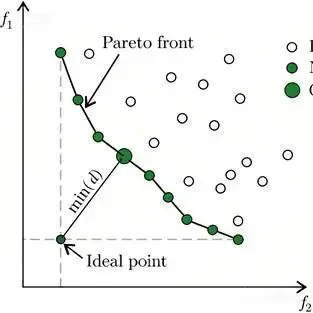
图一 帕累托前沿示意图
从MDP到MOMDP的数学跨越
多目标强化学习的理论基础建立在多目标马尔可夫决策过程(MOMDP)之上。与标准MDP不同,MOMDP的奖励函数  是一个 m维向量,其中每一维代表一个独立的优化目标 3。其累积折扣回报不再是一个数值,而是一个向量值函数:
是一个 m维向量,其中每一维代表一个独立的优化目标 3。其累积折扣回报不再是一个数值,而是一个向量值函数:
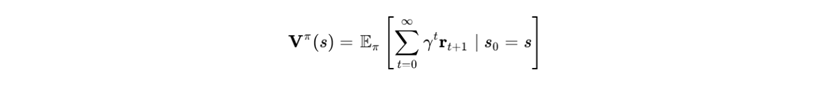
在这种设置下,决策逻辑从寻找单一最优解转向寻找帕累托最优集(Pareto Set)。一个策略pi被认为是帕累托最优的,当且仅当不存在另一个策略 pi2能够在不降低任何一个目标回报的前提下,至少提高其中一个目标的性能 2。
帕累托前沿的几何特征与复杂性
帕累托前沿(Pareto Front)在目标空间中形成的边界形状决定了算法的求解难度。传统的标量化方法(Scalarization)通过线性加权将多维奖励转化为标量,但这种方法在处理非凸(Concave)帕累托前沿时会丢失大量潜在的最优解7。2024年的研究指出,在机器人控制和安全关键型任务中,帕累托前沿往往呈现高度非凸性,这要求算法必须具备探索非凸区域的能力7。
梯度驱动的多目标深度学习前沿
随着深度神经网络在强化学习中的普及,基于梯度的多目标优化(MOO)已成为当前的研究热点。这种方法旨在直接在参数空间中协调多个冲突的梯度更新方向1。
梯度冲突与操控策略
在深度强化学习中,不同目标的梯度方向往往存在冲突,导致模型更新过程中的振荡或收敛到次优解 1。梯度自适应策略优化(GAPO)等前沿方法通过动态缩放各目标的梯度模长,寻找一个能够同时改善所有目标的更新方向12。这种机制利用了多梯度下降算法(MGDA)的原理,确保模型在不牺牲任何关键目标的前提下稳步迈向帕累托前沿2。
帕累托平稳性与收敛保证
2025年的理论研究进一步定义了帕累托平稳点(Pareto Stationary Point)。当所有目标的加权梯度和为零且权重系数非负时,认为模型达到了帕累托平稳状态2。研究表明,引入克罗内克积(Kronecker product)或拉格朗日乘子法可以增强大规模模型在多目标环境下的训练稳定性,特别是在参数规模达到数十亿的语言模型中 10。
帕累托集合学习与超网络架构
为了在推理阶段实现灵活的偏好调节,研究者提出了帕累托集合学习(Pareto Set Learning, PSL)框架。这一技术的核心是使用超网络(Hypernetwork)来建模整个帕累托前沿,而非仅仅寻找单一的权衡点3。
超网络的生成机制
PSL-MORL方法通过训练一个高阶参数生成器,输入用户指定的偏好权重,直接输出对应策略网络的参数3。这种架构实现了“一次训练,随处适配”的能力:
- 连续映射能力:超网络能够学习从偏好空间到参数空间的连续流形,从而生成无限个潜在的帕累托最优策略 3。
- 计算效率优化:相比于传统的多策略MORL(需要为每个偏好独立训练网络),PSL方法显著降低了存储和训练成本 3。
- 参数融合稳定性:通过引入参数融合系数,超网络生成的参数在偏好扰动下表现出更强的鲁棒性,避免了决策行为的剧烈波动 3。
PSL 方法特性 | 技术原理 | 关键优势 |
偏好条件化 (Preference-Conditioned) | 以偏好向量作为输入门控 | 实现推理时的实时策略切换 3。 |
任务分解 (Decomposition) | 将MOO分解为多个子任务 | 提升复杂任务下的覆盖率 3。 |
理论最优性保证 | 基于拉德马赫复杂度 (Rademacher Complexity) 的泛化界限 | 确保生成的策略具有帕累托一致性 3。 |
离线多目标强化学习与扩散模型
由于在线数据采集在很多现实领域(如医疗、自动驾驶)存在高昂成本和风险,离线多目标强化学习(Offline MORL)正成为研究的核心前沿 17。其核心挑战在于处理数据集的分布偏移(Distributional Shift)以及偏好不一致的轨迹 20。
扩散模型作为帕累托规划器
扩散模型(Diffusion Models)在生成式AI领域的成功被迅速引入到MORL中。DiffMORL算法通过将决策轨迹建模为扩散过程,利用强表达能力的扩散先验来规划符合目标偏好的行为18。
- 离线数据混叠 (Mixup):为了增强泛化能力,DiffMORL在离线数据集上执行数据混叠,有效缓解了模型对训练样本的盲目记忆,使其在处理分布外(OOD)偏好时依然能生成高质量轨迹 18。
- 偏好条件规划:扩散模型能够以偏好向量为导向,在隐空间中搜索满足多目标约束的全局最优路径,这在解决长程决策问题时表现优于传统的Q学习方法 18。
行为偏好近似与正则化
在离线场景下,由于专家偏好往往是隐性的,研究者开发了行为偏好近似技术。通过反向估计历史轨迹的权重分布,算法可以过滤掉偏好冲突的噪声数据21。同时,正则化权重自适应技术(Regularization Weight Adaptation)被用于在部署阶段动态调整保守性程度,平衡了对数据的忠实度与目标的达成率 19。
大语言模型中的多目标对齐技术
对齐大语言模型(LLM)与人类价值是MORL目前最具影响力的应用方向。传统的基于人类反馈的强化学习(RLHF)通常依赖单一标量奖励,这往往导致模型在帮助性(Helpfulness)与无害性(Harmlessness)之间产生“奖励偏离”或行为僵化 4。
从标量RLHF到多目标对齐(MOA)
2025年的研究趋势表明,将对齐问题建模为多目标优化问题可以获得更精细的控制14。
- PAMA算法:针对大模型参数规模巨大的特点,PAMA提出了一种基于凸优化的闭式解法,避开了昂贵的二阶导数计算。它将多维奖励信号线性化,并在每一步更新中自动寻找帕累托改进方向 14。
- 推理时对齐 (Test-time Alignment):PARM等技术允许模型在冻结参数的情况下,通过轻量级的偏好感知奖励模型(ARM)在解码阶段引导生成。这种“弱对强”的引导机制使得在计算资源受限的情况下也能实现复杂的多目标权衡 24。
具有可验证奖励的强化学习 (RLVR)
随着推理模型(如DeepSeek-R1)的发展,多目标框架开始整合可验证的回报(Verifiable Rewards) 22。在解决数学或编程任务时,模型不仅要优化正确性,还要优化推理路径的简洁性与逻辑的一致性。Group Relative Policy Optimization (GRPO) 算法通过在同批次生成的多个样本间建立相对性能度量,显著提升了模型在多冲突约束下的学习效率22。
对齐范式 | 核心目标 | 代表技术 |
标量化 RLHF | 最大化加权单一奖励 | PPO, DPO 14。 |
多目标 GAPO | 平衡冲突的梯度更新 | 梯度自适应缩放 12。 |
混合 DPO | 结合显式与隐式奖励信号 | Hybrid Reward Model 23。 |
自动化对齐 (RLAIF) | 使用AI反馈优化多样性目标 | Curriculum-RLAIF 22。 |
安全约束与稳健的多目标决策
安全是强化学习在现实世界部署的先决条件。约束强化学习(CRL)通常将安全性视为硬性约束(Hard Constraint),而MORL则将其视为一种特殊的优化目标,这种视角的融合催生了受限多目标强化学习(CMORL) 11。
多方协商与共识帕累托
2025年提出的MPPN-MORL框架引入了多方协商机制,将安全性视为外部监管方的利益诉求。通过设定协商阈值,算法在性能帕累托前沿上寻找满足所有安全协议的“共识解” 28。这种方法避免了传统拉格朗日乘子法在处理严格约束时的不稳定性,能够灵活适应动态变化的安全标准28。
极端价值理论 (EVO) 与黑天鹅防范
针对传统算法在应对稀有但致命的错误(如自动驾驶中的碰撞)时表现不足的问题,极端价值策略优化(EVO)算法应运而生 29。
- 分位数优化:EVO不再关注平均成本,而是利用极端价值理论(EVT)建模成本分布的尾部 29。
- 零违规保证:通过极值分布(GPD)建模,EVO能够提供理论上的上限约束,确保在特定分位数水平下的“零违规”表现,极大地增强了强化学习在金融、医疗等高风险领域的部署可靠性 29。
序列建模与决策Transformer的融合
将强化学习视为序列建模任务的范式转变(如Decision Transformer)在多目标领域也得到了深化30。
多目标决策Transformer (MODT)
MODT架构将传统的标量“待达回报”(Return-to-Go, RTG)扩展为向量形式。
- MocDT (可控决策Transformer):该模型引入了未来条件策略(Future-conditioned Strategy),将多目标优先级视为一种“提示词”(Prompt)。在推理时,用户只需输入目标的比重,模型即可自回归地生成符合要求的动作序列 33。
- 双层Transformer结构:MODT4R通过一个“用户状态Transformer”捕获长期偏好,结合一个“多目标Transformer”在 trajectory 层面平衡推荐的准确性、多样性与新颖性 31。这种设计解决了传统RL在处理高维稀疏动作空间时的预测偏差积累问题 31。
评价指标、基准环境与科研生态
MORL研究的爆发离不开标准化的评估体系与开源社区的贡献 34。
关键评估指标
评估帕累托前沿质量的指标已从单一的累积回报转向分布特征度量 3:
- 超体积 (Hypervolume, HV):计算被帕累托集合覆盖的目标空间体积。HV越大,说明算法找到的权衡方案越优且越全面 16。
- 稀疏度 (Sparsity):反映帕累托前沿上解的均匀分布程度。低稀疏度意味着决策者在不同区域都能获得连续的权衡选项 3。
- 偏好受控度:衡量生成的轨迹与输入偏好向量之间的余弦相似度,特别是在受限偏好区域内的覆盖能力 37。
基准测试环境
基准套件 | 环境特性 | 典型任务 |
MO-Gymnasium | 标准化API,支持离散/连续空间 | 深海寻宝 (DST), 月球着陆器, MO-MuJoCo 34。 |
D4MORL | 专门针对离线MORL的数据集 | 包含180万条带偏好标注的轨迹 18。 |
MORL-Generalization | 评估环境变体下的鲁棒性 | 具有丰富环境随机性的控制任务 6。 |
PowerGridworld | 专注于能源系统的多智能体环境 | 电网平衡与可再生能源集成 39。 |
行业应用与工程实践案例
多目标强化学习已走出实验室,在复杂的物理系统与工业场景中展现出核心价值 8。
智能电网与综合能源调度
在现代智能电网管理中,运营商必须同时优化用电成本、用电舒适度和电网波动稳定性 15。
- 微电网群协同:通过偏好驱动的MORL(PMORL),系统能够为消费者层、独立系统运营商层和电力网络层分别提供符合其利益诉求的帕累托解集 42。
- 需求响应 (DR):集成了拉格朗日约束处理的PPO算法在合成电网测试中实现了23.4%的成本降低,同时将用户不适指数控制在0.15以下 15。
雾计算与柔性制造
在雾网络任务调度中,NF-MORL框架结合了模糊逻辑与多目标actor-critic代理,有效应对了网络延迟与设备能耗之间的剧烈冲突 43。实验显示,该方法将任务完成时间(Makespan)缩短了35%,同时提升了30%的能效 43。在柔性制造领域,基于图神经网络的多目标代理能够实时调整生产节拍,在应对设备故障等随机事件时表现出比传统元启发式算法更快的响应速度41。
总结与未来研究趋势
多目标强化学习的研究正处于一个向通用性、透明性和安全性深度融合的阶段 4。
可解释的多目标决策 (XMORL)
由于多目标决策涉及复杂的利益取舍,未来的研究正致力于开发XMORL方法。这包括建立策略的可视化摘要、基于反事实推理的决策解释,以及揭示神经网络参数与特定目标贡献度之间的因果联系9。
基础模型与多目标智能体
将LLM或多模态大模型作为决策中枢,利用其强大的先验推理能力来辅助多目标探索是另一大趋势22。这包括利用视觉语言模型(VLM)从原始图像中推断环境动力学与安全目标,从而在稀疏奖励环境下实现更高效的采样46。
总体而言,2023-2025年的前沿研究已清晰地表明:强化学习的未来不再是单一数值的追逐,而是在多维价值流形上的精确航行。这种转变将使AI能够更好地适应充满矛盾与多样性的真实世界 1。
引用的著作
- [1]Gradient-Based Multi-Objective Deep Learning: Algorithms, Theories, Applications, and Beyond - arXiv, 访问时间为 一月 31, 2026, https://arxiv.org/pdf/2501.10945
- [2]Gradient-Based Multi-Objective Deep Learning: Algorithms, Theories, Applications, and Beyond - arXiv, 访问时间为 一月 31, 2026, https://arxiv.org/html/2501.10945v1
- [3]Pareto Set Learning for Multi-Objective Reinforcement Learning - arXiv, 访问时间为 一月 31, 2026, https://arxiv.org/html/2501.06773v1
- [3][2509.21613] Multi-Objective Reinforcement Learning for Large Language Model Optimization: Visionary Perspective - arXiv, 访问时间为 一月 31, 2026, https://arxiv.org/abs/2509.21613
- [4]Gradient-Based Multi-Objective Deep Learning: Algorithms, Theories, Applications, and Beyond - arXiv, 访问时间为 一月 31, 2026, https://arxiv.org/html/2501.10945v3
- [5]ON GENERALIZATION ACROSS ENVIRONMENTS IN MULTI-OBJECTIVE REINFORCEMENT LEARNING - ICLR Proceedings, 访问时间为 一月 31, 2026, https://proceedings.iclr.cc/paper_files/paper/2025/file/c97d5a0a332ac6a8e4836de20462c576-Paper-Conference.pdf
- [6]Divide and Conquer: Provably Unveiling the Pareto Front with Multi-Objective Reinforcement Learning - arXiv, 访问时间为 一月 31, 2026, https://arxiv.org/html/2402.07182v2
- [7]MORSE: Multi-Objective Reinforcement Learning via Strategy Evolution for Supply Chain Optimization - arXiv, 访问时间为 一月 31, 2026, https://arxiv.org/pdf/2509.06490
- [8]Explainable Multi-Objective Reinforcement Learning: challenges and considerations - MODeM 2025, 访问时间为 一月 31, 2026, https://modem2025.vub.ac.be/papers/MODeM_2025_paper_2.pdf
- [9]Safe and Balanced: A Framework for Constrained Multi-Objective Reinforcement Learning - IEEE Xplore, 访问时间为 一月 31, 2026, https://ieeexplore.ieee.org/iel8/34/10958761/10840326.pdf
- [10]A Constrained Multi-Objective Reinforcement Learning Framework, 访问时间为 一月 31, 2026, https://proceedings.mlr.press/v164/huang22a/huang22a.pdf
- Gradient-Adaptive Policy Optimization: Towards Multi-Objective Alignment of Large Language Models - ACL Anthology, 访问时间为 一月 31, 2026, https://aclanthology.org/2025.acl-long.549/
- [11][2507.01915] Gradient-Adaptive Policy Optimization: Towards Multi-Objective Alignment of Large Language Models - arXiv, 访问时间为 一月 31, 2026, https://arxiv.org/abs/2507.01915
- [12]Pareto Multi-Objective Alignment for Language Models - arXiv, 访问时间为 一月 31, 2026, https://arxiv.org/html/2508.07768v1
- [13]AI-Powered Demand Response Optimization in Smart Grids: A Multi-Objective Reinforcement Learning Framework - International Journal of Scientific Research and Engineering Development, 访问时间为 一月 31, 2026, https://ijsred.com/volume8/issue5/IJSRED-V8I5P277.pdf
- [14]EFFICIENT DISCOVERY OF PARETO FRONT FOR MULTI- OBJECTIVE REINFORCEMENT LEARNING - ICLR Proceedings, 访问时间为 一月 31, 2026, https://proceedings.iclr.cc/paper_files/paper/2025/file/adb77ecc8ba1c2d3135c86a46b8f2496-Paper-Conference.pdf
- [15]Offline Multi-Agent Reinforcement Learning - Emergent Mind, 访问时间为 一月 31, 2026, https://www.emergentmind.com/topics/offline-multi-agent-reinforcement-learning-marl
- [16]Boosting Offline Multi-Objective Reinforcement Learning via ..., 访问时间为 一月 31, 2026, https://openreview.net/forum?id=XCUTFbC3Rh
- RPTU researchers achieve exceptional publication success in 2025 - KI-Allianz RLP, 访问时间为 一月 31, 2026, https://www.ki-allianz-rlp.de/en/news/rptu-researchers-achieve-exceptional-publication-success-in-2025-10112025/
- [17]Offline Multi-Agent Reinforcement Learning via In-Sample Sequential Policy Optimization, 访问时间为 一月 31, 2026, https://ojs.aaai.org/index.php/AAAI/article/view/34099/36254
- [18][2401.02244] Policy-regularized Offline Multi-objective Reinforcement Learning - arXiv, 访问时间为 一月 31, 2026, https://arxiv.org/abs/2401.02244
- AI 101: The State of Reinforcement Learning in 2025 - Turing Post, 访问时间为 一月 31, 2026, https://www.turingpost.com/p/stateofrl2025
- [19]Aligning Language Models with Multi-Objective Reinforcement Learning - Extended Abstract - Stanford University, 访问时间为 一月 31, 2026, https://cs224r.stanford.edu/projects/pdfs/CS_224R_Final_Report_final.pdf
- [20]ICML Poster PARM: Multi-Objective Test-Time Alignment via Preference-Aware Autoregressive Reward Model, 访问时间为 一月 31, 2026, https://icml.cc/virtual/2025/poster/43455
- [21]Deep Reinforcement Learning in the Era of Foundation Models: A Survey - MDPI, 访问时间为 一月 31, 2026, https://www.mdpi.com/2073-431X/15/1/40
- [22]A Survey of Constraint Formulations in Safe Reinforcement Learning - IJCAI, 访问时间为 一月 31, 2026, https://www.ijcai.org/proceedings/2024/0913.pdf
- [23]A Survey of Safe Reinforcement Learning and Constrained MDPs: A Technical Survey on Single-Agent and Multi-Agent Safety - arXiv, 访问时间为 一月 31, 2026, https://arxiv.org/html/2505.17342v1
- [24]SAFE MULTI-OBJECTIVE REINFORCEMENT LEARN- ING VIA MULTI-PARTY PARETO NEGOTIATION - OpenReview, 访问时间为 一月 31, 2026, https://openreview.net/pdf/8bc82f4dbe0a64d60205e97a4dc8d99399fe7511.pdf
- [25]ICML Poster Extreme Value Policy Optimization for Safe Reinforcement Learning, 访问时间为 一月 31, 2026, https://icml.cc/virtual/2025/poster/46527
- ICLR Poster Scaling Pareto-Efficient Decision Making via Offline Multi-Objective RL, 访问时间为 一月 31, 2026, https://iclr.cc/virtual/2023/poster/11257
- [26]Beyond Accuracy: Decision Transformers for Reward-Driven Multi-Objective Recommendations - IEEE Computer Society, 访问时间为 一月 31, 2026, https://www.computer.org/csdl/journal/tk/2025/09/11072516/28bEUQ2YjF6
- [27]Beyond Accuracy: Decision Transformers for Reward-Driven Multi-Objective Recommendations - IEEE Xplore, 访问时间为 一月 31, 2026, https://ieeexplore.ieee.org/iel8/69/11119623/11072516.pdf
- [28]Future-Conditioned Recommendations with Multi-Objective Controllable Decision Transformer - arXiv, 访问时间为 一月 31, 2026, https://arxiv.org/html/2501.07212v1
- [29]mo-gymnasium - PyPI, 访问时间为 一月 31, 2026, https://pypi.org/project/mo-gymnasium/
- [30]MO-Gym: A Library of Multi-Objective Reinforcement Learning Environments - UMass CICS, 访问时间为 一月 31, 2026, https://people.cs.umass.edu/~bsilva/papers/MO-Gym_BNAIC_2022.pdf
- [31]Multi-Policy Pareto Front Tracking Based Online and Offline Multi-Objective Reinforcement Learning | Request PDF - ResearchGate, 访问时间为 一月 31, 2026, https://www.researchgate.net/publication/394293317_Multi-Policy_Pareto_Front_Tracking_Based_Online_and_Offline_Multi-Objective_Reinforcement_Learning
- [32]ICML Poster Preference Controllable Reinforcement Learning with Advanced Multi-Objective Optimization, 访问时间为 一月 31, 2026, https://icml.cc/virtual/2025/poster/46501
- [33]MORL Baselines - MO-Gymnasium Documentation, 访问时间为 一月 31, 2026, https://mo-gymnasium.farama.org/examples/morl_baselines/
- [34]Reinforcement Learning Research | Computational Science | NLR - NREL, 访问时间为 一月 31, 2026, https://www.nrel.gov/computational-science/reinforcement-learning
- [35](PDF) Case Studies of ML Implementation in Smart Grid Projects - ResearchGate, 访问时间为 一月 31, 2026, https://www.researchgate.net/publication/391527023_Case_Studies_of_ML_Implementation_in_Smart_Grid_Projects
- [36]Reinforcement Learning Agent for Multi-Objective Online Process Parameter Optimization of Manufacturing Processes - MDPI, 访问时间为 一月 31, 2026, https://www.mdpi.com/2076-3417/15/13/7279
- [37]Preference based multi-objective reinforcement learning for multi-microgrid system optimization problem in smart grid - University of Exeter - Figshare, 访问时间为 一月 31, 2026, https://ore.exeter.ac.uk/articles/journal_contribution/Preference_based_multi-objective_reinforcement_learning_for_multi-microgrid_system_optimization_problem_in_smart_grid/29784323
- [38]NF-MORL: a neuro-fuzzy multi-objective reinforcement learning framework for task scheduling in fog computing environments - PMC - PubMed Central, 访问时间为 一月 31, 2026, https://pmc.ncbi.nlm.nih.gov/articles/PMC12820232/
- [39]Smart Grid for Industry Using Multi-Agent Reinforcement Learning - MDPI, 访问时间为 一月 31, 2026, https://www.mdpi.com/2076-3417/10/19/6900
- [40]Explainable Multi-Objective Reinforcement Learning: challenges and considerations, 访问时间为 一月 31, 2026, https://www.researchgate.net/publication/395834558_Explainable_Multi-Objective_Reinforcement_Learning_challenges_and_considerations
- [41]FOUNDATION MODELS FOR ENHANCED EXPLORATION IN REINFORCEMENT LEARNING - OpenReview, 访问时间为 一月 31, 2026, https://openreview.net/pdf/7baa7a54b869f7dc3da68f6d1ec30ae1c4abc33d.pdf
知识共享许可协议: 署名(BY):您可以复制、发行、展览、表演、放映、广播或通过信息网络传播本作品;作者保留署名权。 非商业性使用(NC):您可以自由复制、散布、展示及演出本作品;您不得为商业目的而使用本作品。相同方式共享(SA):您可以自由复制、散布、展示及演出本作品;若您改变、转变或更改本作品,仅在遵守与本作品相同的许可条款下,您才能散布由本作品产生的派生作品。 无害化申明(Disclaimer of Warranty):在此基础上,不提供任何形式的明示、暗示或法定保证,包括但不限于对于内容没有认知局限性、偏见和缺陷、适销、适合特定用途或不侵权的保证。有关内容的质量和效用的全部风险由您承担。如果任何涵盖内容在任何方面被证明存在缺陷、认知局限性、偏见,您(而非任何贡献者)承担任何必要服务、更正的费用。本免责声明构成本许可的重要组成部分。除非根据本免责声明,否则本许可不得授权。 可靠性限制和免责条款(Limitation of Liability):在任何情况下和任何法律理论下,无论是侵权(包括疏忽)、合同还是其他行为,任何贡献者或按上述许可分发涵盖内容的任何人,对您的任何性质的任何直接、间接、特殊、附带或后果性损害不负有任何责任,包括但不限于利润损失、商誉损失、停工、故障,及所有其他商业损害或损失,即使该方已被告知此类损害的可能性。在适用此类限制声明的司法管辖范围内,不承担任何相关疏忽而导致的死亡或人身伤害的责任。某些司法管辖区不允许排除或限制附带或间接损害,因此此免责条款和可靠性限制可能不适用于您。 诉讼条款(Litigation):与本许可有关的任何诉讼只能在被告保持其主要营业地点的司法管辖区的法院提起,此类诉讼应受该司法管辖区的法律管辖,而无需参考其法律冲突规定。本节中的任何内容均不得阻止一方提出交叉索赔或反索赔的能力。 其他(Miscellaneous):本许可代表有关其标的物的完整协议。如果本许可的任何条款被认定为不可执行,则此类条款应仅在必要的范围内进行改变以使其可执行。任何被可能解释为对贡献者不利的法律或法规所  rch
rch