


昨天有网友私我,对文章中的行业热力图感兴趣,今天贴代码出来了。请各道友指正。
行业热度计算的多种维度
行业热度分析主流的热度计算方法主要有以下几种:
·资金流向法:以行业成交额 / 成交量占全市场的比例为核心,比如某行业当日成交额占全市场 15%,代表资金高度聚焦,这是券商研报中最常用的方法,核心反映 “钱往哪去”;
·涨跌幅加权法:以行业内个股的流通市值为权重,计算行业整体涨跌幅,涨幅越高则热度越高,行情软件的“行业涨幅榜” 本质就是这种逻辑;
· 情绪指标法:聚焦行业内涨停个股数量、连板数、换手率等情绪维度,比如某行业当日 10 只个股涨停,代表市场情绪高度认可;或者基于新闻舆情、搜索指数等另类数据,量化市场情绪对行业的影响。
· 技术指标法:综合使用RSI、MACD、布林带等技术指标,判断行业超买超卖状态。本文代码采用的就是这一思路的变体,通过个股价格相对均线的偏离度,计算行业内“强势个股占比”,也就是本文代码采用的核心逻辑,聚焦 “个股相对自身趋势的强弱”。
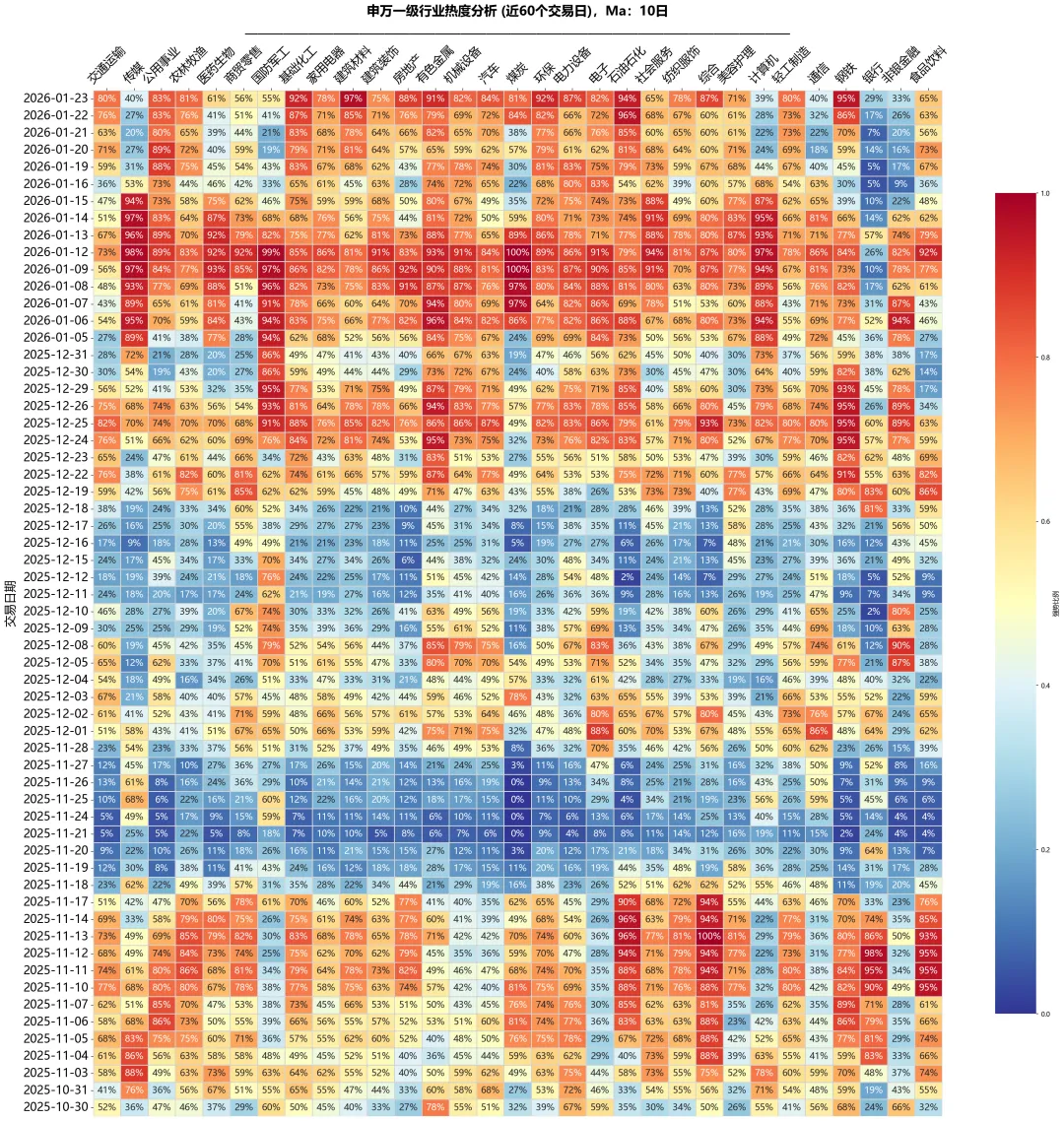
热力图模型:原理与实现步骤
第一步:读取全市场股票数据,采用后复权方式统一价格基准,确保历史可比性。个股需要的字段不多,只有:['股票代码', '交易日期', '新版申万一级行业名称', '收盘价', '前收盘价', '开盘价', '最高价', '股票名称', '最低价'],还是比较容易抓取的。
第二步:计算每只股票的N日均线乖离,均线自定,可以5日,10日,20日。
第三步:统计每个行业中乖离率为正的股票比例(多少个股在均线之上)
第四步:找出每个行业中表现最强势的股票
第五步:用热力图展示行业热度变化趋势
结语
这分析代码呢,我觉得需要的数据量少,逻辑简单,通俗易懂,可以整体回溯,也能满足个人散户的板块轮动分析简单需求。当然如果不用均线乖离,换个指标也可扩展、可验证、可改进。用“一级行业”因为它只有30来个,二级类目就太多来,整体展示,不好直接观察(可以自己去试下)。你也可以用概念等,自己拓展,欢迎来探讨。
最后附上代码:
import pandas as pdimport numpy as npimport osimport globimport matplotlib.pyplot as pltimport seaborn as snsfrom datetime import datetime, timedeltafrom tqdm import tqdmfrom concurrent.futures import ProcessPoolExecutor, as_completedimport multiprocessingimport warningswarnings.filterwarnings('ignore')plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.rcParams['axes.unicode_minus'] = Falseclass Config:DATA_PATH = r"E:\data\stock-data"OUTPUT_DIR = 'D:/data/temp/'DAYS = 60#近60日内#MA_LINE = 10#均线10日#PARALLEL_WORKERS = min(4, max(1, multiprocessing.cpu_count() - 1))#并行核数BATCH_SIZE = 2000 # 多批次,避免内存溢出config = Config()os.makedirs(config.OUTPUT_DIR, exist_ok=True)def cal_fuquan_price(df, fuquan_type='后复权', method=None):fq_factor = (df['收盘价'] / df['前收盘价']).cumprod()if fuquan_type == '后复权':fq_close = fq_factor * (df.iloc[0]['收盘价'] / fq_factor.iloc[0])elif fuquan_type == '前复权':fq_close = fq_factor * (df.iloc[-1]['收盘价'] / fq_factor.iloc[-1])else:raise ValueError(f'计算复权价时,出现未知的复权类型:{fuquan_type}')fq_open = df['开盘价'] / df['收盘价'] * fq_closefq_high = df['最高价'] / df['收盘价'] * fq_closefq_low = df['最低价'] / df['收盘价'] * fq_closedf = df.assign(复权因子=fq_factor,收盘价_复权=fq_close,开盘价_复权=fq_open,最高价_复权=fq_high,最低价_复权=fq_low,)if method and method != '开盘':df[f'{method}_复权'] = df[method] / df['收盘价'] * fq_closereturn dfdef process_single_file(file_path):try:df = pd.read_csv(file_path,encoding='gbk',skiprows=1,usecols=['股票代码', '交易日期', '新版申万一级行业名称', '收盘价','前收盘价', '开盘价', '最高价', '股票名称', '最低价'],dtype={'股票代码': str,'新版申万一级行业名称': 'category','股票名称': str})if len(df) <= 1:return Nonedf = df[df['新版申万一级行业名称'].notna()].copy()if len(df) <= 1:return Nonedf = df.sort_values('交易日期')df = cal_fuquan_price(df, fuquan_type="后复权")df['ma'] = df['收盘价_复权'].rolling(window=config.MA_LINE, min_periods=1).mean()df['bias_line'] = (df['收盘价_复权'] - df['ma']) / df['ma'] * 100return df[['股票代码', '交易日期', '新版申万一级行业名称', '股票名称', 'bias_line']]except Exception as e:print(f"Error reading {os.path.basename(file_path)}: {str(e)}")return Nonedef process_files_parallel(file_list):dfs = []total_batches = (len(file_list) + config.BATCH_SIZE - 1) // config.BATCH_SIZEfor batch_num in range(total_batches):start_idx = batch_num * config.BATCH_SIZEend_idx = min((batch_num + 1) * config.BATCH_SIZE, len(file_list))batch_files = file_list[start_idx:end_idx]print(f"处理批次 {batch_num + 1}/{total_batches} ({len(batch_files)} 个文件)")if len(batch_files) < config.PARALLEL_WORKERS * 2:for file in tqdm(batch_files, desc=f"批次 {batch_num + 1}"):result = process_single_file(file)if result is not None:dfs.append(result)else:with ProcessPoolExecutor(max_workers=config.PARALLEL_WORKERS) as executor:futures = {executor.submit(process_single_file, file): file for file in batch_files}for future in tqdm(as_completed(futures), total=len(batch_files),desc=f"批次 {batch_num + 1}"):result = future.result()if result is not None:dfs.append(result)return dfsdef save_optimized_figure(fig, filepath, dpi=150):try:fig.savefig(filepath, bbox_inches='tight', dpi=dpi)except TypeError:fig.savefig(filepath, bbox_inches='tight', dpi=dpi)def main():print("=" * 60)print("股票行业热度分析工具")print(f"分析天数: {config.DAYS}天,MA周期: {config.MA_LINE}")print("=" * 60)all_files = glob.glob(os.path.join(config.DATA_PATH, "*.csv"))print(f"找到 {len(all_files)} 个股票数据文件")if not all_files:raise ValueError("未找到数据文件")print("开始处理股票文件...")dfs = process_files_parallel(all_files)if not dfs:raise ValueError("未读取到任何有效数据")print(f"成功处理 {len(dfs)} 个股票文件")print("合并所有数据...")all_data = pd.concat(dfs, ignore_index=True)del dfsprint("数据合并完成,开始分析...")print(f"总数据量: {len(all_data):,} 行")print(f"数据时间范围: {all_data['交易日期'].min()} 到 {all_data['交易日期'].max()}")print("转换日期格式并排序...")all_data['交易日期'] = pd.to_datetime(all_data['交易日期'])all_data = all_data.sort_values('交易日期').reset_index(drop=True)print(f"\n筛选最近{config.DAYS}个交易日...")if len(all_data) == 0:raise ValueError("没有有效的数据可供分析")unique_dates = all_data['交易日期'].unique()if len(unique_dates) == 0:raise ValueError("没有找到任何交易日数据")unique_dates_series = pd.Series(unique_dates).sort_values().reset_index(drop=True)if len(unique_dates_series) < config.DAYS:print(f"警告: 只有{len(unique_dates_series)}个交易日,少于设定的{config.DAYS}天")selected_dates = unique_dates_series[-config.DAYS:] if len(unique_dates_series) > config.DAYS else unique_dates_serieselse:selected_dates = unique_dates_series[-config.DAYS:]if len(selected_dates) == 0:raise ValueError(f"筛选后没有找到任何最近{config.DAYS}个交易日的数据")selected_dates = pd.to_datetime(selected_dates)try:if len(selected_dates) > 0:print(f"选择的日期范围: {selected_dates.iloc[0].strftime('%Y-%m-%d')} 到 {selected_dates.iloc[-1].strftime('%Y-%m-%d')}")else:print("警告: 选择的日期范围为空")except Exception as e:print(f"打印日期范围时出错: {e}")date_mask = all_data['交易日期'].isin(selected_dates)filtered_data = all_data[date_mask].copy()del all_dataprint(f"筛选后数据量: {len(filtered_data):,} 行")if len(filtered_data) == 0:raise ValueError("筛选后没有数据,请检查日期范围")print(f"涉及行业数量: {filtered_data['新版申万一级行业名称'].nunique()} 个")print("\n计算每日各行业比例...")grouped = filtered_data.groupby(['交易日期', '新版申万一级行业名称'])dates = []industries = []ratios = []top_codes = []top_names = []group_keys = list(grouped.groups.keys())for date, industry in tqdm(group_keys, desc="计算行业统计"):group = grouped.get_group((date, industry))total_count = len(group)if total_count == 0:continuepositive_count = (group['bias_line'] > 0).sum()ratio = positive_count / total_counttop_idx = group['bias_line'].idxmax()top_stock = group.loc[top_idx]dates.append(date)industries.append(industry)ratios.append(ratio)top_codes.append(top_stock['股票代码'])top_names.append(top_stock['股票名称'])if len(dates) == 0:raise ValueError("没有计算出任何行业数据,请检查输入数据")result_df = pd.DataFrame({'日期': dates,'行业': industries,'比例': ratios,'强势股票代码': top_codes,'强势股票名称': top_names})print("\n" + "=" * 60)print("最近交易日行业热度TOP5及强势股票")print("=" * 60)last_trade_date = selected_dates.iloc[-1]last_date_data = result_df[result_df['日期'] == last_trade_date]if len(last_date_data) == 0:print(f"警告: 最近交易日 {last_trade_date.strftime('%Y-%m-%d')} 没有行业数据")if len(result_df) > 0:last_trade_date = result_df['日期'].max()last_date_data = result_df[result_df['日期'] == last_trade_date]print(f"使用最后一个有数据的日期: {last_trade_date.strftime('%Y-%m-%d')}")if len(last_date_data) > 0:top_industries = last_date_data.nlargest(min(5, len(last_date_data)), '比例')print(f"交易日: {last_trade_date.strftime('%Y-%m-%d')}")print(f"{'排名':<6}{'行业':<15}{'热度比例':<12}{'强势股票代码':<15}{'强势股票名称':<20}")print("-" * 70)for i, (_, row) in enumerate(top_industries.iterrows(), 1):print(f"{i:<8}{row['行业']:<15}{row['比例']:<12.2%} "f"{row['强势股票代码']:<15}{row['强势股票名称']:<20}")else:print("没有最近交易日的行业数据可显示")print("\n生成热力图...")try:heatmap_data = result_df.pivot_table(index='日期',columns='行业',values='比例')if not isinstance(heatmap_data.index, pd.DatetimeIndex):heatmap_data.index = pd.to_datetime(heatmap_data.index)heatmap_data.index = heatmap_data.index.strftime('%Y-%m-%d')heatmap_data = heatmap_data.iloc[::-1]fig_width = max(12, min(30, len(heatmap_data.columns) * 0.8))fig_height = max(10, min(40, len(heatmap_data) * 0.4))fig, ax = plt.subplots(figsize=(fig_width, fig_height))sns.heatmap(heatmap_data,cmap='RdYlBu_r',annot=True,fmt=".0%",annot_kws={'size': 14},linewidths=0.5,linecolor='lightgray',ax=ax,cbar_kws={'shrink': 0.8, 'label': '强势比例'})ax.set_title(f'申万一级行业热度分析 (近{config.DAYS}个交易日),Ma:{config.MA_LINE}日', fontsize=20, pad=20, weight='bold')ax.set_xlabel('———————————————————————————————————————————', fontsize=18, labelpad=10)ax.set_ylabel('交易日期', fontsize=18, labelpad=10)ax.xaxis.tick_top()ax.xaxis.set_label_position('top')plt.xticks(rotation=45, ha='center', fontsize=18)plt.yticks(fontsize=18)plt.tight_layout()timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")heatmap_path = os.path.join(config.OUTPUT_DIR, f"industry_heatmap_{timestamp}.png")save_optimized_figure(fig, heatmap_path, dpi=150)plt.close(fig)print(f"✓ 热力图已保存至: {heatmap_path}")except Exception as e:print(f"热力图生成失败: {str(e)}")import tracebacktraceback.print_exc()heatmap_path = Nonecsv_path = os.path.join(config.OUTPUT_DIR, f"industry_data_{timestamp}.csv")result_df.to_csv(csv_path, index=False, encoding='utf-8_sig')print(f"✓ 统计结果已保存至: {csv_path}")import gcgc.collect()print("\n" + "=" * 60)print("处理完成!")print("=" * 60)return result_df, heatmap_pathif __name__ == "__main__":import timestart_time = time.time()try:result_df, heatmap_path = main()print(f"\n统计摘要:")print(f"- 总记录数: {len(result_df):,}")print(f"- 行业数量: {result_df['行业'].nunique()}")print(f"- 日期数量: {result_df['日期'].nunique()}")if len(result_df) > 0:print(f"- 平均强势比例: {result_df['比例'].mean():.2%}")else:print("- 平均强势比例: 无数据")except Exception as e:print(f"\n❌ 程序执行出错: {str(e)}")import tracebacktraceback.print_exc()end_time = time.time()print(f"\n总运行时间: {end_time - start_time:.2f} 秒")