



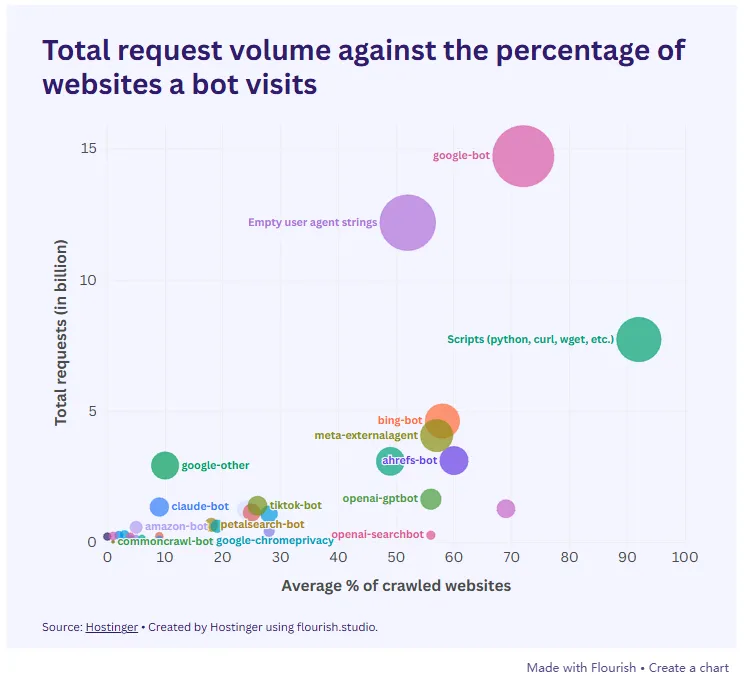
Hostinger最近基于其托管的500多万个网站,分析了长达6天时间窗口内的667亿次机器人请求。
这份庞大的服务器日志分析发现网站管理员们并不是在无差别地抵制AI,而是在进行一场精细的敌我识别。
那些只为了吞噬数据来训练模型的AI爬虫正在大规模失去访问权,而那些能够带来流量、驱动搜索体验的AI助手爬虫,正在悄然扩张其版图。
图源:Hostinger
训练型爬虫令人非常抵触
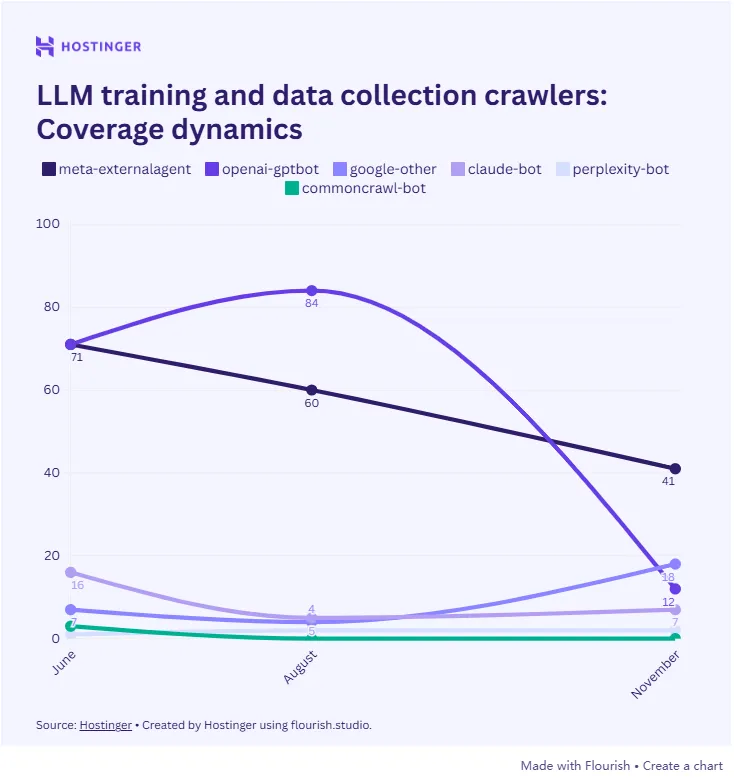
数据中最令人触目惊心的断崖式下跌来自OpenAI的GPTBot。
这个专门用于收集数据以训练模型的爬虫,在研究期间的网站覆盖率从84%暴跌至12%。
这意味着绝大多数站长已经行动起来,通过robots.txt或防火墙规则将这位数据收割者拒之门外。
Meta的ExternalAgent虽然在请求总量上依然庞大,但也面临着同样的窘境。
Hostinger的数据显示,整个训练型机器人组别的覆盖率下降幅度最大。
这与BuzzStream之前的研究不谋而合,当时的数据就表明79%的顶级新闻出版商已经封锁了至少一个训练机器人。
Cloudflare的年度回顾也证实了这一点,GPTBot和ClaudeBot是顶级域名中被全面禁止次数最多的名字。
这种趋势背后的动机非常务实。
训练型爬虫只索取不给予,它们消耗服务器带宽、增加运营成本,却不承诺向网站回传任何流量。
对于网站所有者来说,这就是纯粹的资源消耗,被封锁是必然的商业选择。
图源:Hostinger
搜索型AI获得了大多数网站的通行权
与前者形成鲜明对比的是,为AI搜索工具提供支持的“助手型爬虫”正在获得更广泛的通行权。
OpenAI的OAI-SearchBot,这个专门为ChatGPT搜索功能抓取内容的爬虫,平均覆盖率达到了55.67%。
同样,TikTok的爬虫在发出了14亿次请求的同时,覆盖率增长到了25.67%,苹果的爬虫也达到了24.33%。
这种区别对待并非巧合。这些助手型爬虫通常是由用户行为触发的。
当用户在ChatGPT中提问时,OAI-SearchBot才会出发去寻找实时答案。
对于站长而言,这代表着潜在的流量和曝光机会。
只要被这些爬虫抓取,内容就有可能出现在AI生成的答案中并被引用。
和传统的谷歌搜索类似,是用户通过主动的行为使得网站得到了曝光,这是一种双向的价值交换。
图源:Hostinger
传统搜索与SEO工具的现状
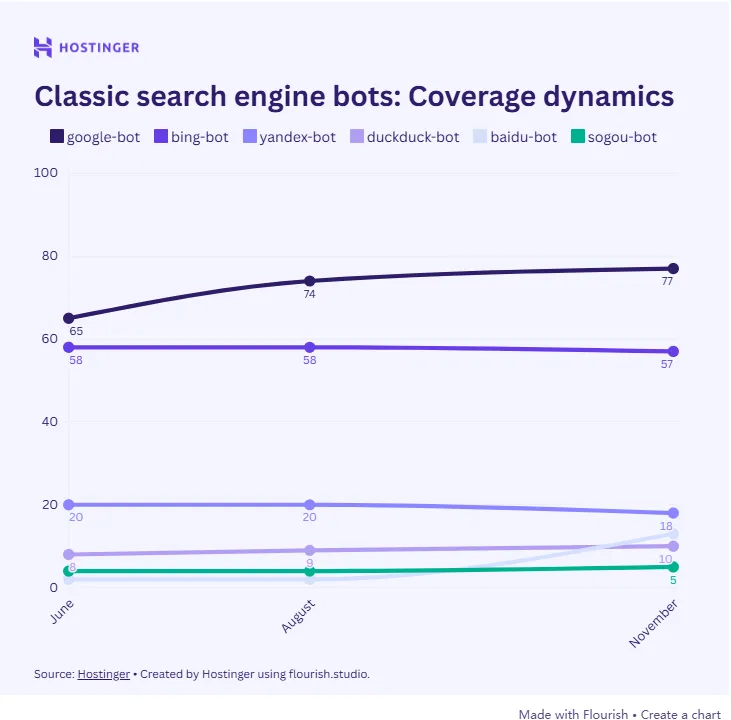
尽管AI抢尽了风头,传统的搜索引擎爬虫依然稳如泰山。
Googlebot在研究期间发出了147亿次请求,保持了72%的平均覆盖率,Bingbot也维持在57.67%。
这说明无论大家对AI有多焦虑,谷歌搜索依然是流量的基本盘。
封锁Googlebot意味着从互联网上隐形,这是绝大多数商业站点无法承受的代价
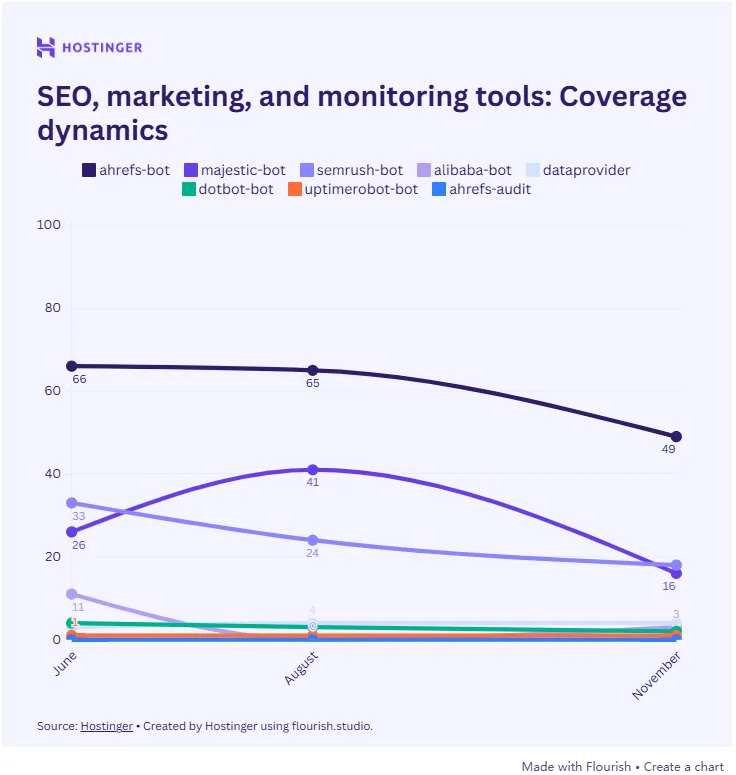
稍微令人担忧的是SEO和营销工具爬虫的衰退。
Ahrefs虽然保持了该类别中最大的足迹(60%覆盖率),但整体类别却在萎缩。Hostinger认为这源于资源成本的考量。
Vercel的数据曾显示GPTBot一个月能产生5.69亿次请求,这种级别的带宽消耗让不少中小站点选择一刀切地封锁非必要爬虫。
这对我们也是一个提醒:当第三方工具的数据采集受限时,可能会导致外链数据的统计出现偏差。
但实际上,只要Googlebot和Bingbot还能抓取到你的外链,它们依然在传递权重。
图源:Hostinger
策略建议:不仅要为爬虫工具开门,还要修路
这次的数据确认了过去一年逐渐形成的共识:站长们正在画一条清晰的界线。
Hostinger建议采取一种折中的策略:坚决封锁训练型机器人以节省资源,但对助手型机器人敞开大门。
OpenAI的官方文档也明确区分了两者,允许OAI-SearchBot并不会导致网站数据被用来训练GPT-5,它只是确保网页能在搜索结果中出现。
对于希望在AI时代保持竞争力的企业来说,仅仅在robots.txt里放行OAI-SearchBot是不够的。
既然这些助手型爬虫是用户触发且目标导向的,它们在抓取时会更加挑剔。
我们需要通过高质量的外部链接来提升站点的权威性,告诉这些AI爬虫:这个站点值得优先抓取和引用。
在这个新环境下,CDN层面的封锁策略可以用来过滤那些无用的消耗,而精准的白名单策略则是为了确保当AI准备回答用户问题时,使我们的品牌正好在它的视野之内。
*本文观点源于SEJ与Hostinger,仅提供内容分享与参考作用
https://www.searchenginejournal.com/openai-search-crawler-passes-55-coverage-in-hostinger-study/565446/
https://www.hostinger.com/blog/ai-bot-analysis