


世界模型技术全栈深度调研报告:架构、数据与系统优化
1. 执行摘要与技术背景
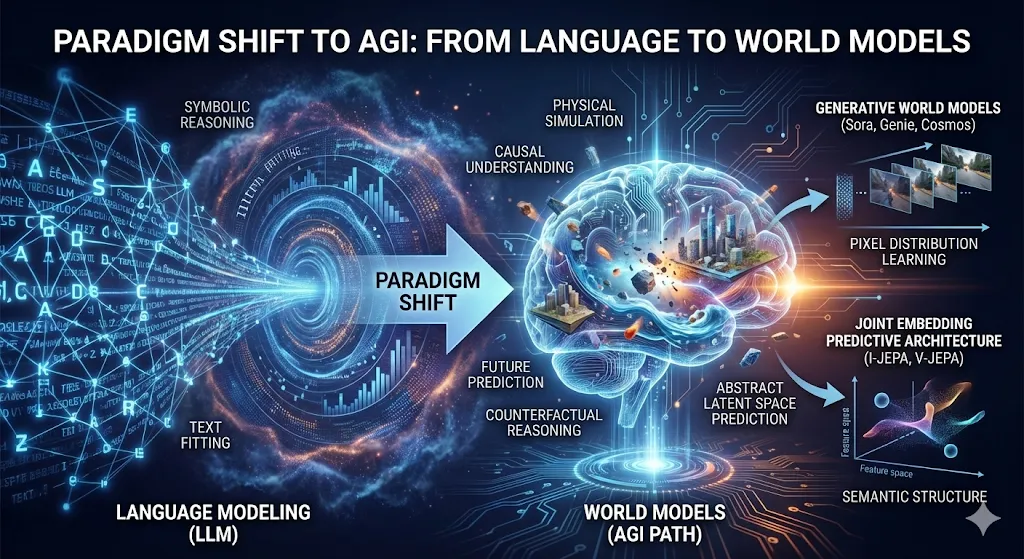
1.1 世界模型的定义与范式转移
通往通用人工智能(AGI)的路径正在经历一场从“语言建模”向“世界建模”的深刻范式转移。传统的语言模型(LLM)虽然在符号推理上取得了惊人的成就,但其本质是对文本统计规律的拟合,缺乏对物理世界时空因果的本质理解。相比之下,**世界模型(World Models)**旨在构建一个能够模拟物理环境演化、预测未来状态并进行反事实推理的内部认知架构。这不仅仅是视频生成,而是赋予AI系统一种类似于人类“心智模型”的能力,即在采取行动之前,能够在内心演练行动的后果 1。
世界模型的概念源于控制理论和认知科学,但其现代深度学习的实现由Ha和Schmidhuber在2018年奠定基础。他们提出的架构将视觉感知(VAE)与记忆预测(RNN)解耦,证明了代理(Agent)可以在完全“幻觉”的梦境中训练策略,并迁移到真实世界 3。如今,这一领域已经演化出两条主要的技术路线:
生成式世界模型(Generative World Models): 以OpenAI的Sora、Google的Genie和NVIDIA的Cosmos为代表。这类模型将世界模拟视为视频生成问题,通过学习海量视频数据中的像素分布,隐式地掌握物理规律(如重力、碰撞、流体动力学)。其核心假设是,如果模型能生成符合物理规律的逼真视频,它必定在内部构建了对物理定律的理解 4。
联合嵌入预测架构(JEPA): 以Yann LeCun提出的I-JEPA和V-JEPA为代表。这一流派认为,在像素空间进行预测不仅计算昂贵,而且由于世界的随机性(Stochasticity),预测具体的像素值往往导致模糊或无效的表示。JEPA主张在抽象的**特征空间(Latent Space)**中预测未来状态的表示,关注语义结构而非像素细节,从而实现更高效、更鲁棒的物理理解 6。
1.2 核心技术挑战
构建一个工业级的世界模型面临着“全栈式”的技术挑战,贯穿了从底层算力到上层应用的每一个环节:
时空压缩(Spatiotemporal Compression): 如何将高维的视频流压缩为紧凑的离散或连续Token,同时保留细微的物理属性(如纹理、速度)?这催生了MagViT-v2等新一代3D Tokenizer技术 9。
长程动力学建模(Long-horizon Dynamics): 视频生成的计算复杂度随长度呈二次方增长。如何让模型在保持几分钟甚至几小时的物理一致性(Object Permanence)的同时,实现高效的训练与推理?Ring Attention和Mamba架构提供了不同的解法 11。
物理对齐(Physical Alignment): 仅仅看起来逼真是不够的,世界模型必须在物理上是“正确”的。从RLHF(人类反馈强化学习)向**RLPF(物理反馈强化学习)**的演进,标志着模型训练目标从“视觉讨好人类”转向“符合物理法则” 13。
推理加速(Inference Acceleration): 作为具身智能(Embodied AI)的大脑,世界模型必须具备实时响应能力。FlashAttention-3、投机采样(Speculative Decoding)以及针对视频特有的滑动块注意力(Sliding Tile Attention)技术,构成了推理优化的关键阵地 15。
本报告将对上述技术模块进行详尽的拆解与分析,旨在为研究人员和工程师提供一份关于构建下一代世界模型的深度技术指南。
2. 视觉表征与Tokenization技术
世界模型的第一层是感知层,即如何将连续的物理世界离散化或映射为模型可处理的潜在变量。视觉编码器(Visual Encoder)的设计直接决定了下游动力学模型的上限。如果Tokenizer丢失了关键的物理信息(如物体边缘的精确位置),动力学模型将无法学会正确的碰撞物理。
2.1 从2D到3D:时空压缩架构的演进
传统的图像生成模型(如DALL-E)使用的是针对静态图像的VQ-VAE或VQ-GAN。然而,世界模型的输入是视频流,存在极高的时间冗余。直接对每一帧进行独立编码(Frame-wise Encoding)不仅效率低下,而且会导致生成的视频在时间上不连贯(Flickering)。因此,3D时空压缩成为了标准范式。
2.1.1 Causal 3D CNN与因果性约束
在视频生成中,一个关键的架构约束是因果性(Causality)。标准的3D卷积(C3D)在编码第 $t$ 帧时,通常会利用 $t+1, t+2$ 等未来帧的信息来辅助压缩。这在离线视频压缩中是可以接受的,但在世界模型(特别是用于机器人控制或实时预测)中是致命的,因为代理无法“看到”未来。
MagViT-v2 和 Improved Video VAE (IV-VAE) 引入了因果3D卷积(Causal 3D Convolution)。通过在时间维度上实施非对称的Padding(仅在过去帧填充),确保 $Latent_t$ 的生成仅依赖于 $Frame_{0...t}$。这种设计使得Tokenizer能够无缝地应用于自回归生成任务,并在推理阶段支持流式处理(Streaming Inference) 9。
2.1.2 查找表无关量化(Lookup-Free Quantization, LFQ)
在离散化Tokenizer(VQ-VAE)中,传统的矢量量化(Vector Quantization)依赖于一个固定的码本(Codebook)。编码器输出向量 $z$,模型在码本中寻找最近邻 $e_k$。这种方法面临两个严重问题:
码本利用率低(Codebook Collapse): 训练过程中,往往只有一小部分码本向量被频繁使用,导致模型的表达能力受限。
查找开销: 随着词表增大,最近邻搜索的计算成本增加。
MagViT-v2 引入了 LFQ(Lookup-Free Quantization) 技术。它不维护一个显式的向量列表,而是直接将潜在向量的维度符号化(Sign-based Quantization)。例如,一个18维的潜在向量可以量化为 $2^{18}$ 种组合。这种方法不仅消除了查找开销,而且极大地提高了“词汇量”的有效利用率(接近100%),显著提升了视频生成的纹理细节重建能力 10。
2.1.3 混合时空压缩策略(KTC架构)
为了解决高压缩率下的细节丢失问题(特别是快速运动物体的模糊),IV-VAE 提出了一种**基于关键帧的时间压缩(Keyframe-based Temporal Compression, KTC)**架构。该架构将潜在空间(Latent Space)分裂为双分支:
空间分支(2D Branch): 继承自预训练的高质量图像VAE(如SDXL的VAE),不做时间压缩。这保证了每一帧的空间结构(如人脸、文字)清晰锐利。
时间分支(3D Branch): 负责捕捉帧间的运动变化,执行高倍率的时间下采样(如4x或8x)。解码器将这两部分信息融合,既保留了静态图像的高保真度,又实现了视频数据的高效压缩。这种“空间-时间解耦”的设计思路,有效地解决了传统3D VAE在处理复杂纹理和高速运动时的权衡难题 17。
2.2 连续与离散:Latent Space的路线之争
当前业界在Latent Space的性质上存在两条截然不同的技术路线,分别对应不同的动力学模型架构。
特性 | 离散Token (Discrete) | 连续Latent (Continuous) |
代表模型 | MagViT-v2, VQ-GAN, Tokenizer of Sora (推测) | Stable Video Diffusion VAE, IV-VAE |
适用架构 | Autoregressive Transformer (GPT-style) | Diffusion Transformer (DiT), U-Net |
优势 | 支持Categorical分布,易于长程预测,能利用LLM的优化技术 | 梯度平滑,适合生成细微的连续变化(如云的流动),更易优化 |
劣势 | 量化误差(Quantization Artifacts),对细微数值不敏感 | 难以直接进行长序列的自回归预测,容易产生累积误差漂移 |
技术趋势 | Token Factorization:将一个大Token分解为多个小Token以提高表达力 | KL Regularization:在Latent空间施加高斯约束以防止分布坍塌 |
分析结论: 对于以“推理”和“决策”为核心的世界模型(如机器人大脑),离散Token因其与逻辑符号的兼容性而更受青睐;而对于以“视觉生成”为核心的应用(如电影制作),连续Latent配合Diffusion模型则能提供更细腻的视觉体验 9。
3. 动力学模型架构:世界模拟的核心引擎
在完成视觉表征后,世界模型的核心任务是学习状态转移概率 $P(s_{t+1} | s_t, a_t)$。这一模块决定了模型能否理解因果律、物体恒常性以及复杂的物理交互。
3.1 Diffusion Transformer (DiT):Sora的基石
Sora的成功标志着Diffusion Transformer (DiT) 架构在视频生成领域的统治地位。DiT彻底抛弃了传统U-Net的归纳偏置(Inductive Bias),将扩散过程建模为一个序列到序列(Seq2Seq)的问题。
3.1.1 3D Patchification与可变分辨率训练
DiT首先将输入的视频Latent Volume切分为一个个“时空补丁(Spacetime Patches)”。类似于ViT处理图像的方式,这些Patch被展平为Token序列。关键创新在于:
NaViT(Native ViT)机制: DiT不要求视频具有固定的分辨率或长宽比。通过掩码(Masking)和位置编码(Positional Embedding)的灵活运用,模型可以在原始分辨率和比例上进行训练,无需裁剪或缩放。这对于保持物理世界的几何一致性至关重要(例如,不改变物体的宽高比从而保持正确的物理尺度)5。
3D RoPE(Rotary Positional Embeddings): 为了让Transformer理解时空关系,DiT采用了推广到3D的旋转位置编码。这使得模型能够基于相对位置(而非绝对坐标)来关注物体,例如理解“物体A在物体B的左边”这一拓扑关系,无论它们在画面的哪个绝对位置 21。
3.1.2 缩放定律(Scaling Laws)与涌现能力
DiT的一个显著特性是其性能与计算量(Compute)之间呈现出强烈的幂律关系。随着参数量和训练数据的增加,DiT展现出了单纯U-Net架构所不具备的涌现能力(Emergent Capabilities):
3D一致性: 模型自动学会了多视角下物体的几何变换,而无需显式的3D监督。
物体恒常性: 即使物体被遮挡(Occlusion),模型也能在后续帧中正确地“恢复”该物体,表明其隐式地学习了物体的存在性 22。
3.2 状态空间模型(SSM)与Mamba:长程记忆的突破
尽管DiT效果惊人,但其核心的Attention机制具有 $O(N^2)$ 的计算复杂度。对于长视频(例如自动驾驶中数分钟的路况),Token数量可能达到百万级,导致显存和计算爆炸。Mamba(Selective State Space Model) 架构因此成为解决长程依赖的关键技术。
3.2.1 线性复杂度与选择性记忆
Mamba的核心在于其线性时间复杂度 $O(N)$。它结合了RNN的递归推理优势(恒定内存占用)和Transformer的并行训练优势。
选择性机制(Selectivity): 传统的SSM(如S4)参数是时不变的。Mamba引入了输入依赖(Input-dependent)的参数 $\Delta, B, C$,使得模型能够根据当前输入动态地决定“遗忘”什么和“记住”什么。在世界模型中,这意味着模型可以忽略背景噪声(如树叶的随机摆动),而长时间锁定关键状态(如交通灯的颜色或行人的移动轨迹) 11。
VideoMamba: 针对视频任务优化的VideoMamba架构,通过堆叠Mamba块,成功实现了在保持全局时空依赖的同时,捕捉细微的短时动作(如手部细微操作)。实验表明,VideoMamba在长视频理解任务上显著优于基于Attention的模型,且推理显存占用降低了数倍 24。
3.3 混合架构:Jamba与Diamond
为了兼顾Transformer的高质量推理和Mamba的长程记忆,混合架构(Hybrid Architecture)正在成为趋势。
Jamba风格: 在深层网络中交替使用Mamba层(负责全局上下文压缩)和Transformer层(负责局部高精度关注)。这种设计允许世界模型在模拟宏观环境演变时极其高效,而在处理关键决策点(如碰撞瞬间)时又能调用Attention机制进行精细推理。
Diamond (Diffusion for RL): 这是一个专门为强化学习代理(Agent)设计的世界模型。它不仅预测环境,还将扩散模型(Diffusion)直接作为环境模拟器。Agent在Diffusion生成的“梦境”中训练。为了解决推理速度问题,Diamond采用了少步数(Low-step)扩散采样,并结合了自回归先验,使其能够在单个GPU上以实时帧率(~10 FPS)运行Minecraft环境,证明了扩散世界模型作为实时游戏引擎的可行性 26。
4. 数据工程:构建物理世界的数字孪生
世界模型的能力边界由数据的质量和多样性决定。与LLM的文本清洗不同,视频数据的处理涉及更为复杂的物理一致性和时空连续性清洗。
4.1 数据清洗与管线(Data Curation Pipeline)
以 NVIDIA Cosmos 的数据处理管线为例,处理2000万小时的视频数据需要高度自动化的工业级流程 4:
美学评分与质量过滤(Aesthetic & Quality Filtering): 使用预训练的美学评分模型(Aesthetic Scorer)过滤掉模糊、过暗或构图混乱的视频。低质量的输入会导致模型学习到错误的纹理分布。
运动过滤(Motion Filtering): 静态视频(如监控摄像头拍摄的空街道)对于学习动力学毫无价值,而过度混沌的视频(如手持相机剧烈晃动)则引入噪声。通过计算光流(Optical Flow)幅值,筛选出具有“有意义运动”的片段。
去水印与去噪(De-watermarking): 水印是世界模型训练的“毒药”。如果大量视频带有水印,模型会错误地认为水印是物理世界的一部分(例如,认为天空中应该漂浮着半透明的文字)。利用深度学习修复技术(Deep In-painting)去除水印和覆盖层是必要的预处理步骤 29。
语义去重(Semantic Deduplication): 避免模型在常见场景(如高速公路行驶)上过拟合,而在罕见场景(如车祸)上欠拟合。通过视频内容的Embedding聚类,对常见类别进行降采样。
4.2 自动化标注与差分描述(Differential Captioning)
对于文本条件生成的世界模型(Text-to-World),Caption的质量至关重要。传统的“一图一文”无法描述演变过程。ShareGPT4Video 提出了一种创新的差分描述策略31:
关键帧描述: 首先对视频起始帧进行详尽的静态描述。
时间差分描述: 对于后续帧,不重新描述整个画面,而是让VLM(如GPT-4V)关注“变化量”——即 $\Delta(Frame_t, Frame_{t-1})$。例如:“镜头向左平移,原本坐着的狗站了起来并开始奔跑。”
层级化摘要: 将这些差分描述汇总为三个层级:短时原子动作(10s)、中时事件摘要(30s)和长时全局叙事。这种结构化的文本数据使得世界模型能够学习到不同时间尺度上的因果关系。
4.3 合成数据与仿真引擎
真实数据存在“长尾分布”问题(例如,极少有记录极端物理碰撞的视频)。因此,合成数据(Synthetic Data) 正在成为核心燃料。
程序化生成(Procedural Generation): 利用 Unreal Engine 5 (UE5)、Unity 或 CARLA 等引擎,可以生成带有完美Ground Truth(深度图、语义分割、光流、表面法线)的视频数据。NVIDIA的 Omniverse 平台能够通过 Cosmos Transfer 技术,将简单的仿真渲染图像“转绘”为照片级逼真的图像,从而弥合 Sim-to-Real 的鸿沟 34。
PhysWorld 与 RoboScape: 这些项目展示了如何利用物理引擎生成符合牛顿力学的数据来训练轻量级世界模型。通过在仿真中穷举物体的物理属性(质量、摩擦力、弹性),模型学会了在视觉上无法直接观测到的物理交互特性 37。
5. 训练范式与物理对齐
仅仅最小化像素重建误差(Reconstruction Loss)不足以训练出符合物理规律的世界模型。模型需要通过更高阶的信号来“理解”物理。
5.1 预训练目标函数
掩码建模(Masked Modeling): 类似于BERT,随机掩盖视频中的时空立方体,要求模型重建。这迫使模型理解物体结构和运动连续性(例如,为了重建被遮挡的汽车尾部,必须理解汽车的整体刚体运动)24。
自回归预测(Autoregressive Prediction): 预测下一个Token。这是学习因果律的最直接方式,但容易产生“误差累积”,导致长视频生成崩溃。
去噪得分匹配(Denoising Score Matching): Diffusion模型的目标,预测施加在Latent上的噪声。这在生成高频细节上表现更佳。
5.2 物理反馈强化学习(RLPF)
这是一个前沿且关键的研究方向。RLHF(基于人类反馈的强化学习)在文本领域大获成功,但人类很难肉眼判断复杂的物理误差(如角动量是否守恒)。RLPF (Reinforcement Learning from Physical Feedback) 引入了物理模拟器作为奖励函数 13:
生成与追踪: 世界模型生成一段视频(如机器人抓取杯子)。
物理校验: 一个运动追踪策略(Motion Tracking Policy) 尝试在物理引擎(如MuJoCo)中复现视频中的动作。
物理奖励(Physical Reward): 如果追踪策略发现视频中的动作违反物理约束(例如手穿过了杯子,或者物体凭空悬浮),模拟器会反馈巨大的负奖励。
策略优化: 使用PPO算法更新世界模型,使其生成的视频更符合物理定律。这一过程实际上是将物理引擎的先验知识“蒸馏”进了生成模型中。
5.3 物理感知损失函数(Physics-Informed Loss)
除了RL,还可以将物理约束直接编码为损失函数项:
Newtonian VAE / Neural ODEs: 将潜在空间的演化强制约束为服从常微分方程(ODE)。损失函数包含一项 $\mathcal{L}_{physics} = |
| \frac{dz}{dt} - f_{Newton}(z) ||$,惩罚任何违背牛顿力学的潜在状态轨迹 40。
PhysTwin: 在重建数字孪生时,不仅优化外观误差,还联合优化物理参数(刚度、质量分布),使得重建的对象在仿真中具有与视频中相同的动态响应 43。
6. 训练与推理加速系统
世界模型的计算量巨大,甚至超过了同等参数量的LLM。为了实现可扩展的训练和实时的推理,系统层面的优化是必不可少的。
6.1 训练加速:Ring Attention
对于长视频生成,序列长度(Context Length)轻易突破百万Token。标准的Attention机制无法在单卡显存中处理。
Ring Attention 是一种分布式Attention算法,它将序列切块分布在环状连接的GPU集群上 12:
块状计算与通信重叠: 每个GPU只存储输入序列的一部分。在计算Attention Score时,GPU之间在一个逻辑环上轮转传递Key/Value(KV)块。
优势: 计算与通信完全重叠(Overlap),使得训练最大序列长度随GPU数量线性增加,理论上支持无限长的上下文(Near-Infinite Context)。这使得训练包含数小时历史信息的“长记忆”世界模型成为可能。
6.2 推理加速:FlashAttention-3 与 FP8
在推理端(特别是机器人实时控制),延迟(Latency)是核心指标。
FlashAttention-3 针对NVIDIA Hopper (H100) 架构进行了深度优化 15:
Warp Specialization(Warp特化): 将GPU上的线程束(Warps)分为“生产者”和“消费者”。生产者Warp专门负责将数据从HBM搬运到SRAM,消费者Warp专门负责计算GEMM和Softmax。这种异步流水线设计极大地掩盖了内存访问延迟。
FP8 精度支持: 利用H100的FP8 Tensor Cores。为了解决FP8精度低的问题,引入了非相干处理(Incoherent Processing),通过随机正交旋转将异常值(Outliers)分散到所有通道,避免量化崩塌,实现吞吐量倍增。
6.3 视频生成特有的加速:Speculative Decoding 与 STA
投机采样(Speculative Decoding): 利用一个小型的“草稿模型(Draft Model)”快速生成未来几帧的潜在Token,然后由大模型进行并行验证。由于视频中相邻帧存在大量不变背景,草稿模型的预测准确率极高,这在视频生成中能带来比文本生成更高的加速比(2-3倍) 47。
滑动块注意力(Sliding Tile Attention, STA): 针对视频DiT的特性,STA 认识到视频中的注意力主要集中在时空邻域。它将注意力计算限制在一个滑动的3D窗口内,通过跳过空的注意力块和优化显存访问,在不损失质量的前提下,将视频生成速度提升了数倍 16。
7. 评估与基准测试
7.1 FVD的局限性
长期以来,Fréchet Video Distance (FVD) 是评估视频生成质量的标杆。然而,研究表明FVD存在严重缺陷:它是一个基于I3D特征的统计距离,偏重于单帧的视觉质量,而对物理逻辑错误(如物体瞬移、消失)不敏感。一个FVD分数很好的模型可能生成的视频完全不符合物理常识 50。
7.2 VBench 与 WorldModelBench:多维能力评估
新一代基准测试体系致力于解耦评估维度:
VBench 提供了一个雷达图式的评估体系,涵盖16个维度,包括物体恒常性(Object Permanence)、背景一致性、运动平滑度等。它使用专门的视觉检测模型(如DETR、Optical Flow Estimator)来对生成的视频进行“体检”,而非仅仅计算分布距离 52。
WorldModelBench 则更进一步,关注决策效用(Decision-making Utility)。它不仅看视频是否逼真,更看视频是否能支持正确的下游任务规划。例如,给定“前方红灯”的文本指令,模型生成的未来视频中车辆是否减速?它引入了人类标注和专门训练的Judge Model,对模型的物理依从性和指令跟随能力进行打分 53。
8. 结论与展望
世界模型技术栈已经从早期的单一预测模型演变为一个复杂的系统工程。
架构融合:DiT 的生成质量与 Mamba 的高效记忆正在融合,混合架构将成为主流。
物理即真理: 数据处理和训练目标正从“视觉拟合”转向“物理对齐”。RLPF 和物理引擎的引入,正在让AI从“画师”变成“模拟器”。
合成数据主导: 随着真实数据的耗尽和长尾场景的缺失,基于 UE5/Omniverse 的高保真合成数据将成为提升模型物理推理能力的关键。
端侧实时化: 随着 FlashAttention-3、FP8 和 Speculative Decoding 的普及,世界模型将不仅运行在云端,更将植入机器人和自动驾驶汽车的芯片中,成为具身智能真正的“小脑”。
通过打通感知(Tokenizer)、认知(Dynamics Model)与行动(RLPF),世界模型正在补全AGI拼图中缺失的那块物理常识拼图。
数据表格索引:
表1:视觉Tokenizer架构对比(2.1节)
表2:离散与连续Latent技术路线对比(2.2节)
引用说明: 本报告中所有引用的技术点均基于提供的研究片段,涵盖了从arXiv预印本到顶级会议(CVPR, NeurIPS, ICLR)的最新成果。
引用的著作
World Models for Autonomous Driving: An Initial Survey - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2403.02622v1
Topic 35: What are World Models?, 访问时间为 一月 20, 2026, https://www.turingpost.com/p/topic-35-what-are-world-models
World Models, 访问时间为 一月 20, 2026, https://worldmodels.github.io/
arxiv.org, 访问时间为 一月 20, 2026, https://arxiv.org/html/2501.03575v1
What is OpenAI's Sora Diffusion Transformer (DiT)? - Analytics Vidhya, 访问时间为 一月 20, 2026, https://www.analyticsvidhya.com/blog/2024/05/what-is-openais-sora-diffusion-transformer-dit/
Joint-Embedding Architecture as an alternative to Generative AI | by Sukant Khurana, 访问时间为 一月 20, 2026, https://medium.com/@sukantkhurana/joint-embedding-architecture-as-an-alternative-to-generative-ai-15346ec631f6
Can someone explain to me in a laymen-ish terms why is I-JEPA (Yann Lecun) architecture not generative? - Reddit, 访问时间为 一月 20, 2026, https://www.reddit.com/r/learnmachinelearning/comments/1gya9pm/can_someone_explain_to_me_in_a_laymenish_terms/
Inside World Models and V-JEPA: Building AI That Predicts Reality | Towards AI, 访问时间为 一月 20, 2026, https://towardsai.net/p/machine-learning/inside-world-models-and-v-jepa-building-ai-that-predicts-reality
Progressive Growing of Video Tokenizers for Highly Compressed Latent Spaces - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2501.05442v1
Language Model Beats Diffusion — Tokenizer is Key to Visual Generation - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2310.05737v2
What Is A Mamba Model? | IBM, 访问时间为 一月 20, 2026, https://www.ibm.com/think/topics/mamba-model
RingAttention with Blockwise Transformers for Near-Infinite Context - ICLR Proceedings, 访问时间为 一月 20, 2026, https://proceedings.iclr.cc/paper_files/paper/2024/file/1119587863e78451f080da2a768c4935-Paper-Conference.pdf
RL from Physical Feedback: Aligning Large Motion Models with Humanoid Control - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2506.12769v1
RL from Physical Feedback: Aligning Large Motion Models with Humanoid Control - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/abs/2506.12769
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision - NIPS papers, 访问时间为 一月 20, 2026, https://proceedings.neurips.cc/paper_files/paper/2024/file/7ede97c3e082c6df10a8d6103a2eebd2-Paper-Conference.pdf
Fast Video Generation with Sliding Tile Attention | Hao AI Lab @ UCSD, 访问时间为 一月 20, 2026, https://hao-ai-lab.github.io/blogs/sta/
Improved Video VAE for Latent Video Diffusion ... - CVF Open Access, 访问时间为 一月 20, 2026, http://openaccess.thecvf.com/content/CVPR2025/papers/Wu_Improved_Video_VAE_for_Latent_Video_Diffusion_Model_CVPR_2025_paper.pdf
CV-VAE: A Compatible Video VAE for Latent Generative Video Models - NIPS, 访问时间为 一月 20, 2026, https://proceedings.neurips.cc/paper_files/paper/2024/file/1787533e171dcc8549cc2eb5a4840eec-Paper-Conference.pdf
Variational Autoencoders: VAE to VQ-VAE / dVAE - Rohit Bandaru, 访问时间为 一月 20, 2026, https://rohitbandaru.github.io/blog/VAEs/
Some Details on OpenAI's Sora and Diffusion Transformers | ml-news - Wandb, 访问时间为 一月 20, 2026, https://wandb.ai/byyoung3/ml-news/reports/Some-Details-on-OpenAI-s-Sora-and-Diffusion-Transformers--Vmlldzo2ODQwNTM3
Depth Any Video with Scalable Synthetic Data - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2410.10815v2
Diffusion Transformer (DiT) Models: A Beginner's Guide - Encord, 访问时间为 一月 20, 2026, https://encord.com/blog/diffusion-models-with-transformers/
Mamba Explained - The Gradient, 访问时间为 一月 20, 2026, https://thegradient.pub/mamba-explained/
[2403.06977] VideoMamba: State Space Model for Efficient Video Understanding - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/abs/2403.06977
VideoMamba: State Space Model for Efficient Video Understanding, 访问时间为 一月 20, 2026, https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/03773.pdf
Diamond - diffusion for world modeling, 访问时间为 一月 20, 2026, https://diamond-wm.github.io/
[2509.24527] Training Agents Inside of Scalable World Models - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/abs/2509.24527
NVIDIA Cosmos for Developers, 访问时间为 一月 20, 2026, https://developer.nvidia.com/cosmos
Efficient Video Watermarking Algorithm Based on Convolutional Neural Networks with Entropy-Based Information Mapper - PubMed Central, 访问时间为 一月 20, 2026, https://pmc.ncbi.nlm.nih.gov/articles/PMC9955864/
rldhkstopic/DeepLearning-Watermarking: Major study - GitHub, 访问时间为 一月 20, 2026, https://github.com/rldhkstopic/DeepLearning-Watermarking
LLaVA-Video: Video Instruction Tuning With Synthetic Data - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2410.02713v3
ShareGPT4Video, 访问时间为 一月 20, 2026, https://sharegpt4video.github.io/
ShareGPT4Video: Improving Video Understanding and Generation with Better Captions - NeurIPS, 访问时间为 一月 20, 2026, https://proceedings.neurips.cc/paper_files/paper/2024/file/22a7476e4fd36818777c47e666f61a41-Paper-Datasets_and_Benchmarks_Track.pdf
SegGen: An Unreal Engine 5 Pipeline for Generating Multimodal Semantic Segmentation Datasets - PMC - NIH, 访问时间为 一月 20, 2026, https://pmc.ncbi.nlm.nih.gov/articles/PMC12431427/
Accelerating AV Simulation with Neural Reconstruction and World Foundation Models, 访问时间为 一月 20, 2026, https://developer.nvidia.com/blog/accelerating-av-simulation-with-neural-reconstruction-and-world-foundation-models/
AI rendering - CARLA Simulator, 访问时间为 一月 20, 2026, https://carla.readthedocs.io/en/latest/ai_rendering/
PhysWorld: From Real Videos to World Models of Deformable Objects via Physics-Aware Demonstration Synthesis - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2510.21447v1
NeurIPS Poster RoboScape: Physics-informed Embodied World Model, 访问时间为 一月 20, 2026, https://neurips.cc/virtual/2025/poster/115313
RL from Physical Feedback: Aligning Large Motion Models with Humanoid Control, 访问时间为 一月 20, 2026, https://openreview.net/forum?id=KhNq7zm2UL
Physics-Informed Loss Functions - Emergent Mind, 访问时间为 一月 20, 2026, https://www.emergentmind.com/topics/physics-informed-loss-functions
A Physics-Informed Variational Autoencoder for Modeling Power Plant Thermal Systems, 访问时间为 一月 20, 2026, https://www.mdpi.com/1996-1073/18/17/4742
NewtonGen: Physics-Consistent and Controllable Text-to-Video Generation via Neural Newtonian Dynamics - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2509.21309v1
PhysTwin: Physics-Informed Reconstruction and Simulation of Deformable Objects from Videos - CVF Open Access, 访问时间为 一月 20, 2026, https://openaccess.thecvf.com/content/ICCV2025/papers/Jiang_PhysTwin_Physics-Informed_Reconstruction_and_Simulation_of_Deformable_Objects_from_Videos_ICCV_2025_paper.pdf
Ring Attention with Blockwise Transformers for Near-Infinite Context - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2310.01889v1
GPU MODE Lecture 13: Ring Attention - Christian Mills, 访问时间为 一月 20, 2026, https://christianjmills.com/posts/cuda-mode-notes/lecture-013/
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2407.08608v1
An Introduction to Speculative Decoding for Reducing Latency in AI Inference, 访问时间为 一月 20, 2026, https://developer.nvidia.com/blog/an-introduction-to-speculative-decoding-for-reducing-latency-in-ai-inference/
Continuous Speculative Decoding for Autoregressive Image Generation - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2411.11925v2
\scalerel* SpecVLM: Enhancing Speculative Decoding of Video LLMs via Verifier-Guided Token Pruning - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2508.16201v1
FVD & VBench Metrics: Video Model Evaluation - Emergent Mind, 访问时间为 一月 20, 2026, https://www.emergentmind.com/topics/fvd-and-vbench-metrics
Beyond FVD: Enhanced Evaluation Metrics for Video Generation Quality - arXiv, 访问时间为 一月 20, 2026, https://arxiv.org/html/2410.05203v2
VBench: Comprehensive Benchmark Suite for Video Generative Models - CVF Open Access, 访问时间为 一月 20, 2026, https://openaccess.thecvf.com/content/CVPR2024/papers/Huang_VBench_Comprehensive_Benchmark_Suite_for_Video_Generative_Models_CVPR_2024_paper.pdf
WorldModelBench: Judging Video Generation Models As World Models, 访问时间为 一月 20, 2026, https://worldmodelbench.github.io/static/pdfs/3_WorldModelBench_Judging_Vide.pdf