


算力芯片是专门为AI应用设计的处理器,具备并行计算能力和针对神经网络的优化架构,用于快速处理大规模数据和复杂模型。其核心作用是为AI服务器提供算力底层支撑,是“AI时代的引擎”。当前共有四种AI计算加速芯片技术架构,GPU为目前大模型训练及推理主力。当前国产算力行业的发展环境正由“外部封锁”与“内需爆发”双引擎合力驱动,处于历史性机遇期。2026年,国产算力芯片将迎来性能提升的关键年份,多家厂商的新一代产品将实现与国际先进水平的并跑甚至局部领跑,国产芯片的发布节奏已从早期的追赶进入自我迭代的良性周期。
围绕算力芯片行业,我们对其发展驱动因素及国产算力近年发展情况、芯片制造及市场供需关系进行分析,了解国产替代相关进程,并对产业链及相关公司进行梳理,希望帮助大家更多了解算力芯片行业发展情况。
01
算力芯片发展驱动因素
1.人工智能取得突破性进展,多模态大模型涌现
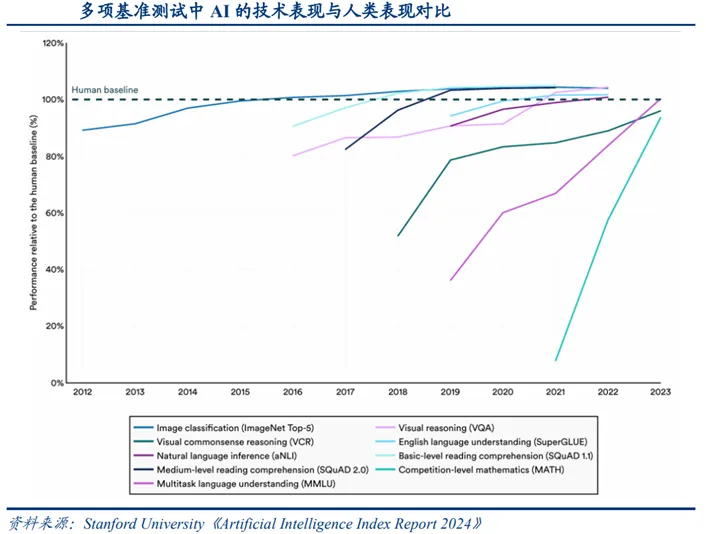
十年前,世界上最好的人工智能系统也无法以人类的水平对图像中的物体进行分类。如今,人工智能已在多项基准测试中实现了超越人类能力的性能水平。据斯坦福大学在相关资料中统计,人工智能分别在2015、2017、2020、2021年在图像分类、基本阅读理解、视觉推理和自然语言推理任务中超越人类表现。2023年,人工智能聊天机器人ChatGPT、AI编程工具GitHub CoPilot和图像生成系统Stable Diffusion等生成式人工智能应用和工具产品涌现,为文本创建、图像生成、代码生成以及研发流程等工作带来全新的智能体验。2025年8月,ChatGPT-5在数学、实际程序设计、多模态理解和健康领域的基准测试中全面刷新最高记录,并在GPQA中取得88.4%的高分,创下SOTA新纪录。
2.大语言模型进化遵循Scaling law法则,能力提升依赖于海量算力供给
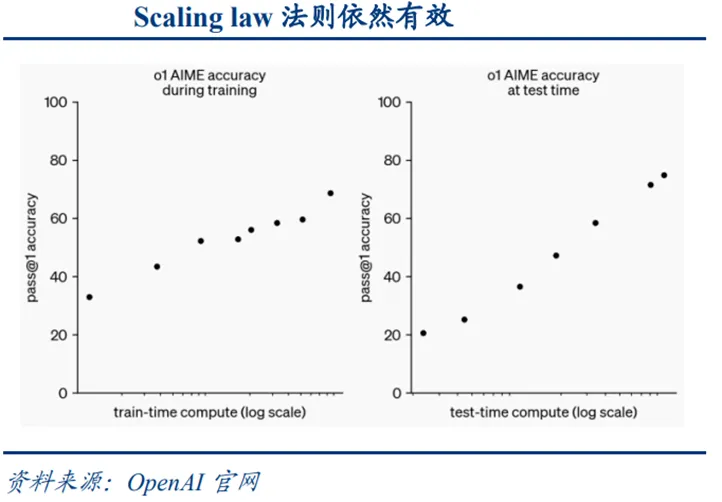
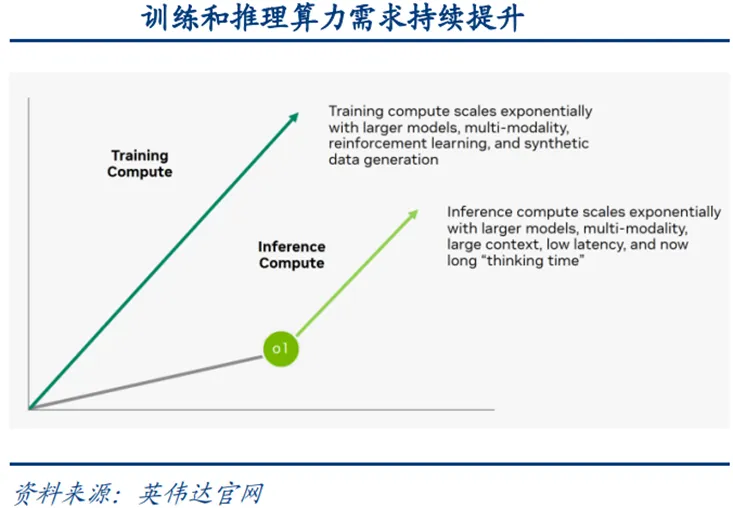
大语言模型的性能遵循Scaling Law法则。即在固定的模型架构下,模型的最终性能主要与计算量、模型参数量和训练数据量相关。当保持其中两个因素不变时,提升第三个因素,模型的测试损失会以可预测的幂律形式下降。据OpenAI等机构研究,训练阶段的Scaling Law已得到充分验证;同时,模型在各类下游推理任务上表现出的能力,也展现出类似的缩放规律。未来,随着AI大模型向多模态、强推理、数据合成等方向演进,算力将继续作为核心驱动力,推动模型能力不断突破,并加速AI应用的广泛落地。
3.GPU为当前主流算力芯片
算力芯片是专门为AI应用设计的处理器,具备并行计算能力和针对神经网络的优化架构,用于快速处理大规模数据和复杂模型。其核心作用是为AI服务器提供算力底层支撑,是“AI时代的引擎”。
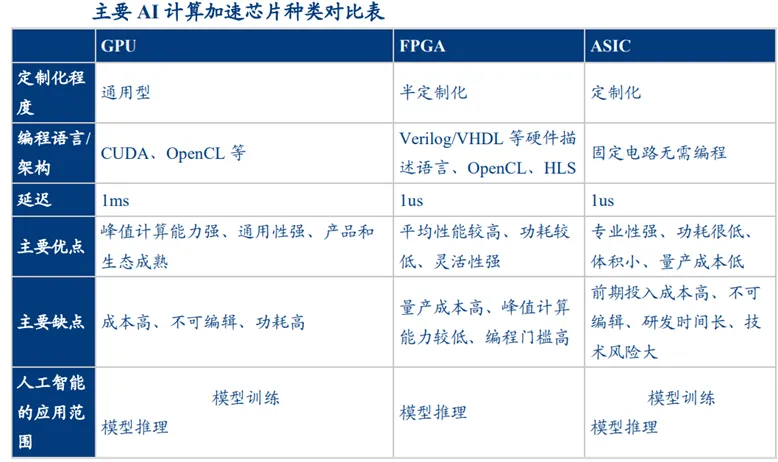
当前共有四种AI计算加速芯片技术架构,GPU为目前大模型训练及推理主力。在技术构架角度,AI计算加速芯片可分为GPU、FPGA(Field Programmable Gate Array,可编程逻辑门阵列)、ASIC(Application Specific Integrated Circuit,专用集成电路)和NPU(Neural Processing Unit,神经网络处理器)。在当前阶段,相较于ASIC和FPGA,GPU在通用计算性能、开发友好性上更具优势,也比处于探索阶段的NPU更为成熟。因此,GPU成为大模型训练和推理领域的主力。未来随着经济社会进步和AI技术的深入发展,更多专业化的AI计算加速芯片也会进入市场。
02
我国算力芯片发展概述
1.发展环境处于历史性机遇期
当前国产算力行业的发展环境正由“外部封锁”与“内需爆发”双引擎合力驱动,处于历史性机遇期。一方面,外部技术出口管制,特别是美国针对高端AI芯片的限制,在市场上制造了紧迫的供给真空,促使国内产业加速寻求替代方案。另一方面,国内大型语言模型(LLM)技术的飞速进步和AI应用的爆发式增长,点燃了对高性能计算前所未有的需求。这种供需两侧的强烈共振,正加速国产算力产业链的迭代升级,筑牢行业长期增长的坚实根基。
2.我国将“自主可控”提升至战略高度
作为回应,国家政策将“自主可控”提升至战略高度,通过国企采购倾斜、研发补贴等方式注入强劲动力。近年来,我国高度重视算力基础设施建设,将“东数西算”工程、全国一体化算力网等纳入国家战略顶层设计,形成系统性政策支持体系。2025年10月20日,中共第二十届中央委员会第四次全体会议审议通过《中共中央关于制定国民经济和社会发展第十五个五年规划的建议》,明确将算力作为数字经济时代的新型生产力,将其发展提升至支撑中国式现代化的战略高度。
3.我国算力市场呈现结构化增长特征
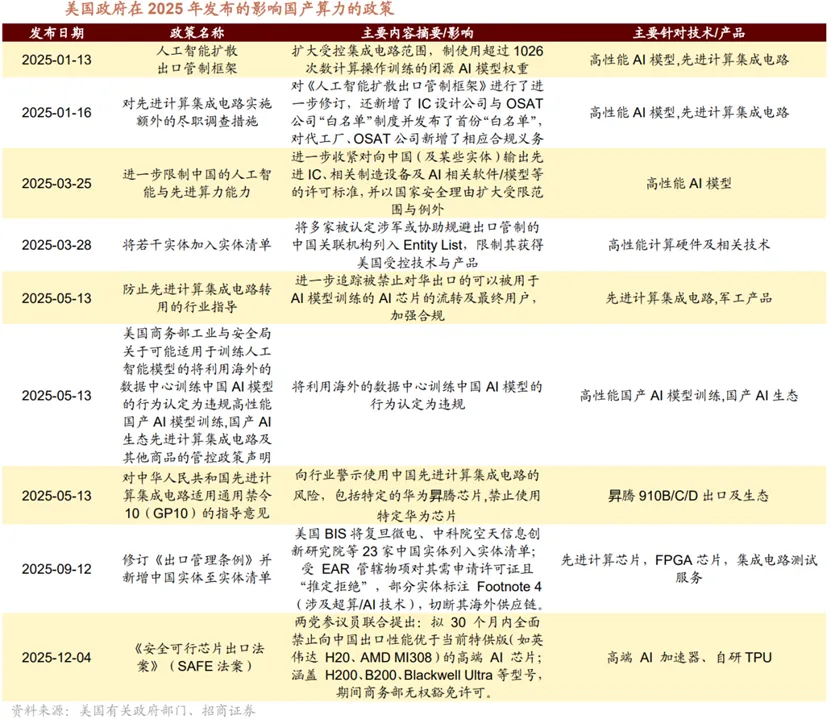
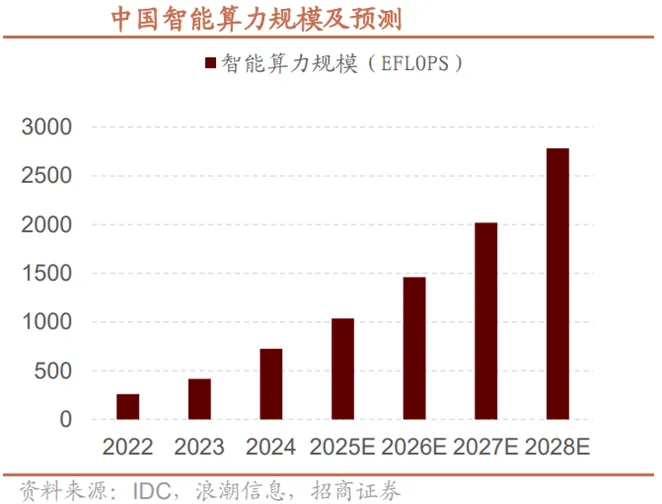
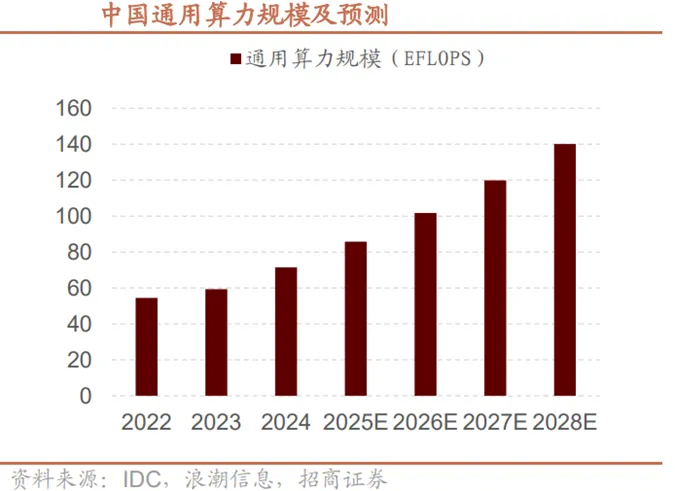
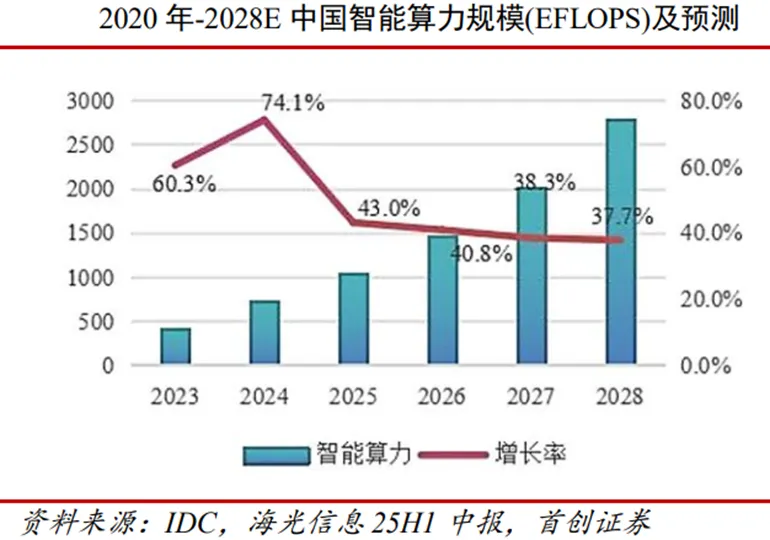
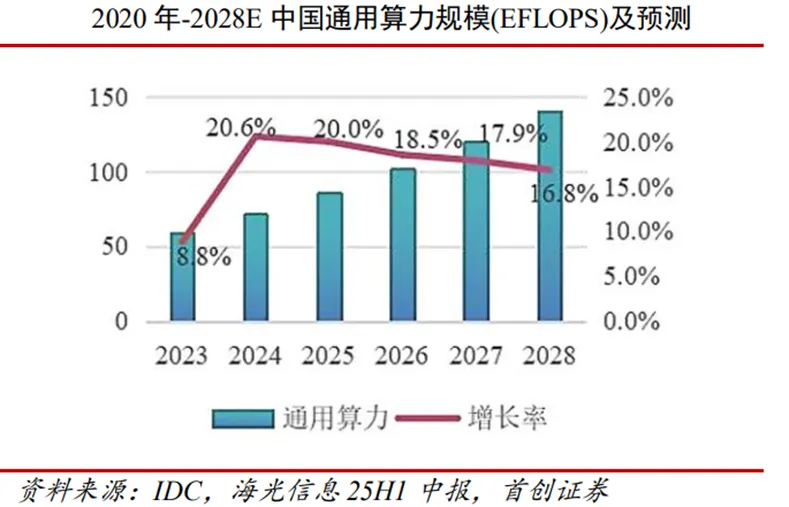
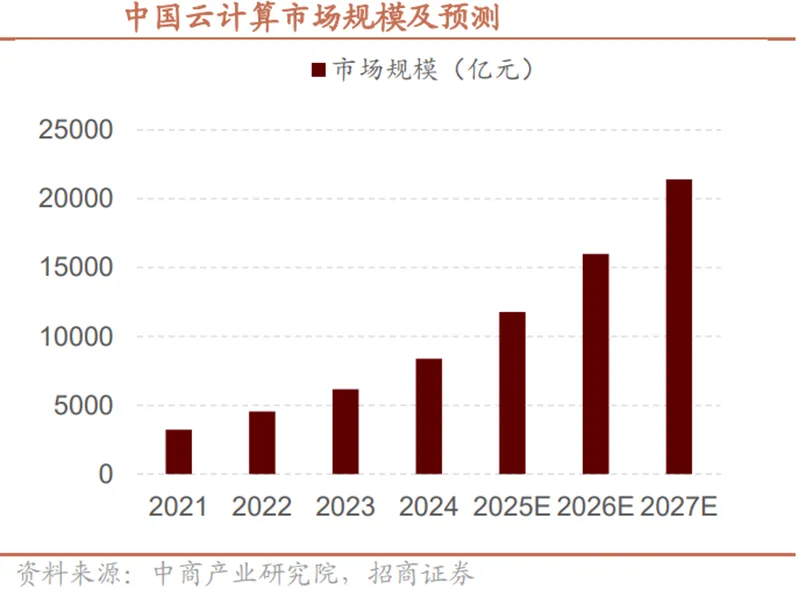
根据国际数据公司(IDC)与浪潮信息联合发布的《2025年中国人工智能计算力发展评估报告》,2024年我国算力市场呈现结构化增长特征。通用算力规模达71.5EFLOPS(每秒百亿次浮点运算次数),同比增长20.6%;智能算力规模飙升至725.3EFLOPS,同比大增74.1%,增速为通用算力的三倍以上。2025年增长趋势延续,通用算力预计达85.8EFLOPS,同比增长20%;智能算力规模将进一步扩大至1037.3EFLOPS,同比增长43%,持续显著跑赢通用算力增速,成为算力增长核心引擎。预测显示,2023-2028年中国智能算力规模和通用算力规模的五年年复合增长率预计分别达46.2%和18.8%,较上期均有显著提升。
4.国产AI加速芯片:市场规模爆发与结构重构并行
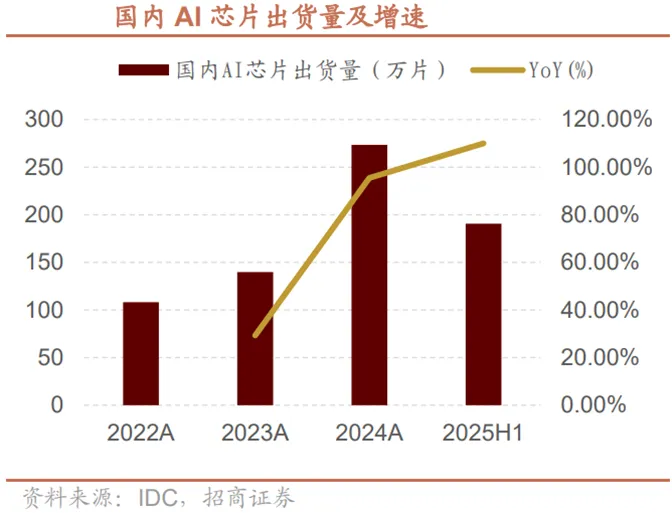
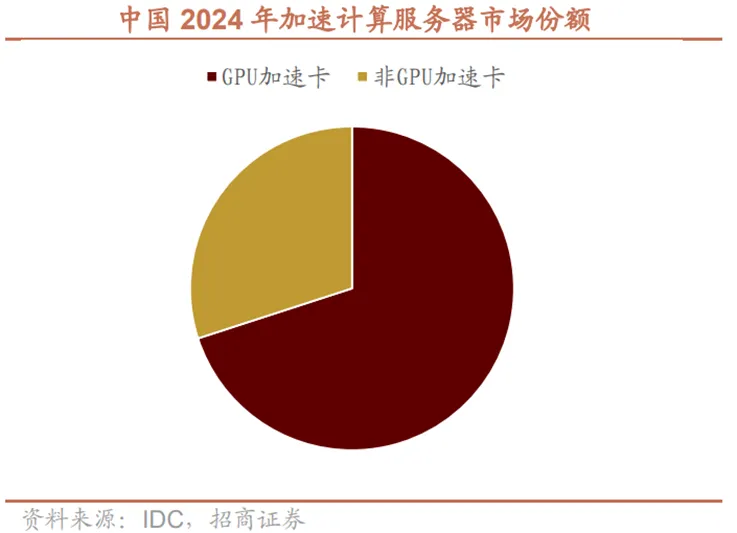
据IDC最新统计数据,中国AI加速芯片市场呈现“规模爆发+结构优化”的双重特征。2025年上半年中国AI芯片整体出货量突破190万张,较2024年上半年的90万张同比激增111%,净增超100万张,彰显国内AI算力需求的井喷态势。从技术路线来看,市场结构正发生深刻调整。国内加速计算服务器GPU仍为主流算力载体,但市场份额已从2024年上半年的80%降至70%,同比下滑10个百分点;ASIC、FPGA等非GPU加速方案凭借场景适配性与能效优势高速增长,占比跃升至30%,其中ASIC因定制化算力优势成为增长主力,广泛应用于工业质检、医疗影像等垂直场景。IDC预测,随着多模态大模型与行业定制算力需求爆发,2029年非GPU加速服务器市场规模占比将接近50%,形成“GPU与非GPU协同发展”的多元化格局。
5.国产大模型和国产芯片有望形成闭环
算力作为数字经济发展的核心要素,应用场景不断由通用扩展到专业。据IDC数据,2025年中国智能算力规模将达1037.3EFLOPS,预计2028年攀升至2781.9EFLOPS;通用算力规模同期由85.8EFLOPS增长至140.1EFLOPS,增长稳健。2023-2028年期间,中国智算算力五年复合增长率高达46.2%,显著高于通用算力18.8%的增速,智算成为拉动算力产业增长的核心引擎。
国产大模型和国产算力芯片有望形成商业闭环。2025年8月21日,DeepSeek发布了DeepSeek-V3.1大模型。DeepSeek-V3.1采用了UE8M0FP8Scale参数精度,并表示UE8M0FP8是针对即将发布的下一代国产芯片设计。在AI训练与推理的过程中,通过降低数值精度,可以提升计算效率。采用FP8能够使算力效率翻倍,同时降低训练和推理过程中的网络带宽的通信量,使得在相同的功耗下,AI芯片可以训练更大的模型或缩短训练时间。
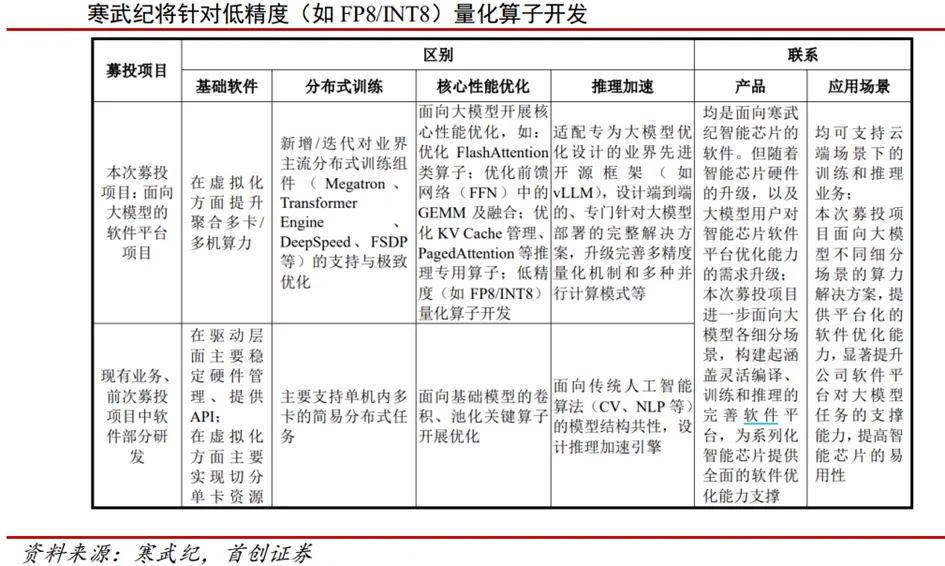
寒武纪在下一代算力芯片的研发中针对FP8进行布局。根据寒武纪在2025年7月18日的定增问询函回复中的披露,其该次募投项目将面向大模型开展核心性能优化,包括优化Flash Attention类算子;优化前馈网络(FFN)中的GEMM及融合;优化KVCache管理、Paged Attention等推理专用算子;低精度(如FP8/INT8)量化算子开发。
03
算力芯片产业链
算力产业包括上游的芯片及元器件,中游的服务器与网络设备,下游的数据中心及云服务三部分构成,在其中的各个板块,均已有国产厂商深度布局。上游涵盖GPU/NPU/ASIC/CPU、存储与高速互联器件及EDA/IP,其关键作用是决定单卡算力、能效与指令集兼容性,构成技术壁垒与长期价值锚;中游由AI服务器整机、互联交换、光模块与冷却/电源等网络设备构成,负责将芯片能力工程化为可部署的算力单元,决定集群效率、部署密度与单位算力TCO;下游则为IDC与超大云厂商,承担算力的规模化承载、运维与商业变现,直接把需求侧的模型训练与海量在线推理转化为对上游与中游的资本支出与采购订单。
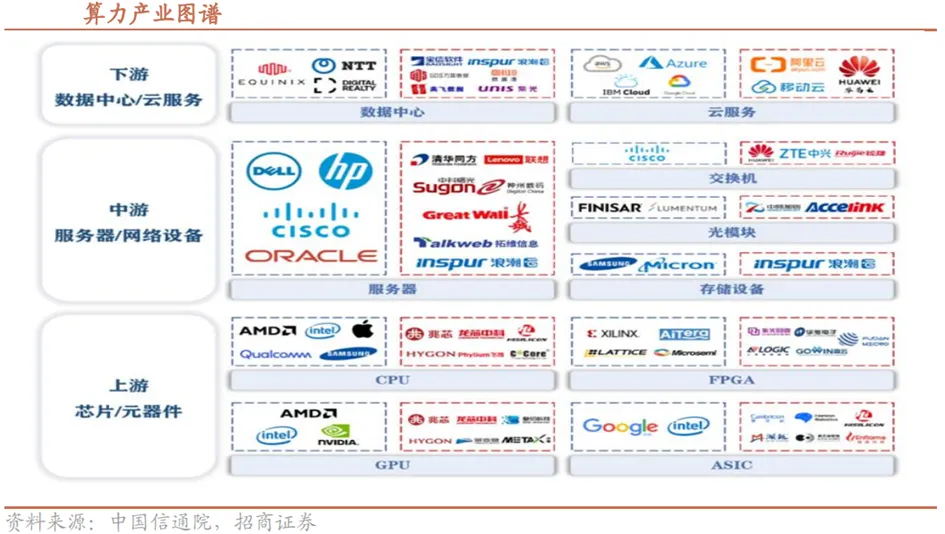
1.上游:AI芯片技术实现跨越式跃迁,引领国产算力堆栈升级
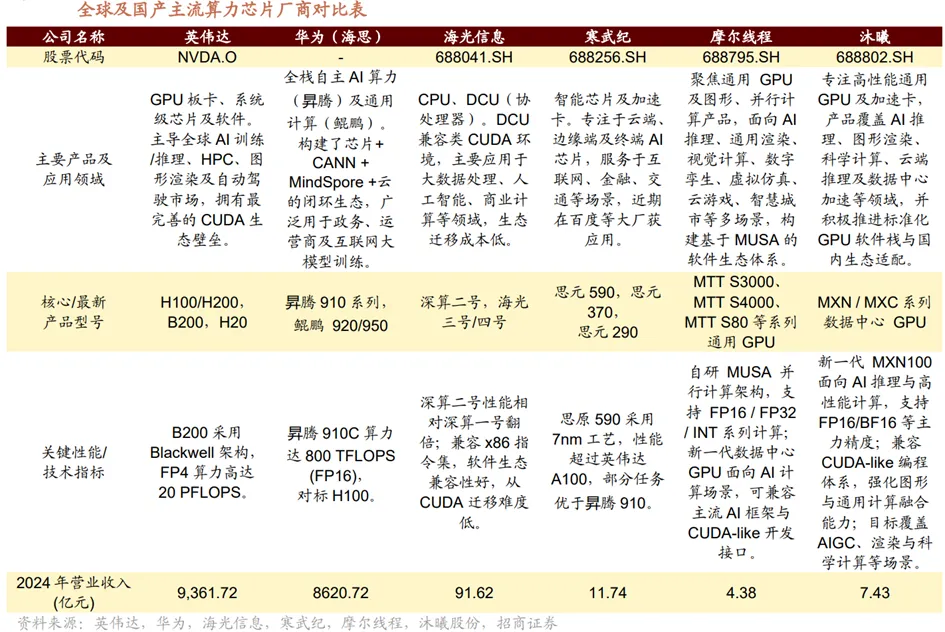
国产算力堆栈的核心支柱为AI加速芯片,其作为算力供给的底层核心硬件,直接决定算力输出效率、成本控制与自主可控水平,是支撑国产算力体系自主化的“压舱石”。国产算力芯片在性能指标上正实现历史性突破,与国际先进产品的技术差距显著缩小。在AI芯片自主化攻坚进程中,华为、海光信息、寒武纪、昆仑芯、摩尔线程等本土高性能AI芯片龙头企业,成为突破核心技术、构建自主可控算力体系的关键载体。
其中,华为昇腾2025Q1推出的910C作为国产高端训练芯片的代表产品,采用中芯国际7nm(N+2)工艺,并基于chiplet架构实现约数百亿量级晶体管集成。在FP16精度下,该芯片的单卡理论峰值算力可达800TFLOPS,性能已接近英伟达于2022年推出的H100芯片的80%。昇腾910C配置64GBHBM2e大容量高带宽内存,带宽可达数TB/s量级,并通过通富微电提供的2.5D封装技术提升HBM堆叠良率至高位区间,有助于增强系统供应稳定性。整体上,昇腾910系列已形成国产高端训练芯片的“标杆级”性能水平。
除华为之外,其他国产厂商亦在高端芯片领域加速突破。寒武纪思元590芯片采用7nm工艺,在百度“文心一言”项目中获得应用,FP32单精度算力达到80TFLOPS,峰值性能远超英伟达2020年推出的A100芯片(19.5TFLOPS)。海光信息的CPU产品凭借其独有的x86成熟生态的兼容,在以自主可控为目标的国产算力市场中已占据重要地位,同时DCU系列基于通用GPGPU架构,在政府、金融、电信等行业实现规模化部署。得益于其CPU+DCU双产品线和成熟的生态兼容性,海光信息已成为国产算力在政企市场的核心供给。摩尔线程则聚焦通用GPU赛道,其基于第四代平湖GPU架构的MTTS5000芯片,FP32算力达32TFLOPS,超越英伟达A100芯片,展现出国产GPU在通用渲染与并行计算领域的跨代提升。截至2025年底,摩尔线程已形成覆盖AI智算、数字孪生、科学计算等领域的多元产品矩阵,新一代架构产品进入研发阶段,同步推进高性能GPU与智算集群前沿技术预研。
值得重视的是国产化供应链架构的变化。江原科技在2025年宣布量产基于国产12nm工艺的全流程自主AI芯片,其设计、代工、封测均基于国内供应链体系完成。尽管12nm与国际先进制程存在代差,该事件依然具有标志性意义:首次验证了AI大算力芯片全国产业链在工程与量产层面的可行性,为未来建立更高国产化率的供应体系提供了路径探索。整体来看,过去一年国产算力芯片的演进已从“单点突破”进入“体系能力增强”阶段。
2.中游:服务器超节点技术突破,国产替代加速推进
服务器作为AI加速芯片的“算力载体与系统协同中枢”,是承接芯片性能、实现算力规模化输出的关键支柱。国产服务器在超节点技术方面实现了从“技术可行”到“商业可用”的关键跨越,国产厂商与国际巨头的技术差距正在快速缩小。中科曙光在2025年11月发布的全球首个单机柜级640卡超节点scaleX640,通过系统级重构实现了革命性突破。该产品采用“一拖二”高密架构设计,单机柜算力密度提升20倍,HBM总容量达81.9TB,较华为昇腾384提升1.7倍。更重要的是,scaleX640基于AI计算开放架构设计,硬件层面适配多品牌加速卡,软件层面兼容主流计算生态,构建了“软硬协同、生态兼容”的国产智算新范式。
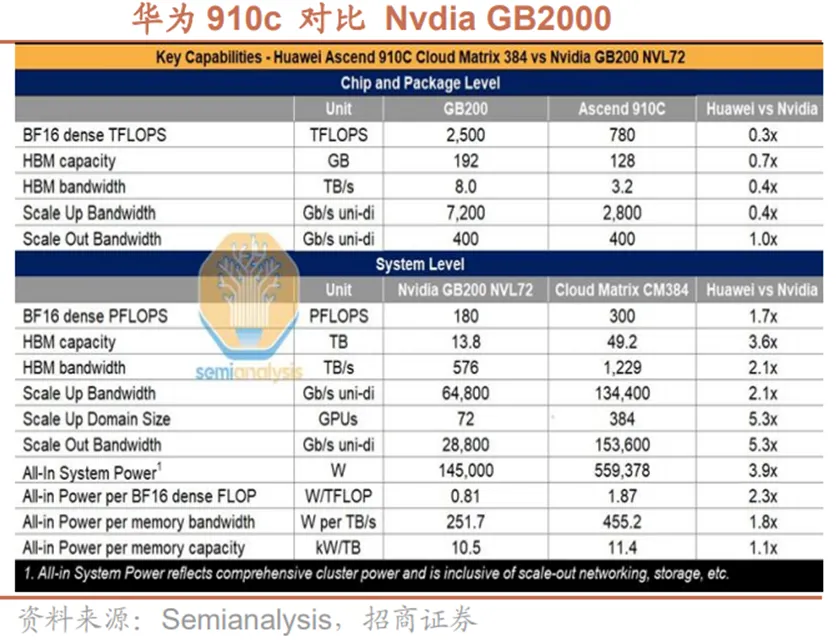
华为在超节点技术方面同样取得重要进展。华为推出的CloudMatrix384超节点集群,通过高效的自研互联架构将数百颗国产芯片的能力整合,不仅成功训练出准万亿参数大模型,更在DeepSeek等模型的实际推理测试中,展现出媲美甚至部分超越英伟达H100集群的系统吞吐量与性能。CloudMatrix384超节点采用全对等互联架构,集成384颗昇腾910C和192颗鲲鹏CPU,通过统一总线实现资源池化。系统级算力为英伟达GB200NVL72的1.7倍,内存容量达3.6倍,内存带宽2.1倍。美国在2025年5月祭出更严厉的出口管制,新规首次将全球任何地方使用华为昇腾910c芯片的行为直接认定为违反其出口管制,旨在全球范围内孤立昇腾硬件、遏制其CANN生态发展。尽管面临全球封锁的风险,昇腾超节点已在中国电信等数据中心实现商用落地,并开始带动国内供应链发展。这标志着全球AI算力竞争已从单点芯片性能转向大规模系统效能、生态构建与产业链能力的全面对抗,华为的发展路径正重塑中美对立下的新算力格局。

阿里云在2025云栖大会上发布的磐久AIInfra2.0AL128超节点服务器,采用面向下一代超大集群的服务架构,重构GPU间互连方式。该产品采用灵活的模块化、多维解耦系统架构,实现CPU节点与GPU节点解耦、GPU节点与ALinkSW节点解耦、算力节点与供电节点解耦,不仅兼容行业主流CPU、GPU、ALinkSW芯片,还支持主力芯片独立演进、CPU与GPU数量的灵活配比。总体来看,超节点技术已经成为弥补国产芯片单点性能差距、支撑算力规模化部署的核心系统级创新载体。
3.下游:数据中心与云服务迎来发展机遇
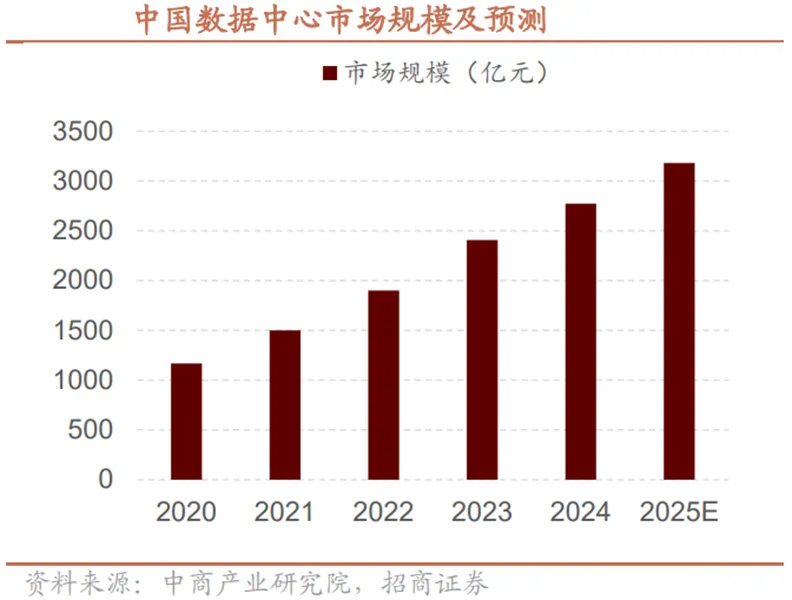
国内数据中心市场呈现“运营商主导、第三方崛起”的分层扩张态势。三大运营商凭借基础设施优势占据近六成市场份额,第三方运营商份额从2021年的39.3%提升至2023年的43.1%,头部企业规模优势持续凸显。“东数西算”工程的推进加速了算力规模化布局,八大枢纽节点总算力突破215EFLOPS,智能算力占比超80%,甘肃庆阳、贵州等核心集群已形成万架机架级部署能力,带动社会投资超万亿元。同时AI算力需求的爆发推动智算中心的建设,据中商产业研究院预测,2025年中国智算中心市场规模将达到1356亿元。国产替代政策下,数据中心硬件自主化率持续提升,为服务器等国产产业链提供广阔落地场景,同时余热回收、可再生能源利用等绿色技术成为新的增长引擎。
国内云服务市场形成阿里云、华为云、腾讯云“三分天下”的稳定格局,合计占据61%以上市场份额,阿里云以33%-34%的占比领跑。云服务市场2025年保持超20%的增速,AI相关收入连续多季度实现三位数增长,运营商云快速崛起,天翼云、移动云跻身IaaS市场前五,其中天翼云政务云市占率达28%,成为政企市场重要力量。从技术能力看,中国云服务商在某些领域已经达到国际先进水平,特别是在AI和大数据处理方面,阿里云的Qwen3-Max模型拥有逾一万亿参数,腾讯云的混元模型系列在多个benchmark测试中取得优异成绩,华为云在全栈AI能力上的长期投入开始显现成效,助推国产算力能力跻身全球前列。
2026年被视为中国国产算力产业链实现闭环发展的关键转折之年,产业将从早期的“单点技术突破”迈向“体系化能力增强”的规模化阶段。在外部技术限制和内部AI需求井喷的“双引擎”驱动下,产业链上游(芯片设计与制造)、中游(服务器与网络)和下游(软件生态与应用)的国产化进程将全面加速,形成相互支持、自我强化的内循环体系。
04
算力芯片制造及市场分析
1.国产算力芯片产能大幅提升
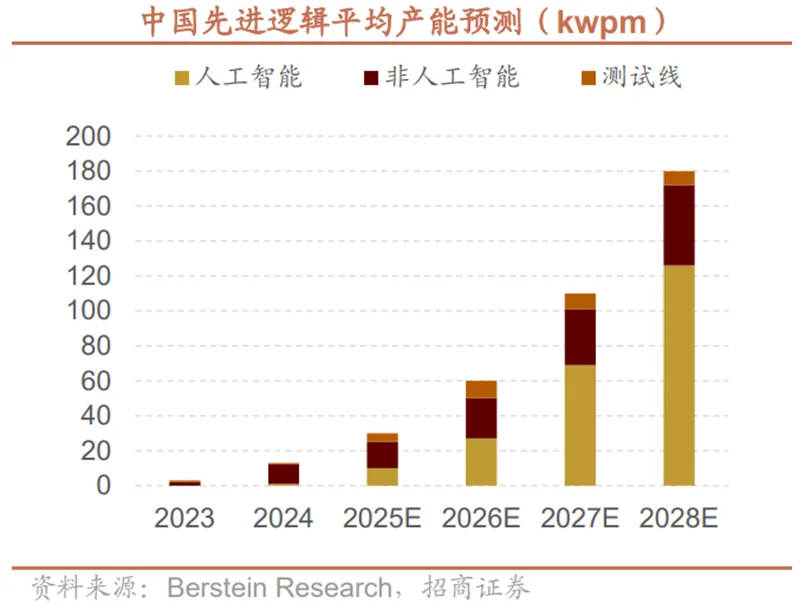
尽管国产芯片设计在性能上实现跨越式跃迁,但目前限制本地AI芯片产量的最大瓶颈在于受限的本地先进逻辑产能。据Berstein Research预测,中国先进逻辑制造能力将在2025-2028年快速扩容,2026年制造端的核心价值正是通过产能提升逐步缓解这一瓶颈,为AI芯片供应构建闭环的物质基础。这一产能增长也将直接作用于AI芯片市场:一方面推动本地AI芯片产量持续攀升,另一方面带动芯片平均销售价格逐步下行,有效改善AI芯片的供应与成本问题。
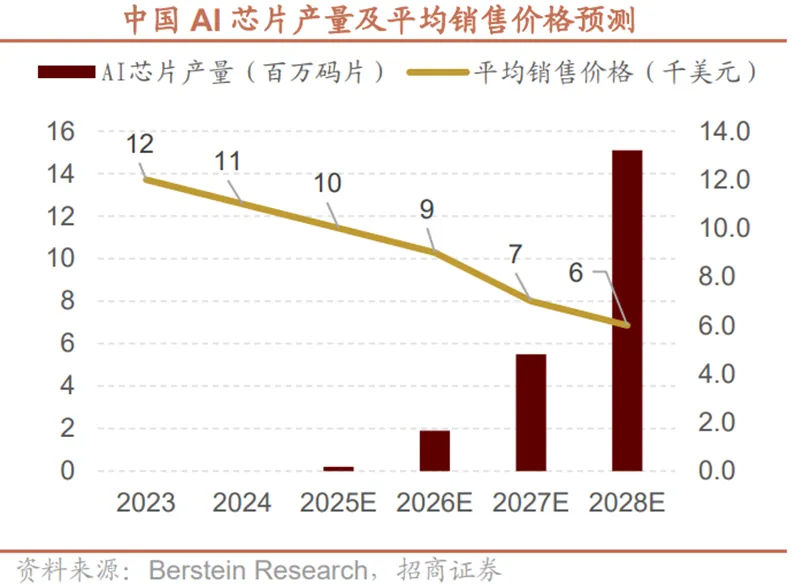
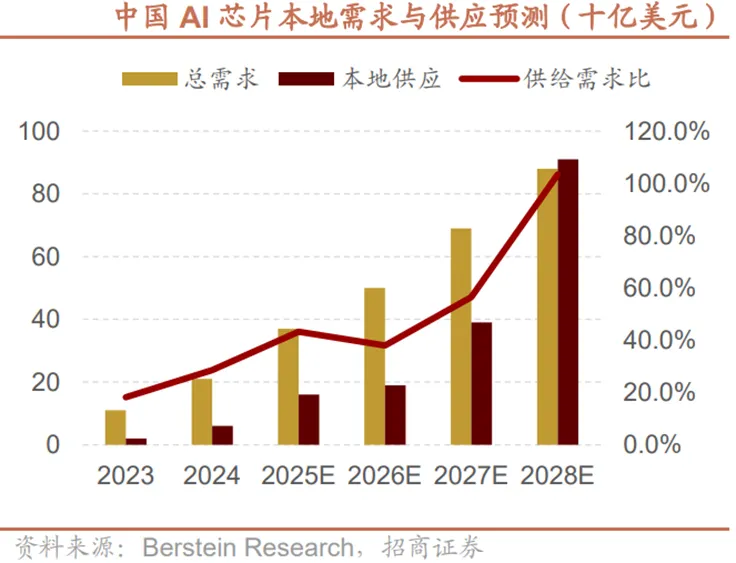
从中国AI芯片的本地供需与市场格局来看,需求与供应的双向扩容中,本土产能的崛起尤为突出。2023-2028年,AI芯片总需求从11亿美元增长至88亿美元,但本地供应的增幅更显著,供应对需求的覆盖比例也从20%逐步提升。尽管2026-2027年仍处于供应瓶颈阶段,但2028年覆盖比例将达到104%,实现供需平衡甚至小幅过剩。这一变化背后是本土供应商的快速替代:2023年本土供应商在国内AI芯片市场的销售额占比仅19%,而到2028年国产占比将升至93%,2025-2028年本土AI芯片销售额的复合年增长率高达74%;反观全球供应商,其在华销售额的复合增长率则为-17%,本土供应链已逐步完成对海外供应商的市场替代,构建起自主可控的供应体系。
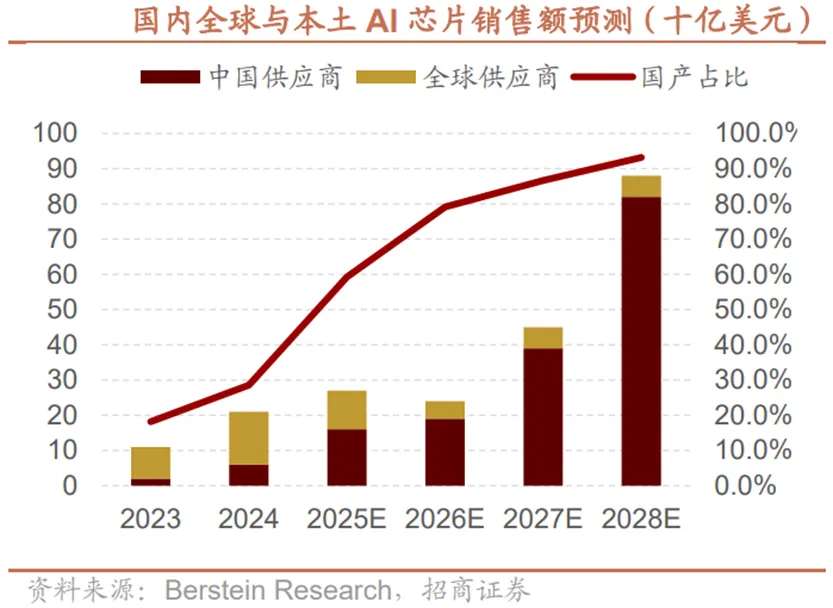
2.国产算力优势将持续释放
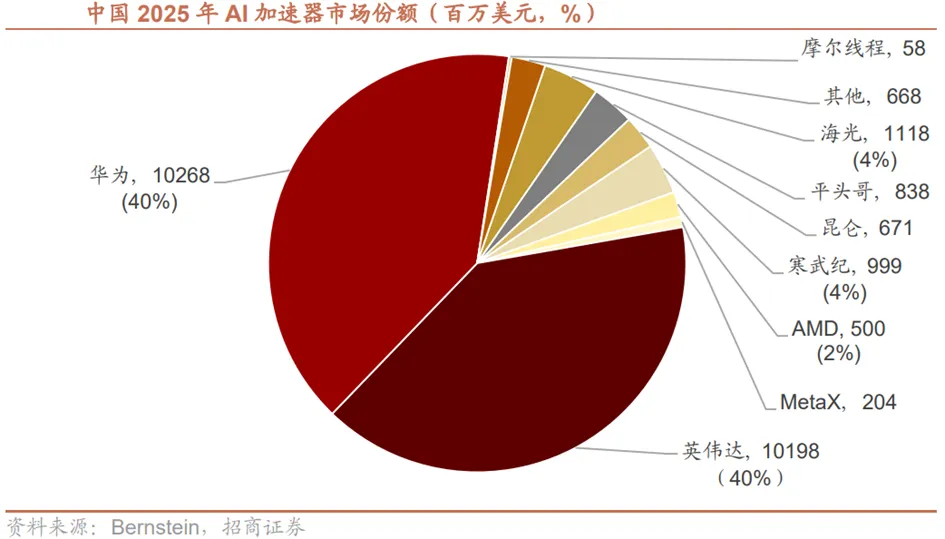
2026年,国产算力的市场份额将实现历史性突破,华为与英伟达在中国AI芯片市场形成的双雄对峙格局将被彻底改写。根据Bernstein预测,英伟达在中国AI芯片市场的份额将从当前的40%暴跌至8%,而华为将占据50%的市场份额,AMD以12%位列第二,寒武纪以9%位列第三。这一剧烈的市场格局变化,直观反映出国产算力在技术、生态等维度优势的持续释放。
05
算力芯片竞争格局及国产替代
1.竞争格局
英伟达处于全球GPU市场领先地位。英伟达(NVIDIA)总部位于美国加利福尼亚州,自1993年成立起就专注于GPU的设计开发,形成了强大的实力和竞争壁垒。根据泡泡网转载的Jon Peddie Research的报道,在PC(个人电脑)领域,2025年二季度英伟达独立显卡的市场份额达到94%,断崖式领先于AMD及其他厂商。随着大模型训练推理需求的兴起,英伟达凭借领先的GPU产品和生态在AI领域进一步称霸市场。
在数据中心GPU市场,英伟达一家独大且保持高速增长。据蓝鲸科技报导,在以GPU芯片为主导的AI数据中心市场,英伟达占据了90%以上的市场份额。在过去四个财季中,英伟达的总收入从Q4FY25的393.3亿美元上涨到Q3FY26(截至2025年10月26日)的570.1亿美元,Q3同比提升62.5%。其中,数据中心业务收入从355.8亿美元提升至512.2亿美元,Q3同比增长约66.4%,是整体业务增长的核心驱动力。按季度划分,数据中心业务在总收入中的占比分别约为90.5%、88.8%、87.9%、89.8%,显现了市场对于数据中心GPU产品有着强盛需求。此外,英伟达在数据中心方面仍有充足订单。公司首席财务官(CFO)科莱特·克雷斯(Colette Kress)披露了一组令人瞩目的数据:目前可见至2026年底,仅Blackwell和Rubin两大AI加速平台就将为公司带来约5000亿美元的可见收入。
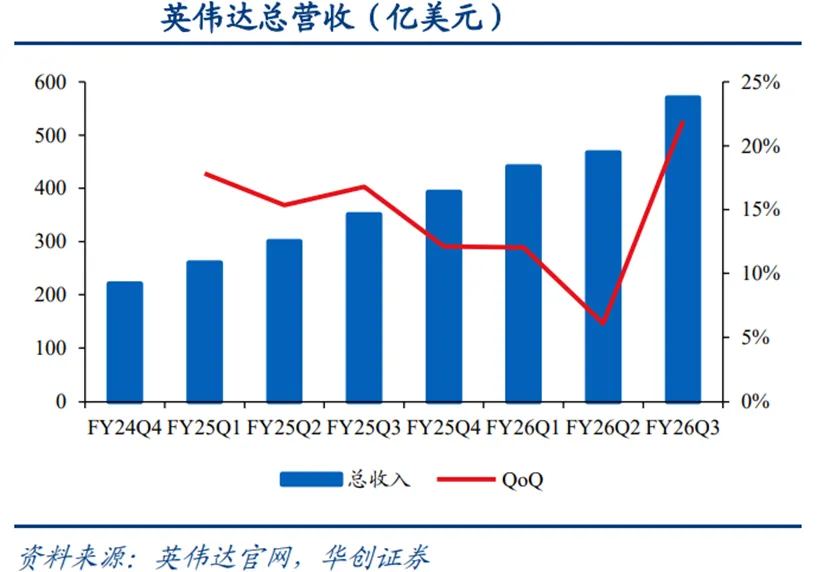
英伟达GPU产品AI智算性能不断革新,GB300专为推理任务打造。A100兼具大模型推理和训练性能,在此基础上,H系列训练和推理计算性能均大幅提升,GB系列进一步提升。据英伟达官网,GB200的LLM推理性能是H100的30倍,训练性能是H100的4倍,此外还通过液冷式机柜设计使得节能效果是H100的25倍。英伟达GB300采用NVIDIABlackwellUltraGPU,相较于NVIDIABlackwellGPU,其密集FP4Tensor核心FLOPS高出1.5倍,注意力效能高出2倍,专为测试阶段扩展推理与AI推理任务而打造。
2.国产替代
(1)美国多次修订出口规则管制范围,国产算力自主可控迫在眉睫
近年来,美国多次修订出口管制规则,旨在限制中国从美国进口先进的AI处理器用于人工智能的训练。虽然近日特朗普允许英伟达向中国出售H200,但一方面更高阶GB200、GB300仍存限制,另一方面多次修订的出口管制范围也加强了国产GPU实现自主可控的紧迫程度。
(2)国家政府立足发展需求,高度支持国产算力产业发展
2025年8月,国务院出台《关于深入实施“人工智能+”行动的意见》,其中提出“应强化智能算力统筹,支持人工智能芯片攻坚创新与使能软件生态培育,加快超大规模智算集群技术突破和工程落地”。同月,在《电子信息制造业2025-2026年稳增长行动方案》中,两部门提出“加强CPU、高性能人工智能服务器、软硬件协同等攻关力度,开展人工智能芯片与大模型适应性测试。适度超前部署新型基础设施建设,提升各地已建基础设施运营管理水平,强化服务器、芯片和关键模块的兼容适配”,并从供应链政策支持、加强基础技术研究、促进国际合作、构筑人才队伍等角度为先进算力产业助力,继承发展了既往算力领域的积极政策。持续利好的政策为国产算力实现自主可控创造良好条件。
06
算力芯片国产替代进展
AI热潮下,算力芯片国产替代如火如荼。美国不断升级对华限制导致英伟达高端GPU在中国市场供应几乎被完全切断。在市场空缺和国家战略的双重刺激下,国产GPU企业迎来历史性发展机遇。当前,寒武纪、海光信息、摩尔线程、沐曦股份等国内厂商推出多款AI智算芯片产品,并逐步追赶国际领先标准。
1.华为昇腾:自研达芬奇构架,昇腾910持续更新
华为持续研发昇腾系列商用GPU产品,力争自主可控。华为全资控股的子公司海思科技专门从事半导体及器件设计,2018年华为发布昇腾310(12nm,终端低功耗,最大功耗8W)和昇腾910(7nm,云端高算力,可组成Ascend集群)两款AI芯片,均基于达芬奇架构。后续的昇腾910B基于7nm+EUV工艺与32核自研架构,支撑千亿参数大模型训练,已实现规模化落地。基于华为昇腾系列AI处理器和基础软件,华为构建Atlas人工智能计算解决方案,包括Atlas系列模块、板卡、小站、服务器、集群等丰富的产品形态,打造面向“端、边、云”的全场景AI基础设施方案,覆盖深度学习领域推理和训练全流程。

华为在2025年9月全联接大会上明确披露了昇腾系列AI芯片的三年规划,2026年将推出两款重磅产品:昇腾950PR计划于第一季度推出,昇腾950DT计划于第四季度推出。昇腾950PR将成为首款采用华为自研高带宽内存(HBM)技术的昇腾芯片,算力达到1PFLOPS,支持FP8 /MXFP8 /HIF8 /MXFP4等低精度数据格式。该芯片的推出将显著提升华为在高端AI训练市场的竞争力,特别是在大模型训练场景中有望实现与英伟达产品的正面竞争。昇腾950DT的算力更是高达2PFLOPS,配备144GB显存和4TB/s带宽,专门针对大模型解码场景优化。
2.百度:将推出昆仑芯M100芯片与天池256/512超节点两大重磅硬件
百度在2025年11月百度世界大会上同步披露了昆仑芯新一代产品规划,2026年将推出昆仑芯M100芯片与天池256/512超节点两大重磅硬件。昆仑芯M100专为大规模推理场景量身优化,以极致性价比为核心卖点,可高效支撑多模态大模型的推理部署需求。该芯片与百度文心5.0大模型深度协同,能充分发挥MoE架构适配优势,助力企业降低AI推理的单位算力成本。同步推出的天池256和512超节点,其中单个天池512超节点即可完成万亿参数模型训练,依托百度百舸4.0平台的高性能网络与分布式优化技术,集群有效训练率可达98%。这些产品的落地将进一步强化百度“芯片-大模型-集群”的全栈优势,其积累的数万卡部署经验也将为超大规模算力集群的稳定运行提供保障。
3.寒武纪:聚焦人工智能,MLU590表现亮眼
寒武纪围绕人工智能发展四大产品线。寒武纪成立于2016年,专注于人工智能芯片及基础系统软件的研发设计,形成云端、边缘端、IP授权及软件、智能计算集群系统核心业务布局。近年公司云端产品线(包括智能芯片、加速卡及训练整机)持续深化与互联网及大模型头部企业的技术合作,产品在自然语言处理场景实现批量出货。边缘端产品聚焦智能制造、智能驾驶等低延时场景,IP授权及软件平台提供跨云边端一体化开发工具,智能计算集群系统为AI应用部署提供整体解决方案。
AI芯片产品矩阵更新引领国内行业突破。据北方算网公众号数据,思元590基于7nm工艺打造,支持云端和端侧应用,具备314TFLOPS(FP16)的峰值算力、80GB显存和高达2TB/s的带宽。在分布式计算和大规模模型训练任务中表现尤为突出。其架构具有端云一体的可扩展性,以TP(Tensor Processor)和MTP(Multi Tensor Processor)作为最小扩展单元:TP适用于单个IPU核心,适合低功耗的端侧应用;MTP则由多个IPU核心组成的Cluster,面向高性能的云端任务,可通过单机多卡或多机多卡的MLU-Link集群实现并行加速,满足云端AI计算和分布式任务的多样化需求。MLU590的设计在性能、灵活性和扩展性之间达到了良好平衡,是AI训练和推理的重要选择。为满足更多元化的市场需求,寒武纪在2024年11月推出MLU370-X4,主打高性价比AI加速方案。相比MLU590,它的FP16算力为96TFLOPS,配备24GBLPDDR5内存,内存带宽307.2GB/s,最大设计功耗150W。这款新品在延续寒武纪技术优势的基础上,以更低功耗和适中性能,为中低端AI推理任务提供了新选择,拓宽了寒武纪产品的应用场景。

4.海光信息:CPU、DCU双线发展,深算三号进展顺利
海光业务以商用CPU和DCU为主。海光信息成立于2014年,主营业务是研发、设计和销售应用于服务器、工作站等计算、存储设备中的高端处理器。公司的产品包括海光通用处理器(CPU)和海光协处理器(DCU,GPGPU的一种)。面向企业计算、云计算数据中心、大数据分析、人工智能、边缘计算等众多领域,海光信息提供多种形态的海光处理器芯片,满足互联网、电信、金融、交通、能源、中小企业等行业的广泛应用需求。
公司DCU采用通用并行计算架构,能够较好地适配、适应国际主流商业计算软件和人工智能软件。海光DCU基于通用图形处理器设计理念,具有全精度支撑能力,按照代际进行升级迭代,每代际产品细分为8000系列的各个型号。公司核心产品包括深算一号、深算二号和深算三号。目前深算三号产品进展顺利,海光DCU产品已与互联网、金融、电信等各大行业、企业用户进行了广泛适配,适配效果较好,能够支持人工智能、大数据、云计算等领域的发展。配套的开发工具套件DTK、人工智能基础软件栈DAS及应用平台DAP形成的“三驾马车”,可全面覆盖从十亿级到千亿级模型的训练与推理需求,为各行业AI创新提供一体化支撑。其中,海光DCU具备自主研发的开发工具套件DTK,是目前国内最为完备的生态之一,减少了应用迁移难度。完善的统一底层硬件驱动平台,能够适配不同API接口和编译器,并支持常见的函数库,在百度、阿里等头部互联网厂商得到认证,并推出联合方案,打造全国产软硬件一体全栈AI基础设施。
针对AI行业应用场景,海光DCU已形成多元化落地成果。在科研领域,支撑全球首个L2级高能物理大模型“溪悟”及科研智能体系统“赛博士”实现世界领先的数据分析效率;在医疗领域,与卫宁健康等伙伴合作的医疗AI解决方案已在全国30多个项目落地,为临床诊断、基因分析等提供高效算力支持;在天文领域,处理中国天眼FAST的海量观测数据时,计算效率较传统CPU提升超百倍,碳星识别等场景性能表现突出。

海光信息在“销售一代、验证一代、研发一代”的产品策略下,明确2026年将量产新一代DCU产品神算三号。该芯片聚焦大模型训练核心场景,创新采用FP8与FP16混合精度计算方案,相比前代产品能效比提升40%,可高效支撑从十亿级到千亿级模型的全流程算力需求。神算三号延续了海光DCU的核心生态优势,兼容x86指令集与类CUDA环境,对标CUDA的算子覆盖度超99%,能实现现有AI系统的无感迁移,大幅降低企业国产化替代成本。依托CPU+DCU双芯协同架构,该芯片已在智能电网、科研计算等场景完成验证,其在南方电网实时仿真平台中实现了300%的算力效率提升。神算三号的量产将进一步完善海光在AI训练与推理领域的产品布局,为金融、能源、科研等行业的智能化转型提供安全可信的国产算力支撑。
5.摩尔线程:拥有完整GPU产品矩阵,最新架构“平湖”功能强大
摩尔线程是拥有完整GPU产品矩阵和解决方案的供应商。摩尔线程成立于2020年,以自主研发的全功能GPU为核心,自建MUSA架构,致力于向全球提供加速计算的基础设施和一站式解决方案。公司已成功推出四代GPU架构,并形成了以大模型智算加速卡MTTS4000、大模型训推一体机MCCXD800X1、专业视觉加速卡MTTX300等产品为代表的多元计算加速产品矩阵,产品线涵盖政务与企业级智能计算、数据中心及消费级终端市场。
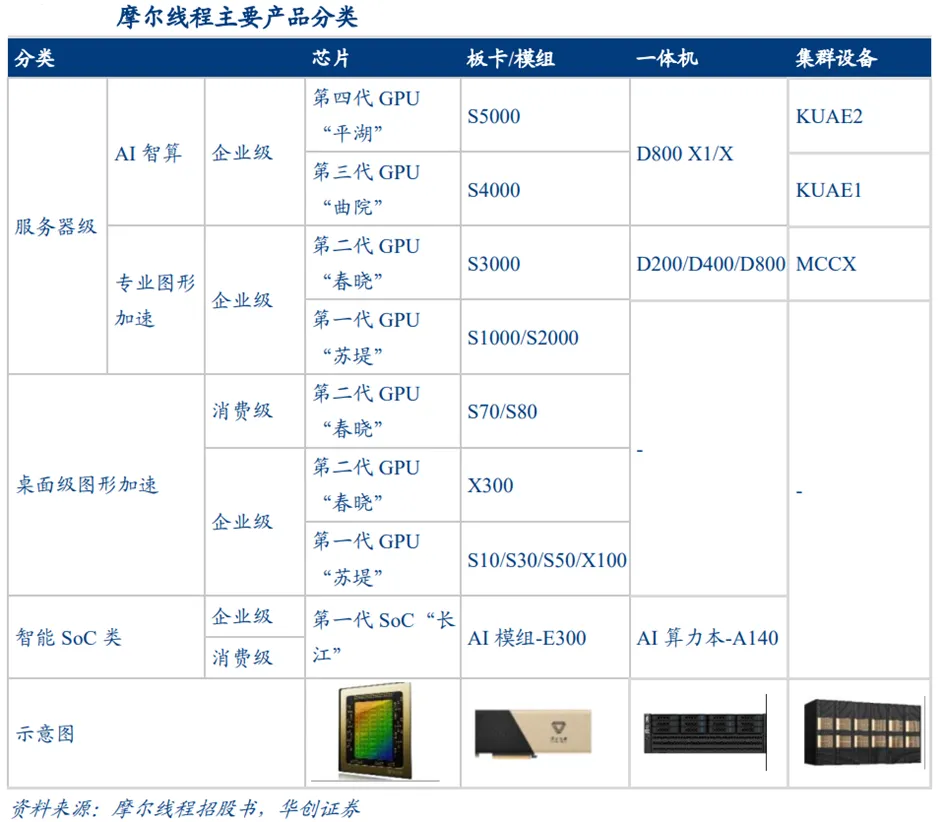
摩尔线程最新芯片架构“平湖”AI智算性能显著提升。2024年摩尔线程推出第四代芯片架构“平湖”,最大频率提升至2.0GHz,Tensor核心数量升级为512个,增加了FP8精度支持,大幅提升AI算力。最大显存容量80G,支持更训练更复杂的模型。使用自研MTCodecGen3编解码器,AI视觉处理编解码效率提升。片间互联带宽800GB/s,摩尔线程基于该芯片支撑面向DeepSeek类前沿大模型预训练的万卡集群智算中心解决方案。

6.沐曦股份:打造全栈GPU芯片产品,曦云C500已实现量产
沐曦股份是拥有全栈开发能力的GPU供应商。沐曦股份成立于2020年,致力于自主研发全栈高性能GPU芯片及计算平台,主营业务是研发、设计和销售全栈GPU产品,并围绕GPU芯片提供配套的软件栈与计算平台。公司产品采用自主研发的GPUIP和指令集、统一的GPU计算和渲染架构,形成了由用于AI智算的曦思N系列,用于推训一体和通用计算的曦云C系列,以及用于图形渲染的曦彩G系列构成的GPU产品体系和自主开放的软件生态,以满足“高能效”和“高通用性”的算力需求。公司产品涵盖了计算(包括训练、推理、通用计算)和渲染的全场景,并已实现多款高性能GPU产品的量产销售。

公司曦云C500适用于大模型训练及推理任务,已实现量产。曦云C500采用公司自研的XCORE1.0架构及指令集,面向云端人工智能训练与推理、通用计算、AIforScience等计算任务。芯片拥有标量、矢量和张量计算单元,支持多种混合精度计算;采用HBM2e显存,显存容量64GB;支持卡间高速互连。基于MetaXLink互连技术,公司的单颗芯片产品拥有7个高速MetaXLink互连接口,具备超多卡互连能力,支持千亿参数以上规模AI大模型训练算力集群建设。自研MXMACA软件栈适配主流算法框架、运算库、通信库、操作系统、编程语言、调试和运维管理工具等,编程接口在API层面实现了对CUDA生态的高度兼容。

沐曦股份的下一代GPU产品曦云C700系列基于国产供应链打造,性能对标英伟达H100,预计2026年下半年流片。该系列产品将采用更先进的制程工艺和架构设计,有望在特定应用场景实现对国际产品的超越。
这种差异化的多头并进策略,确保了国产算力体系在面对复杂的市场需求时,具有更强的整体韧性。设计端性能的确定性突破,反过来对本土先进逻辑产能形成了巨大的、确定的商业拉动。
07
算力芯片国内相关公司
1.寒武纪
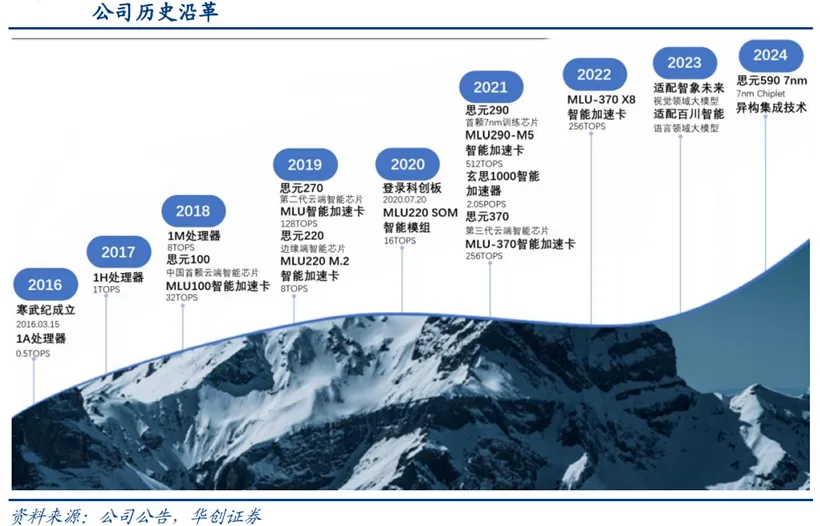
专注AI芯片研发,我国AI芯片领域领军企业之一。寒武纪成立于2016年,专注于人工智能芯片产品的研发与技术创新,致力于打造人工智能领域的核心处理器芯片。公司始终围绕“云-边-端”全场景战略持续开展技术迭代与产品演进,已完成多代架构升级,具体来看:2016-2018年,先后推出1A/1H/1M处理器及思元100系列芯片,初步构建云端与边缘端产品体系;2019年,推出第二代云端芯片思元270,并于2021年科创板上市后发布思元290训练芯片及玄思1000加速器。2021年,实现思元370量产,同步推出MLU370系列加速卡,完成训练-推理一体化产品布局。2022-2024年,MLU370-X8及思元590芯片已与智象未来、百川智能等大模型客户完成全面适配,进入生成式AI算力供应链。当前,寒武纪产品广泛应用于服务器厂商和产业公司,面向互联网、金融、交通、能源、电力和制造等领域的复杂AI应用场景提供充裕算力,推动人工智能赋能产业升级。
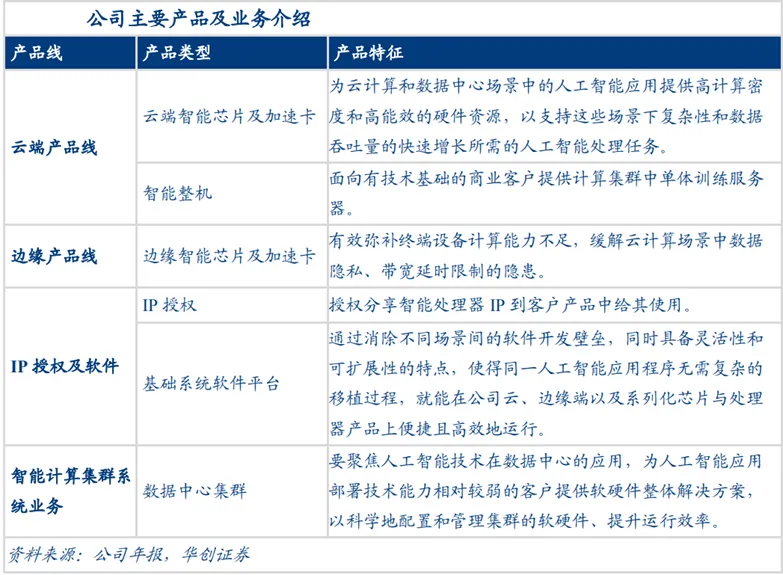
产品矩阵完善,提供云边端一体、软硬件协同的人工智能综合解决方案。公司主要产品线包括云端产品线、边缘产品线、IP授权及软件。在云端产品方面,寒武纪推出思元370芯片、加速卡及训练整机,凭借支持多数据位宽,超大容量和低功耗特点,为云服务商提供强大算力支持;在边缘端产品方面,寒武纪推出了思元220边缘计算模组,有效处理本地数据,减少延迟,在物联网和智慧城市场景中广受好评。软件侧,公司提供IP授权及软件生态配套研发。硬件侧,公司思元系列产品覆盖AI算力行业的计算集群、自动驾驶、边缘计算和AIOT设备全领域。近年来,公司积极拥抱生成式AI浪潮。2023年,公司从底层硬件架构出发,针对自然语言处理、视频图像生成等软件使用重点场景进行优化,提升产品在编程开发的灵活性、易用性、性能、能耗、面积等方面的竞争力。
2.海光信息
2025年12月17-19日,光合组织2025人工智能创新大会在江苏昆山成功举办。此次大会以“智算无界、光合共生”为主题,聚焦AI计算开放架构,旨在推动中国AI计算产业的协同创新与生态共建。海光信息在会上正式发布“双芯战略”,宣布以“海光DCU+海光CPU”为核心,全面升级系统互联与软件生态体系。
战略定位跃迁:从替代到平台,构筑异构算力底座。公司凭借“C86+GPGPU”构建了兼容主流生态的双芯产品矩阵,在CPU产品基础上,公司进一步布局加速器产品与相关软件生态,异构算力平台能力持续增强。这一战略升级通过通用计算与AI加速的深度协同,更高效地承接从大模型训练到行业AI落地的多样化需求,并以系统级工程化能力构筑差异化壁垒。
硬件生态开放:HSL规范推动国产算力标准化与规模化。新发布的HSL1.0互联规范是打通国产算力生态的关键一步。该规范提供了从总线协议、IP设计到指令集的全栈定义,旨在实现海光CPU与多元AI芯片的紧耦合互联,显著降低异构集成的复杂度和开发门槛。其开放策略有望吸引外设、OEM及系统厂商共建统一生态,为国产高性能计算集群的规模化复制与部署提供基础“高速路网”。
软件生态开源:构建“中国版CUDA”,降低应用迁移成本。公司通过全面开放DTK、DAS、DAP三层软件栈,致力于打造开放统一的“中国版CUDA”生态。这一体系覆盖了从底层异构编程、算子优化到上层应用使能的全链路,其核心目的在于显著降低开发者的迁移与适配成本,截至目前,海光DCU已在20多个关键行业、300+应用场景实现广泛落地,将有效增强生态粘性,加速国产AI应用从“可用”到“好用”的规模化落地进程。依托“DCU+CPU”双芯协同与HSL+软件栈开放战略,海光信息正由芯片厂商向平台型国产算力核心枢纽升级,AI高景气与“十五五”战略有望放大其成长确定性。
3.摩尔线程
公司是国内唯一实现全功能GPU量产量销的厂商,覆盖芯片、板卡、集群及软件生态全链条,产品矩阵涵盖AI智算、专业图形、桌面级GPU与智能SoC四大类。其中AI智算板卡与集群为公司核心营收来源。公司25年前三季度实现营收7.85亿元,同增181.99%。25前三季度研发费用支出为8.61亿元,同增4.66%。
AI时代驱动GPU需求快速扩张,国产替代进入加速窗口期。据弗若斯特沙利文预测,2024年全球GPU市场规模超万亿元,预计2025–2029年CAGR有望达24.5%。中国市场成长更快,市场规模将从2024年的1,425亿元跃升至2029年的13,368亿元,2025–2029年CAGR高达53.7%,国产GPU厂商有望深度受益。全球市场由英伟达(全功能GPU)、AMD(GPGPU)长期主导,自23年起美国逐渐升级对中国的AI芯片禁令,公司作为国内稀缺的全功能GPU厂商,在硬件、生态与集群交付方面持续突破,有望成为国产GPU加速替代的重要力量。25年上半年公司营收超95%由AI智算业务贡献,同时境内营收占比超99%。
IPO募资推进自主可控新品研发,自主架构、软硬一体布局构筑护城河。根据Wind的数据,公司于2025年11月发行7000万股,发行价114.28元,预计募集资金84.24亿元。资金主要投向新一代自主可控AI训推一体芯片研发项目、新一代自主可控图形芯片研发项目、新一代自主可控AISoC芯片研发项目以及补充流动资金,持续的高强度研发投入将增强公司的产品迭代和对客户需求的满足能力,进一步巩固长期竞争优势。
4.沐曦股份
快速崛起的国产高性能通用GPU领军企业。沐曦股份成立于2020年,是国内领先的高性能通用GPU芯片及计算平台提供商,主营业务涵盖GPU芯片设计、系统平台开发及配套软件生态建设。公司凭借自研XCORE架构与MetaXLink高速互连技术,构建了覆盖人工智能训练与推理、通用计算及图形渲染的完整产品矩阵,包括曦云C系列训推一体GPU、曦思N系列推理GPU及曦彩G系列渲染GPU,广泛应用于智算中心、科研机构及工业计算等场景。公司具备千卡集群商业化能力,累计交付超2.5万颗GPU,已实现国产替代突破。我们看好公司:1)受益AI算力需求高速增长带来的通用GPU国产化机遇;2)高端GPU性能持续迭代与CUDA生态兼容加速市场导入。我们预计2025/26/27年公司营收为16.76/28.43/42.28亿元,归母净利润-6.60/-2.15/3.32亿元。采用相对/绝对估值法,我们认为公司上市后6-12个月远期公允价值区间为372–401亿元。
全球高性能计算与智能芯片产业加速成长沐曦股份所处行业为计算机、通信和其他电子设备制造业。据WSTS与中国半导体行业协会数据,全球集成电路市场规模预计将于2025年达到6116亿美元,中国集成电路市场规模2024年约为14313亿元,产业规模将持续扩大。GPU作为智能计算的关键硬件,其应用已从传统图形渲染扩展至人工智能训练与推理、科学计算、工业仿真及数字孪生等高算力场景,据相关研究资料,2024年全球GPU市场规模达774亿美金,中国市场规模约1073亿元,预计2025-2030年全球GPU市场规模CAGR达35.19%,在政策推动与算力需求快速增长背景下,中国GPU产业亦将进入快速发展期。随着AI大模型与智算中心建设加速推进,本土GPU厂商在技术突破与生态兼容方面不断进步,或将受益高端通用GPU国产替代机遇,沐曦等正成为这一新兴赛道的核心力量。
公司:自研XCORE架构+MetaXLink互连打造国产核心竞争优势沐曦股份基于自主设计的XCORE架构与MetaXLink高速互连技术,构建了覆盖AI训练、推理与图形渲染的全栈GPU产品体系。公司核心产品包括曦云C系列训推一体GPU、曦思N系列推理GPU及曦彩G系列图形GPU。其中,曦云C系列面向大模型训练与通用计算场景,具备FP8/FP16混合精度算力及64卡互联能力,性能已进入国内第一梯队;曦思系列聚焦云端与边缘推理,兼顾性能与性价比;曦彩系列则将专注图形渲染及云游戏应用,完善公司在通用GPU领域的布局。公司已率先实现千卡集群的大规模商业化应用,累计交付超2.5万颗GPU,并正积极推进万卡集群的研发与落地。凭借对CUDA生态的高度兼容和完整的软件栈支持,沐曦股份的GPU产品已在智算中心、科研机构及工业仿真等场景实现规模化落地,成为国产高性能GPU自主可控体系的关键推动者。
5.品高股份
品高股份创立于2003年,作为国内专业且最早从事云计算服务的提供商,面向政府、公安、轨道交通、金融、教育等行业提供从IaaS基础设施层、PaaS平台层、DaaS数据层到SaaS软件层的全栈企业级云平台和信息化服务。随着全行业数智化深化发展,公司正在从传统的云计算及大数据为主的产品体系逐步向“云-边-端”协同与自主可控智算软硬一体融合发展迈进。公司以“云数基座平台”为核心战略,聚焦“国产算力生态+特种领域人工智能”双轮驱动,逐步构建起覆盖全栈云服务、云边端协同基座、国产化算力生态的多元化业务体系。
战略入局国产算力芯片领域。近期,品高股份以“4亿元增资+5亿元股权转让”的“产业投资+资本绑定”组合拳,与国内领先算力芯片企业江原科技达成深度战略合作。此次交易形成双向持股闭环——品高股份增资后将成为江原科技第二大股东,江原系通过股权受让成为品高股份第二大股东,双方通过产业端增资与资本端股权转让的双向举措,构建起稳固的协同发展格局。早在2024年9月,品高股份便已投资江原科技,通过近一年半的磨合,完成从芯片适配、软件优化到产品落地的全流程验证。江原科技为国内首个实现大算力芯片境内流片量产的企业,其推出的江原D1芯片率先构建“先进自主设计+先进制造+先进封装”境内流片量产全流程,打造极具性价比的国产算力生态体系,不仅有效填补了国家在人工智能芯片供应链安全方面的战略空白,更以先发优势领跑行业,标志着我国AI算力产业迈入“自主可控+高性能落地”双轮驱动的新阶段。其核心产品江原D1算力芯片,基于12英寸晶圆国产流片工艺,专注AI推理场景。江原科技新一代芯片T800正在加紧研发,预计2026年实现国产流片量产,综合性能直接对标英伟达H800芯片,更加聚焦大模型算力训练集群方案,将进一步填补国产高端算力芯片的空白。T800的主要客户对象为互联网厂商和大型数据中心,品高股份将和江原科技一起实现针对上述互联网厂商和大型数据中心的软硬件配套销售。
智算平台加快落地,助力AI业务形成新增量。品高股份持续加码AI与智能算力领域,发布了Bingo AI Infra品高智能算力调度平台,构建了“算力管理层+模型管理层+应用支撑”的全栈能力体系,具备GPU驱动级切割能力,实现算力资源的统一调度与弹性分配,提升整体算力效率。伴随政策支持AI基础设施建设、下游行业对智能算力需求快速释放,公司AI与智算业务有望成为新一轮增长驱动。Bingo AI Infra在多方面具备行业领先优势:在算力效能优化方面,该平台可通过驱动级GPU切割,实现算力精细化分配与全局池化共享,降低算力闲置,提升硬件利用率,目前该技术正在申请国际和国内专利。在芯片适配与效能方面,平台已适配英伟达、昇腾、江原、沐曦等,支持构建混合异构的AI芯片集群。在私有化部署方面,Bingo AI Infra支持软硬件平台国产自主可控,且已经获得了相关的安全认证及保密认证。公司多年深耕行业私有云兼容,相关产品和技术团队已积累了从AI开发到落地的全流程服务经验,同时支持多租户隔离与国产软硬件兼容,为客户构建自主可控的AI运行体系。目前Bingo AI Infra已经适配在多个大型智算中心。
AI算力一体机介绍:品高股份与江原科技联合推出的“品原AI一体机”产品,面向AI算力国产化需求,实现了“芯片-整机-软件”全链条自主可控的软硬件一体化解决方案。全新品原AI一体机仅需4U机身,即可搭载16张D20芯片,构建单机5P算力,显存容量最高达4T,可直接替代英伟达T4、4090、H20等主流推理芯片。通过江原团队的算子融合技术与品高自研的4D并行调度策略,产品将DeepSeek-R1大模型响应速度提升30%,且单卡功耗使能效比达到主流GPU的2.5倍,实现性能与成本的双重优化,为国产推理芯片的规模化应用提供了成熟方案。该产品广泛应用于特种行业、政务、金融、医疗、交通、制造、低空经济等领域,并支持信创、智算中心等多元化场景。