



一、超节点技术概述
(一)超节点的定义与核心思想
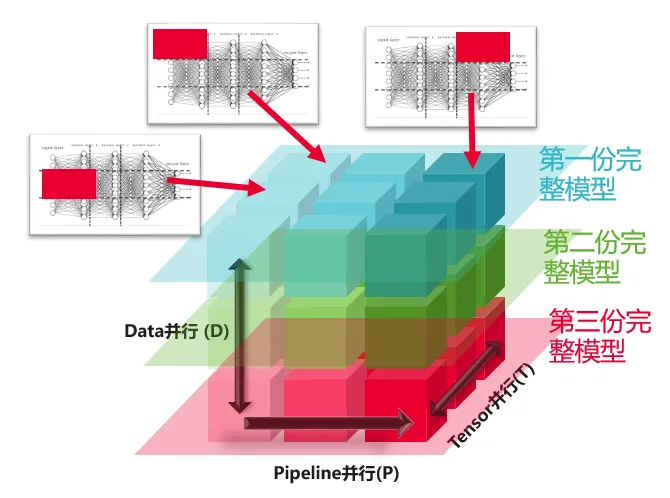

二、超节点技术演进趋势
(一)从“单机多卡”到“机柜即计算机”的架构演进
技术路线正从传统的服务器内多卡互联,向将整个机柜乃至多个机柜整合为单一计算实体的方向演进。例如,英伟达的GB200 NVL72将72颗GPU和36颗CPU集成在一个机柜内;华为的CloudMatrix 384将384颗NPU和192颗CPU封装为“一台计算机”;中科曙光则推出了单机柜集成640卡的超节点scaleX640。
(二)互联技术成为性能决胜关键
超节点的本质是通过极致的网络互联来弥补或发挥单卡算力。因此,高速互联总线与网络的价值凸显。英伟达力推其NVLink 5.0(机柜内带宽1.8 TB/s)和Quantum InfiniBand集群网络;华为依赖其MatrixLink全对等总线;中科曙光则开放了自研的HSL高速互联总线生态。未来,互联路径呈现“柜内全铜、柜间全光”的短期主流,并向共封装光学(CPO)等更前沿技术演进。(三)液冷从“可选项”变为“刚需”
随着单机柜功率密度从传统的10kW级跃升至100kW甚至500 - 600kW,风冷散热已触及物理极限。液冷成为超节点的唯一可行散热方案。冷板式因兼容性好占据主流,浸没式则因极致能效(PUE可低至1.04 - 1.1)在高密度场景占比快速提升。(四)竞争焦点从“单点硬件”转向“系统级效率与生态”
三、主流厂商超节点技术路线深度解析
(一)英伟达超节点技术路线
英伟达的超节点技术路线,是其“AI工厂”愿景的核心工程实现。其本质是通过全栈垂直整合,从最底层的芯片架构创新出发,经由革命性的高速互联技术,最终构建出机柜乃至集群规模的、逻辑统一的超级计算机。1. 芯片架构:从“超级芯片”到“系统级芯片”
Grace Hopper超级芯片:将72核Arm架构的Grace CPU与Hopper架构的H200 GPU通过NVLink - C2C技术封装在一起,CPU - GPU间带宽高达900 GB/s,是PCIe 5.0的7倍。其核心创新在于构建了最高624GB的统一内存池(CPU的480GB LPDDR5X + GPU的144GB HBM3e),允许GPU直接、高速访问全部内存,彻底消除了数据迁移的瓶颈,专为处理TB级数据的AI与HPC工作负载设计。
Blackwell Ultra架构:采用双晶片设计,通过NV - HBI接口连接,提供10 TB/s的内部带宽,作为一个统一的加速器运行。其革命性在于引入了NVFP4(4位浮点)精度格式,在保持模型精度的同时,将内存占用和计算成本降至新低。相比前代Hopper架构,它在AI推理中实现了最高40倍的能效提升,训练性能提升4倍,电力消耗减少75%。
Rubin GPU:在2026年CES上亮相,NVFP4推理性能达50 PFLOPS(是Blackwell的5倍),训练性能35 PFLOPS(3.5倍),HBM4内存带宽22 TB/s(2.8倍),单GPU NVLink互连带宽翻倍至3.6 TB/s。这些提升让单个GPU能处理更多推理任务与更长上下文,从根本上降低对GPU数量的依赖。

2. 系统集成:定义“机柜即计算机”
英伟达将超节点从概念推向工程现实,其核心是GB200 NVL72这一机柜级系统。一个标准机柜内集成了72颗Blackwell Ultra GPU和36颗Grace CPU,系统可提供超过20 TB的HBM3e显存,为万亿参数模型提供充足的“活动空间”。基于Blackwell架构的DGX SuperPOD可实现11.5 ExaFLOPS的FP4精度算力,AI推理性能相比上一代提升70倍。新一代DGX SuperPOD则将Rubin的能力扩展至数据中心级别,由8个Vera Rubin NVL72机架组成,576个GPU通过NVLink 6和Spectrum - X以太网实现无缝协同。3. 液冷方案:混合液冷与开放生态
其高端超节点产品默认采用冷板与浸没式相结合的混合液冷方案。其官方宣称,该方案使Blackwell架构系统的功耗较前代Hopper架构降低高达75%。在HGX平台,合作伙伴提供的液冷方案可对高达 98%的系统热量进行散热,并使用高达40°C 的温水,据称能降低 高达40%的能耗。未来,英伟达可能推动Rubin架构液冷方案向微通道技术(MCCP/MCL)演进。
(二)华为超节点技术路线
华为的超节点技术路线,是一条以全栈自研、系统架构创新和开源开放生态为核心,旨在突破先进制程限制,通过极致集成与软硬件协同实现全局性能最优的独特路径。1. 芯片基石:达芬奇3.0架构与昇腾系列演进
达芬奇3.0架构的核心创新:该架构是昇腾910C及后续芯片的计算核心。其核心是一个专为矩阵运算优化的3D Cube计算单元 (16×16×16阵列),单周期可执行4096次FP16乘加运算。同时,通过 Cube(矩阵)、Vector(向量)、Scalar(标量)计算单元的协同,以及多精度混合计算支持 (INT8/FP16/BF16/FP32),实现了高算力密度与任务灵活性的平衡。
关键芯片规格与定位:昇腾910C(当前主力)采用7nm(N + 2)工艺,双Die封装,集成约530亿晶体管。其FP16算力达800 TFLOPS,INT8算力达512 TOPS,并集成128GB HBM2e内存,带宽3.2 TB/s。华为已公布了清晰的昇腾芯片路线图:将于2026 年一季度推出昇腾950PR ,四季度推出昇腾950DT ,并计划在2027 年底和2028年底陆续推出昇腾960 与昇腾970。这些芯片将为Atlas系列超节点提供源源不断的算力支持。
(三)中科曙光超节点技术路线
中科曙光代表了一条与英伟达“垂直整合”截然不同的技术路径:开源开放与全栈垂直整合相结合。其核心战略是通过构建开放的硬件底座与软件生态,并深度融合从芯片到液冷的全产业链能力,以应对中国在先进制程受限背景下“以规模换性能”的独特发展需求。1. 核心战略:从开放硬件底座到全栈垂直整合
开放兼容的硬件平台基因:曙光XMachine AI服务器系列自诞生起就秉持开放理念。其早期产品采用CPU主板与GPU底板解耦设计,为兼容多种加速卡奠定了硬件基础。至2025年,XMachine三代GPU/DCU通用平台已能支持“一键切换”18种机型,同时适配基于NVLink 5.0的GPU与国产海光深算三号(BW1000)DCU,成为一个真正中立的硬件底座。
全产业链垂直整合的深化:2025年,海光信息(国产DCU设计商)启动对中科曙光的吸收合并,旨在打造 “芯片(海光DCU/CPU) - 服务器(曙光XMachine) - 液冷基础设施(曙光数创) - 算力服务” 的全产业链闭环。这使得曙光在超节点系统级优化上,具备了从芯片级、硬件架构到散热基础设施的深度协同能力。
2. 旗舰产品:scaleX640超节点的工程实现
极致密度与“一拖二”架构:为实现单机柜640张加速卡的部署,曙光采用了创新的高密架构。其核心很可能是基于“一拖二”或类似拓扑,将多个计算节点高度集成,使得算力密度较业界同类产品提升20倍。
液冷散热成为必然选择:如此高的功率密度(单机柜预计可达数百kW)使得传统风冷完全失效。scaleX超集群全面采用液冷设计,其电能利用效率(PUE )可低至1.04,达到业界领先水平。这得益于其全栈液冷技术,不仅覆盖计算服务器,还延伸至ParaStor液冷存储系统,实现“存算一栈式”部署。
系统级扩展:从机柜到集群:如此高的功率密度(单机柜预计可达数百kW)使得传统风冷完全失效。scaleX超集群全面采用液冷设计,其电能利用效率(PUE )可低至1.04,达到业界领先水平。这得益于其全栈液冷技术,不仅覆盖计算服务器,还延伸至ParaStor液冷存储系统,实现“存算一栈式”部署。
3. 相变间接液冷与全栈服务
曙光选择了相变间接液冷作为其高密度算力的核心技术,代表性方案为C7000 - F。其原理是利用环保冷媒在冷板内的相变(沸腾汽化)过程吸收大量潜热,实现高效散热。通过优化冷板内部的微纳米多孔流道,换热热阻降低15%以上,系统温度可降低5℃以上。该方案使用自研的专用环保冷媒,工作压力低(≤0.3MPa),安全性高。
2. 系统架构核心:CloudMatrix超节点与“以网强算”
| 架构层面 | 核心设计 | 技术目标与效果 |
|---|---|---|
| 集成规模 | 将384颗昇腾NPU与192颗鲲鹏CPU通过高速互联封装为一个逻辑统一的超级服务器。 | 实现从“服务器级”到“矩阵级”的资源供给,单节点提供 300 PFlops 的BF16稠密算力。 |
| 互联总线(MatrixLink) | 自研全对等互联总线,通过 3168根光纤连接,实现节点内无阻塞通信。 | 卡间互联带宽高达2.8Tb/s,时延**<200纳秒**,将训练效率提升至单卡性能的90%,通信性能较传统RoCE架构提升 15倍 。 |
| 内存体系(EMS) | 创新弹性内存存储技术,实现显存与算力解耦,支持独立扩容。 | 突破“内存墙”,内存带宽/容量提升2.1倍/3.6倍;降低首Token时延最高80%,提升系统吞吐最高 100%。 |
| 网络扩展 | 双层AI网络:节点内ScaleUp(纳秒级)、节点间ScaleOut(微秒级)。 | 支持将432个超节点级联,构建最高16万卡 的超大规模集群,万卡线性度高达95% 。 |
| MoE亲和设计 | 架构针对混合专家模型优化,支持“一卡一专家”并行。 | 一个CloudMatrix 384节点可支持384个专家并行推理,极大提升MoE模型训练与推理效率。 |
3. 散热刚需:全液冷解决方案与极致PUE
华为的液冷方案以全液冷设计为特征,其核心是自研的液冷热管理控制器(TMU)。TMU采用行业首创的双AC/DC供电架构,实现0毫秒无缝切换,确保供液无波动。其高效板式换热器将冷热流体出口温差(逼近度)压缩至 3℃以内,使一次侧供水温度可提高3–5℃,直接降低制冷系统功耗3%–15% 。结合iCooling@AI能效优化技术,可额外降低 8% - 15%的制冷能耗。华为全液冷方案将数据中心PUE值降至1.1(传统风冷约1.4 +)。在贵安等实际部署中,预计年省电费超2000万元。其散热功耗较风冷下降96%,散热效率提升10倍以上

四、功耗、散热与液冷技术对比
(一)技术路线:从冷板到浸没的多元化演进
英伟达:混合液冷与开放生态。其高端超节点产品默认采用冷板与浸没式相结合的混合液冷方案。其官方宣称,该方案使Blackwell架构系统的功耗较前代Hopper架构降低高达75%。在HGX平台,合作伙伴提供的液冷方案可对高达 98%的系统热量进行散热,并使用高达40°C 的温水,据称能降低 高达40%的能耗。未来,英伟达可能推动Rubin架构液冷方案向微通道技术(MCCP/MCL)演进。
中科曙光:相变间接液冷与全栈服务。曙光选择了相变间接液冷作为其高密度算力的核心技术,代表性方案为C7000 - F。其原理是利用环保冷媒在冷板内的相变(沸腾汽化)过程吸收大量潜热,实现高效散热。通过优化冷板内部的微纳米多孔流道,换热热阻降低15%以上,系统温度可降低5℃以上。该方案使用自研的专用环保冷媒,工作压力低(≤0.3MPa),安全性高。
华为:全液冷设计与预制化交付。华为的液冷方案以全液冷设计为特征,其核心是自研的液冷热管理控制器(TMU)。TMU采用行业首创的双AC/DC供电架构,实现0毫秒无缝切换,确保供液无波动。其高效板式换热器将冷热流体出口温差(逼近度)压缩至 3℃以内,使一次侧供水温度可提高3–5℃,直接降低制冷系统功耗3%–15% 。结合iCooling@AI能效优化技术,可额外降低 8% - 15%的制冷能耗。

(二)能效表现:PUE与TCO的终极较量
极致PUE与节能效果:中科曙光采用浸没相变液冷技术的数据中心可实现极致的PUE值。例如,西部(重庆)科学城先进数据中心及长沙某5A级智算中心的PUE均已降至1.04。在实际改造案例中,如华南理工大学全栈式液冷数据中心,PUE降至1.2以下,在性能提升 100%的同时,电费节省高达60% 。其冷板液冷方案也能将PUE稳定控制在1.15以下。华为的全液冷方案同样表现卓越,可将数据中心PUE值降至1.1。其宣称,全液冷设计能将散热功耗较传统风冷下降 96%。在贵安华为智算中心等实际部署中,PUE 1.1的水平较行业平均1.4预计可实现年节省电费超2000万元。英伟达虽未直接披露其超节点整机柜的PUE值,但通过系统级优化,其Blackwell架构在AI推理场景中实现了最高40倍的能效提升,训练性能提升4倍的同时电力消耗减少75%。其液冷系统的引入也使散热成本降低了35% 。
系统级TCO优势凸显:能效提升直接转化为运营成本(OPEX)的降低,从而在系统级TCO上建立优势。中科曙光通过分析指出,当单机柜功率密度超过10kW时,其相变液冷方案的TCO已低于传统风冷。华为则通过TMU的智能控制和预制化交付,在降低能耗的同时也压缩了部署时间和运维成本。英伟达则在软件层推出 NVIDIA Mission Control,实现AI数据中心运维的自动化,进一步降低长期OPEX。
(三)部署策略与市场适应
英伟达:通过与数据中心运营商(如Equinix)合作,推出 “Instant AI Factory” 托管服务。该服务在全球数据中心部署预配置的、支持液冷的DGX系统,为企业提供开箱即用的AI超算能力,省去了复杂的基础设施规划与建设周期,降低了用户的使用门槛。
华为:强调高可靠与易运维,其TMU控制器所有关键部件采用2N冗余设计,支持热插拔,故障模块可在1分钟内更换。在极端情况下(如系统泄漏),可在5分钟内完成冷却液补充,无需停机,保障了业务连续性。
中科曙光:提出了三种灵活的部署架构:1)泵驱排级架构 ,适用于单机柜 100kW以上的高功率密度场景;2)无泵自循环池级架构,利用重力回流实现“零泵功耗”,在适宜条件下PUE可逼近 1.0;3) 模块化柜级架构,采用“即插即用”设计,部署灵活,可将工期缩短 50%,特别适合快速部署需求。
五、定价策略与总拥有成本(TCO)分析
(一)厂商定价策略与商业模式对比
| 厂商 | 核心定价策略与商业模式 | 目标客户与价值主张 |
|---|---|---|
| 英伟达 (NVIDIA) | 高端硬件溢价 + 软件订阅与服务化:以性能领先的Blackwell架构硬件为基础,通过NVIDIA AI Enterprise软件平台和NIM微服务创造持续收入。推出“Instant AI Factory”托管服务,将重资产投资转化为可订阅的OPEX。 | 追求极致性能与成熟生态的大型云服务商、企业及研究机构。通过“AI工厂即服务”模式,降低客户前期部署门槛和运维复杂度。 |
| 中科曙光 | “液冷即服务”与灵活配置计价:强调从规划设计到智能运维的全生命周期服务。硬件底座采用开放架构,支持按加速卡数量、机柜规格或集群规模进行灵活配置与计价。通过超高密度集成(如scaleX640)和极致能效(PUE低至1.04)来降低单位算力的TCO。 | 对成本敏感、注重长期运营效率的政府、高校、科研机构及大型企业。通过开放生态和模块化方案,提供高性价比的国产算力解决方案。 |
| 华为 | 全栈自研、软硬一体化的解决方案销售:通常以整集群招标、交钥匙工程的形式进行销售,提供从芯片、服务器、液冷到AI框架的全栈能力。软件栈(如CANN、MindSpore)采取开源策略,降低用户生态迁移成本,从而间接优化整体TCO。 | 对自主可控、数据安全有强需求的政府、国企及关键行业客户。通过全栈优化和预制化交付,提供高性能、高可靠且能效卓越的一体化算力底座。 |
(二)TCO构成与关键影响因素分析
散热方案:液冷技术是降低TCO的核心。不同方案对应不同的CAPEX/OPEX结构。冷板式液冷改造成本相对较低,兼容性好,PUE可稳定在1.15以下,是当前大规模部署的主流。相变/浸没式液冷初期投资较高,但能效极致,可实现PUE 低至1.04。中科曙光的数据表明,在高功率密度(>10kW)场景下,其全生命周期TCO已优于风冷。预制化交付能大幅缩短部署周期,降低建设成本和不确定性。
系统级能效:提升有效算力利用率是降低单位计算成本的关键。芯片级能效方面,英伟达Blackwell Ultra在AI推理上实现40倍能效提升,训练功耗降低 75%;华为昇腾910C能效比达2.14 TFLOPS/W。更高的能效直接转化为更低的电费支出。网络内计算方面,英伟达NVSwitch的SHARP技术、华为的全对等互联,能将部分集合通信计算任务卸载到网络,减少GPU空闲等待,提升集群整体计算效率。
运维与资源利用率:智能运维与调度能力直接影响电费和硬件折旧。弹性资源调度方面,中科曙光CloudOPs - AI平台可在2分钟内完成从1000卡到800卡的弹性缩容,实现节能18%。华为通过“训推共池”技术,将集群资源利用率提升 30%。自动化运维方面,英伟达的Mission Control、华为的“1 - 3 - 10”运维标准,能减少人工干预,降低运维人力成本,并提升系统可用性。
六、未来3 - 5年技术路线图与发展目标
(一)英伟达:持续制程微缩与垂直整合深化,定义“AI工厂”标准
芯片与架构路线图:2026年,Rubin架构发布,作为Blackwell的继任者,预计将带来显著的算力提升。与之配套的NVLink 6.0技术将使GPU间互联带宽再次翻倍,达到3.6 TB/s,进一步缓解超大规模集群的通信瓶颈。2027年及以后,遵循其“一年一代架构”的节奏,持续推动制程微缩与芯片设计创新,以维持单芯片性能的绝对领先优势。
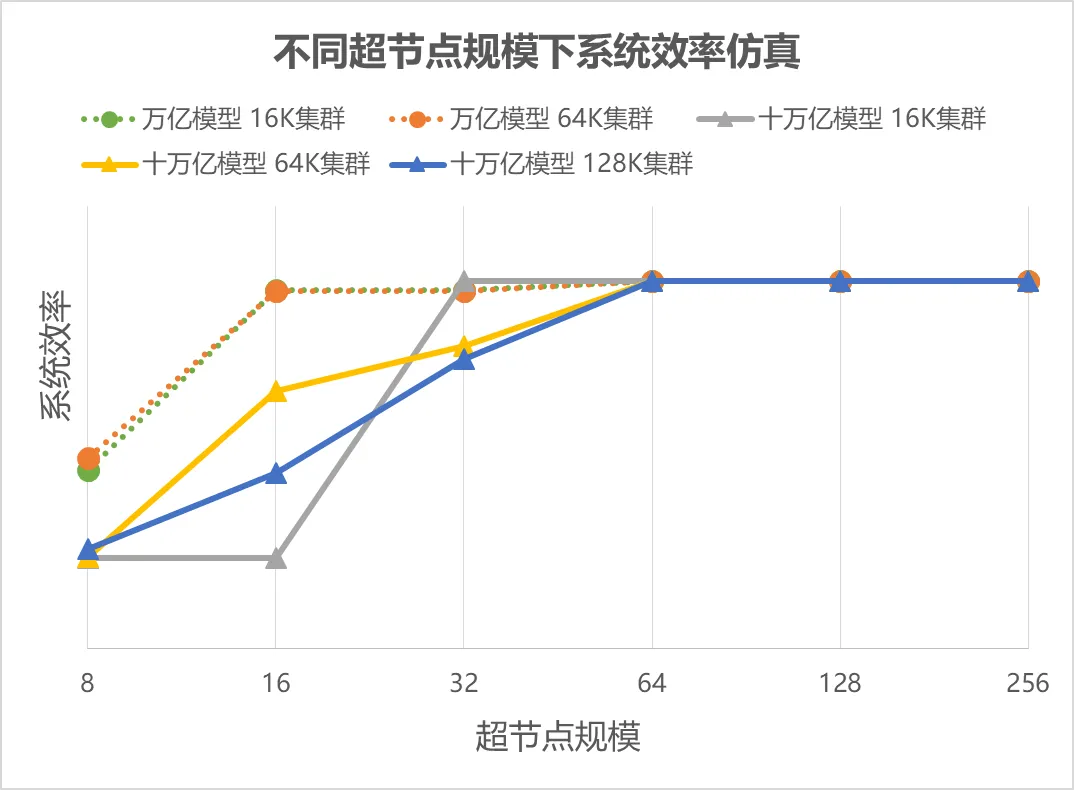
系统与互联路线图:2026年,光互联商用化关键节点。计划推出的Quantum - X Photonics(InfiniBand)与 Spectrum - X Photonics(以太网)交换机将采用共封装光学(CPO)技术,能效提升3.5倍。这将支撑构建非阻塞两级胖树拓扑下连接超过10,000个GPU的超大规模集群,为下一代万亿参数乃至更大规模模型训练铺平道路。
生态战略:通过 “NVLink Fusion” 计划,有限度地向合作伙伴开放NVLink和C2C接口,旨在构建一个以自身为核心的半定制生态联盟,在保持控制力的同时扩大硬件兼容性。
商业模式与发展目标:将“Instant AI Factory”托管服务模式推广至全球核心数据中心区域,由Equinix等合作伙伴运营,为企业提供开箱即用的超节点算力订阅服务,推动企业AI基础设施从CAPEX向OPEX模式转变。维持并扩大在高端AI训练与推理市场的绝对份额,特别是在全球大型云服务商和领先AI研究机构的采购中占据主导。
(二)华为:全栈自研与软件开源,构建替代性生态体系
昇腾芯片路线图:已公布昇腾AI芯片未来三年路线图,将依次推出 Ascend 950系列(包括950PR和950DT)、Ascend 960 和Ascend 970。目标是在制程受限的情况下,通过达芬奇架构优化、Chiplet集成等技术,持续提升单芯片算力、能效和内存带宽,系统性追赶国际先进水平。昇腾950PR计划于2026年一季度推出,昇腾950DT计划于2026年四季度推出。
超节点与集群路线图:在CloudMatrix 384(单节点384 NPU)和Atlas 900 A3 SuperPoD的基础上,计划于2026年第四季度推出支持8192卡的Atlas 950 SuperPoD,并进一步规划15488卡的Atlas 960 SuperPoD(2027年四季度上市)。其目标是实现单集群算力从数百PetaFLOPS向ExaFLOPS(百亿亿次)迈进。

(三)中科曙光:开放生态与系统工程创新,打造国产算力底座
芯片与异构计算路线图:推进海光五号(128核512线程)等下一代CPU的研发与量产,提升通用计算性能。在深算三号(BW1000) 实现全精度算力覆盖的基础上,持续迭代,提升FP16、BF16等AI关键精度下的算力密度与能效比,缩小与国际领先产品的绝对性能代差。
系统与生态路线图:在已实现单机柜640卡 (scaleX640)的基础上,进一步优化供电、散热与互联架构,目标在2026 - 2027年实现单集群万卡级超节点的稳定部署与高效运行,总算力持续提升。大力推广自研的HSL高速互联总线 协议生态,吸引更多国产GPU、加速卡及服务器厂商加入,形成事实上的国产超节点互联标准,打破生态壁垒。
七、市场预测与竞争格局演变研判
(一)市场总规模与核心增长引擎
超节点作为AI算力基础设施的终极形态,其市场规模直接由底层AI算力需求驱动。综合各方预测,其核心构成市场将呈现爆发式增长。算力硬件市场基石稳固,2026年国产卡出货量预计从2025年的100万颗,上升到接近300万颗的量。超节点在国产卡应用比例将占到20%,超1万柜(单机柜芯片用量不等32/128/384甚至万卡机柜)。同时,支撑高密度算力的 高带宽内存(HBM)市场预计在2026年收入翻番,达到约300亿美元。液冷成为确定性高增长赛道,2026年,液冷在AI数据中心的渗透率预计将达到40%(2024年仅为14%)。
(二)技术驱动的市场结构演变
“性能密度”与“能源效率”成为核心采购指标:市场竞争焦点已从单卡算力(TFLOPS)转向系统级效率。客户将综合评估单机柜算力密度(如卡数/柜)、集群线性扩展效率、以及每瓦特算力产出(TFLOPS/W)。英伟达DGX SuperPOD、华为CloudMatrix 384、曙光scaleX640均在极致提升这些指标。液冷渗透率在2026年突破40%并持续向更高水平迈进,正是这一趋势的直接体现。
国产化路径催生独特市场逻辑—— “以规模换性能” :在单芯片制程受限的背景下,中国头部厂商选择了通过超高密度集成和系统架构创新来追赶整体算力。这导致了一个关键市场预测:到2027年,在实现同等算力条件下,国产超节点所需的加速卡数量预计将达到海外方案的8.5倍。这意味着,与“量”(GPU/DCU、交换芯片)和“能源”(电源、液冷)相关的产业链环节,在中国市场将面临更陡峭的需求曲线。
(三)竞争格局的三条路径演化
| 竞争维度 | 英伟达(垂直整合) | 华为(全栈自研 + 开源开放) | 中科曙光(开放硬件底座 + 垂直整合) | 其他力量 |
|---|---|---|---|---|
| 核心战略 | 通过NVLink/CUDA生态实现软硬件深度锁定,维持性能与溢价优势。 | 通过全栈自研掌控核心技术,并通过开源CANN、MindSpore构建替代生态,实现国内市场主导。 | 通过开放HSL总线等硬件接口,聚合国产芯片与服务器生态,提供“一站式”算力解决方案。 | UEC/UALink联盟推动开放标准;云厂商(阿里、腾讯)自研超节点;专业AI芯片公司寻求生态合作。 |
| 市场地位 | 全球性能标杆与市场领导者,但在中国市场受地缘政治影响。 | 在中国国产开放生态中占据80 - 90%的市场份额,是国产替代的绝对主力。 | 国内“国家队”代表,通过开放架构整合产业链,在政府、科研及关键行业市场优势显著。 | 在特定场景(如互联网公司内部)、细分市场(如边缘推理)或作为生态补充者存在。 |
| 未来挑战 | 封闭生态面临开放联盟挑战;ASIC(如谷歌TPU)在能效与成本上构成潜在威胁。 | 如何将国内生态优势转化为全球竞争力;持续应对供应链与技术封锁压力。 | 如何协调开放生态与自身商业利益;在极致性能上追赶头部厂商。 | 生态碎片化;在性能与规模上难以与头部厂商抗衡。 |
当我们谈论超节点竞争时,我们实际上在讨论下一代AI算力基础设施的主导权归属。这场竞争早已超越了单纯的产品比拼,它已经成为AI时代的“光刻机”——一个决定产业命运的战略制高点。它的价值不仅仅在于支撑当前大模型的训练,更在于为未来十年的AI研发定义了效率上限与成本结构。
在这场竞赛中,市场最终会奖励那些能够提供“系统级效率×能源效率×开发效率×总拥有成本(TCO)”最优组合的厂商。无论是通过封闭生态实现极致性能,还是通过开放开源实现广泛适配,抑或是通过垂直整合提供一站式解决方案,成功的关键在于能否以可持续的方式,为客户打造稳定、高效且经济的“AI算力工厂”。
这场竞赛的结果,将深刻影响全球AI产业未来十年的力量对比与创新格局,决定着谁将引领下一个技术时代的浪潮。

参与方式 Hao to Participate - 演讲/参会/推广 -

陈经理:18702120901
—— 液冷技术链动 | 智汇算力未来 ——

- 演讲/参会/推广 -
陈经理:18702120901
—— 液冷技术链动 | 智汇算力未来 ——