【大模型入门】大模型训练数据白皮书——阿里研究院(上)
原文链接:https://pan.quark.cn/s/06b719a16a5f本文阅读了书中的1-4章,主要讲述了训练数据的重要性,不同模型上训练数据的差别,同时定义了什么是高质量数据,以及详细描述了合成数据的方法和重要性。
GPT的进化过程,主要是基于数据集的数量和质量上的提升,自身的模型架构非常相似。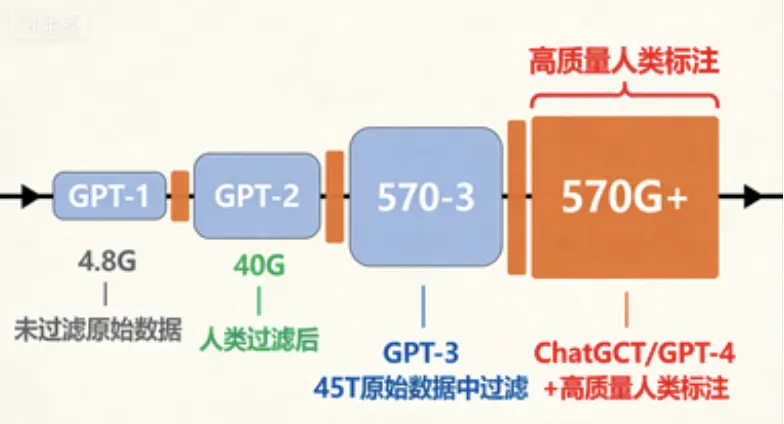
LLM训练过程一般分为预训练(Pre-training)、监督微调(SFT)、基于人类反馈的强化学习(RLHF),后两个部分统称为“对齐(Alignment)”阶段。- 预训练训练集:各种类型的世界知识。通过大量学习世界知识,构建模型基础能力。
- SFT训练集:通过标注人员设计问答,将带有正确答案的例题供模型学习,并提升模型的泛化能力。
- RLHF训练集:训练目标是让模型的价值观与人类对齐,通过对模型的回答进行监督学习(例如打分、排序等),让模型知道“怎么做更好”。
- 专项训练数据:如果将模型部署后用于特定行业,则需要特定领域知识进行预训练和对齐,例如行业数据库、专业文档、专业网站等。
多模态一般包含图像、视频、音频等。以以 Mid-journey 和 Sora 为例来看,训练阶段需要大量图像-文本对,视频-文本对等带标注的数据集进行训练。- 图像-文本对:包含一张图像和一段描述该图像内容的文本的数据,供模型学习图像像素、文字和图像的关联。
- 视频-文本对:包括一个短视频和一段描述视频中发生事件的文本,让模型不仅学习单个画面,还需要理解视频中的时间序列和动态变化。
- 传统的决策类人工智能在需求侧通过分析海量的用户行为数据,判断用户的偏好和需求;在供给侧通过学习内容的特征,借助推荐、排序等机制实现内容匹配,根据用户行为反馈进行优化,提升算法准确性。
- 大模型模拟人类思维比生成人类可以理解和使用的内容。在训练阶段依赖世界知识、专业知识库等,不依赖个人信息等原始数据。也可以通过人工标注等机制优化表达,使模型生成内容接近人类认知。
- 大模型推理过程不依赖用户个人数据,同时国内主流大模型也提供用户隐私保护,同时不过度收集和使用用户个人信息。但是在推理阶段的用户恶意诱导,目前仍无法完全避免个人信息泄露。
3.2 中文语料短缺不是制约我国大模型发展的重要因素实践表明,语料规模并不是大模型发展的决定性因素。主要原因如下:- 部分世界知识是通用的,使用不同的语言表达并不影响模型的理解。
但是,目前中式价值观类语料极为重要且十分短缺。大量来自知识和价值观层的数据,可以更好的帮助模型理解客观世界和掌握规律。因此加入更多中式价值观的语料,有助于更好的理解和反应中国使用者的文化背景和价值取向,保持文化的多样性和独特性。高质量的中式价值观语料包括文言文、古汉语、电子书(包含传统文化内容)、流媒体上的本土价值观的内容。存在问题:古籍数字化差、开发共享和开发利用率低、机器算法和编码系统建设缺乏。
什么是高质量的训练数据?满足“真实性”、“准确性”、“客观性”、“多样性”的要求。- 技术层面:使用损失函数来量化模型预测输入和实际目标直接的不匹配程度。当模型在训练集上的损失函数越小,模型预测的概率越逼近实际数据的真实分布。
- 数据清洗是提高数据质量的重要环节,包括去重、删除个人隐私内容、纠正错误、填补缺失值等。
- 利用数据增强提升多样性。比如通过旋转、缩放、亮度调整等手段进行数据变换或扩充。
此外,如果训练数据中出现较多错误、有毒、重复的低质量数据,则会对模型能力产生破坏性影响。- 重复语料:导致模型对特定类型的示例产生偏见,降低结果多样性。
- 第一重是所需的语料种类。针对不同模型能力需求,定义什么是高质量数据的类型是完全不一样的,下面列举了大模型发展过程中高质量模型的发展历程:

- 第二重是语料形态的演化,高质量数据的形态会不断增加。
- 领域知识生成:对于大模型难以使用的原始数据,经过加工、改造、泛化等可以形成有效知识数据。
- 自动驾驶等领域:通过仿真数据生成多样化、多视角的物理世界用于模型训练,增加特定场景的数据收集。
- 代码和教材:代码扩展到仓库级,从单一任务模块扩展到整体框架;教材也从中小学扩展到大学,增加了复杂场景的推理能力。
- 第三重是不同数据类型的有效搭配,通过对不同来源的数据混合,提升数据集多样性。包含两个重要环节:
- 调整不同来源数据的配比(数据混合)。下面介绍常用策略:
- 让大模型更好学习某项技能,探索语料学习顺序的影响。一般来说,按照技能集合的顺序组织语料会更为有效。
此外,“少而精”的数据在模型对齐能力上可能会取得更好的效果。对同类语料的质量评估,往往从质量、规模、多样性三个维度出发。- 质量上:通过了有用性和质量筛查,一般通过数据来源和模型打分等方式进行判断。数据来源判断有以下几种:
- 语言模型训练中,新闻、科研论文、开源项目代码是已审查的数据。
- 多模态训练:视觉中国网站提供大量图片和视频,并且有图像的光照、构图、艺术性、美观性等专业标注。
- 公开网页:首先通过少量样本人工评估获得可读性、帮助性、安全性等指标,然后通过这些样本进行评估模型训练。
- 规模上:当模型的参数或计算量按比例扩大时,模型性能也与之成比例提升。此外,模型参数和训练语料也成正比例关系。注意并不是语料规模越大越好,而是高信息密度的语料规模越大越好。
- 数据集公平性。网络数据可能存在弱势群体不公平现象,可能会加剧偏见或系统性不平等。增加数据集审查确保分布广度和均衡性,可以缓解公平性问题。
- 同类语料的多样性。在安全能力结社方面,可以通过打安全标签的方式提升模型对安全风险的识别。
高质量更多是一种主观判断,取决于模型的应用目的,可以参考模型的发展阶段、开发人员的判断、模型的训练效果等多个维度评估。
风险:据Epoch AI估算,书籍、科研论文等高质量数据集会在2024年前耗尽。那么如何解决数据集的问题呢?- 利用机器感知数据。例如增加无人车、无人机、其他智能设备等生成大量真实数据。
- 利用模型和算法,批量生产新数据。例如数据合成。数据合成能作为真实数据的补充,扩展模型学习范围和能力;但是生成的数据存在偏差和噪声,和真实数据存在误差。
通过算法和数据模型创建的。主要流程为建模真实数据分布,然后采样并创建新数据集,模拟真实数据中的统计模式和关系。什么情况用到合成数据?本质是因为真实世界获取困难,例如:- 真实世界难以观测。例如罕见病、极端天气、特殊路况等。
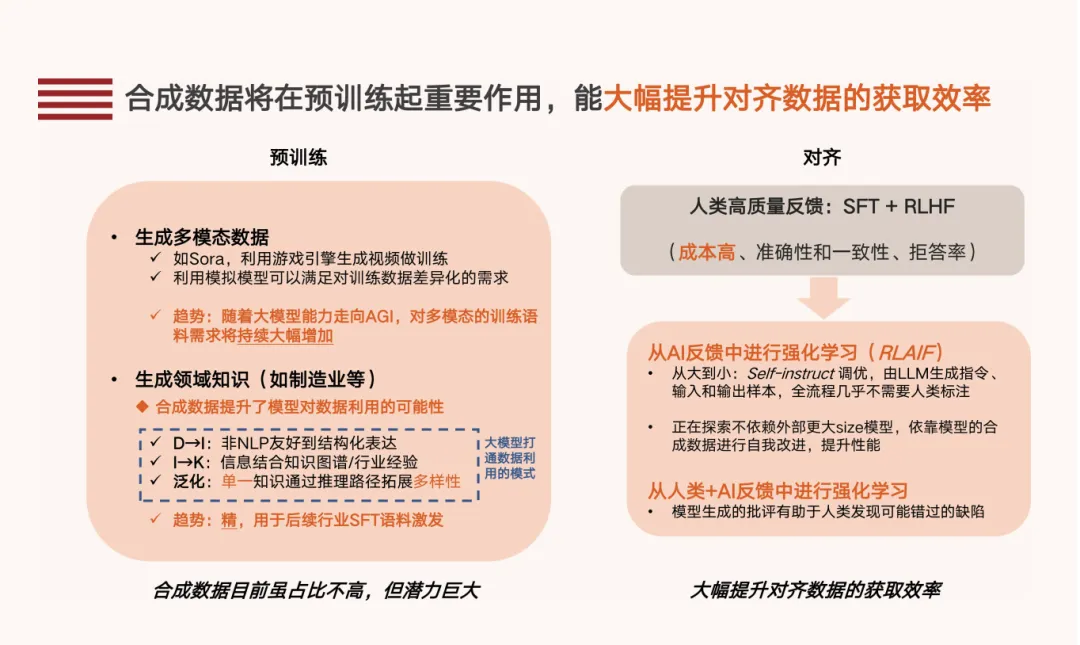
- 真实世界获取成本高。例如大模型所需的高质量反馈,利用合成数据实现对齐流程自动化,免去人类标注,提高获取效率。
- 基于真实数据集构建:通过模型获取真实数据的分布特征和结构特征,然后从该模型中抽取或生成合成数据。
- 不基于真实数据集构建:通过使用现有模型或人类专业背景知识构建。例如Sora就使用了游戏引起合成的视频作为训练集。
- 媒体合成数据:即由模型和算法合成的视频、图像或声音。
- 表格合成数据,类似真实的数据记录或表格的合成数据。
- 应用于多模态数据生成。广泛应用于具身智能机器人、自动驾驶、AI for Serience等场景的训练。合成数据可以更好满足训练数据差异化的需求,例如通过有效的“过采样”罕见、灾难事件,确保模型的鲁棒性。
- 应用于高价值领域知识生成。通过对现有数据的加工,转化不能训练的数据。例如转化工业制造数据:将生产、制造等工艺流程和知识图谱结合,转换成可用的工业语料。通常分为三步:
- 原始数据(Data)转变为信息(Information),将数据结构化。
- 信息提炼为知识:将结构化信息和行业知识图谱、专家经验结合,产生有价值的行业知识。
- 知识泛化:将单一的知识通过大模型推理进行多样性扩展。
目前在对齐阶段(包括微调和强化学习阶段)存在的问题包括:1.数据获取成本高;2.人类评估准确性和一致性;3.模型避免回答敏感问题和争议问题。使用合成数据可以大幅度提升对齐数据的获取效率。通常使用合成数据进行以下操作,可以大幅度降低标注成本:- 自我指导(Self-instruct):Alpaca通过OpenAI 的 API 自动生成指令数据进行微调。
- 自我对局(Self-play):利用合成数据进行自我对抗微调(t+1 代的模型尝试将 t 代模型的输出与真人的输出区分开)。
- 宪法式 AI:让AI在遵循预先设定的原则下,使用模型自身生成反馈和修正意见并进行自我改进,例如Claude3。
当前训练数据侧重于构建开放、包容的高质量数据源,包括建立公共(准公共)属性的高质量数据集、鼓励行业数据共享、放开对训练数据的权属保护等。使用合成数据可以解决以下问题:- 解决部分类型的真实数据无法观测的问题,提升数据多样性。生成“边缘情况”或“潜在隐患”可以弥补样本分布不均衡的问题,提高数据分布合理性和客观性。未来,仿真数据、大模型加工后的新型数据都可以提升模型的推理和泛化能力。
- LLM方面:解决RLHF过程中人类回答标准不统一、问答准确性不足的问题。
- 图像领域:弥补对抗样本稀疏的缺陷,通过合成数据和普通数据进行混合,可以提高模型对图片的判断能力。
- 替代个人特征数据,有助于隐私保护。例如推荐系统中降低对个人信息的依赖,具体操作如下
- 利用生成器自动产出个性化提示词(即合成数据)用于模型优化
- 通过用户反馈,由模型进行推荐,降低对个人特征数据依赖
- 合成数据不能堆量,更要重质。训练阶段过多的引入合成数据,可能导致模型对世界知识理解产生偏差。可以通过一定比例将合成数据和真实数据混合,提升模型准确性、鲁棒性和安全性。此外,更重要的是关注生成合成数据对客观世界模拟的准确性,更好满足模型对训练数据差异化的需求,以及拓展模型对训练数据利用的可能性。
- 合成数据要具有安全性。尽量保证合成数据安全性和真实性不低于真实世界的数据。
- 设置相应的安全管控策略,确保模型安全性。主要有以下几种方式:
- 设置备用数据集;需要验证不同类型、模态和配比的合成数据对模型性能带来的影响,同时准备备用的真实世界数据集。
- 对用于模型优化、对齐的合成数据,适当引入人类参与。