


AI眼镜通过其传感器阵列,以第一人称视角持续收集多模态的上下文数据。
市场上的标准操作是:在设备端进行初步处理和关键的去标识化,再将脱敏数据安全上传至云端,用于清洗、标注并最终训练AI模型,从而形成一个不断自我强化的数据与智能闭环。
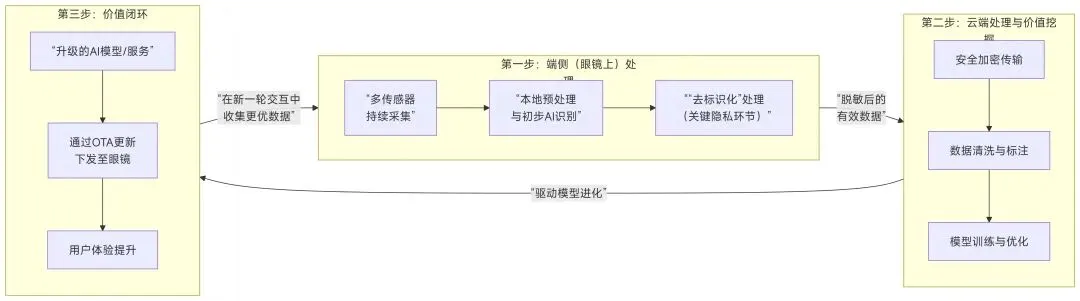
这场“百镜大战”的背后,实则是对未来AI时代核心生产要素——高质量、高维度物理世界数据——的入口争夺战。
➠➠➠➠➠➠➠➠➠➠➠➠
?不同厂商在AI眼镜上的“数据策略差异”非常大,这根本上源于它们各自的核心商业模式和战略目的。总体来看,主要分为三类,它们的目标和方法各有侧重。
1. 平台型互联网巨头:构建覆盖生活全场景的“超级数据入口”
代表厂商:阿里巴巴、谷歌、百度。
· 核心战略与数据目标:这类厂商手握搜索、电商、支付、地图、内容等核心应用生态。他们的主要目标是,将已有的庞大线上生态数据与用户第一视角采集的真实世界物理数据进行深度融合。其数据策略最终服务于生态扩张和防御。
· 主要数据来源与方式:通过眼镜深度整合自有App服务(如支付、导航、购物),引导用户在各类生活场景(逛街、旅游、点餐)中主动或被动使用。收集的数据不仅包括环境视觉、音频,更强调用户意图、行为路径和最终交易的闭环数据。
· 关键动作与案例:阿里夸克眼镜明确旨在实现“想买什么 -> 高德导航 -> 淘宝拍立淘比价 -> 支付宝扫码支付”的完整服务闭环。这本质上是在记录并优化从“看到”到“买到”的整个数据链路。
2. 手机与消费电子厂商:打造“设备协同下的行为数据闭环”
代表厂商:小米、华为、Meta(与雷朋合作)。
· 核心战略与数据目标:这类厂商的优势在于庞大的存量硬件设备网络(手机、手表、耳机、智能家居)。他们的数据策略核心是强化 “人-车-家”全场景的设备协同和用户粘性,收集用户在跨设备互动中的行为习惯数据。
· 主要数据来源与方式:数据收集更侧重于用户与多设备交互的指令和偏好。例如,通过眼镜语音控制智能家居、在车内与车机联动、或在户外将眼镜作为手机的音视频延伸。其目的是绘制更立体的用户全场景行为图谱,而非单纯追求物理世界画面的原始数据。
· 关键动作与案例:小米将AI眼镜定位为“人车家全生态”的随身AI入口,其数据价值在于串联用户在家庭、出行等不同空间下的指令和行为。Meta则利用其社交平台优势,鼓励用户通过眼镜进行第一视角拍摄和分享,数据服务于内容生成和社交互动。
3. 垂直场景与技术厂商:深耕“特定领域的专业数据”
代表厂商:Rokid、影目科技、理想汽车。
· 核心战略与数据目标:这类厂商通常选择特定专业或高价值场景(如工业、安防、医疗、车载)作为突破口。其数据策略是在特定领域内收集高精度、高价值的专业数据,建立技术壁垒,并可能向行业解决方案拓展。
· 主要数据来源与方式:数据收集场景高度聚焦。例如,在工业巡检中收集设备图像和故障特征数据,在演讲提词场景中收集语音和文本同步数据,在车载场景中收集与车辆状态、道路环境结合的语音指令数据。
· 关键动作与案例:理想汽车的Livis眼镜,其数据策略紧密围绕“车”展开,收集用户用车前后及过程中的环境与交互数据,旨在优化车联体验。Rokid在工业、文旅等B端领域,其收集的数据也更偏向于提升特定行业的工作效率。
?AI眼镜的“数据之争”远不止于硬件传感器本身,更是背后厂商核心商业模式在物理世界的延伸:
· 互联网巨头要的是打通线上线下、覆盖生活全场景的“广数据”,用于巩固其应用生态。
· 手机/消费电子厂商要的是连接万物、理解用户习惯的“协同数据”,用于卖更多硬件和服务。
· 垂直领域厂商要的是高精度、能解决实际问题的“深数据”,用于在细分市场建立壁垒。
➠➠➠➠➠➠➠➠➠➠➠➠
最原始的第一视角信息,主要来自以下几类,它们各有优劣,适用不同阶段:
? 数据来源全览
1. 由研究者或厂商组织系统采集
· 参与者与设备:邀请用户佩戴专用眼镜或头戴相机,在特定时间内记录日常生活。
· 目的与特点:用于科研或模型预训练。数据质量与标注规范极高,包含密集的场景、动作、语音标注。例如Ego4D数据集(3000小时)和EgoLife数据集(300小时)。
· 优势:数据多模态、高质量、标注精细,隐私授权清晰。
· 局限:规模有限、成本高、场景可能不够自然。
2. 从公开视频平台(如YouTube)爬取
· 参与者与设备:大量Vlog博主、户外运动爱好者用运动相机、手机或眼镜拍摄的第一视角视频。
· 目的与特点:用于训练基础视觉或世界模型。数据“野生成分”高,场景极其丰富。例如Sekai数据集从YouTube收集了超过5000小时的第一人称行走视频。
· 优势:数据量巨大、场景多样、获取成本低。
· 局限:质量参差不齐,缺少精细标注,存在版权和隐私风险。
3. 从虚拟世界生成
· 参与者与设备:在《虚幻引擎5》等高拟真游戏中录制,或由AI视频生成模型(如Veo 3)合成。
· 目的与特点:获取真实世界难以采集或标注的数据(如精确的物体3D坐标、相机轨迹)。
· 优势:可批量生成、标注信息精确、完全规避隐私问题。
· 局限:与真实世界存在“模拟鸿沟”,物理规律和细节可能失真。
4. 用户日常使用产品产生
· 参与者与设备:普通用户在日常使用智能眼镜等设备中产生的数据(如拍摄、语音指令)。
· 目的与特点:用于迭代和优化已上市的特定产品。数据最真实、最自然,与具体产品功能强相关。
· 优势:反映真实用户习惯,是产品优化的核心燃料。
· 局限:涉及强隐私保护,需严格脱敏,初始积累缓慢。
? 总结与趋势
不同来源的数据在AI发展的不同阶段扮演着不同角色:
· 早期研发:依赖高质量、强标注的系统采集数据和合成数据来“冷启动”模型。
· 模型训练与优化:利用海量的公开网络数据来提升模型的通用性和鲁棒性。
· 产品迭代与护城河:最终依赖真实用户数据进行个性化优化,这是核心壁垒。
所以,厂商的数据策略差异,也体现在他们更擅长获取和利用哪一类数据。例如,互联网巨头拥有整合公开数据的优势;而硬件厂商则着眼于获取真实用户使用数据。