点击上方“Python学习与数据挖掘”,关注公众号
工作中你是否会经常被你的老板问到:“最近这个产品的活跃用户在下降,流失的人数在变多,问题出在什么环节,怎么回事呢”。这样类似的问题应该会有很多,遇到这样的场景时,老板们喜欢听到的不仅仅是什么地方出现了问题,更多的是想得到这样的答案:出现了什么问题、判断依据是什么、怎么解决问题。
之前写过一篇文章(一招教你如何去做商业数据分析),更多是从宏观视角教大家如何去做商业数据分析,今天小编将以电信流失数据为例,教你如何具体去做一份数据分析报告。需要完整版代码及数据的同学,公众号后台回复:“分析报告”。
数据源
在分析问题之前,我们先看一下数据源都有那些字段,可以思考一下那些字段可能用户的流失有关。
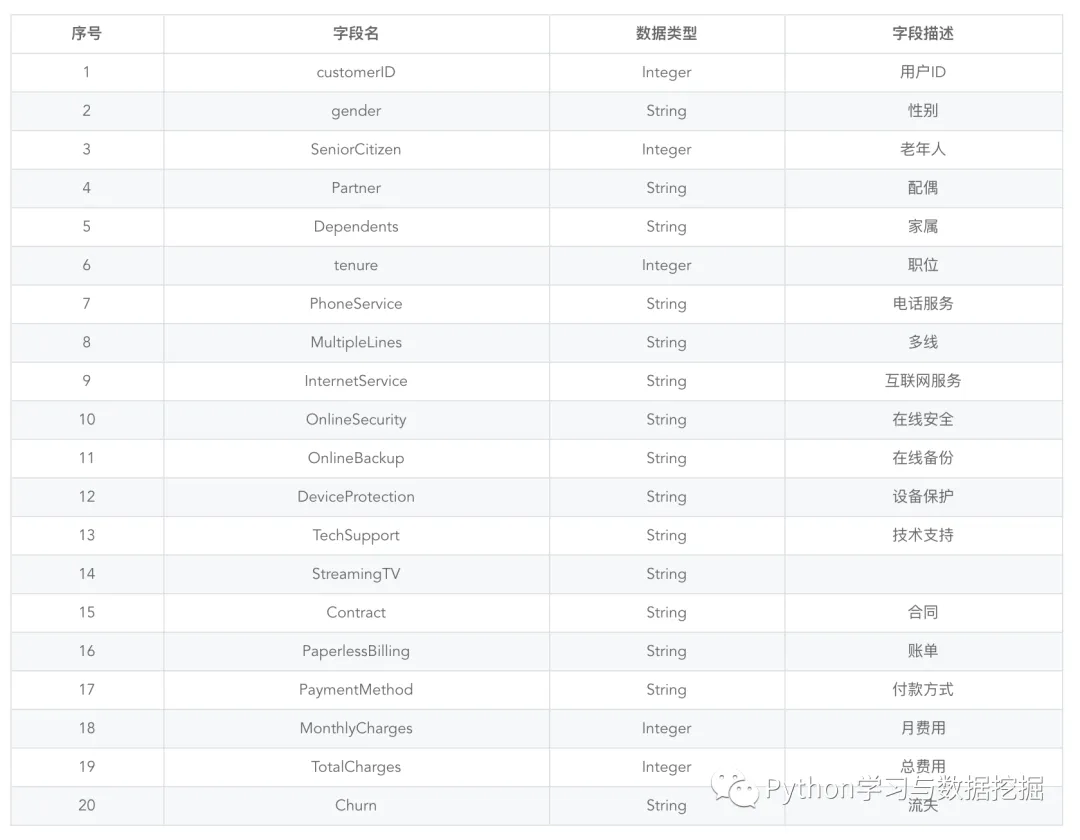
数据获取
# 读取数据文件
telcom=pd.read_csv(r"WA_Fn-UseC_-Telco-Customer-Churn.csv")
# 获取数据类型列的描述统计信息
telcom.describe()
telcom.info()
# 查找缺失值
pd.isnull(telcom).sum()
telcom["Churn"].value_counts()
对数据进行概括分析,数据集中有5174名用户没流失,有1869名客户流失,数据集是不均衡。

数据预处理
删除缺失值、类型转换
# TotalCharges表示总费用,这里为对象类型,需要转换为float类型
telcom.dropna(inplace=True)
telcom['TotalCharges']=telcom['TotalCharges'].astype('float')
# 再次查找是否存在缺失值
pd.isnull(telcom["TotalCharges"]).sum()
#由于数量不多我们可以直接删除这些行
telcom.dropna(inplace=True)
print(len(telcom))
对Churn 列中的值 Yes和 No分别用 1和 0替换,方便后续处理
# 对Churn 列中的值 Yes和 No分别用 1和 0替换,方便后续处理
telcom['Churn'].replace(to_replace = 'Yes', value = 1,inplace = True)
telcom['Churn'].replace(to_replace = 'No', value = 0,inplace = True)
telcom['Churn'].head()
数据分析
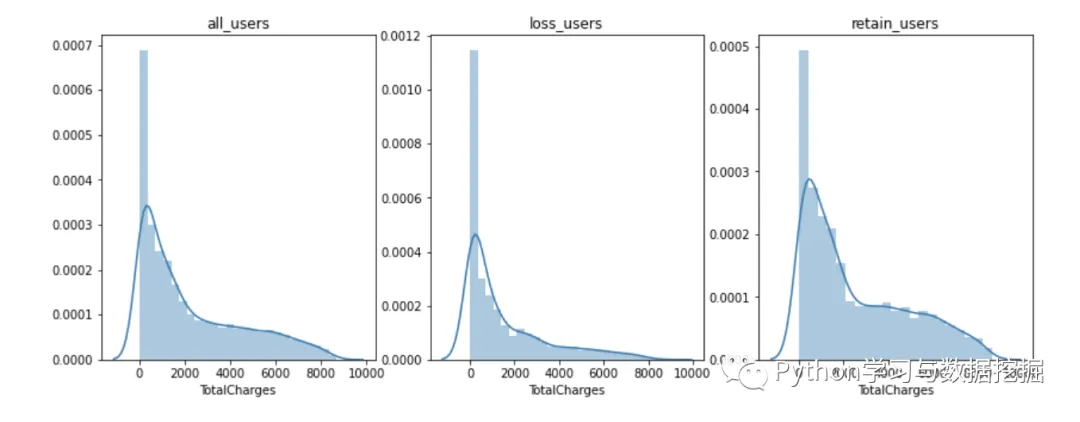
1.先画直方图查看整体用户总费用的数据分布形态
2.流失用户占比
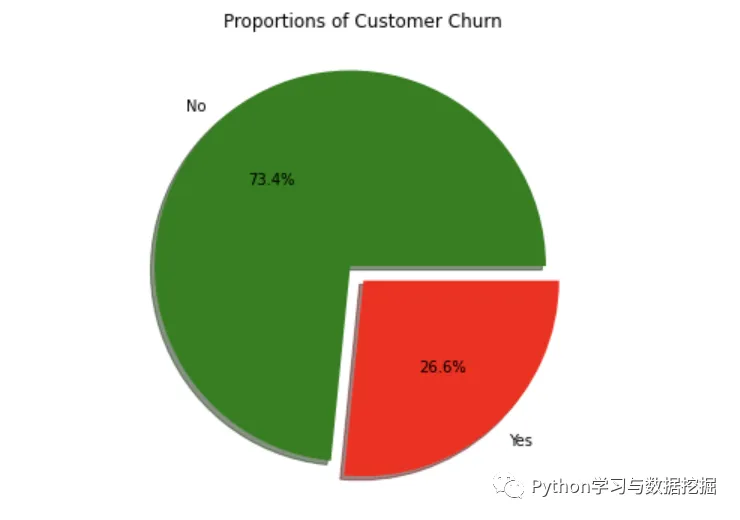
流失客户样本占比26.6%,留存客户样本占比73.4%,明显的“样本不均衡”。解决样本不均衡有以下方法可以选择:分层抽样、过抽样、欠抽样
3.分析性别、老年人、配偶、亲属对流客户流失率的影响
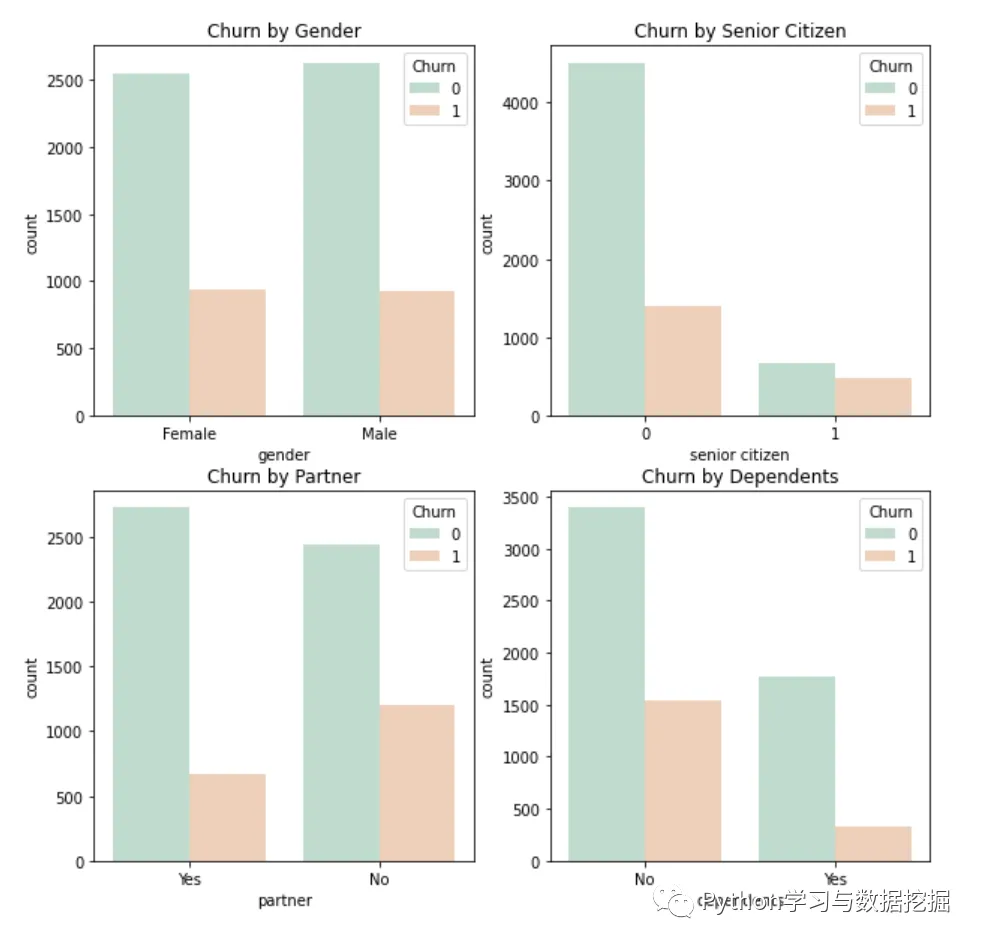
通过上图我们可以看出,在性别方面流失情况基本没有差异,老年用户中流失占比明显比年轻用户,无伴侣中流失人数比有伴侣的流失人数高出很多,从经济独立情况来看,经济未独立的用户流失率要远远高于经济独立的用户。
4.使用热地图显示相关系数
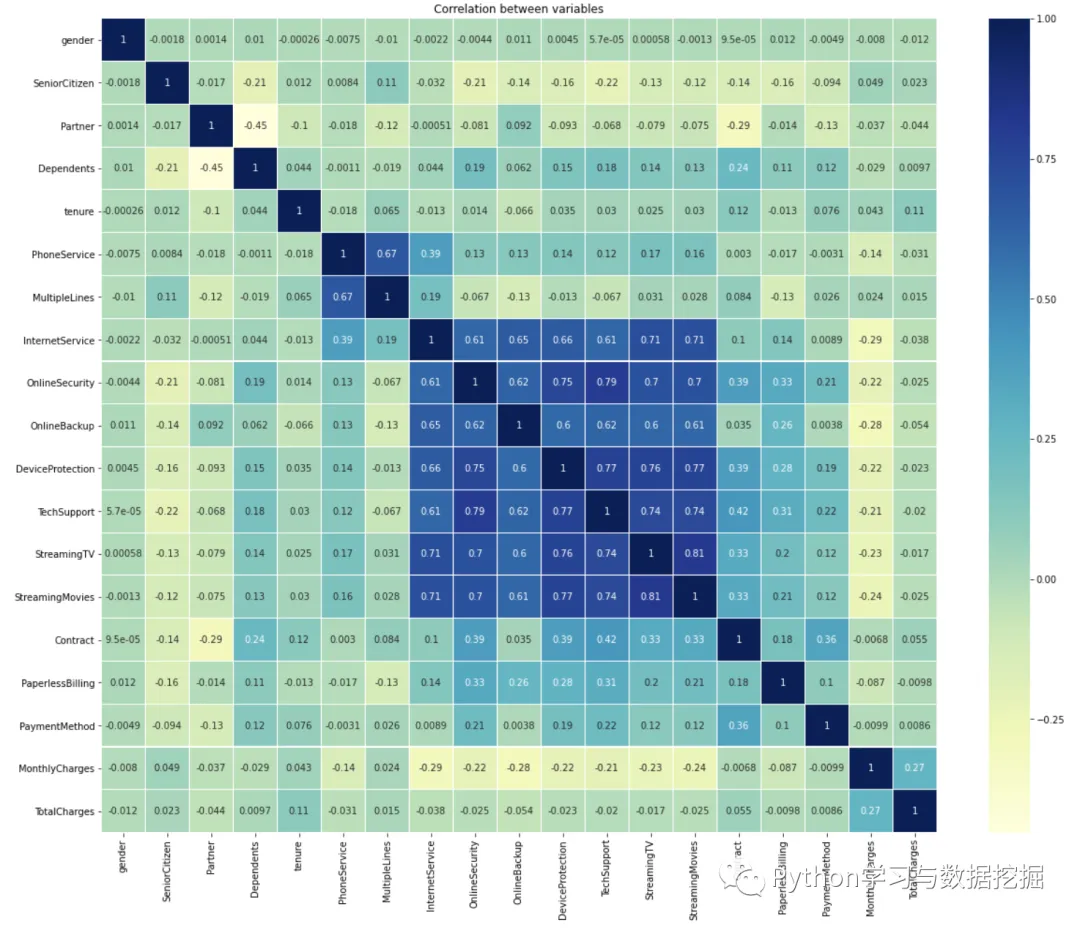
从上图可以看出,互联网服务、网络安全服务、在线备份业务、设备保护业务、技术支持服务、网络电视和网络电影之间存在较强的相关性,多线业务和电话服务之间也有很强的相关性,并且都呈强正相关关系。
5.用户是否流失与各变量之间的相关性
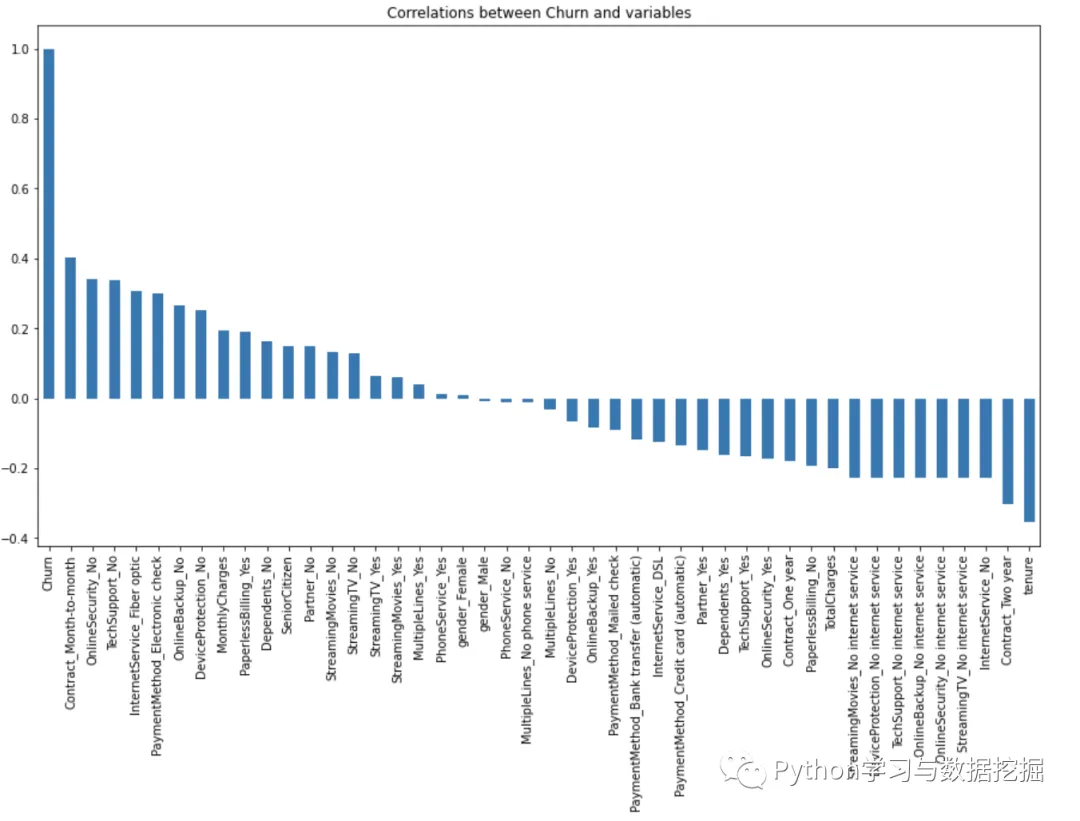
由图上可以看出,变量电话服务、性别、多线、网络电视等处于图形中间,其值接近于 0 ,这几个变量对客户流失预测影响非常小,可以直接舍弃。
6.网络安全、在线备份、设备保护、技术支持、网络电视、网络电影和无互联网服务对客户流失率的影响
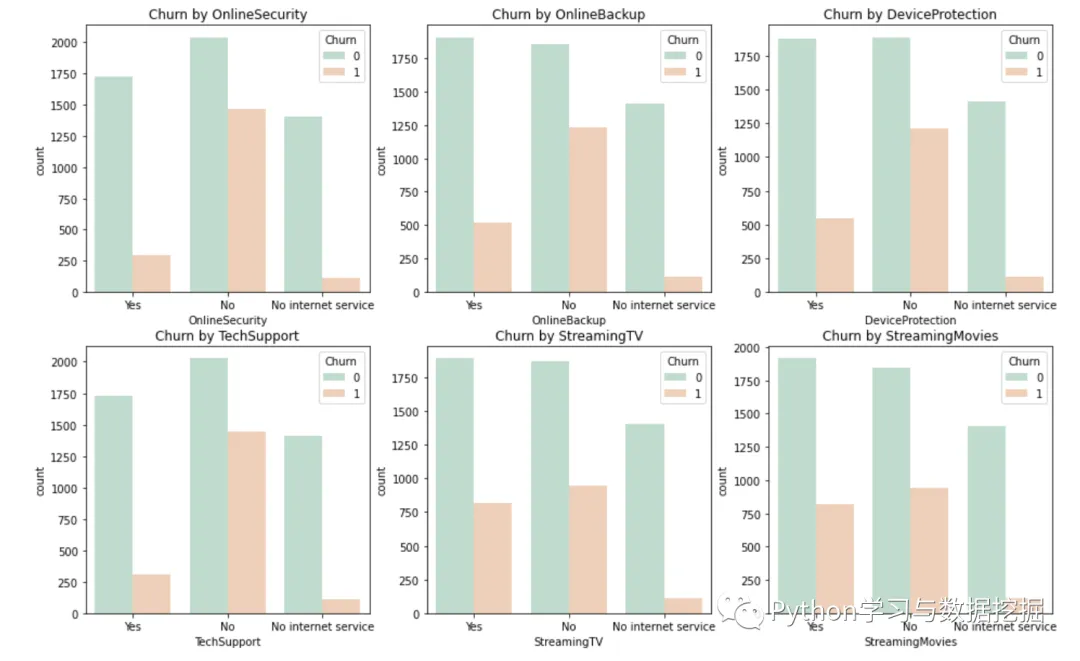
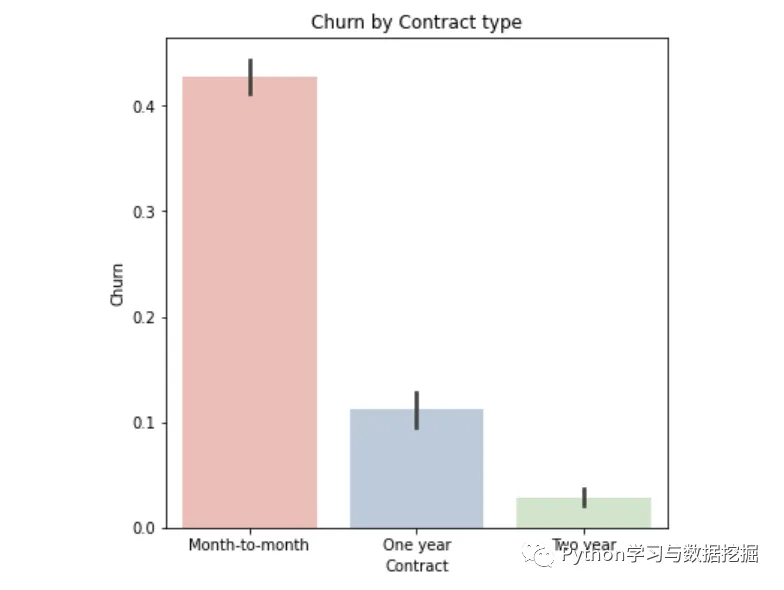
解决方案
"""
将数据集拆分为训练集和测试集以进行验证。
由于数据集是不平衡的,最好使用分层交叉验证来确保训练集和测试集都包含每个类样本的保留人数。
交叉验证函数StratifiedShuffleSplit,功能是从样本数据中随机按比例选取训练数据(train)和测试数据(test)
参数 n_splits是将训练数据分成train/test对的组数,可根据需要进行设置,默认为10
参数test_size和train_size是用来设置train/test对中train和test所占的比例
参数 random_state控制是将样本随机打乱
"""
X=telcomvar
y=telcom["Churn"].values
sss=StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=0)
print(sss)
print("训练数据和测试数据被分成的组数:",sss.get_n_splits(X,y))
for train_index, test_index in sss.split(X, y):
print("train:", train_index, "test:", test_index)
X_train,X_test=X.iloc[train_index], X.iloc[test_index]
y_train,y_test=y[train_index], y[test_index]
# 输出数据集大小
print('原始数据特征:', X.shape,
'训练数据特征:',X_train.shape,
'测试数据特征:',X_test.shape)
print('原始数据标签:', y.shape,
' 训练数据标签:',y_train.shape,
' 测试数据标签:',y_test.shape)
# 使用分类算法
Classifiers=[["Random Forest",RandomForestClassifier()],
["Support Vector Machine",SVC()],
["LogisticRegression",LogisticRegression()],
["KNN",KNeighborsClassifier(n_neighbors=5)],
["Naive Bayes",GaussianNB()],
["Decision Tree",DecisionTreeClassifier()],
["AdaBoostClassifier", AdaBoostClassifier()],
["GradientBoostingClassifier", GradientBoostingClassifier()],
]
# 训练模型
Classify_result=[]
names=[]
prediction=[]
for name,classifier in Classifiers:
classifier=classifier
classifier.fit(X_train,y_train)
y_pred=classifier.predict(X_test)
recall=recall_score(y_test,y_pred)
precision=precision_score(y_test,y_pred)
class_eva=pd.DataFrame([recall,precision])
Classify_result.append(class_eva)
name=pd.Series(name)
names.append(name)
y_pred=pd.Series(y_pred)
prediction.append(y_pred)
names=pd.DataFrame(names)
names=names[0].tolist()
result=pd.concat(Classify_result,axis=1)
result.columns=names
print(result)

4.选择模型
通过上述的准确率和召回率等指标,我们朴素贝叶斯方法,当然根据不同场景模型根据效果进行选择即可,下面构建流失预警模型。
# 使用朴素贝叶斯方法,对预测数据集中的生存情况进行预测
model = GaussianNB()
model.fit(X_train,y_train)
pred_y = model.predict(pred_X)
# 预测结果
predDf = pd.DataFrame({'customerID':pre_id, 'Churn':pred_y})
print(predDf)结论
至此,我们已经完成来技术方面的所有环节,内容包含数据分析、数据可视化、数据建模等,根据需要灵活选择。面对海量用户,通过构建了用户流失预警模型,可以实时掌握用户的动态变化,对用户的挽留非常有益。有原因、数据分析过程、解决方案才是一份完整版的数据分析报告。


●GitHub热榜|5款优质的Python小工具,最后一款真神器!

获取更多精彩内容,请长按二维码关注!
解惑答疑,进群交流