



一、什么是质性\\案例分析?
质性分析是聚焦过程与机制的研究方法,核心不是估计统计系数,而是深入具体情境,理解行为者的决策逻辑、认知框架,以及制度、组织环境对行为的影响。
特征:
研究目标:回答“如何发生”“为什么”,拆解 “黑箱” 里的行为博弈、组织过程(如银行一线如何平衡合规与业务增长);
数据类型:非结构化数据,包括访谈逐字稿、观察笔记、内部文件、会议记录、文本资料等;
样本逻辑:理论取样,样本量小但信息密度高,常选典型个案、极端个案或对比个案;
分析方式:通过“编码”(给文本贴标签→归类范畴→提炼机制)梳理逻辑链条,形成过程模型或概念框架;
输出结果:机制链条、过程叙事、新概念 / 范畴(如 “影子合规实践”),而非回归表或统计系数。
二、什么是实证分析?
实证分析是以“验证因果关系、估计量化效应”为核心的研究方法,通过结构化数据和统计模型,回答“某变量是否影响结果”“影响方向与大小如何”,最终产出可统计推断的量化结论,为研究假设或政策效果提供客观证据。
特征
研究目标:聚焦“是否”与“多大”,验证因果关系,不深入拆解黑箱内的行为机制,仅关注变量间的统计关联与量化影响。
数据形态:依赖结构化数据数据需是可定义、可度量的形式,包括:
公开统计数据如《统计年鉴》;
微观观测数据(上市公司财报、面板数据、问卷调研数据);
政策/事件数据(如试点政策名单、专利申请数据)。
分析方法:以统计模型为核心核心工具是各类计量模型与因果识别方法,目的是控制混杂因素、确立变量间的因果关系,
样本逻辑:追求统计代表性采用概率抽样,优先选择大样本数据(如数千家企业、数万个体),确保样本能反映总体特征,支撑后续从样本推断总体的统计泛化。
只要满足模型识别假设(如条件独立性、平行趋势),即可将样本层面的量化结论外推至总体,强调结论的普适性与可重复性。
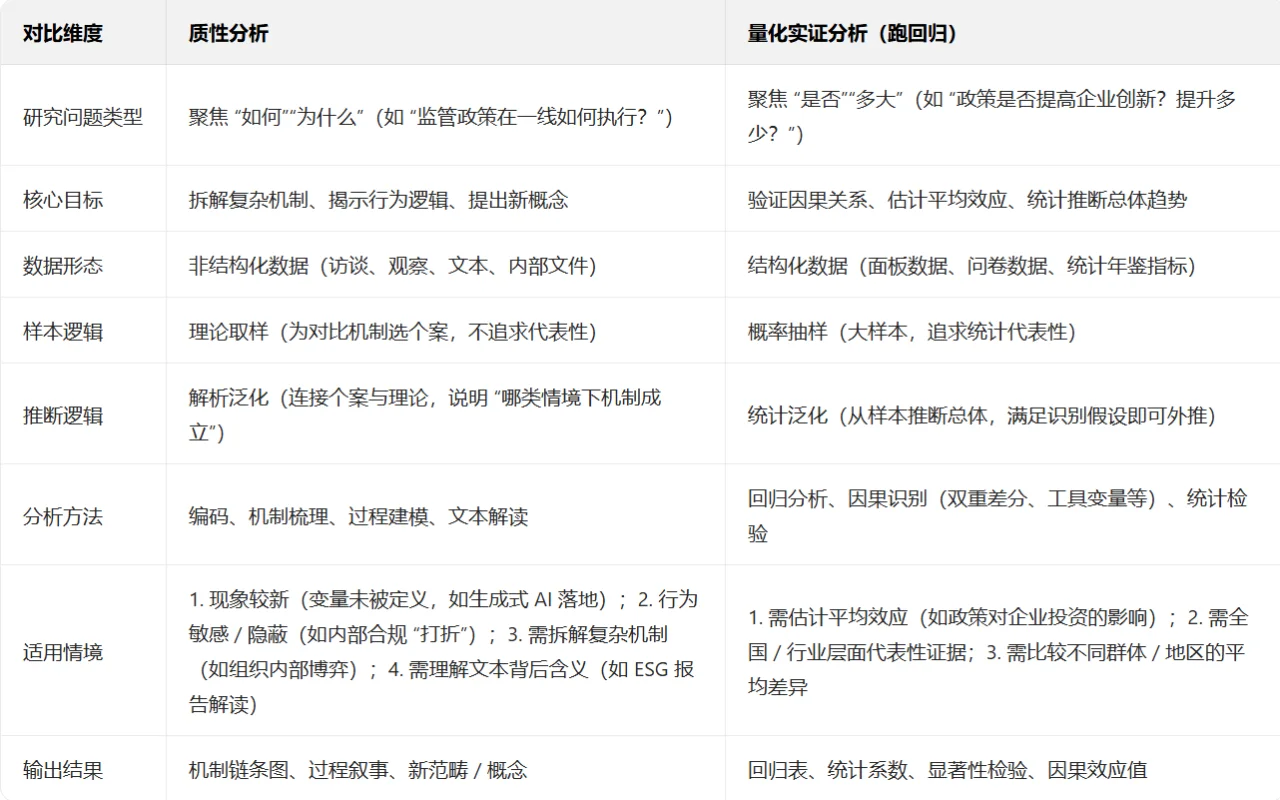
具体区别看图2
#论文辅导 #论文写作 #案例分析 #实证分析 #论文 #stata #毕业论文 #本科毕业论文 #实证论文 #论文发表
质性分析是聚焦过程与机制的研究方法,核心不是估计统计系数,而是深入具体情境,理解行为者的决策逻辑、认知框架,以及制度、组织环境对行为的影响。
特征:
研究目标:回答“如何发生”“为什么”,拆解 “黑箱” 里的行为博弈、组织过程(如银行一线如何平衡合规与业务增长);
数据类型:非结构化数据,包括访谈逐字稿、观察笔记、内部文件、会议记录、文本资料等;
样本逻辑:理论取样,样本量小但信息密度高,常选典型个案、极端个案或对比个案;
分析方式:通过“编码”(给文本贴标签→归类范畴→提炼机制)梳理逻辑链条,形成过程模型或概念框架;
输出结果:机制链条、过程叙事、新概念 / 范畴(如 “影子合规实践”),而非回归表或统计系数。
二、什么是实证分析?
实证分析是以“验证因果关系、估计量化效应”为核心的研究方法,通过结构化数据和统计模型,回答“某变量是否影响结果”“影响方向与大小如何”,最终产出可统计推断的量化结论,为研究假设或政策效果提供客观证据。
特征
研究目标:聚焦“是否”与“多大”,验证因果关系,不深入拆解黑箱内的行为机制,仅关注变量间的统计关联与量化影响。
数据形态:依赖结构化数据数据需是可定义、可度量的形式,包括:
公开统计数据如《统计年鉴》;
微观观测数据(上市公司财报、面板数据、问卷调研数据);
政策/事件数据(如试点政策名单、专利申请数据)。
分析方法:以统计模型为核心核心工具是各类计量模型与因果识别方法,目的是控制混杂因素、确立变量间的因果关系,
样本逻辑:追求统计代表性采用概率抽样,优先选择大样本数据(如数千家企业、数万个体),确保样本能反映总体特征,支撑后续从样本推断总体的统计泛化。
只要满足模型识别假设(如条件独立性、平行趋势),即可将样本层面的量化结论外推至总体,强调结论的普适性与可重复性。
具体区别看图2
#论文辅导 #论文写作 #案例分析 #实证分析 #论文 #stata #毕业论文 #本科毕业论文 #实证论文 #论文发表