


华为“韬定律”V2版本标志着中国半导体产业从理论探索迈向工程实证的关键转折。该理论通过确立“时间常数τ”为单一优化目标,取代传统的“几何微缩”,构建了跨越器件、电路、芯片及系统四层的统一度量衡。工程落地层面,V2版本详细披露了“逻辑折叠(LogicFolding)”技术及其关键工艺指标(如1.5μm混合键合间距),并在麒麟2026芯片上实现了晶体管密度提升53.5%、能效比提升41%的量化突破。此外,路线图明确指出2029年麒麟芯片主频将突破4GHz,AI算力集群通过“统一总线+Hi-one光引擎”将在2035年实现百倍增长。这一范式转移带动了产业链价值重构,使得先进封装、EDA、半导体设备及光互联等环节成为核心受益赛道。
第一章 背景与挑战:后摩尔时代的产业重构
随着半导体技术的发展逼近物理极限,传统的摩尔定律(Moore's Law)正面临前所未有的挑战。在过去六十年中,半导体行业一直依赖几何缩微(Geometric Scaling)作为核心驱动力,即通过缩小晶体管尺寸来提升性能并降低成本。然而,进入7nm及以下节点后,单纯依靠缩小尺寸带来的收益日趋平缓,而设计成本却呈指数级上升,单颗尖端芯片的设计预算已超过10亿美元。更为严峻的是,单位晶体管成本在最先进节点上不再下降,甚至不降反升,行业契约已然失效[1][2]。
在此背景下,华为半导体业务部总裁何庭波于2026年5月25日发布了“韬定律”V1版本,并于7月3日正式推出了V2版本。V2版本不再是单纯的理论框架,而是补充了大量工程落地细节、实测量化数据与全场景产品演进路线,标志着该理论已进入工程实证阶段。该理论的核心思想是用“时间缩微”替代“几何缩微”,将衡量技术进步的标尺从晶体管面积转变为时间本身,旨在打破外部技术封锁与内部物理定律失效的双重困境,为中国半导体产业寻找一条可持续的内生增长路径[3][4]。
第二章 韬定律V2核心理论体系:τ分层时空模型
韬定律V2版本构建了一个全新的理论框架,即τ缩放理论(Tau Scaling)。该理论主张在全计算栈中建立统一的优化目标——单一特征时间常数τ(Tau),并将其分解为四个层级进行协同优化。
2.1 统一优化目标:单一特征时间常数τ
韬定律V2提出,应当关注系统对负载的响应时间,即信号传输与处理的延迟。τ被定义为贯穿从晶体管开关(皮秒级)到数据中心负载(秒级)十二个数量级的统一优化目标。无论是在微观的器件层面,还是宏观的系统层面,技术进步的衡量标准都统一为“时间”的缩减[5][6]。
这一理论填补了自1974年登纳德缩放定律(Dennard Scaling)以来的空白,成为首个为整个计算堆栈建立共享优化目标的缩放原则。它不再孤立地看待某个器件的微缩,而是强调全栈协同,当某一层级成为瓶颈时,通过优化该层级的τ来实现整体性能的提升[7][8]。
2.2 四层级分层时空模型
为了实现τ的整体缩减,韬定律V2将电子系统划分为四个层级,并分别定义了其特征时间常数与优化路径:
· 器件层(Device Layer):τ_transistor
· 物理含义:晶体管的本征开关延迟,对应皮秒级时间尺度。
· 优化机制:通过材料创新与工艺改进来提升晶体管的开关速度。具体手段包括迁移率增强(Mobility Enhancement)、应变工程(Strain Engineering)、高κ栅极介质(High-k/Metal Gate)以及 gate-all-around(环绕栅极)等结构的引入。这些技术旨在降低晶体管的本征导通电阻和栅极电容,从而缩短信号的产生时间[1][9]。
· 电路层(Circuit Layer):τ_circuit
· 物理含义:信号在互连网络中的传播延迟,对应纳秒级时间尺度。
· 优化机制:这是韬定律工程落地的核心战场。通过降低互连的寄生电阻(R)和电容(C),以及缩短信号路径长度(L),可以显著降低RC延迟。V2版本重点强调了通过垂直集成(3D Stacking)和低电阻/低介电常数材料的应用来实现这一目标[2][10]。
· 芯片层(Chip Layer):τ_chip
· 物理含义:指令执行、数据计算与存储访问的延迟,对应微秒级时间尺度。
· 优化机制:涉及架构层面的创新,如流水线深度的设计、缓存层次结构(Cache Hierarchy)的优化以及近存计算(Processing-in-Memory)技术的应用。通过减少数据的搬运时间和计算时间,压缩芯片级的响应延迟[1][11]。
· 系统层(System Layer):τ_system
· 物理含义:端到端的消息传递与任务响应延迟,对应毫秒至秒级时间尺度。
· 优化机制:关注系统级的互连拓扑(Topology)、协议栈(Protocol Stack)以及任务调度算法。通过统一总线架构和高效的通信协议,减少节点间的数据传输时间和同步开销,从而提升整个系统的吞吐量[7][12]。
2.3 代际演化规律:τ缩放因子
韬定律V2还定义了不同应用场景下的代际演化规律,即τ缩放因子(Scaling Factor, α)。该因子描述了每经过一个代际周期,系统时间常数的缩减比例(τ_{n+1} = τ_n / α)。不同的应用场景对延迟的敏感度不同,因此具有不同的α值:
· 移动终端设备:受限于电池能量密度和散热,主要追求能效比。预计年度缩放因子约为 1.3,即每过一年,同等功耗下的性能提升约30%。
· 自动驾驶系统:对确定性和安全性要求极高,通信延迟必须极低。预计年度缩放因子约为 1.5。
· AI生成式任务(Token Generation):数据吞吐量巨大,对带宽和延迟极其敏感。其缩放因子最高,年度因子可达 10 甚至更高,显示出AI算力对τ缩减的极度渴求[2][13]。
第三章 工程落地核心:逻辑折叠(LogicFolding)技术详解
韬定律V2的工程落地主要依赖于“逻辑折叠(LogicFolding)”技术。这是一种通过三维空间重构来换取时间缩减的创新架构,其核心在于打破传统3D堆叠的物理限制,实现全局最优的垂直逻辑划分。
3.1 核心概念:齿比(Gear Ratio)
逻辑折叠技术的关键在于解决“宏块级离散优化”向“单元级连续优化”的跨越。在传统3D堆叠中,由于混合键合(Hybrid Bonding)的精度限制,设计时往往只能将较大的宏块(Macro Blocks)进行对齐,导致大量的标准单元(Standard Cells)无法在垂直方向上进行有效整合。
V2版本引入了“齿比(Gear Ratio)”这一关键工程指标,定义为混合键合间距与顶层金属布线(Top-layer Metal Pitch)尺寸的比值。传统的齿比通常大于3,而韬定律V2通过极致的工艺控制,将这一比值控制在 2以内,甚至趋近于1。
· 工程意义:当齿比接近1时,键合点之间的距离与芯片内部布线的间距处于同一数量级。这意味着设计师可以在极精细的尺度上(接近单个晶体管级别)规划逻辑电路的垂直分布。
· 技术优势:这种“单元级连续优化”能够突破传统3D堆叠仅能按功能块分层的局限,将数字、模拟和存储电路分区到垂直堆叠的有源层(Active Layers),从而实现全局最优的逻辑划分[2][14]。
3.2 关键工艺指标与良率挑战
为了实现上述工程目标,逻辑折叠技术对制造工艺提出了极高要求,V2版本详细披露了量产所需的工艺参数:
· 混合键合间距(Hybrid Bonding Pitch):< 2μm。在麒麟2026的实际量产中,该间距已达到 1.5μm。这是实现高密度互连的基础,直接决定了垂直方向上的通信带宽。
· 套刻精度(Overlay Accuracy):< 0.5μm。在垂直堆叠过程中,上下两层晶圆的对准精度必须控制在亚微米级别,任何偏差都会导致连接失效。
· TSV工艺窗口:硅通孔(TSV)的临界尺寸及保持区(Keep-Out Zone)需控制在 < 1.5μm,间距 < 6μm。此外,为了保证量产良率,V2版本还提出了一系列工程对策:
· 低温混合键合:为了避免顶层有源器件受高温退火影响而性能衰减,必须采用低温键合工艺。
· 智能冗余设计:针对晶圆间工艺偏差(Wafer-to-Wafer Process Variation),引入智能冗余与自适应补偿机制,确保在物理连接存在微小误差时仍能维持电路的电气性能[2][15]。
3.3 逻辑折叠的进阶演进
V2版本明确了逻辑折叠技术的演进路径:
· 第一阶段(现状):在混合键合区域保留较厚的保护层(Spacer),键合区域仅作为“桥梁”,连接上下层的顶层金属层。
· 第二阶段(未来):随着工艺成熟,逐步去除保护层,实现“铜-铜直接连接(Direct Cu-Cu Bonding)”。这将彻底消除保护层带来的寄生电阻和电容,进一步降低垂直互联的延迟和能耗。
· 多层堆叠:未来将从双层有源层向三层、四层甚至更多层演进,实现真正的“摩天大楼”式芯片架构[15][16]。
第四章 移动端产品演进:麒麟(Kirin)芯片实证
韬定律V2在移动端的落地主要通过麒麟(Kirin)系列芯片体现。华为披露了从Kirin 9030 Pro到Kirin 2029的详细演进路线图,用实测数据验证了“时间缩微”的有效性。
4.1 麒麟2026:量产实测数据
作为首款采用逻辑折叠技术的量产芯片,Kirin 2026与前代基线产品Kirin 9030 Pro进行了详细的对比测试。测试条件统一为25℃环境温度。
表1 麒麟2026与Kirin 9030 Pro关键指标对比[2][14]
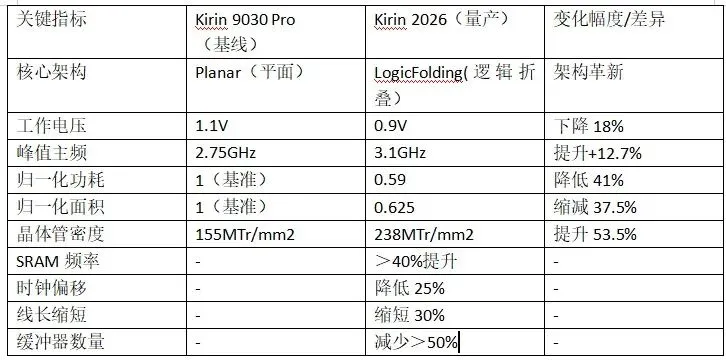
数据解读:
· 密度与性能的双重飞跃:在保持或提升性能的前提下,Kirin 2026实现了晶体管密度的大幅跃升(53.5%),这相当于在成熟制程上实现了摩尔定律三年才能完成的微缩量。
· 能效革命:得益于电压的降低(从1.1V降至0.9V)和互连延迟的缩短,芯片在同等性能下的功耗降低了41%。
· 系统级收益:逻辑折叠不仅提升了计算单元的性能,还显著优化了时钟树(Clock Tree)和SRAM等辅助电路,使其更适合高频高能效的应用场景。
4.2 2026-2029 年演进路线图
V2版本披露了未来的芯片迭代规划,显示出清晰的技术演进逻辑:
· Kirin 2026:已流片,进入硅片实测。主要验证逻辑折叠技术的可行性与基础性能提升。
· Kirin 2027:预期主频进一步提升至 3.39GHz。重点优化良率与稳定性。
· Kirin 2028:处于Pre-silicon设计验证阶段,目标主频 3.71GHz。
· Kirin 2029:处于Pre-silicon设计验证阶段,目标主频突破 4.0GHz。
· 这一路线图表明,韬定律正在为移动芯片确立新的性能增长曲线,使其能够绕开EUV光刻机的限制,通过架构创新逼近甚至超越先进制程芯片的性能表现[5][17]。
第五章 AI算力集群演进:统一总线与光互连
在云端AI算力领域,韬定律V2提出了“三层τ缩减架构”,旨在解决数据移动(Data Movement)带来的延迟与能耗瓶颈。
5.1 升腾(Ascend)系列演进
华为明确规划了昇腾系列AI芯片的落地节奏:
· Ascend 910C (2025):作为过渡产品,采用2.5D扇出型封装(Fan-out)技术,集成HBM存储,提升带宽。
· Ascend 950 (2026):引入“统一总线(Unified Bus)”架构,开始在系统层面优化通信延迟。
· Ascend 990 (2030):这是逻辑折叠技术在AI领域的关键节点。该芯片将首次在AI加速器中全面引入LogicFolding技术,实现多层有源层的垂直堆叠。
· 远期目标 (2035):通过上述技术的组合拳,预计到2035年,AI硬件系统的集成度将实现超过100倍的增长[18][19]。
5.2 三层τ缩减架构
为了实现这一目标,V2版本设计了包含以下三个层级的技术栈:
1.第一层:统一总线(Unified Bus / 灵衢)
· 技术原理:这是一种具备内存语义的系统级互连架构。
· 核心价值:它打破了传统计算、存储和网络之间的协议壁垒,实现了单一协议覆盖机柜内和跨机柜的通信。
· 量化收益:通过消除多层协议开销,端到端的远程访问延迟从传统的几十微秒(μs)量级大幅降低至约 100纳秒(ns),τ缩减幅度高达约 500倍[20]。
2.第二层:Hi-one近封装光引擎
· 技术原理:将微型硅光子收发器直接封装在AI芯片的附近(Near-chip)。
· 核心价值:利用光信号进行数据传输,彻底解决了铜导线在高频下严重的信号衰减和串扰问题。
· 量化收益:提供高达 8 TB/s 的互联带宽,将芯片间的互联距离从传统的百米级(通过集线器)缩短至封装内的厘米级,极大地降低了功耗和延迟[18]。
3.第三层:3D折叠与资源重构
· 技术原理:通过3D堆叠技术,将高带宽内存(HBM)、SerDes收发器和电源模块等资源,从芯片的边缘(Perimeter)转移到封装的表面(Surface)。
· 核心价值:这种“边缘到表面”的重构使得芯片核心区域的面积可以完全用于计算逻辑,实现了计算资源与I/O资源的同步缩放,解决了2.5D芯片在扩展性上的物理瓶颈[20]。
第六章 产业链深度解析与受益标的
韬定律V2的实施将重塑半导体产业链的价值分配,使得封装、设备、EDA和材料环节的重要性显著提升。根据产业链受益程度的不同,可将其划分为核心受益与强受益两大梯队。
6.1 核心受益:先进封装与设备(确定性最高)
这一环节是韬定律V2落地的物理基础,也是资本开支增长最显著的领域。
· 先进封装(Advanced Packaging)
· 长电科技(600584):作为国内封测龙头,其XDFOI高密度异构集成平台已具备量产能力,是华为麒麟与昇腾芯片的核心封测供应商。
· 通富微电(002156):深度绑定AMD等国际大厂,在Chiplet及2.5D/3D异构封装领域拥有领先的量产能力,能够承接复杂的逻辑折叠订单。
· 华天科技(002185):在SIP及系统级封装领域处于国内领先地位,同时具备3D IC封装能力,是光互连芯片封装的重要参与者。
· 深科技(000021):专注于高端存储芯片的3D堆叠封装,是存储资源垂直整合的关键力量。
· 半导体设备(Equipment)
· 拓荆科技(688072):作为国内唯一量产混合键合设备的厂商,其键合设备是实现“逻辑折叠”中微米级间距互连的“卡脖子”环节,直接受益于3D堆叠工艺的普及。
· 北方华创(002371):国内半导体设备平台型龙头,其刻蚀、沉积及清洗设备广泛应用于TSV加工、混合键合前处理等工艺步骤。
· 中微公司(688012):在高端刻蚀设备领域具备国际竞争力,同时也是TSV及混合键合设备的重要供应商。6.2 强受益:EDA、材料与光互联(弹性最大)这一环节受益于设计复杂度的提升和新架构的引入。
· EDA与IP(EDA & IP)
· 华大九天(301269):逻辑折叠导致芯片设计从2D平面变为3D立体,这对EDA工具提出了全新挑战。华大九天是国内唯一具备3DIC全流程设计能力的厂商,其Argus平台能够支持多层有源层的协同设计,处于卖水人地位。
· 概伦电子(688206):在器件建模与时序仿真领域具有深厚积累,能够支持复杂的3D工艺与材料特性分析。
· 光互联与PCB(Optical Interconnect)
· 中际旭创 / 新易盛:受益于“统一总线”架构对高速光模块(800G/1.6T)的需求激增。
· 天孚通信:光引擎中的精密元器件(如光引擎支架、保偏光纤等)核心供应商。
· 深南电路 / 生益电子:AI算力集群对高频高速PCB及IC载板的需求将推动高多层板及HDI板的增长。
· 电子材料(Materials)
· 鼎龙股份:随着3D堆叠层数的增加,对底部填充胶(Underfill)、临时键合胶及CMP抛光垫的需求量将大幅增加。
· 华特气体:先进制程中对电子特气的纯度要求极高,以降低漏电损耗。
第七章 结论与展望
华为“韬定律”V2版本的发布,不仅是一次技术路线的修正,更是一场产业范式的转移。它成功地将半导体产业的竞争维度从单纯的“空间微缩”拉升至“时间压缩”,为后摩尔时代及受限技术环境下的产业发展指明了新方向。
通过麒麟2026芯片的量产实测,我们看到了晶体管密度提升53.5%、能效比提升41%等令人信服的数据,这些数据有力地证明了“逻辑折叠”技术的工程可行性。同时,面向未来的路线图——Kirin 2029突破4GHz主频、AI集群2035年集成度增长100倍——描绘了一个清晰且极具竞争力的前景。
对于中国半导体产业而言,韬定律V2意味着成熟制程的价值重估。通过架构创新与先进封装,14nm/28nm等成熟节点依然能够产出具备顶级性能的芯片,这极大地缓解了对先进光刻机的依赖。未来5-10年,围绕“时间常数τ”进行的系统级创新,将贯穿从设计(EDA)、制造(晶圆+设备)、封测(先进封装)到互联(光通信)的全产业链,催生出新的技术巨头与投资机会。
注:本文由AI综合整理自公开数据资料分析,仅为个人学习笔记,仅供参考交流,不构成任何投资建议。市场有风险,决策需谨慎。