



AI科普馆部分垂类内容转移至?
【长三角人工智能联盟】公众号,快点进去瞧瞧!
2024年,三件事几乎同时落地:欧盟AI法案正式生效,违规罚款最高全球年营业额6%;中国算法备案制度全面推行;美国6个州通过AI相关立法。三套逻辑完全不同——欧盟用风险分级强制监管,中国用备案制穿透到底层,美国靠州法碎片化试水——但指向同一个事实:AI治理已不是"做不做"的问题,而是"怎么做才能过关"。
DAiMA发布的《2026人工智能治理白皮书》96页,给出了当前国内覆盖最完整的AI治理操作框架。核心拆成六个模块。
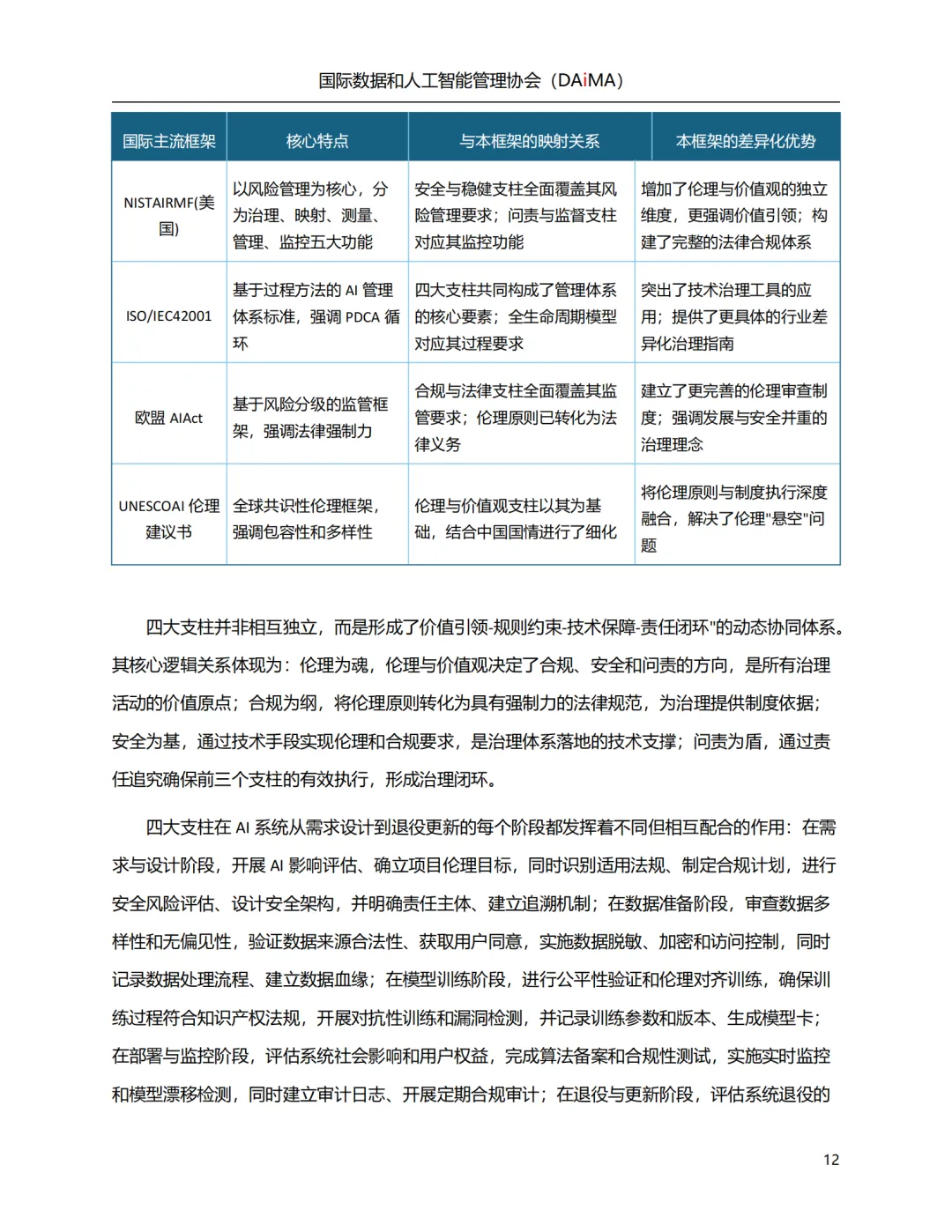
四大支柱:不是四份独立清单,是一个闭环
伦理与价值观、合规与法律、安全与稳健、问责与监督——白皮书的四根柱子有明确的递进关系:伦理定方向,合规转强制,安全做兜底,问责关闭环。缺任意一环,体系就会在某个节点断裂。
两个差异化:一是"可持续发展"被列为贯穿四者的顶层原则,部分国家已开始要求披露AI碳足迹;二是与NIST AI RMF和欧盟AI法案相比,白皮书将伦理维度独立化——不是某一条款的子项,而是需要独立评价机制的治理科目。
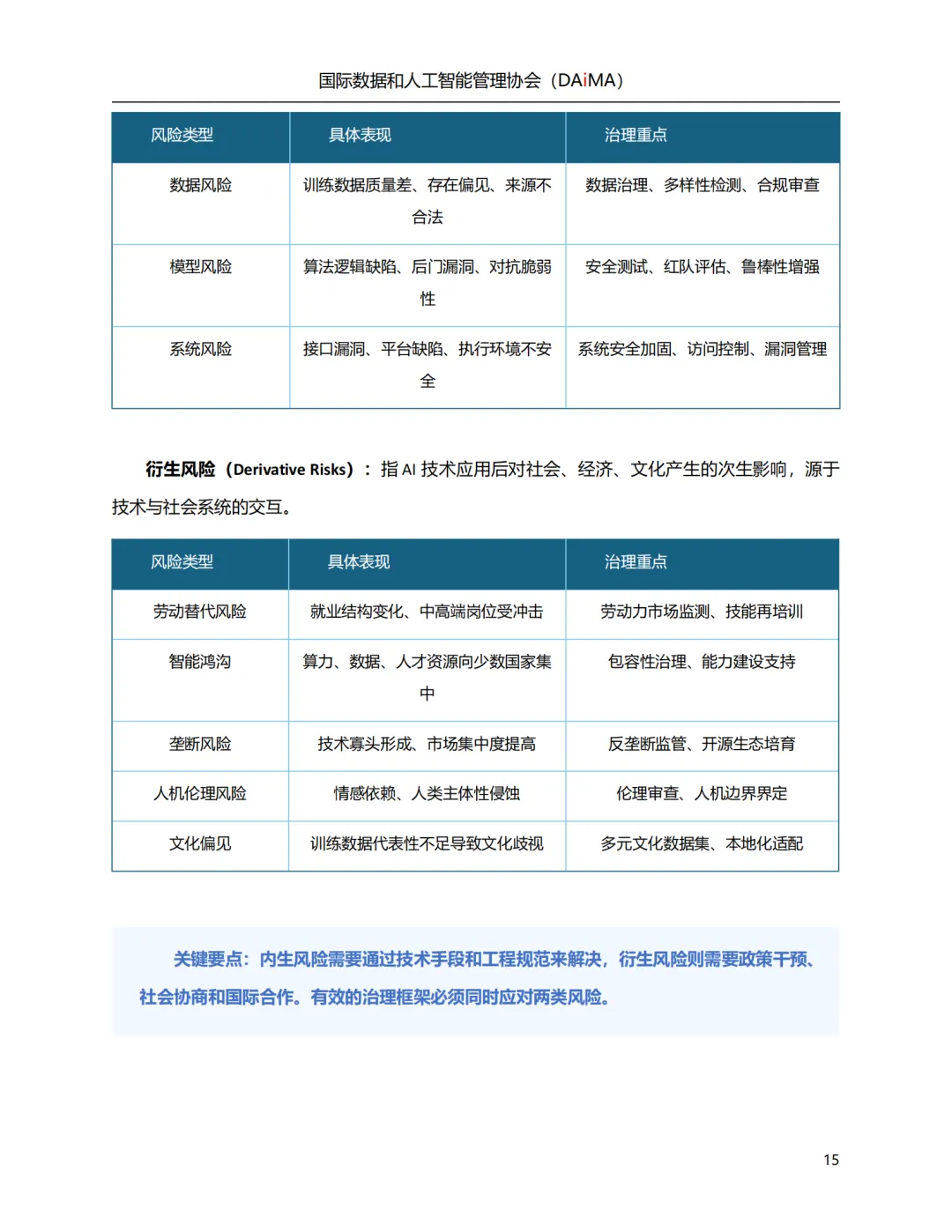
风险三层:每层对应一种治理盲区
- 内生风险:模型自身有缺陷——数据偏见、后门漏洞、对抗样本攻击。靠技术手段解决。
- 衍生风险:模型没问题,社会有伤害——就业替代、深度伪造污染、智能鸿沟。靠政策干预。
- 行为风险:人怎么用的问题——误用靠教育,滥用靠权限,恶用靠法律和跨境执法。
三层叠加的实用价值:一个企业如果只做了模型安全评估(对内生风险),却没做过AI上线的社会影响评估(对衍生风险),治理就是半截的。
三大法域三套逻辑
- 欧盟:四层风险分级——不可接受风险直接禁止,高风险系统须合格评定、嵌入人类监督,罚款最高全球年营业额6%或3500万欧元。
- 中国:备案+审查四道门槛——算法备案、内容标识、数据出境安全评估、训练数据来源合法。
- 美国:联邦无统一立法,加州、科罗拉多等州各自推进,联邦贸易委员会靠反歧视条款"间接执法"。
白皮书指出了一个关键的出海难题:欧盟AI法案具有域外效力——只要AI输出在欧盟境内被使用就受管辖。不管总部在哪,合规基线正被欧盟标准间接锁定。应对策略是"最高标准+本地适配"双轨制。
两类被低估的新风险
"AI中转站":整合多家大模型接口转售的代理平台。风险包括截留倒卖用户数据、以低配模型冒充高端产品、通过后门植入恶意代码。中国AI生态的灰色地带,监管几乎空白。
AI Agent自主性风险:Agent不是更聪明的API——被授权代表人在真实环境中规划、决策、执行,权限一旦从咨询延伸到签约付款,风险从信息泄露升级为资金损失。四个维度:
自主权边界决定风险敞口 权限粒度决定破坏半径 上下文实时变化使静态安全评估失效 多Agent协作时单点失效可逐级放大
防护方案:分级授权 + 最小权限 + 不可绕过的人工检查点 + 行为审计链。"不可绕过"是重点——不能让Agent自己决定什么时候需要人。
技术工具箱:四项直接咬合硬性合规
白皮书列了17项工具,挑出四项直接对应具体法规的:
- 数据血缘追踪:欧盟AI Act要求高风险系统完整技术文档,中国要求训练数据合法来源。不知道数据从采集到训练的全路径,合规声明就是空话。
- 持续漂移检测:模型上线后数据分布和用户行为在变,准确率和公平性会静默退化。没有检测,可能直到用户大规模投诉才发现模型已跑偏数月。
- 红队测试:从攻击者视角突破安全边界。白皮书案例:某社交平台推荐AI在测试中被发现可通过特定关键词触发仇恨内容推荐,上线前补了漏洞。
- 机器反学习:从模型中"撤销"特定训练数据,直接回应GDPR被遗忘权和PIPL删除权。
成熟度五级:65%的权重压在"能管住"
五个维度的权重分配:
技术工具+监控审计合计65%。信号很清楚:AI治理的瓶颈不在"有没有政策和委员会",而在"模型上线后能不能实时监控、出了问题能不能追溯倒查"。
白皮书建议每6-12个月做一次成熟度自评。真正的坎是从"有制度文件"跨越到"有监控审计执行"——65%的权重压的就是这个跨越。
趋势信号
白皮书总结了七项趋势,几条有实质判断价值:
从"事后追责"向"设计即治理"转移——合规工作须更早嵌入开发流程; 从"软准则"到"硬约束"——伦理原则加速转化为法律义务,不是趋势预测而是已发生的现实; 可持续发展成为硬指标——AI碳足迹披露要求形成中,技术选型将受"绿色AI"标准约束; 技术治理与制度治理深度融合——差分隐私、可解释AI等工具从研究方向转变为监管执行手段。
本文基于国际数据和人工智能管理协会(DAiMA)《2026治变:人工智能治理白皮书》撰写,详细内容请查阅原文。
以下是内容节选↓↓↓ 文末点击链接免费下载pdf,扫二维码加入交流群














AI科普馆:打开AI世界之窗

