


刚看到 OpenAI 发布了 GPT-5.6,分 Sol、Terra、Luna 三个档,各种测评性能果然又一次超过了 Claude(包括已经被禁用的 Fable 5)。不过应该是被 Anthropic 模型被禁的问题拖累了,只开放给了一些合作伙伴,普通人暂时用不上,只能眼馋了。
对我们来说,最重要的还是把手头的模型和工具用好。这不,翻到了 OpenAI 一份 27 页的白皮书,作者 Jason Liu 是 Codex 团队的开发者体验工程师。他把怎么让 Codex 的工作不断线这件事讲透了,关键在于把上下文、记忆、工具、定时任务和审查机制组成一个持续运转的工作台。
白皮书总共 10 个模块,构成一个完整闭环:上下文 → 工具 → 记忆 → 定时检查 → 审查。这五个环节哪个缺了,Agent 都可能会退化为一个更烧 Token 的聊天机器人。下面逐个拆解看看。
一、重要工作应该有个固定的家
第一个观点是别让重要工作散在不同的对话里。
把关键工作流都固定成持久会话线程。每个线程对应一个具体的工作域,比如有管 CLI 命令规范的,有管开源项目 issue 的,有专门追踪社交反馈的等等。
这样一来,上下文会随时间积累,旧决策不会丢,之前的工作都留在里面,并且会话上下文超出后会主动压缩。代价当然也有的,长线程会越来越贵,每次回来都要加载前面的历史。但对关键工作流来说,这个成本是值得的。
二、语音输入给 AI 的信息质量反而更高
这是为什么呢?
因为人说话时会把那些打字时觉得不好意思写出来的模糊想法也说出来。比如我记得 Slack 里有个叫 Ben 的人提过这个事,具体忘了,你去翻翻。这种指令打字很别扭,但说出来就很自然。而这恰恰是 AI 最需要的上下文。
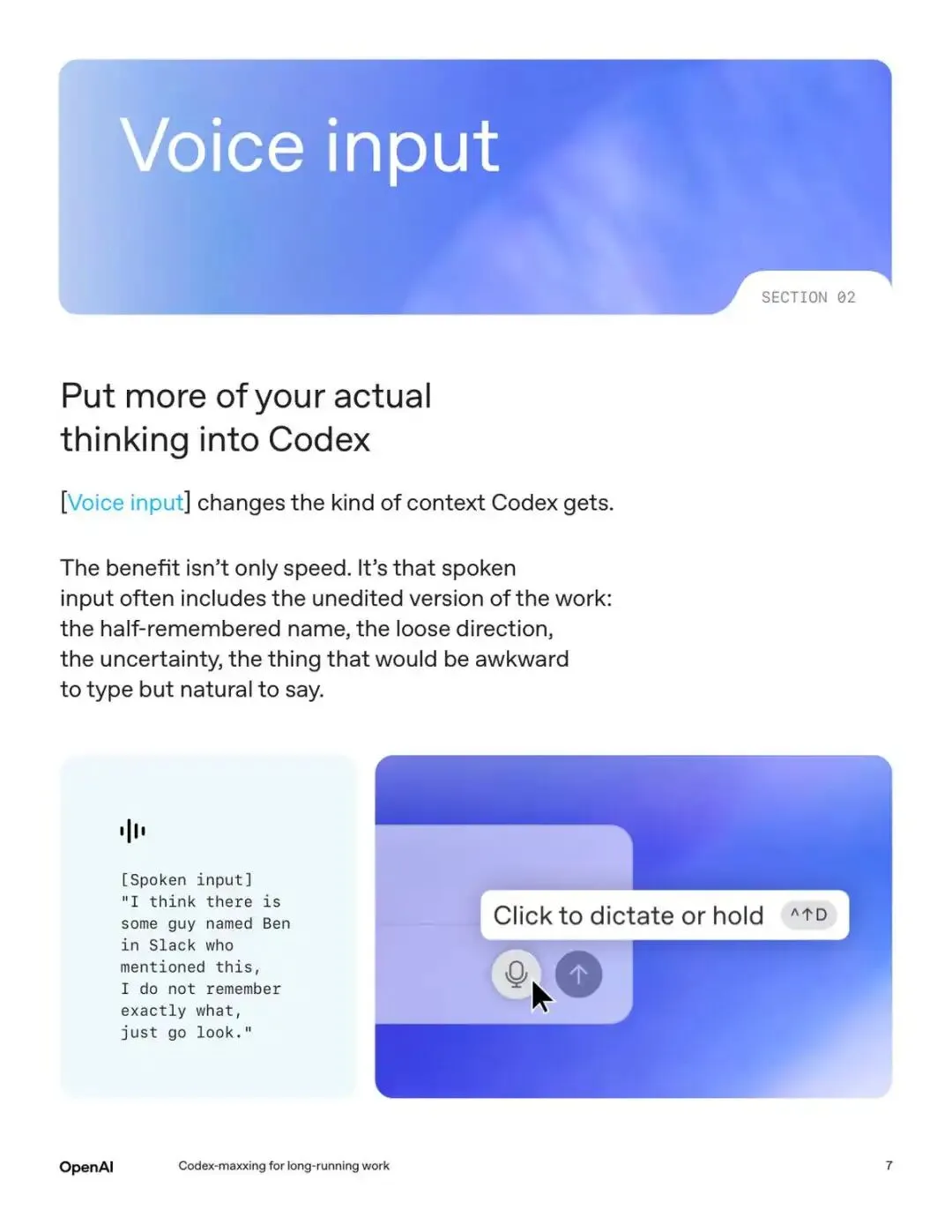
让模型拿到你思考的原始版本,而不是你精心整理/清理过的版本,很多计划反而会执行得更好。
三、不用等它做完再说不对
Codex 在执行任务的过程中,你随时可以追加指令,不用等它跑完再推倒重来。
它在跑的时候你就可以插一句,这个做小一点、这段代码不对,甚至追加后续步骤,做完之后顺便开个 PR。
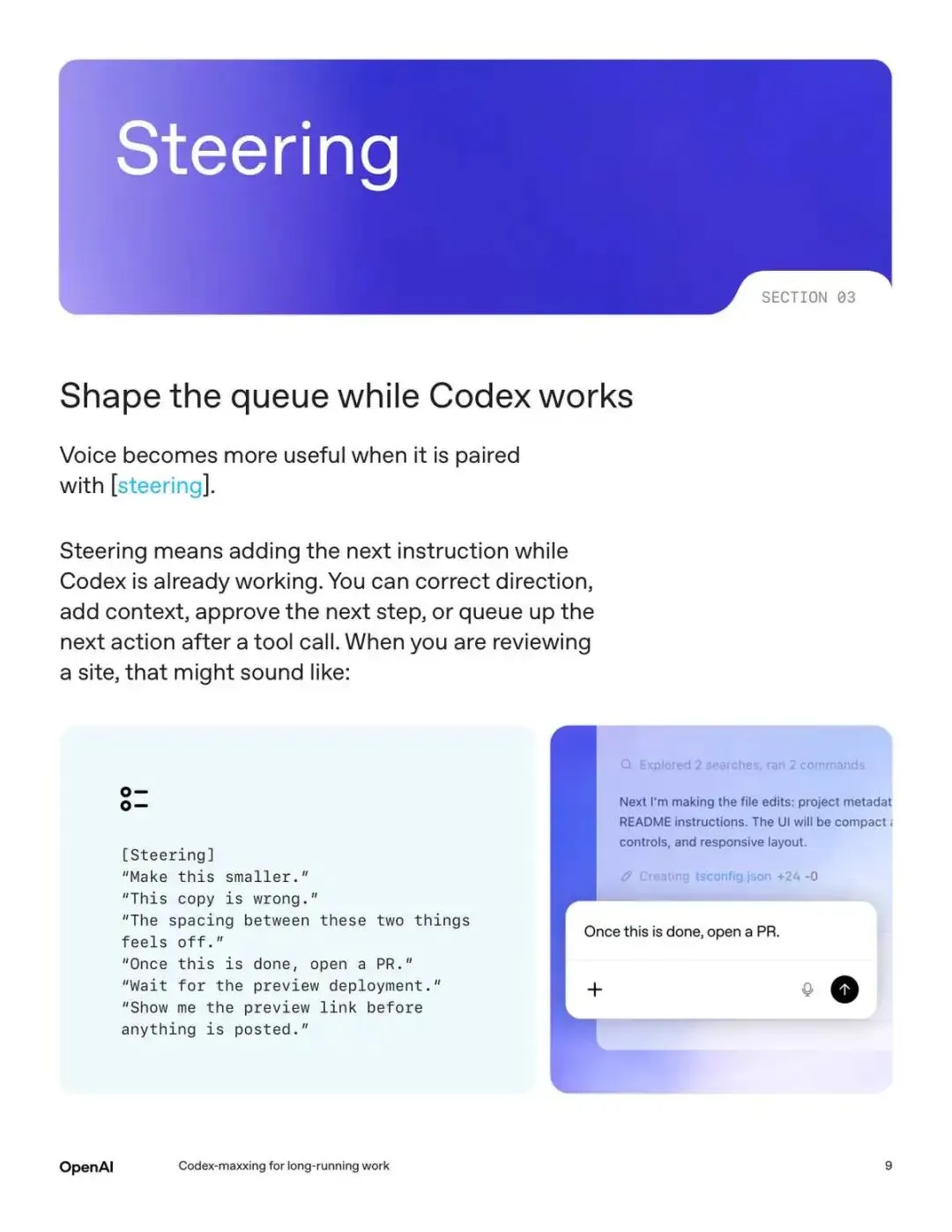
交互模式从一来一回变成了持续塑形,你在塑造一个正在进行的过程,随时可以调方向。这跟 Claude Code 的 Queuing 功能很像,但 Codex 把它做得更显性了。
四、光靠聊天历史是不够的
随着线程变长,对话历史翻起来越来越痛苦。有用的上下文应该变成可以打开、编辑、对比和复用的文件。
白皮书里用的是一个叫记忆库(vault)的文件结构:
vault/├── TODO.md├── people/├── projects/├── agent/└── notes/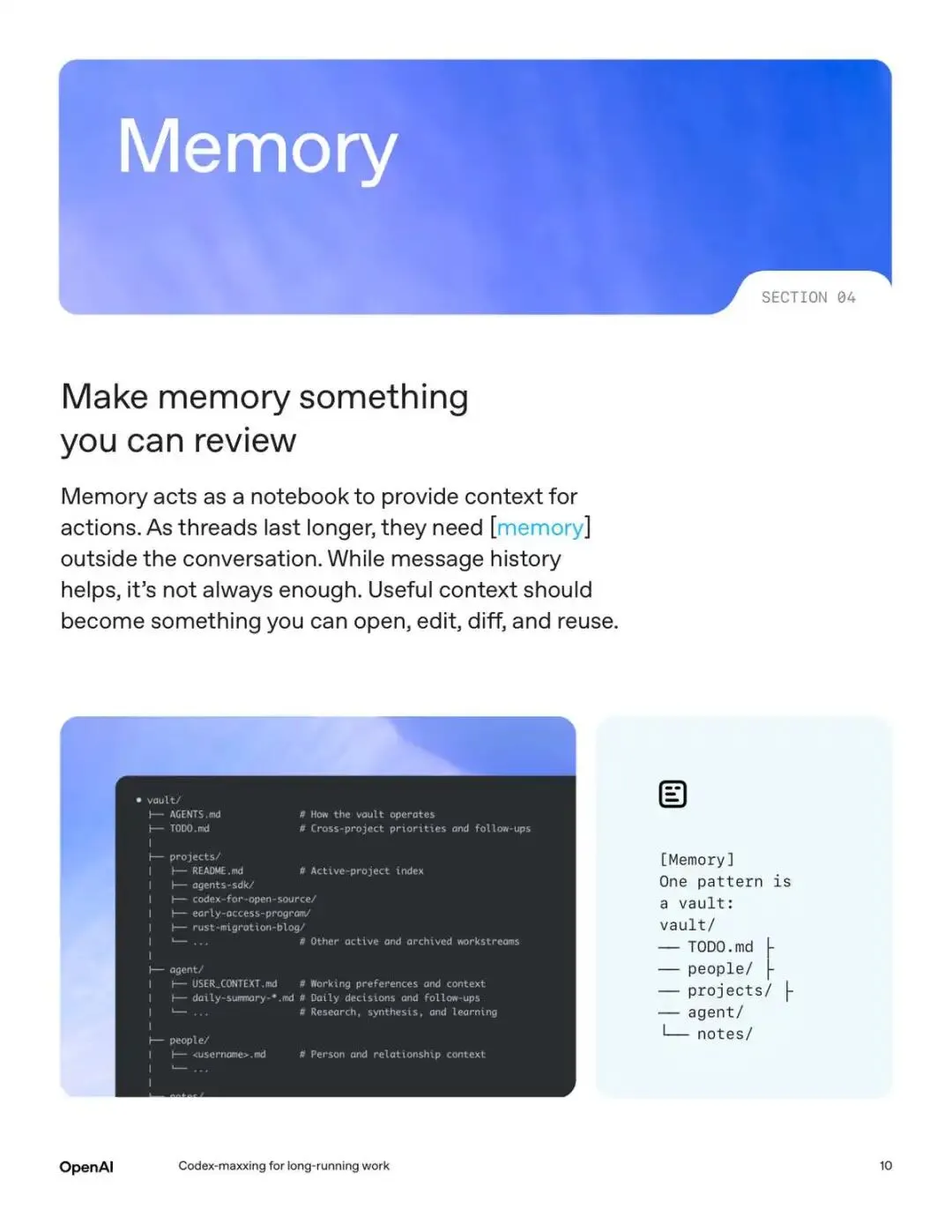
要点是区分这两件事:Git 仓库放代码,记忆库放工作的流动上下文。人、决策、还没关闭的待办、日常笔记、项目状态,这些都放记忆库里。
记忆库放在 GitHub 上,这样每次 Codex 更新记忆库都会产生变更记录。变更记录就变成了记忆的审查界面,你能看到 AI 认为什么值得记下来。
那什么时候该写记忆呢?白皮书列了四条触发规则:
• 有人被提到 → 更新人物笔记 • 项目推进 → 更新项目页 • 待办关闭 → 标记已完成 • 有决策 → 写下决策和原因
这个思路跟我自己做的数字分身记忆系统几乎一模一样。我的 notes 仓库里也是用 OBSERVATIONS.md 和 REFLECTIONS.md 做分层记忆,用 git diff 做审查。这样做还有一个好处是记忆跟 Agent 解耦了,相同的记忆库可以方便共享给 Codex、Claude Code、Hermes 等各种 AI Agent。
五、AI 能操作什么?
线程有了记忆之后,下一个问题是它能真正帮你干啥。
Codex 内置了很多跟外界打交道的工具,大致可以分成五类:本地浏览器预览、需要登录态的 Chrome 页面、桌面操作、第三方连接器(比如 Slack、Gmail、日历、GitHub 等),以及可复用的技能包。原则也简单,接口能搞定的就别动图形界面,重复的活儿打包成技能。

六、人可以不在工位,但任务不能卡住
这估计是老板们最想看到的功能了吧!Codex 支持从手机远程查看和操作正在运行的任务。
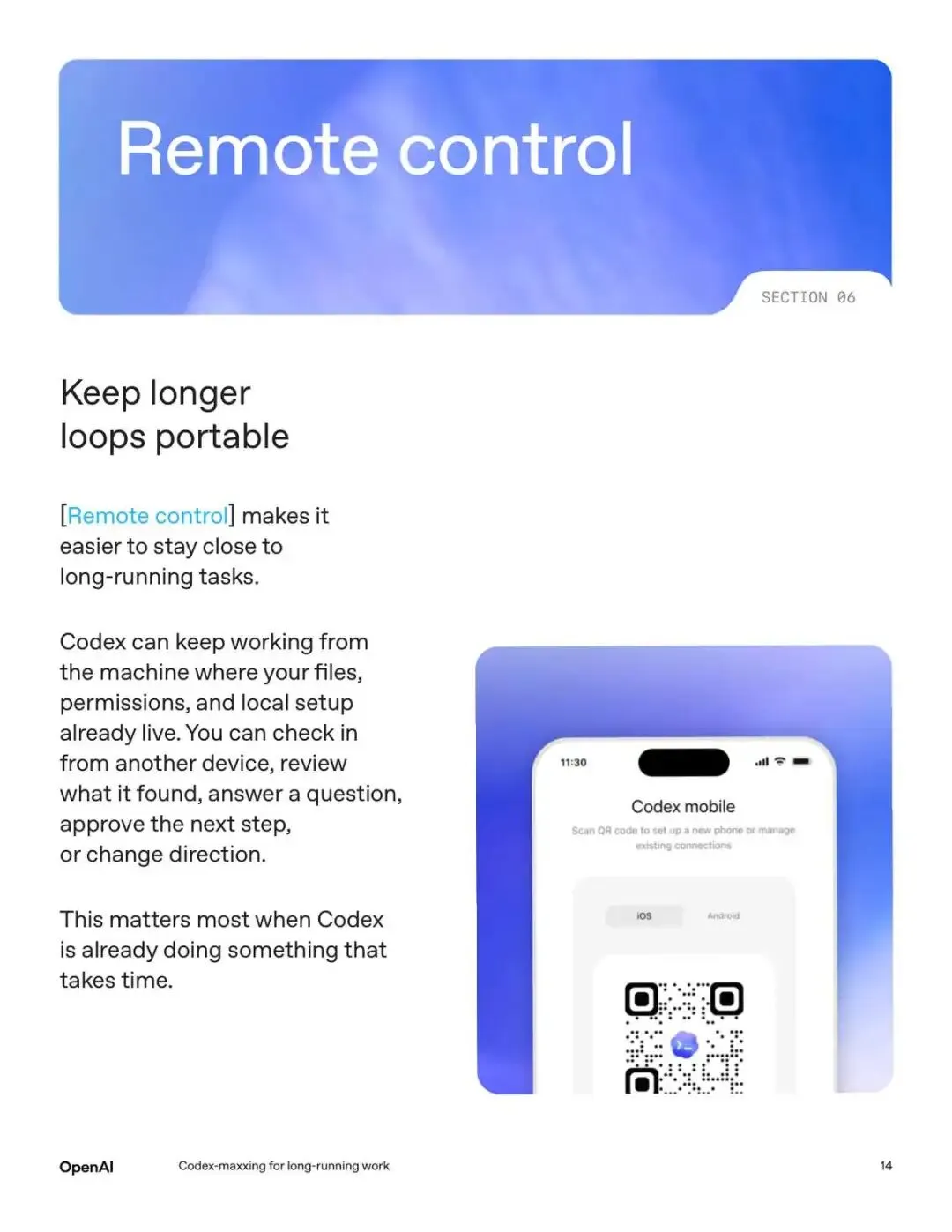
无论你是去开会还是上个洗手间,活不能卡住。在电脑上启动任务后,离开工位去开会,到了决策点手机收到通知,批准、改方向或者换个思路。这样关键决策点能够随时介入,但人却不需要一直盯着屏幕了。
七、让 AI 自己回来检查
这部分最接近自主 Agent 的边界了。
线程自动化是绑定在会话线程上的心跳式定时任务,告诉 Codex 按照固定节奏回到这个对话,保持上下文,不要从头开始。

这跟普通提示词有什么区别呢?普通提示词是你告诉它现在做这个,做完就结束了。线程自动化不一样,它会持续盯着,有变化就自己往前推。
再往前走一步,一个线程可以有多个定时计划,可以设置条件退出,也可以随着任务变化调整频率。因为和线程上下文绑在一起,不用每次重新交代背景。
八、三个实战循环
白皮书给了三个完整的循环示例,每个都清楚地划分了 Codex 准备什么和人决定什么。
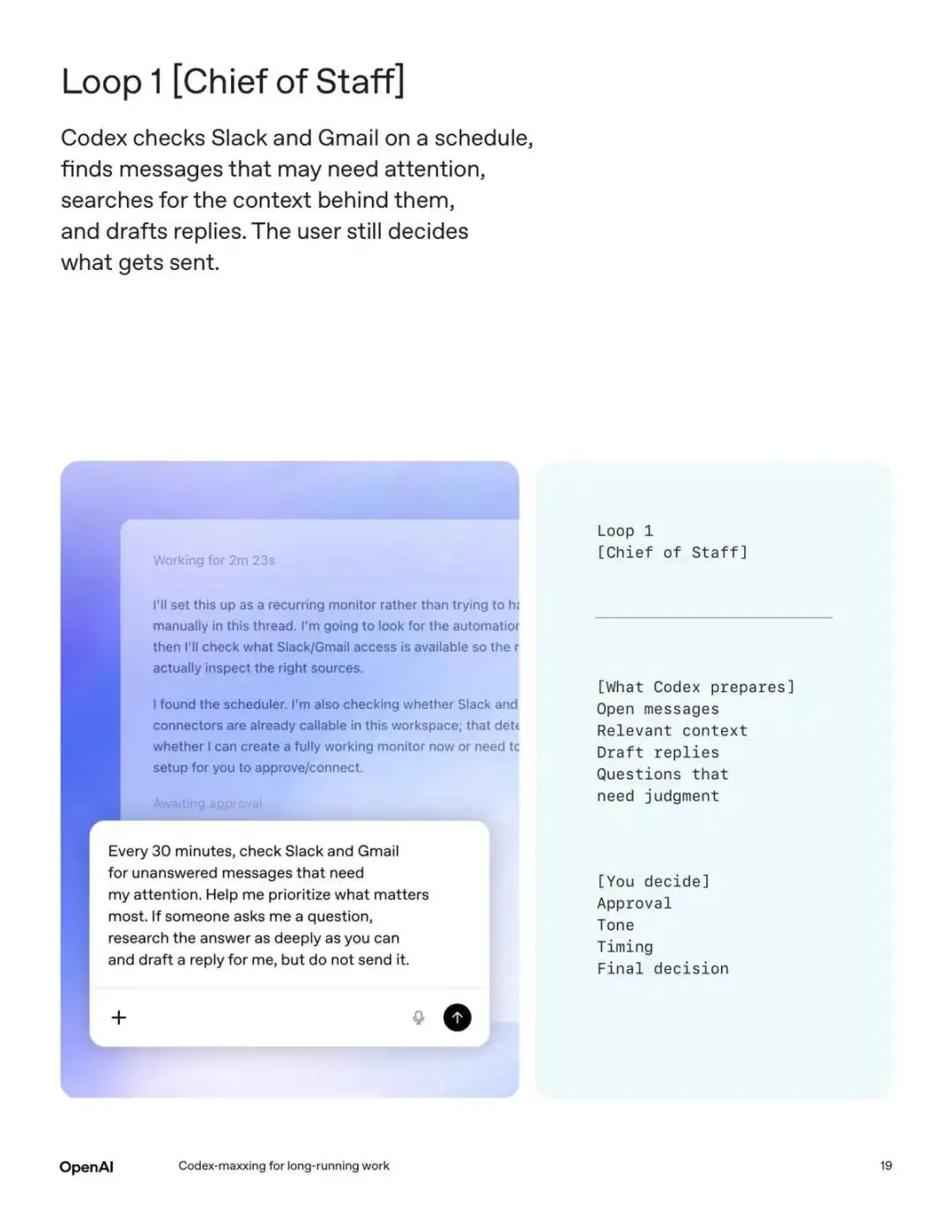
Loop 1:Chief of Staff
Codex 每 30 分钟检查 Slack 和 Gmail,找到需要关注的消息,搜索相关上下文,起草回复。你打开手机看到的不是一堆未读消息,而是整理好的待办清单和草稿,拍板发送就行。
Loop 2:Monitor for Feedback
第二个场景更自动化一些。Codex 每个工作日早上检查一个 Slack 频道里的用户反馈,更新 Remotion 项目,重新渲染,准备修改版供审查。反馈进来、代码改完、渲染跑完,人只需要做最后的创意判断。

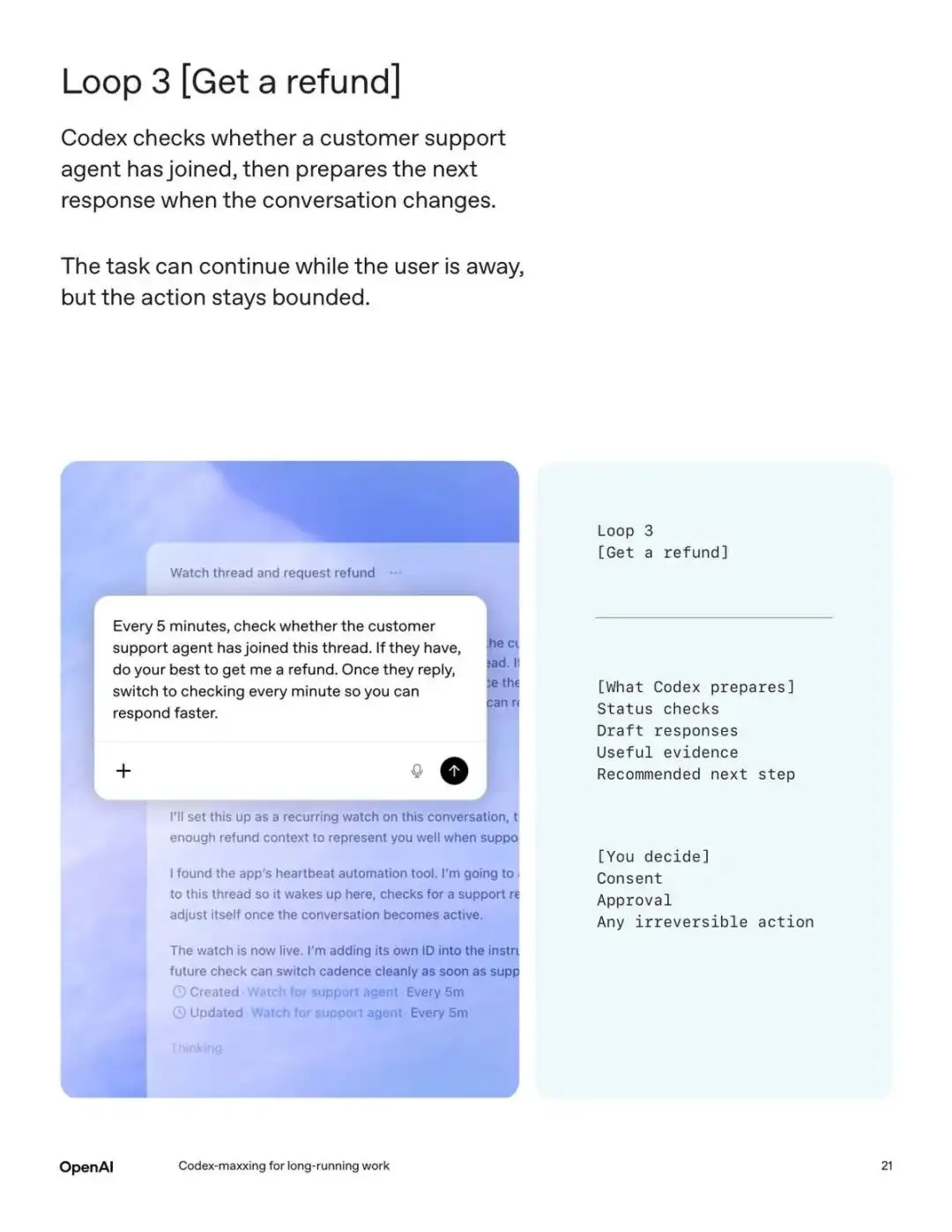
Loop 3:Get a Refund
第三个最有意思。Codex 每 5 分钟检查客服线程里有没有人工客服加入。一旦检测到真人,自动切换到每分钟检查一次,准备下一轮回复的草稿和证据。你要做的就是看一眼草稿,觉得没问题就批准发送。
三个场景都是类似的,Codex 干活,人来拍板。任务在你不在的时候照样推进,但所有重大决策都卡在人手里。
九、怎么给 AI 设目标
目标设得好不好,直接决定 Codex 能不能高质量完成你分配的任务。
比如按照这个 Markdown 文件实现这个计划,看起来有目标,但做完之后没法自我验证。换一种写法:把这个库移植到 Rust,保持公共 API 兼容,用原来的单元测试作为验收标准,测试通过且差异已记录,工作才算完成。

后者给了 Codex 一个可以自己跑的验收条件。
就像我之前聊 Codex /goal 时说的,没有验证条件的目标,只能是个愿望,跑好跑坏全靠运气。
十、侧边栏
侧边栏不只是看看输出结果的预览窗口,还可以用来可以检查 Codex 正在操作的对象,加评论、审查变更、把产出物保留在线程里等等都可以在这里完成。
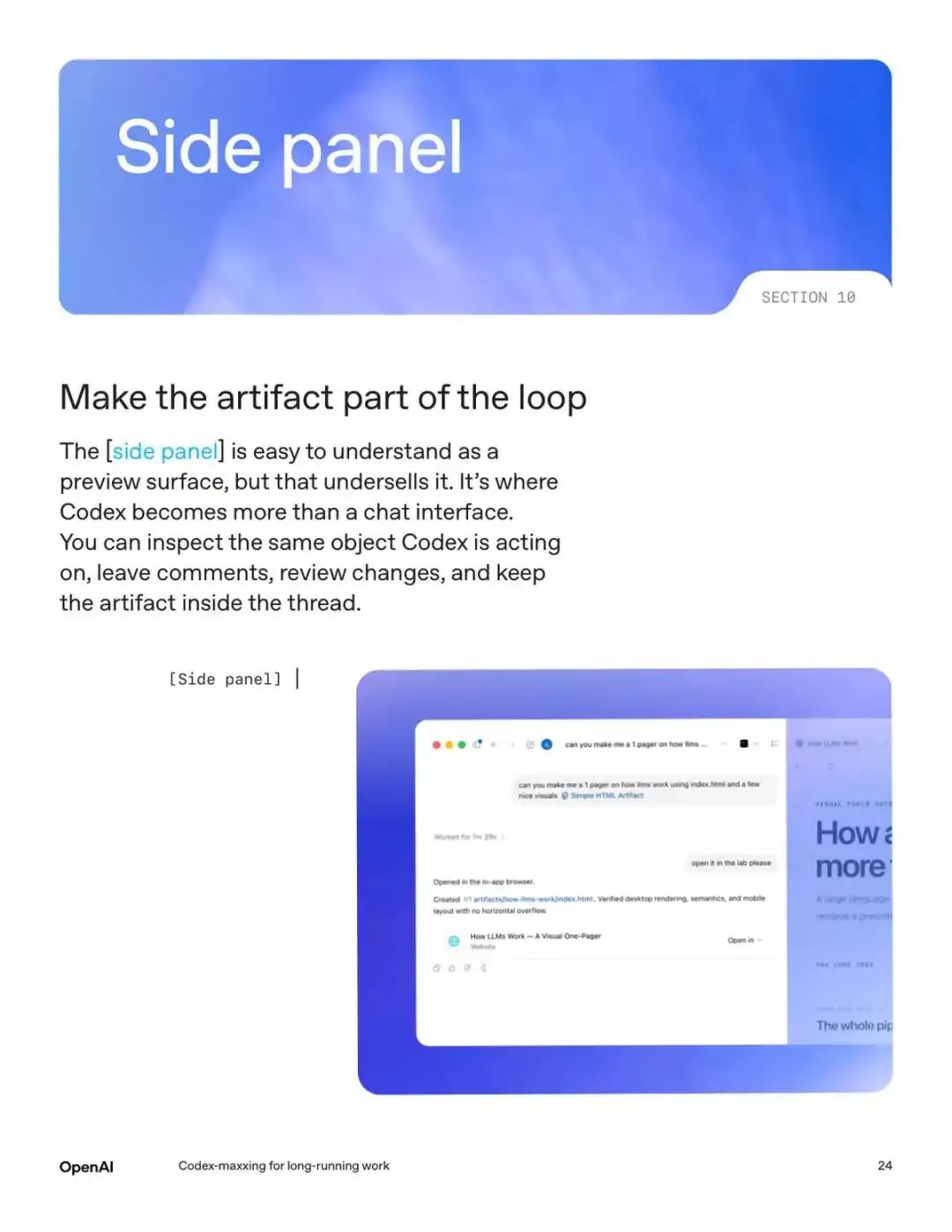
侧边栏支持的格式挺广的,Markdown、表格、CSV、PDF、幻灯片都能渲染。甚至一个 HTML 文件加点 JavaScript 就能变成可交互的工作面板。说白了,侧边栏是 Codex 从聊天应用变成工作台的关键界面。
写在最后
读完这份白皮书,给我触动最大的是这 10 个模块组合起来的闭环。上下文让 Agent 知道自己在干嘛,工具让它碰到真实世界,记忆让经验留下来,再加上定时检查和人工审查,整个系统才能持续转起来。少了哪一环,都可能退化成一个更烧 Token 的聊天机器人。
推荐完整读一遍原文,不管你用的是 Codex、Claude Code 还是别的 Agent 工具,这个闭环的思路都是通用的。
原文链接:https://openai.com/index/codex-maxxing-long-running-work/
如果你也在探索 AI 编程和 AI Agent,欢迎关注 Feisky,我会持续分享实践中的发现和踩坑。