



文本数据快被"吃光"了,下一个AI战场在物理世界——而决定谁能赢的,不是模型,是数据。
一、先搞懂:什么是"具身数据"?
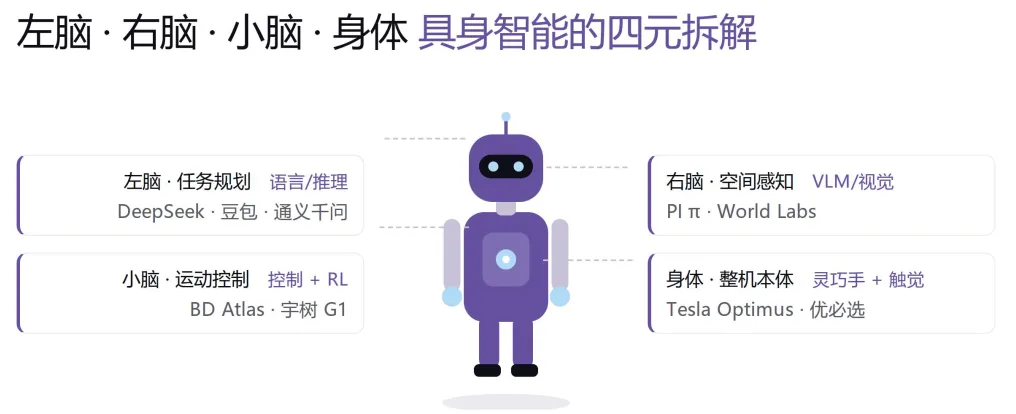
AI过去十几年主要在"数字世界"卷——啃网页、啃书、啃代码。但具身智能(Embodied AI)不一样,它要让机器人真的走进工厂、家庭、医院,去"动手"。
⚡这就带来一个问题:
? 互联网上能爬到的文本差不多被吃完了,但具身数据没法从网上扒——你必须让机器人真的去抓、去走、去碰,才能拿到"动作-视觉-语言"对齐的数据。
报告给了一个很震撼的对比:
? 具身数据 vs 文本数据可用量级差距:约 20,000 倍也就是说,LLM 喂的是"海洋",具身模型喂的是"水滴"——数据稀缺,是2026年这个行业最大的卡点。
二、市场有多大?三套口径别看错
报告给了全球、中国、美国三套口径,定义不同不能直接加(这点很关键):
口径 | 代表机构 | 2030-2050 预测 | 备注 |
|---|---|---|---|
全球(人形本体) | 高盛 | $38B / 2035 | 仅本体硬件 |
全球(含供应链+服务) | 摩根 | $5T | TAM 全口径 |
全球(含非人形) | 花旗 | $7T / 2050 | 最宽口径 |
中国(用户支出) | IDC | $77B / 2030,CAGR 94% | 高增长 |
中国(本体销售) | 中金 | 581 亿元 / 2030 | 偏保守 |
? 一句话:如果只盯本体硬件,是百亿美金级;如果把供应链、服务、非人形都算上,是万亿美金赛道。差两个数量级,看你怎么定义。
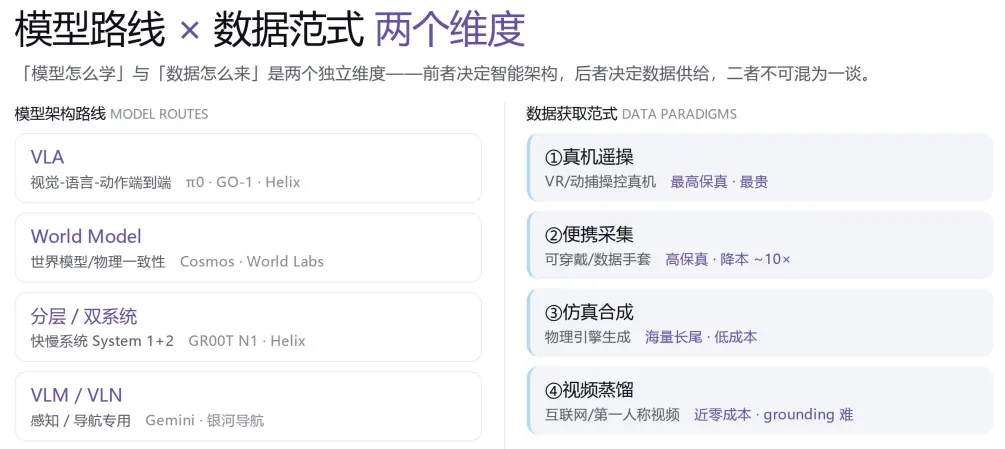
三、具身数据的"四层金字塔"
?这是白皮书最核心的框架,也是行业共识(参考 NVIDIA GROOT):
? 真机遥操(VR/动捕) / 保真最高、最贵、最难规模化 / / ? 便携采集(数据手套) / 降本 ~10x,性价比平衡点 / / ? 仿真合成(物理引擎) / 成本≈真机 1/100,覆盖长尾 / ? 人类/互联网视频(蒸馏) 近零成本,但缺动作标签、grounding 难?越往上越贵越真,越往下越便宜越海量——主流训练范式是"底层预训练 + 顶层精调",混合喂。

四、价值链:谁在赚大钱?
白皮书有个很关键的判断——价值链利润在往上游数据层迁移:

毛利逐级抬升,资产化环节 60-70%
⚠️ 本体硬件反而趋于薄利。这意味着:"卖铲人"比"挖金矿的"更肥——Figure 估值 $39B 是整机,但光轮、它石这种纯数据公司估值也在百亿人民币级,且毛利更高。
?商业模式——三种变现模式:
数据集授权(一次性卖)
DaaS 订阅(持续喂数据,复购率高)
评测基准服务(光轮的 RoboFinals 就是这条路)
五、中美双轨:闭源飞轮 vs 开放分工
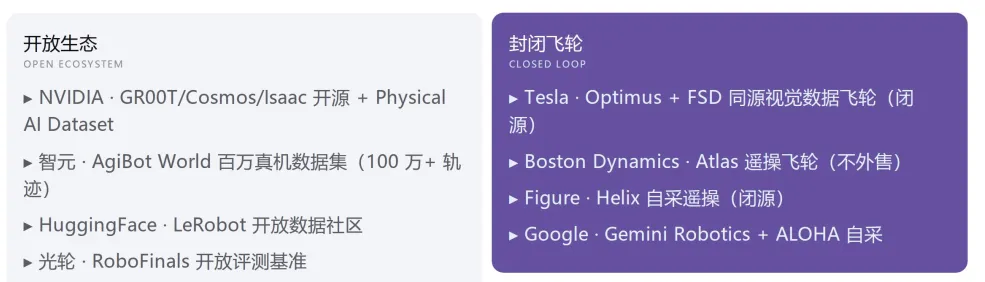
这部分是白皮书的精华对比:
维度 | ?? 美国 | ?? 中国 |
|---|---|---|
数据来源 | Scale 等巨头 + 大厂自采 | 遥操工厂 + 便携 + 仿真 + 蒸馏并行 |
核心打法 | 闭源飞轮(Tesla/Figure 自建闭环) | 开放+专业化(独立数据公司分工) |
代表 | Figure 39B、PI5.6B、Skild $14B | 光轮、它石、帕西尼、智元 |
优势 | 算力/人才/基础模型 | 工程化快、采集成本低、场景多 |
整机出货 | 谨慎 | 宇树 5500+ 台领先 |
❌??? 走"苹果式"——自己采自己练自己卖;
⭕??? 走"安卓式"——数据公司、本体公司、模型公司各切一段,更容易长出数据交易市场。
六、2026 = 具身数据规模化元年,三个信号

报告给的 Five Key Insights 浓缩一下:
数据成卡点:2026 真机+仿真+视频混合数据开始爆发
VLA 三年十倍:RT-1 → π0.5 → GROOT,任务成功率 3 年涨 10x
世界模型崛起:2027+ 进入 World Model 阶段,数据需求跳到千万-亿小时级
仿真合成验证可独立估值:光轮独角兽就是信号
中国场景红利:工业、物流、医疗已经开始落地商业化
七、给从业者的几句话
做本体的别只卷硬件,数据飞轮才是壁垒(看看 Tesla Optimus + FSD 同源视觉飞轮)
做数据的四范式里,"仿真合成"已经跑出独角兽,"视频蒸馏"还没出头部,是窗口期
投资视角价值链往上游迁,资产化环节 60-70% 毛利比本体香
风险点UBS 已经警示估值领先商业化,Sim2Real 鸿沟、数据合规、标准缺位都是坑
报告来源:艺恩数据《2026全球具身数据市场白皮书》,数据截至 2025-05
详尽报告后台回复“2026627”查看原报告,仅供研究参考
