


最近,我看到好多朋友都在参考我那篇文章《亿级品牌化卖家,到底怎么做用户洞察?》做用户洞察工具。
挺高兴的。
这说明一件事:大家都开始吃到"懂用户"这块价值了。
要知道,两三年前,跟同行聊用户洞察,十个里有九个跟你聊关键词、聊广告、聊坑产。
现在不一样了。越来越多的人意识到——
真正的胜负手,在评论区里那一堆用户原声里。
既然这个方向大家都在做,那我也别藏着了。
今天这篇,我把自己从去年年底开始打磨到 4 月的这套用户洞察工具,直接开源——思路、流程、每一步的门道,全摊开给你看。
我敢说一句不太谦虚的话:就评论分析这件事的颗粒度和准确度,这套东西,目前在亚马逊圈里,我没见过比它更前沿的。
这话说满了吗?看完你再评。
先看东西,再听道理
讲道理之前,我先让你看个实物。
别急着自己直接搓,照着实物搓。
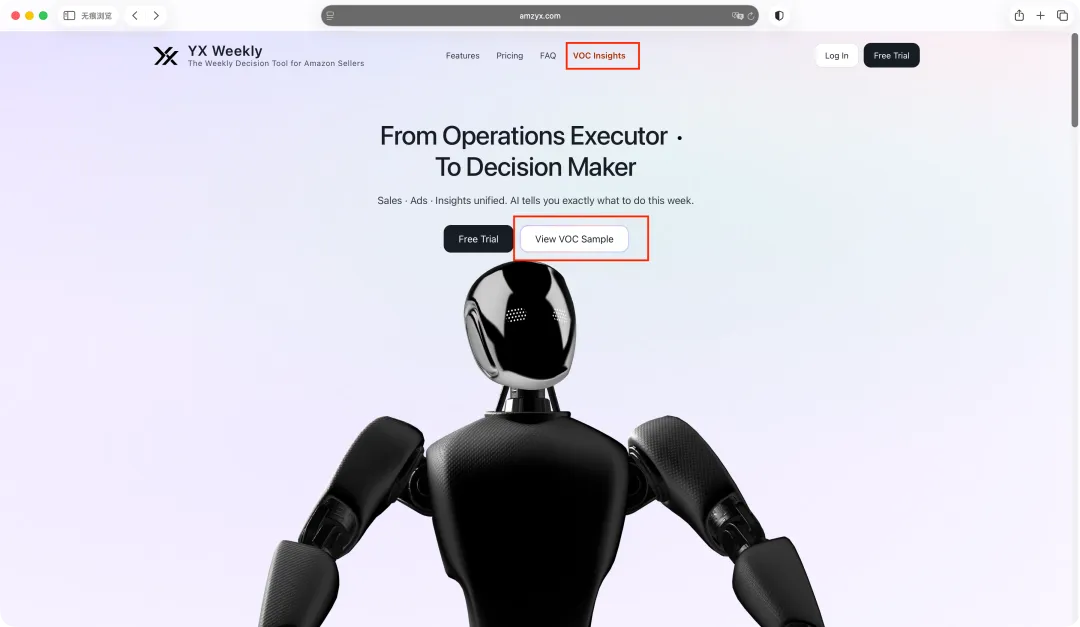
打开 amzyx.com,点进 VOC,这是一份真跑出来的报告——不用注册,直接看。
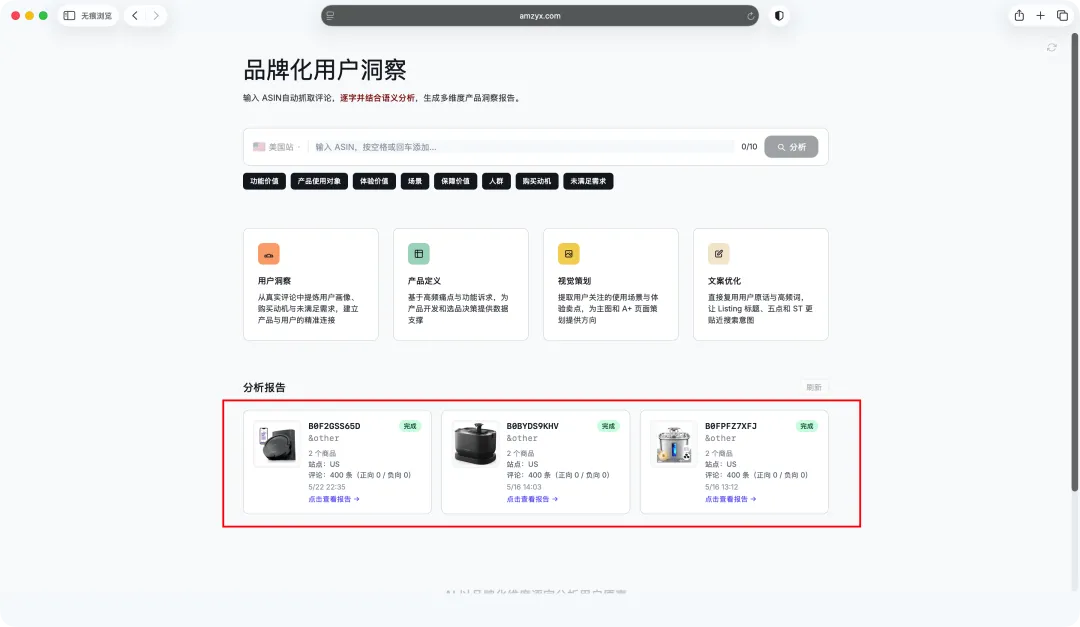
你滑一遍这份报告。
多个 ASIN,400 条真实评论,10 分钟,变成一张能直接拿去开工的产品地图。
逐字拆好的标签、八个维度的分布、一条情绪曲线、一句精准的用户核心任务、再到 P0/P1/P2 的产品改进单——
全在里面。
看完这份报告,你大概会有两种反应。
一种是:"这玩意儿看着不难啊,我也能搓一个。"
另一种是:"等等……它怎么做到不胡说八道的?"
如果你是第二种,恭喜你,你摸到门了。
因为这套工具真正难的地方,根本不在你看到的那张漂亮报告里,而在你看不见的、每一步背后那个不起眼的约束上。
下面,我把这五步,一步一步拆给你。
这套东西,长什么样
整个流程,就五步:
抓原声 → 逐字标注 → 归类统计 → 旅程图 → 收敛落地。
每一步看起来都平平无奇。
但你真上手就会发现,每一步都有一个"差一点就全废"的坑。 这在去年,我也跟大家一样,踩过幻觉的坑。今天讲的,就是这五个坑怎么填。
老规矩,能看懂的往下看;觉得吃力的,那这套你大概率也搓不动,文末有更省事的路子。
第一步:评论得有人读,但不能是"人"读
洞察的原材料,是用户原声。
原声从哪来?我们这行,最大的一座金矿就是——亚马逊评论区。
用户在那儿,毫无防备地告诉你:他在什么场景用、解决了什么、又被什么坑了。
这是免费的、海量的、自带真实场景的用户访谈。
可问题来了。
一个品,几百上千条评论。
你让运营一条条读?
读到第 50 条,人就麻了。读到第 200 条,标签全凭感觉。
累、慢、还不准。 这是第一个卡点,我在上一篇就讲过。
所以第一步,我推荐大家用 Sorftime CLI,输入 ASIN直接把真实评论批量抓下来。(技术党可以手搓插件)
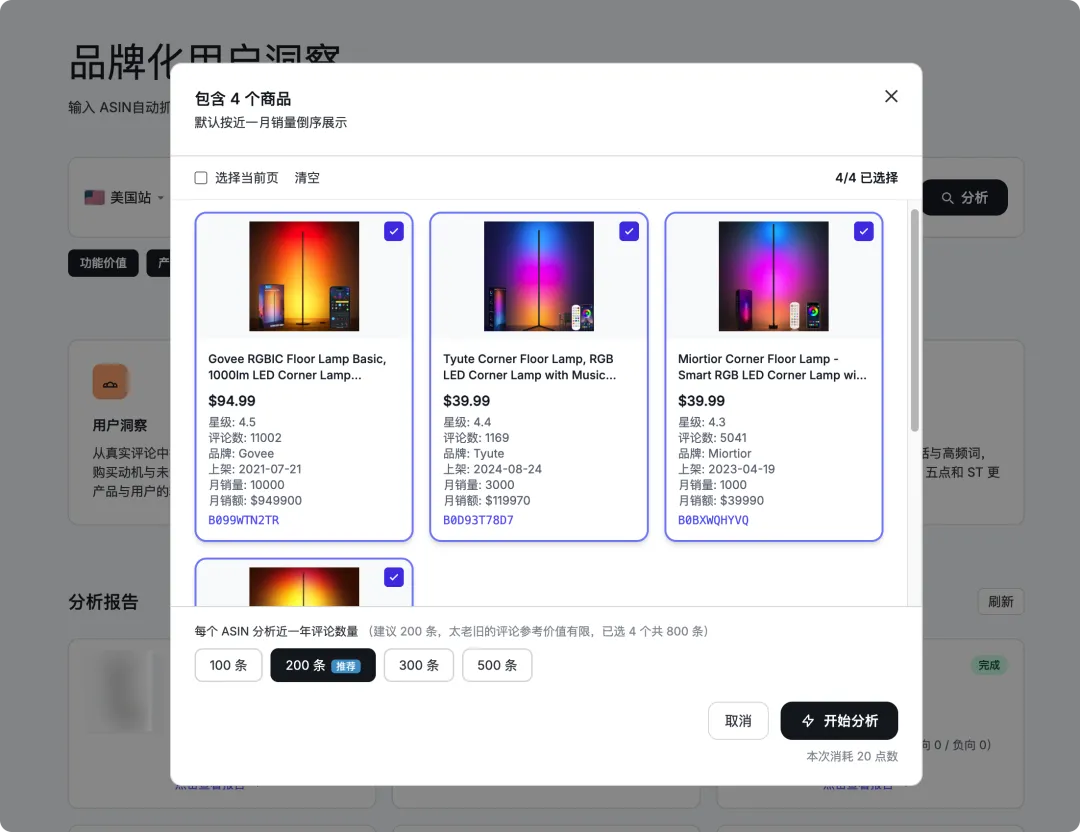
多少条?
我建议从 200 条。虽然它不限量,500 条、上千条,照样跑,但是老评论价值不大。
评论这东西,不是"人"该去读的,是该让机器规模化地读。 把人从"读"里解放出来,人只负责最后看结论、做判断。
这一步不难。难的在下一步。
第二步:标注这一步,我为什么宁可用贵的 Claude
抓下来一堆英文原声,怎么变成结构化的洞察?
最直觉的做法是:一股脑全丢给 AI,让它"帮我分析分析"。
我早期就这么干的。
结果呢?
AI 一上来就给你编。
用户没说的痛点,它给你"洞察"出来了。
用户那句明明是反讽、是阴阳怪气,它照单全收当真夸。
你拿着一份满是幻觉的报告去定义产品,那不叫洞察,那叫占卜。
这就是第二个卡点:丢给 AI,幻觉一堆。
我后来想明白了,毛病不在 AI 笨,在你喂它的姿势不对。
我现在这套标注,做了三件事,专治幻觉:
一是分批喂,不一锅烩。 一次塞几百条进去,AI 的注意力会稀释,越往后越敷衍、越爱编。拆成小批,一批一批过,每条都过得扎实。
二是死命约束它"只标注明确提及的"。 用户没说的,一个字都不许添。这一条,把一大半幻觉摁死在门口。
三是给每个维度设数量上限。 不设上限,AI 就会硬凑、硬套模板,标签越长越像废话。卡住上限,它只能挑最实的标。
就这三下,幻觉率断崖式往下掉。
(这三段话是工具价值核心,我反复编辑了好几次,尽可能让大家理解,如果理解吃力,欢迎大家评论区提问,因为大家的问题角度或许是我没想到的。)
讲到这儿,得说个得罪人的实话。
我这套标注,跑的是 Claude,不是其他模型。
为什么?
因为在去年我尝试过各种模型,最开始就陷入了最懂中文的千问的陷阱,实则也有幻觉。
后面直接尝试Claude。好家伙!那种省心感,一下充满胸腔。
但是Claude 的自动化成本,是某些模型的好多好多好多倍·········
但用户洞察这种活儿,本质是"受约束的业务归因"——不是简单理解文字,是要在一堆约束下,精准判断这句话该归到哪、不该编什么,最重要的是我在之前那篇文章提到的“语境”:
标题是"Not quiet —— it's silent!"
你品品这句。字面像在骂"不安静",其实用户是在反着夸——"哪是不安静,根本就是静音好吗!"
所以模型差一档,归因就开始飘。 越是这种带镣铐跳舞的活儿,便宜模型越容易翻车。
我核算过,一篇报告的token 成本大概在 20-50 的样子,这比我们让运营助理花几天时间挨个标注的成本低多了。
所以我认。这一档,省不得。
各位铁子,你品品——光是"用 Claude 还是用其他模型"这一个选择,就已经是一道门槛了。 后面还有四步呢。
凭什么偏偏是这八个维度?
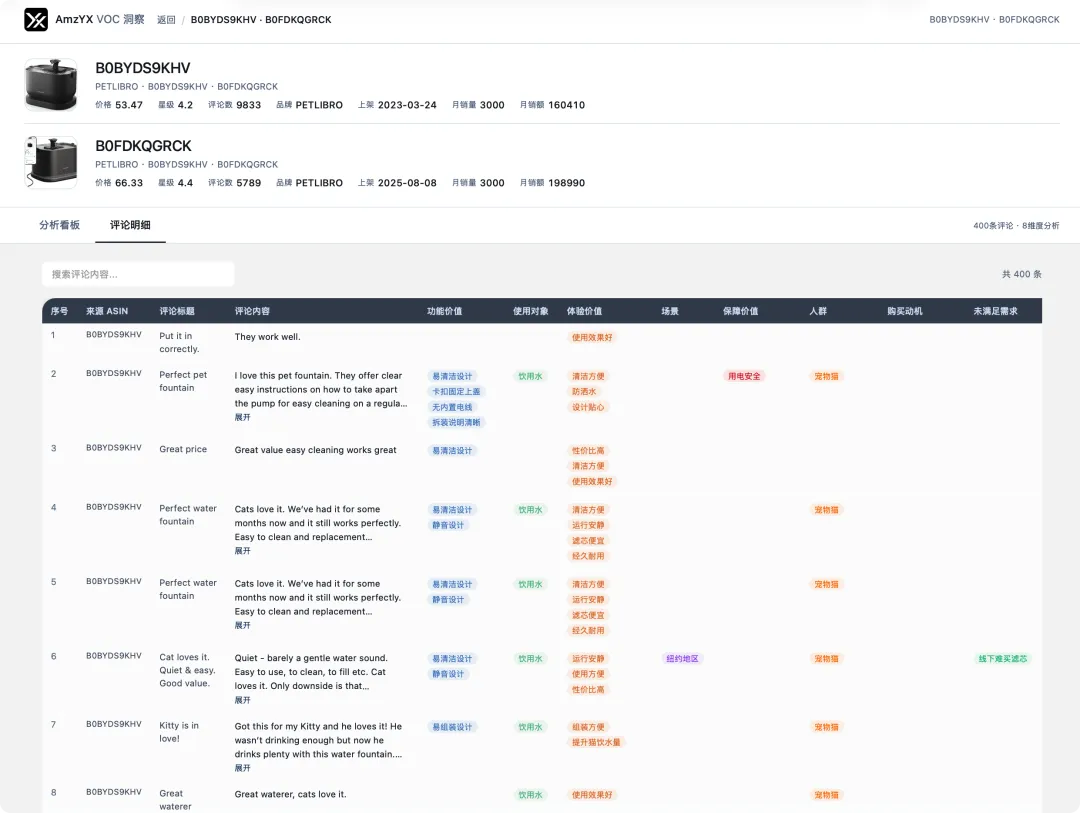
标注按八个维度走:
功能价值、体验价值、保障价值、场景、人群、产品使用对象、购买动机、未满足需求。
可能有较真的铁子要问:凭什么是这八个?拍脑袋分的吗?
好问题。这恰恰是这套工具最"装"得起来的地方。
这八个篮子,背后缝的是三套经典理论。
• 功能价值、体验价值、保障价值——这是"消费者感知价值"理论的底子(Sheth 那帮人 1991 年的消费价值论,Zeithaml 也早讲过感知价值)。用户掏钱,从来不只买功能,还买体验,还买一份"别让我翻车"的安全感。 • 场景——对应"情境价值",就是奶昔故事里那句"在什么场景下雇它",克里斯坦森翻来覆去强调的 circumstance。 • 人群、产品使用对象——营销里最老牌的 STP 市场细分:谁在用、买给谁用。 • 购买动机、未满足需求——这俩,正是 JTBD 的两张脸:他为什么雇这个产品,以及,哪份"活儿"至今还没人替他干利索。
看明白了吗?
把消费价值论 × JTBD × 市场细分缝成一张网——这才是这八个维度真正的来路。
单拎一套理论的人满大街都是。
能把它们缝进一个看板、还落得了地的,没几个。
第三步:先别急着下结论
标完了,是不是就能出报告了?
不行。这里藏着第三个坑,最隐蔽。
很多工具的做法是:一边读评论,一边顺手就把结论给下了。
听着没毛病?
毛病大了。
这等于让 AI"边读边拍板",标签先行,业务语义后置。 出来的结论看着有证据,可证据和结论之间,根本没做过校验。
我的做法是把它掰成两段:
第一段,只做"受约束的归因"——把每句话老老实实归到对应的维度标签上,不许下任何结论。
第二段,等所有标签都落库了,再去聚合、计数、排序,看每个维度里谁被提得最多。
先让证据归位,再让结论浮现。 顺序反了,整份报告的地基就是歪的。
这一步没有花哨的东西。
但"先归因、再统计"这个顺序,是我交了不少token费才悟出来的。
第四步:让 AI 闭嘴,把话筒还给用户
到这儿,标签有了,统计有了。
最关键的一步来了——把这些点,连成一条线。
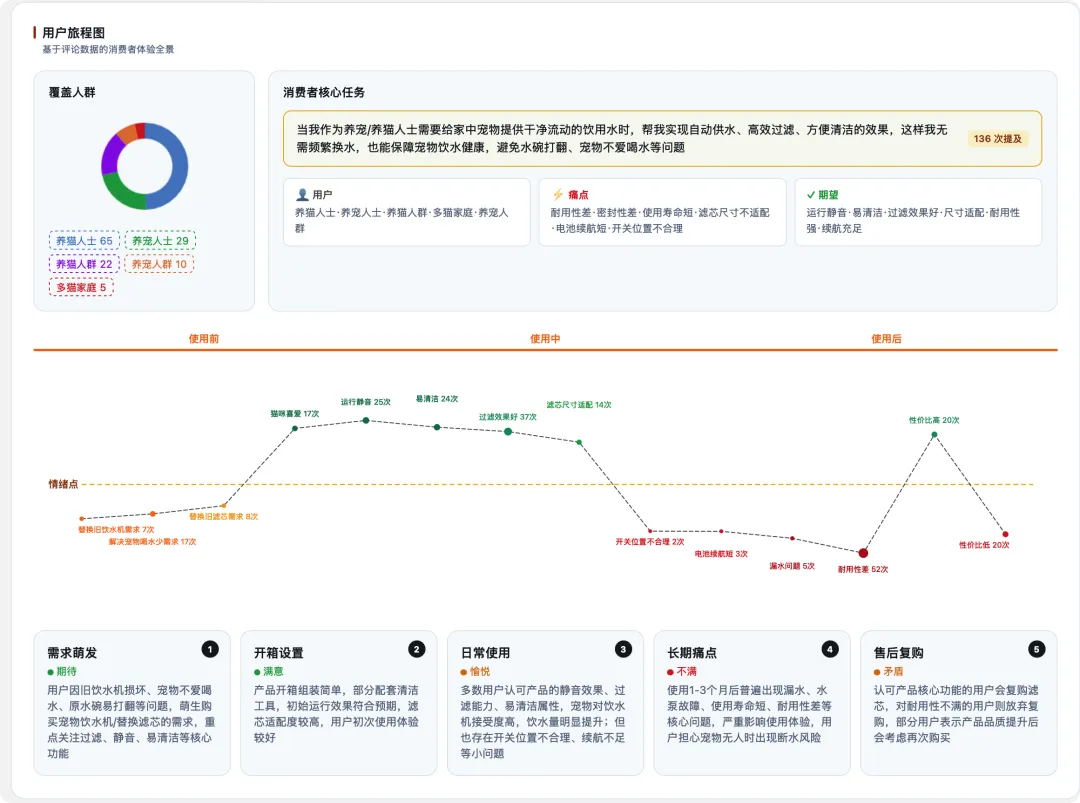
工具会基于前面的统计,加上一批真实原声样本,生成一张用户旅程图:
从使用前、使用中到使用后,拉出一条情绪曲线;高点是爽点,低谷是劝退点。
更狠的是中间那个框——消费者核心任务。
它会用 JTBD 的标准句式,把这个产品的"活儿"提炼成一句话:
"当我作为养宠人士、需要给宠物提供干净流动的饮用水时,帮我实现自动供水、高效过滤、方便清洁,这样我无需频繁换水,也能避免宠物不爱喝水。"
各位铁子,这不就是奶昔故事里那个 JTBD 句式吗?——"当我……我想要……这样我就能……"
前面那篇讲了半天理论,这一句,就是 JTBD 落到一个真实产品上的样子。
可这一步,也是最容易出幻觉的一步。
为什么?因为到了"生成旅程"这步,AI 最容易开始自说自话、自己脑补一段用户故事。
我的卡法是:每一个情绪点,都强制它回填一句真实的用户原话。
它说用户"在长期使用中感到失望"?
可以,把那句失望的原话给我贴出来。
贴不出原文,这个点就不成立。
这一招,等于把话筒从 AI 手里抢回来,还给用户。
旅程不是 AI 编的,是从原声里一句一句挖出来的。
第五步:报告再漂亮,不能落地都是废纸
最后一步,也是最容易被忽略的一步。
我见过太多分析工具,最后吐一份花里胡哨、什么都有的报告。
然后呢?
没有然后。 看着很满,落不了地。
一追求"什么都做",这套系统就会越堆越重,最后重到没法用。
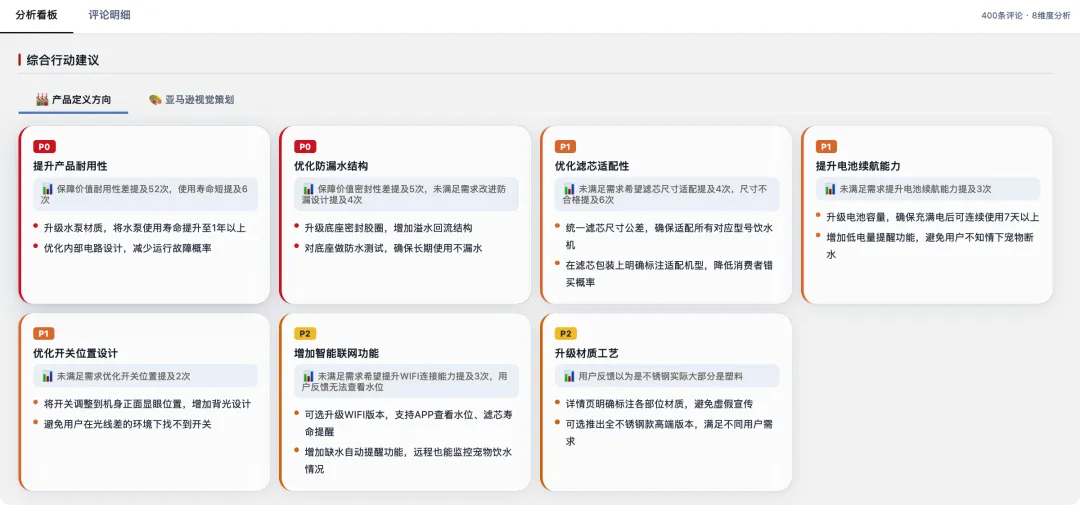
所以我给它定了死规矩:收敛。
只交付两张"开工单":
一张是产品定义方向——按 P0/P1/P2 排好优先级,每条都挂着数据:哪个先改、改的理由、用户喊了多少次,清清楚楚。这是给产品经理的。
一张是亚马逊视觉策划——主图、场景图、对比图、A+、细节图……每一块都告诉你拍什么、为什么拍。这是给设计和运营的。
到这儿,洞察才算闭环。
从一条条原声,一路走到"下一版产品改什么、主图先打哪个点"。

好,五步讲完了。
思路我全摊开了,一点没藏——抓原声、分批标注、约束归因、回填原声、收敛落地。
部署建议
接下来这套东西怎么用,看你是哪种人。
第一种:你自己用。
一个人,手上几个品,自己琢磨产品方向——
照着这篇文章,再对着那份 demo 报告,自己搓一个,够用了。
这条路我是真心欢迎你走。毕竟这行,懂用户的人越多越好。
第二种:你要让公司用起来。
那就是另一回事了。
自己本地跑通一个 demo,和让整个团队天天用——中间隔着一整套工程。
你得有个前端网站,让运营点几下就能出报告;
你得有台服务器在后端常驻,抓评论、调模型、跑分析、推结果,一刻不能停;
你还得做团队鉴权——谁能用、谁看哪个品、点数怎么扣、账号怎么开。
再加上那一档不能省的 API,在后面一直烧着钱。
这小半年,我填的坑、搭的系统、压的成本,全压在这一层。
demo 谁都能搓,系统没那么好搭。
第三种:你不想折腾。
前端、后端、鉴权、模型,我都给你搭好了。
找我,我给你开个账号,打开就用,照着报告做产品就行。
但有句话我先撂在前头:
服务器运力有限,这套现成的,我暂时只放一小批人用。
不是端着,是现在的服务器真跑不起那么大的量。
想要的,趁早。
写在最后
绕回我那句座右铭——
知道用户在选什么,怎么让用户选我们。
用户洞察,就是前半句的全部答案:先听见用户到底在选什么。
这是"怎么让用户选你"的第一块地基。
地基这东西,你可以自己一砖一瓦地砌,也可以直接用我这套现成的。
但不管哪条路,方向是一样的——
赚快钱的时代结束了。往后这几年,拼的就是谁更懂人。