



一、项目简介
1.1 项目背景
在数字经济、绿色发展、科技创新、营商环境、产业升级等研究中,省级政府工作报告是一类非常重要的文本资料。它不仅记录了地方政府每年的重点工作安排,也反映了不同地区在不同时期对某些政策议题的关注程度。
过去,研究者要从政府工作报告中构造文本指标,通常需要手动整理文本、配置 Python 环境、修改关键词词典、设置停用词、运行分词统计,再将结果整理成省级面板数据。这个过程虽然技术门槛不算特别高,但步骤繁琐、重复性强,而且非常容易因为路径、编码、词典设置或文件命名问题导致结果不稳定。
provincial-text-analysis Skill 的价值就在于:它将这一整套省级政府工作报告文本分析流程封装为一个可复用的研究型执行单元,把原本分散在本地脚本中的文本挖掘任务,转化为更标准、更稳定、更适合科研数据生产的自动化流程。
1.2 项目定位
这个 Skill 并不是简单的“词频统计代码”,而是一个围绕省级文本指标生产设计的工作流工具。它面向的是科研场景中的文本变量构造问题,核心目标是把政府工作报告中的政策关注度信息转化为可以进入实证分析的数据表。
可以将它理解为:
一个面向省级政府工作报告的文本指标生产工具,用于将政策文本转化为“省份—年份—主题词频”面板数据。
1.3 项目价值
这个 Skill 的核心价值主要体现在三个方面。
第一,它提升了文本指标生产效率。原来需要手动修改代码、反复调试参数的流程,现在被封装成更加标准化的执行逻辑。
第二,它提高了结果检查的安全性。流程中设置了 Demo 预览机制,避免一开始就直接处理全量文本,从而降低大规模运行后的返工风险。
第三,它增强了科研复现性。关键词、停用词、运行参数和结果输出都被纳入统一流程,使得同一套分析可以在不同主题、不同年份和不同省份样本中重复使用。
二、Skill 设计思路
2.1 从松散脚本到标准工作流
传统文本分析通常依赖一份或多份 Python 脚本。用户需要自己打开代码,手动修改输入路径、关键词词典、停用词、输出文件名和运行模式。每次更换研究主题或文本数据时,都要重复调整。
这个 Skill 的设计思路,是把这些重复操作前移到 Skill 层,让文本分析不再只是“运行一个脚本”,而是变成“执行一套可控流程”。
整体逻辑可以概括为:
文本材料 ↓参数确认 ↓词典与停用词配置 ↓Demo 小样本验证 ↓全量文本处理 ↓省级面板指标输出这套流程强调的不是“跑得越快越好”,而是在保证效率的同时,尽量减少文本分析中常见的隐性错误。
2.2 阶段式流程设计
该 Skill 的流程可以拆成四个核心阶段。
这个设计的重点在于:文本分析结果不是“黑箱式直接产出”,而是在正式全量运行前先经过局部验证。
2.3 人类介入式验证机制
政府工作报告文本通常篇幅较长,涉及年份多、省份多、主题多。如果关键词词典设置不合理,或者停用词过滤不到位,直接运行全量很可能得到一批“看似完整但实际偏差较大”的结果。
因此,该 Skill 采用了 Human-in-the-Loop 的设计:
机器先跑 Demo ↓人类检查预览结果 ↓确认无误后再全量执行这种机制的好处是,研究者可以在正式产出数据之前检查几个关键问题:
这使得文本指标生产从“跑完再看”变成“边跑边验证”。
三、核心代码逻辑展示
3.1 文本读取逻辑
政府工作报告通常以 .txt 文件形式存放。代码首先扫描目标文件夹中的文本文件:
from pathlib import Pathinput_dir = Path("data/gov_reports")txt_files = list(input_dir.glob("*.txt"))这段代码用于获取所有待分析的政府工作报告文本。每个文本文件通常对应一个省份和一个年份。
3.2 Demo 模式控制
Demo 模式用于小样本验证。代码中可以通过参数控制是否只读取少量文件:
TEST_MODE = TrueTEST_FILE_LIMIT = 1if TEST_MODE: txt_files = txt_files[:TEST_FILE_LIMIT]这段代码的含义是:如果当前处于测试模式,就只处理前 1 个文本文件。这样可以快速检查流程是否正常,而不是直接处理全部文本。
3.3 省份和年份解析
为了生成省级面板数据,需要从文件名中识别省份和年份。假设文件命名格式为:
北京_2023.txt上海_2022.txt广东_2021.txt可以通过下面的代码解析:
stem = file_path.stemprovince, year = stem.split("_")year = int(year)解析后,每个文本都会对应到一个明确的省份和年份。后续输出结果也会按照这一结构形成面板数据。
3.4 分词与停用词过滤
中文文本分析通常需要进行分词。代码中可以使用 jieba 完成分词:
import jiebawords = jieba.lcut(text)分词之后,需要过滤停用词:
words = [ w for w in words if w.strip() and w not in stopwords]停用词过滤的作用是去掉“的”“了”“和”“进一步”“持续”等对研究主题贡献较低的词,减少无效高频词对统计结果的干扰。
3.5 关键词词典结构
关键词词典是文本指标构造的核心。一个简单的词典结构可以写成:
KEYWORDS = { "数字经济": [ "数字经济", "数字化", "大数据", "人工智能", "云计算", "区块链", "数据要素" ], "绿色发展": [ "绿色发展", "生态文明", "节能减排", "碳达峰", "碳中和" ]}不同主题对应不同关键词组。每一组关键词都可以生成一个独立的主题词频指标。
3.6 关键词匹配逻辑
词频统计可以通过分词结果进行匹配:
matched_count = 0for word in words: if word in keyword_list: matched_count += 1如果研究对象更多是固定政策短语,也可以直接在原文中统计:
matched_count = sum(text.count(keyword) for keyword in keyword_list)两种方法的区别如下:
在政府工作报告场景中,短语匹配往往更适合政策主题识别。
3.7 词频指标计算
最基础的词频指标为:
frequency = matched_count / total_words其中:
matched_count | |
total_words | |
frequency |
最终每个省份、每个年份、每个主题都会生成一条记录:
row = { "province": province, "year": year, "keyword_group": group_name, "total_words": total_words, "matched_count": matched_count, "frequency": frequency}3.8 结果导出逻辑
全量运行后,结果可以导出为 Excel 和 CSV:
result_df.to_excel("result/provincial_text_index.xlsx", index=False)result_df.to_csv( "result/provincial_text_index.csv", index=False, encoding="utf-8-sig")Excel 适合人工检查和展示,CSV 更适合后续进入 Stata、R 或 Python 做面板回归。
四丶结果展示

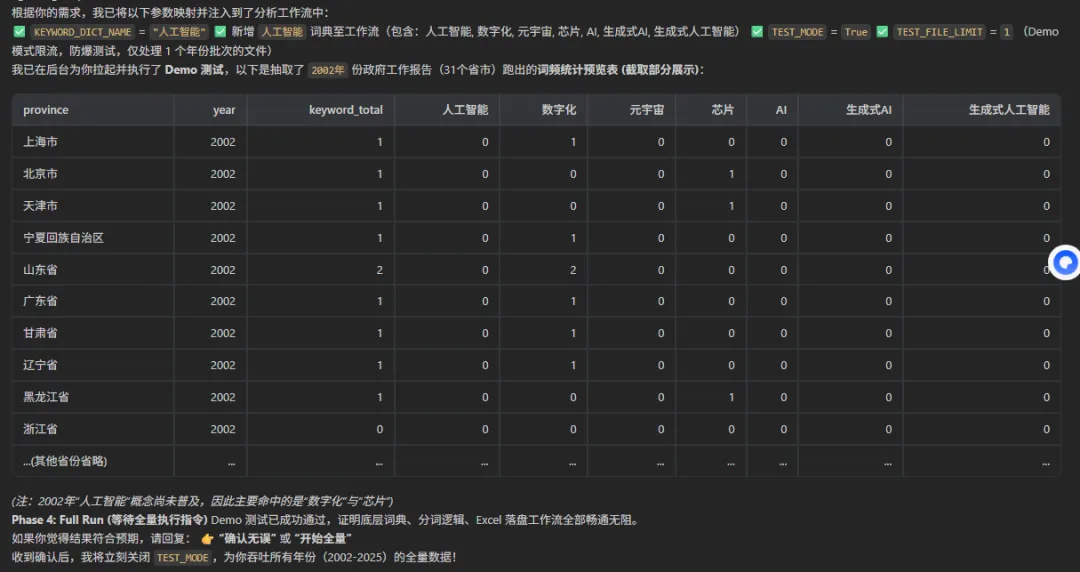
代码链接:
https://ppmandata.net/codeBase/2061727516035444737

C0158

转发本推文到朋友圈
添加客服
发送保留2小时并集齐10个点赞的截图
即可免费领取代码
