


摘要
随着数字经济进入深水区,算力作为核心生产力正在经历深刻的结构性变革。传统以CPU 为核心的通用算力,正在逐步让位于以 GPU、NPU 等异构芯片为核心的智能算力。本报告系统梳理了通用算力与智能算力的核心差异,深入剖析了智能算力的底层工作原理,包括异构计算架构、大规模并行计算机制以及软件生态体系。基于中国信息通信研究院等权威机构的最新数据,报告展示了我国智能算力的爆发式增长态势:2025 年我国智能算力规模预计突破 1037 EFLOPS,在总算力中的占比超过 80%,成为驱动大模型、生成式 AI 以及产业数字化的核心引擎。报告同时梳理了智能算力在大模型训练、科学计算、数字内容创作、产业赋能等领域的典型应用,并探讨了当前产业面临的异构协同、供需错配等挑战,展望了算力互联网、云边端协同等未来发展趋势,为理解 AI 时代的算力变革提供了全面的参考框架。
一、算力体系的二元演进:从通用到智能的分野
1.1 算力的三元分类体系
在当前的数字基础设施体系中,算力根据其架构、用途和性能特征,被业界划分为三大核心类型:通用算力、智能算力与超算算力。这三者共同构成了支撑数字经济运行的算力底座,但在技术路线和应用场景上存在显著的分工。
超算算力:面向尖端科学研究的极致高性能算力,主要用于气象预报、核能仿真、生物医药大分子模拟等对双精度浮点运算要求极高的科研场景,是国家科技竞争力的战略重器。
通用算力:以CPU 为核心的传统计算能力,支撑了过去三十年互联网与信息化的发展,是数字经济的基础底座。
智能算力:以GPU、NPU、ASIC 等异构加速芯片为核心,专门针对人工智能训练与推理任务优化的新型算力,正在成为当前算力增长的绝对主力。
1.2 通用算力:传统信息化的基础底座
通用算力,本质上是由通用服务器提供的、以x86 架构 CPU 为核心的计算能力。它的设计理念是 “全能通用”,擅长处理复杂的逻辑控制、串行任务和不规则的数据结构。
核心特征:
硬件架构:以少量高性能CPU 核心为主,通常单服务器配备 2 路或 4 路 Xeon / 鲲鹏 CPU,核心数量通常在几十核级别。
算力特性:侧重低延迟的串行运算,并行处理能力较弱,单精度浮点运算(FP32)是其主要算力指标。
部署特征:单机功耗低,通常单机在300-800W,适配传统 IDC 的风冷散热,单机柜功率仅 3-8kW。
典型应用场景:通用算力支撑了绝大多数传统互联网与企业信息化业务,包括网站托管、企业ERP 系统、数据库存储、云主机、文件存储等。在这些场景中,任务的逻辑复杂但数据量相对可控,CPU 的通用处理能力能够以最高的效率完成任务。
1.3 智能算力:AI 时代的新质生产力
随着大模型与生成式AI 的爆发,传统的通用算力已经无法满足指数级增长的计算需求,智能算力应运而生。智能算力是指由异构加速芯片提供的、针对大规模并行矩阵运算优化的计算能力,专门用于支撑人工智能模型的训练与推理。
与通用算力的缓慢增长不同,智能算力呈现出爆发式的增长态势。根据中国信息通信研究院与IDC 的最新数据,2023 年到 2025 年,通用算力从 61.3 EFLOPS 增长到 85.8 EFLOPS,年复合增长率仅为 18.8%;而智能算力则从 417.1 EFLOPS 猛增到 1037.3 EFLOPS,年复合增长率高达 46.2%,是通用算力增速的 2.5 倍。
这种增长直接重塑了我国的算力结构:
图:中国算力结构占比变化预测(数据来源:中国信通院)
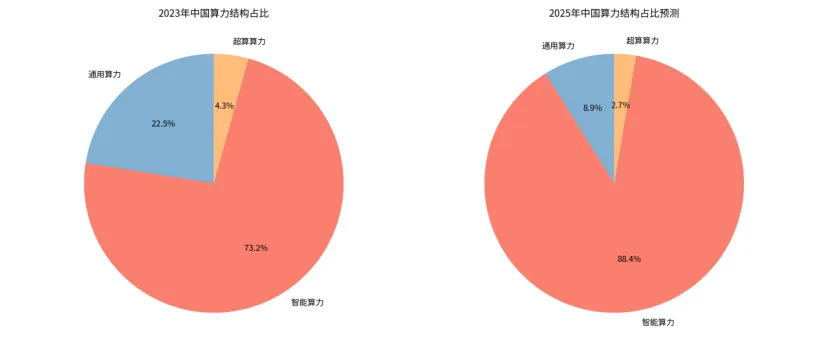
2023 年,智能算力在总算力中的占比为 73.2%,而到 2025 年,这一比例将提升至 88.4%,通用算力的占比则从 22.5% 下降至 8.9%。这标志着我国已经正式进入了以智能算力为主导的算力新时代。
二、智能算力的底层架构与工作原理
智能算力之所以能够爆发式增长,核心在于其底层的异构计算架构与大规模并行处理机制,这从根本上区别于传统的通用计算。
2.1 异构计算:CPU+GPU 的协同范式
智能算力的核心是异构计算,即通过两种不同架构的处理器协同工作,扬长避短,实现计算效率的最大化。
图:CPU 与 GPU 核心架构与并行能力对比
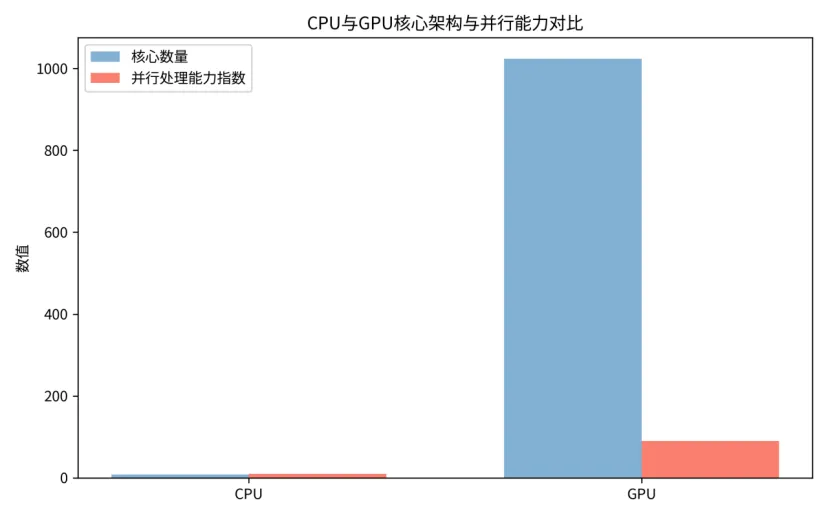
2.1.1 CPU 与 GPU 的架构差异
CPU(中央处理器):作为系统的“总指挥”,CPU 只有少量的高性能大核心(通常 4-32 核),每个核心都拥有复杂的逻辑控制单元和大容量 Cache,擅长处理复杂的分支判断和串行任务。它就像几个经验丰富的老工程师,能够快速处理复杂的工序,但一次只能处理少数几个任务。
GPU(图形处理器):作为计算的“劳工大军”,GPU 拥有成千上万个简单的小核心(例如 NVIDIA H100 单卡就有超过 1.4 万个 CUDA 核心)。这些核心结构简单,专门针对并行的浮点运算优化。它就像几万个流水线工人,虽然每个工人只会做简单的重复计算,但加在一起,就能同时处理海量的简单任务。
2.1.2 异构计算的工作流程
在异构计算架构中,CPU 和 GPU 分工明确:
(1)任务分发:CPU 负责处理整个系统的逻辑控制、任务调度和数据预处理,将复杂的控制流处理完毕。
(2)并行计算:CPU 将大规模的矩阵运算任务(例如深度学习中的张量计算)发送给 GPU。
(3)批量处理:GPU 的上千个核心同时开工,对这批数据进行同步的并行计算,完成海量的乘法和加法操作。
(4)结果汇总:计算完成后,GPU 将结果返回给 CPU,由 CPU 进行后续的逻辑处理。
这种分工完美适配了深度学习的需求:大模型的训练和推理,本质上就是海量的矩阵乘法运算,这些运算规则简单、数据量大,正好是GPU 的强项。而 CPU 则负责处理剩下的复杂逻辑,两者协同,将计算效率提升了上百倍。
2.2 大规模并行计算:大模型训练的核心机制
对于千亿参数的大模型而言,单张GPU 的能力依然不够。因此,智能算力必须通过大规模并行计算,将成千上万张GPU 组织起来,协同完成同一个任务。
正如我们之前探讨的,大模型训练面临两大瓶颈:一是模型参数太大,单卡显存装不下;二是训练数据(万亿级Token)太多,单卡算不完。并行计算就是为了解决这两个问题而生的。
2.2.1 数据并行:解决海量 Token 的计算效率
数据并行是最基础的并行策略,它的核心思路是:模型不动,数据拆分。
(1)每一张GPU 都完整复制了一份整个模型的参数。
(2)将一批训练数据(Batch)切成 N 份,N 张 GPU 各自拿一份数据,独立进行前向计算和反向传播,算出自己那份数据的梯度。
(3)最后,所有GPU 把各自的梯度汇总起来,统一更新模型的参数。
这种方式非常适合处理海量的Token 数据,能够线性地提升训练的吞吐量,让万亿 Token 的数据集能够在数月甚至数周内训练完成,而不是花上几年。
2.2.2 模型并行:解决超大参数的存储瓶颈
当模型大到单卡显存根本装不下的时候,就需要模型并行,核心思路是:数据不动,模型拆分。
张量并行(横向切分):把单个神经网络层拆开到多张GPU。例如,一个注意力层的权重矩阵,切成左右两半,分别放在两张 GPU 上,计算的时候各自算一半,最后合并结果。这样就解决了单层计算量过大、显存不够的问题。
流水线并行(纵向切分):把整个模型按层切成几段。GPU1 负责前几层,GPU2 负责中间层,GPU3 负责后几层。数据像流水线一样,依次流过这些 GPU,完成整个模型的计算。
2.2.3 3D 并行:混合并行的工业实践
在真实的千亿大模型训练中,业界通常会将数据并行、张量并行、流水线并行结合起来,形成3D 并行(混合并行)。例如,训练一个GPT-3 175B 参数的模型,通常会使用几百张 A100 GPU:
(1)跨服务器之间做数据并行,处理不同的数据分片。
(2)服务器内部的8 张卡之间,做张量并行和流水线并行,拆分模型的层和参数。
通过这种方式,上万张GPU 可以协同工作,将一个原本需要几百年才能跑完的训练任务,压缩到几个月完成。
2.2.4 Token 与算力的关联
在这个过程中,Token 作为大模型处理的最小单元,与智能算力的吞吐能力直接挂钩。
(1)每处理1 个输入 Token,都需要所有的模型参数做一次矩阵运算。
(2)每生成1 个输出 Token,GPU 都要做一轮完整的前向计算。
(3)因此,智算集群的性能,通常用Tokens/sec(每秒生成的Token 数量)来衡量。一个万卡集群,每秒可以处理数万个 Token,这正是智能算力的核心价值所在。
2.3 CUDA 生态:异构计算的软件底座
仅有硬件的异构是不够的,要让开发者能够方便地使用GPU 的并行能力,还需要软件生态的支持,这就是 NVIDIA CUDA(Compute Unified Device Architecture)的价值。
CUDA 是一套并行编程框架,它屏蔽了 GPU 硬件的复杂性,让开发者可以用类似 C 语言的语法,直接编写并行计算程序。
(1)它提供了cuDNN、cuBLAS 等加速库,将深度学习的常用算子都做了硬件级的优化。
(2)它统一了异构计算的编程模型,让CPU 和 GPU 的协同变得简单。
(3)正是因为CUDA 生态的成熟,才使得 GPU 成为了智能算力的绝对主力,支撑了过去十年深度学习的爆发。
三、智能算力的产业生态与发展现状
智能算力的爆发,带动了整个产业链的重构,从上游的芯片,到中游的智算中心,再到下游的算力服务,形成了一个全新的产业生态。
3.1 上游:AI 芯片的多元化爆发
智能算力的核心载体是AI 芯片,随着需求的爆发,AI 芯片市场呈现出百花齐放的态势。
GPU:依然是市场的绝对主力,占据了70% 以上的市场份额。NVIDIA 的 A800、H100、B200 等产品,凭借强大的算力和成熟的 CUDA 生态,主导了高端市场。AMD 的 MI300 系列也在快速追赶。
国产AI 芯片:国内厂商正在快速突破,形成了“一超多强” 的格局。华为昇腾、百度昆仑芯、壁仞科技、沐曦、海光 DCU 等国产芯片,正在逐步填补市场空白,并且已经能够支撑千卡甚至万卡级的集群训练。
ASIC/NPU:寒武纪、地平线等专用AI 芯片,针对特定场景做了硬件定制,在能效比上具备优势,正在推理和边缘场景快速落地。
3.2 中游:智算中心的规模化建设
承载智能算力的基础设施,是智算中心,它与传统的IDC 有着本质的区别:
对比维度 | 传统IDC | 智算中心(AIDC) |
核心芯片 | CPU 为主 | GPU/NPU 为主,CPU 为辅 |
单机柜功率 | 3~8kW | 20~100kW+ |
散热方式 | 风冷为主 | 液冷为主 |
网络 | 普通以太网 | RDMA/IB 高速互联 |
PUE | 1.3~1.6 | 1.1~1.3 |
截至2025 年,我国智算中心的建设已经进入快车道,各地纷纷部署万卡级的智算集群,为大模型训练提供底座。这些智算中心不仅提供硬件,还通过资源池化技术,将异构的算力资源整合起来,形成统一的资源池。
3.3 下游:智能算力服务的普惠化
随着算力资源的丰富,下游的算力服务也在快速发展,从过去的“卖机柜” 转向 “卖服务”。
算力租赁:企业无需自建昂贵的GPU 集群,只需按需租赁算力,按 GPU 小时或者 Token 数量付费,极大降低了 AI 创业的门槛。
训推一体服务:云厂商提供从模型训练到推理部署的全流程服务,企业只需关注业务逻辑,无需关心底层的硬件和并行策略。
算力互联网:通过统一的调度平台,将全国分散的算力资源整合起来,实现算力的跨域流动,让算力像水电一样,随用随取。
四、智能算力的典型应用场景与实践
智能算力已经不再是实验室里的技术,它正在千行百业落地,释放出巨大的生产力。
4.1 大模型与生成式 AI:最核心的需求场景
这是智能算力最直接的应用。
大模型训练:OpenAI 训练 GPT-4,动用了数万张 GPU 的超大规模集群;国内的文心一言、通义千问等大模型,也都依托万卡级的智算集群,将训练周期从数年压缩到数月。
高并发推理:ChatGPT 上线后,亿级用户的并发访问,每秒需要生成数百万个 Token,这背后正是智能算力的弹性扩容支撑。随着推理需求的爆发,预计到 2026 年,推理算力将占据智能算力的 70% 以上。
4.2 AI for Science:科研的新引擎
智能算力正在重塑科学研究的范式。
生物医药:DeepMind 的 AlphaFold2,利用智能算力预测了超过 2 亿个蛋白质的结构,将原本需要数年的实验工作压缩到数天,极大加速了新药研发的进程。
气象预报:国家气象局利用智算算力,将气象数值预报的精度提升到了公里级,能够更准确地预测极端天气。
工业仿真:在汽车、航空航天领域,利用智能算力进行流体力学、电磁仿真,能够将仿真速度提升上百倍,缩短产品的研发周期。
4.3 数字内容创作:释放创意生产力
智能算力正在赋能数字内容产业。
影视特效渲染:电影《哪吒之魔童闹海》的1900 多个特效镜头,正是依托智算中心的算力,完成了海量的光线追踪渲染,将原本需要数月的渲染周期压缩到了数周。
AIGC 创作:文生图、文生视频等应用,每生成一张高清图片或者一秒钟的视频,都需要海量的并行计算。正是智能算力的普及,才让普通用户也能免费使用这些创意工具。
工业设计:浙江台州的模塑企业,利用智算中心的算力训练了日化设计大模型,原本设计师3 天才能出一套方案,现在 AI 几分钟就能出多套方案,效率提升了上百倍。
4.4 产业数字化:赋能千行百业
在传统产业,智能算力也在加速落地。
自动驾驶:小鹏汽车依托阿里云的智算算力,将自动驾驶模型的训练速度提升了170 倍,研发周期缩短了 20%,支撑了端到端的自动驾驶大模型的迭代。
海洋工程:厦门的企业发布了全国首个船舶与海洋工程大模型“文鳐”,依托智算中心的算力,实现了船舶设计、运营的全流程智能化。
智能制造:在新能源电池工厂,边缘智算节点实时处理极片的图像,实现了99.9% 的缺陷检出率,毫秒级的响应速度,支撑了产线的高速运转。
五、挑战与未来趋势
尽管智能算力发展迅猛,但产业依然面临着诸多挑战。
5.1 当前面临的核心挑战
(1)异构协同难题:当前AI 芯片种类繁多,架构各异,软件生态割裂。不同厂商的芯片之间难以协同训练,导致算力资源碎片化,无法形成合力。
(2)算力供需错配:东部地区需求旺盛但资源紧张,西部地区资源丰富但需求不足。同时,训练需求的集中化和推理需求的碎片化,导致算力资源的利用率有待提升。
(3)能耗与成本挑战:智算中心的功耗极高,一个万卡集群的年耗电量超过1 亿度。如何提升能效,实现绿色算力,是产业面临的长期挑战。
5.2 未来发展趋势
(1)算力互联网的构建:通过统一的标识、调度和互联技术,打破地域和厂商的壁垒,将全国的异构算力整合起来,形成一张统一的算力网络,实现算力的全域流动和按需调度。
(2)云边端协同的算力架构:未来的算力将不再集中在中心节点,而是形成“中心大模型训练 + 边缘推理 + 端侧小模型” 的协同架构。中心负责通用能力的训练,边缘负责低时延的实时处理,端侧负责隐私保护,三者协同,最大化算力效率。
(3)绿色智算与技术创新:液冷散热、绿电耦合、存算一体、光计算等新技术将不断突破,推动智算中心的PUE 持续降低,实现算力的可持续发展。
(4)普惠化的算力服务:算力服务将从“卖资源”转向“卖结果”,用户无需关心底层的 GPU 和集群,只需提交任务,就能按效果付费,让智能算力真正成为像水电一样的社会基础设施。
六、结论
从通用算力到智能算力的演进,是数字经济发展的必然趋势。智能算力凭借其异构计算架构和大规模并行处理能力,完美适配了大模型时代的算力需求,正在成为驱动经济增长的新质生产力。
随着技术的不断成熟和产业生态的完善,智能算力将进一步渗透到千行百业,不仅支撑了生成式AI 的爆发,更在科研、制造、医疗等领域释放出巨大的价值。未来,随着算力互联网的构建,智能算力将真正实现普惠化,成为支撑整个数字经济的核心底座,推动人类社会进入智能时代的新阶段。