


2026
4/22
TextIn.com
TextIn
—— 专注智能文字识别19年 ——
项目介绍: 这是一个开箱即用的财务报表抽取工具,支持上传PDF/Excel格式的年报、审计报告,自动提取资产负债表、利润表、现金流量表三大表结构化数据,输出JSON或Excel。它能够处理跨页表格、合并单元格等复杂排版,并支持结果溯源至原文页码。适用于投融资分析、财务校验及企业知识库建设。
GitHub项目地址: https://github.com/intsig-textin/xparse-sample-projects
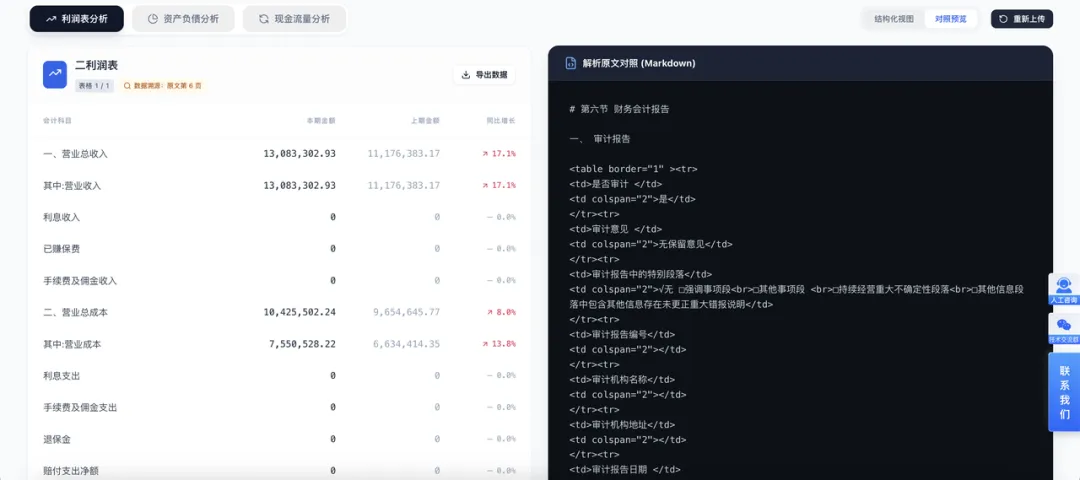
下面我们讨论实现方法。如果目标是从一份很长的财务报告里快速、稳定地提取三大表,第一件事不是写Prompt,而是先判断这个问题到底属于语义理解,还是属于结构定位。财务三大表更接近后者:核心问题往往是“哪一块是表题、哪一块是表格、哪几列是金额列”,而不是“模型能不能理解财报”。
一、先把目标定义清楚
如果目标只是读懂财报,一次性全文问答当然也可以;但如果目标是做成结构化工具,要求通常会变成下面这样:
从长 PDF 财报里快速定位资产负债表、利润表、现金流量表 稳定提取“科目 + 金额列” 把结果直接交给前端继续做同比、导出和后续分析
在这种目标下,重点不再是生成自然语言答案,而是尽快、稳定地把三张表还原出来。
二、架构应该怎么拆
更适合这类问题的链路通常是:
PDF 财务报告 ↓TextIn 文档解析 ↓markdown + detail ↓定位 table_title ↓查找后续表格块 ↓标准化列结构 ↓输出三大表 JSON这条链路里的职责边界很明确:
解析层负责把长财报转成结构化文档树 规则层负责定位表题、关联表格块、识别金额列 交付层负责把结果给前端做展示和导出
这里的关键判断是:如果结构信息已经足够好,就不要强行把核心抽取写成LLM任务。
三、先把解析层输入输出定义对
真正调用的还是 TextIn 的二进制流接口:
POST https://api.textin.com/ai/service/v1/pdf_to_markdown代码里的请求方式如下:
headers = {"x-ti-app-id": TEXTIN_APP_ID,"x-ti-secret-code": TEXTIN_SECRET_CODE,"Content-Type": "application/octet-stream",}params = {"parse_mode": "auto","page_count": 200,"dpi": 144,"table_flavor": "html","apply_document_tree": 1,"markdown_details": 1,"page_details": 1,"apply_merge": 1,}resp = await client.post("https://api.textin.com/ai/service/v1/pdf_to_markdown", headers=headers, params=params, content=file_bytes,)这里同样要强调:
Body 是原始 PDF 二进制内容,不是 multipart/form-data这一层除了 markdown,还依赖detail里的结构化块信息
可以把上游输出理解成:
{"code": 200,"result": {"markdown": "...","detail": [ {"sub_type": "table_title", "text": "资产负债表", "page_id": 12}, {"type": "table", "rows": [["项目", "本期", "上期"], ["货币资金", "100", "80"]]} ] }}如果做前后端分离,通常会在本地后端包一层 /api/parse-document 给浏览器上传使用;但上游解析协议本身仍然是“二进制流 + 结构化返回”。
四、为什么这里不把核心抽取写成 Prompt
很多人一上来会想:既然前面很多文档抽取都可以用 Prompt,财报是不是也可以直接让模型输出三大表?
当然可以试,但这里不是最优解。原因很简单:
三大表提取首先是定位问题,不是开放语义问题 长财报对时效和稳定性要求很高 如果解析层已经给出了表题和表格块,规则通常比全文 Prompt 更直接、更快、更稳
所以这里更合理的思路是:让解析层提供结构,让规则层消费结构。
五、真正的输入契约是什么
虽然这里没有抽取 Prompt,但它一样有严格的输入契约。
1. 输入不是全文语义,而是 detail
这套实现真正依赖的是 detail 里的结构化块。规则层首先看的是块类型和顺序,而不是整份财报文本的自然语言含义。
最关键的锚点就是:
if item.get("sub_type") != "table_title":continue这说明规则层并不是在“读懂一段话”,而是在找“结构上已经被标注成表题的块”。
2. 表题定位之后,再找后续表格块
找到 table_title之后,代码会继续向后扫描,寻找与之相邻的表格块:
for j in range(i + 1, n): nxt = detail_list[j]if isinstance(nxt, dict) and is_table_block(nxt): table_block = nxtbreak这一步的含义很清楚:先定位标题,再关联表格,而不是让模型在全文里自己猜哪一段属于哪张表。
3. 表格块还要做输入适配
不同文档里的表格块并不一定长成同一种结构,所以代码专门兼容了三种来源:
rowscellshtml
对应逻辑是:
defextract_table_matrix_from_block(item: dict) -> list:if isinstance(item.get("rows"), list) and item.get("rows"):return item["rows"]if isinstance(item.get("cells"), list) and item.get("cells"):return cells_to_matrix(item["cells"]) html = item.get("table_html") or item.get("html") or item.get("table")这一步其实就是这类工具的“输入适配层”。如果没有这一层,后续列识别和表结构统一都会很脆弱。
六、输出结构应该怎么定
规则层最终要输出的,不是原始表格块,而是前端可直接消费的三大表结果。
本地后端最终返回的是:
{"status": "success","markdown": "...","tables": {"balanceSheet": [],"incomeStatement": [],"cashFlow": [] }}每张表里再是一组已经过标准化的行,例如:
[ {"title": "资产负债表","page_id": [12],"rows": [ ["货币资金", "1000000", "800000"], ["应收账款", "500000", "420000"] ] }]这样设计的重点是:
后端先把结构问题解决掉 前端不需要再理解原始 detail后续做同比、导出、可视化时,直接消费标准化后的 tables
七、为什么这里的规则比全文 Prompt 更合适
如果硬要把这件事写成全文 Prompt,通常会遇到几个问题:
长文档 token 成本高 同一张表多次抽取结果可能波动 模型对表格边界、列边界、续表边界的处理不一定稳定
而这里的核心其实是:
TextIn智能文档解析本身就会对文档做结构化 表题识别 表格块关联 列结构标准化 数值列筛选
这四件事都更接近结构化规则问题,不是开放式生成问题。
试用财报抽取工具?https://www.textin.com/tasks/financial-report-extraction。 以上是基于规则与结构化解析实现财报三大表提取的一次实践。方案已上传GitHub,欢迎大家在项目中与我们交流。如果你在实际处理财报表格时遇到其他复杂情况(如多级表头、不规则合并单元格、跨页续表等),也可以留言或私信交流探讨。
