


SNIA 在 2026 年2月发布了一篇白皮书《Introduction to Flexible Data Placement》,系统介绍了 NVMe 的一项新能力:FDP(Flexible Data Placement,灵活数据放置)。
近两年从行业趋势看,hyperscale / cloud eSSD 基本都会支持 FDP。
那FDP到底是什么,解决了什么问题?本文将严格沿着白皮书的行文逻辑,把 FDP 的背景、机制和实际作用讲清楚。
文末编者也将从 Controller / Firmware 视角讨论 FDP 的真实成本。

资料来源:文中配图均来自 SNIA 白皮书《Introduction to Flexible Data Placement》(2026)
一、问题从哪里来:为什么 NVMe SSD 避不开写放大(WAF)
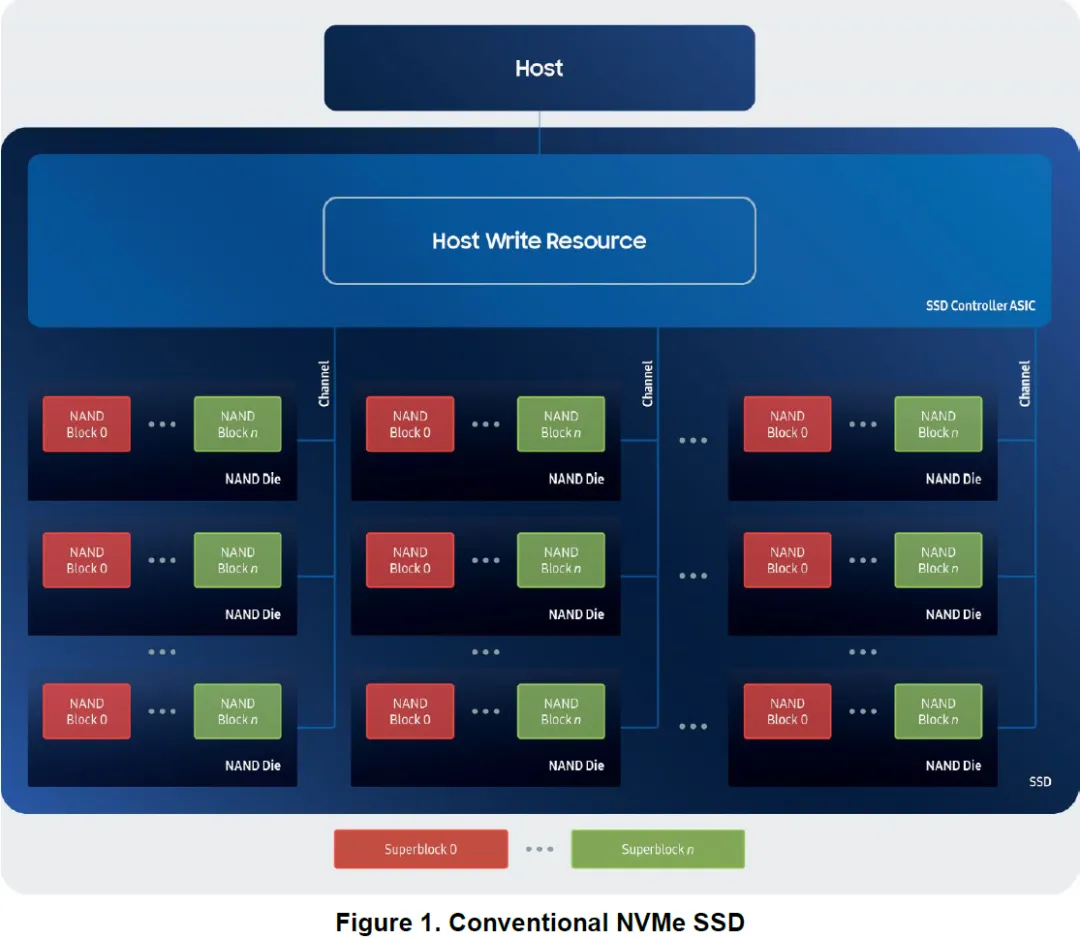
在 NVMe SSD 中,Host 写的是逻辑块(LBA),而 SSD 实际写入的是 NAND 的 page / erase block。
NAND 的一个基本约束是:已经写过的物理块,在再次写入前必须整体擦除。
SSD 控制器内部因此维护了:
LBA → PBA 的映射表
垃圾回收(GC)机制
超级块(superblock):由多个 die / plane 上的 erase block 组合而成
问题在于:
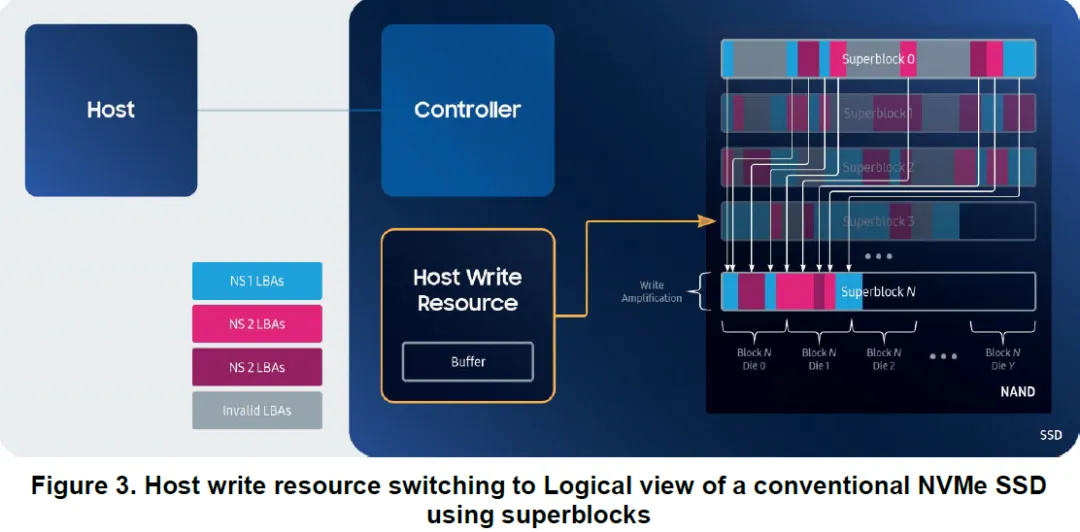
Host 并不知道哪些 LBA 会被写入同一个 superblock。
于是,典型情况是:
不同 namespace、不同应用、生命周期完全不同的数据,被混写在同一个 superblock 中
当其中一部分数据失效,SSD 为了回收空间,必须搬移仍然有效的数据
这些额外的数据搬移,就构成了写放大(WAF)
白皮书给出的定义是:
WAF = SSD 实际写入 NAND 的逻辑块数 / Host 提交写入的逻辑块数
理想情况下 WAF = 1,但在随机写、混合写、缓存型工作负载中,WAF 往往显著大于 1。
二、传统 NVMe SSD 的工作方式:Host 没有参与空间
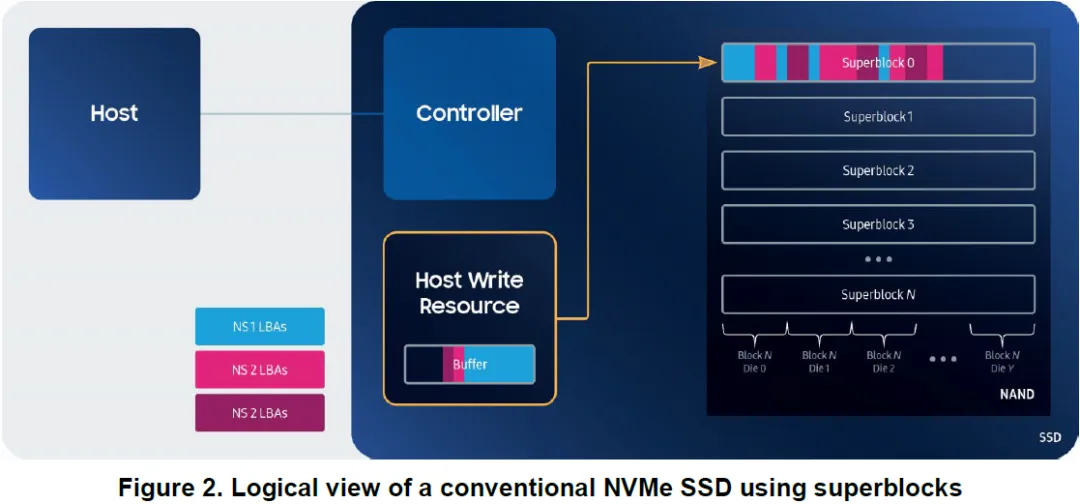
白皮书用一组示意图,先回顾了传统 NVMe SSD 的写入模型。
SSD 将来自不同 namespace、不同 LBA 的写请求缓存在内部
累积到一定规模后,统一写入一个 superblock
superblock 写满后,切换到下一个
垃圾回收时,以 superblock 为单位进行 erase 和 copy
Host 只能看到 LBA,而 superblock 的边界、状态和生命周期完全在 SSD 内部。
三、FDP 的核心想法:把将来会一起回收的数据显式化
SNIA 并没有试图让 Host 控制物理地址,而是引入了一个新的中间抽象:
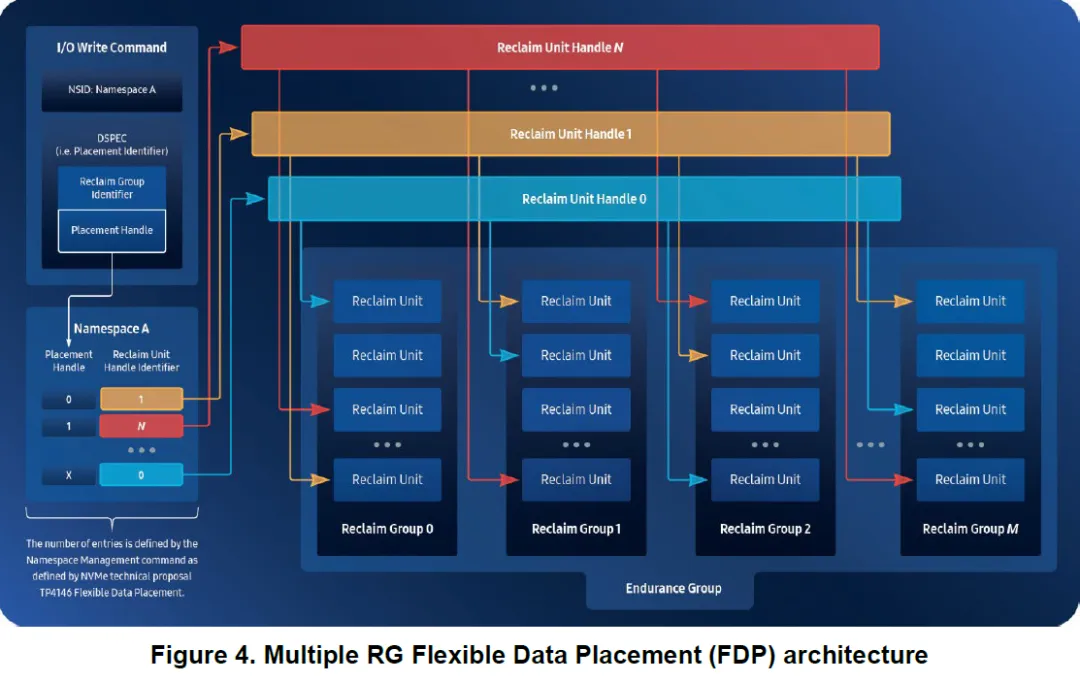
Reclaim Unit(RU)
RU 是一组 NAND block
在推荐实现中:一个 RU = 一个 superblock
RU 是 将来会被一起擦除和回收的单位
FDP 的目标不是减少 GC 次数,而是:
让 Host 有能力,尽量保证一个 RU 里的数据会在相近时间一起失效。
四、FDP 的几个关键组件(白皮书定义)
1. Reclaim Unit(RU)
表示一组会一起回收的 NAND block
2. Reclaim Unit Handle(RUH)
表示一条 Host 写入管线
RUH 决定当前写请求会写入哪一个 RU
一个 namespace 可以访问多个 RUH
3. Reclaim Group(RG)
RU 和 RUH 的管理边界
白皮书明确推荐:单 RG 覆盖整个 SSD
4. Data Placement Directive
Host 在 NVMe 写命令中,显式指定使用哪个 RUH(以及 RG)
如果 Host 不指定 placement directive:SSD 会自动回退到默认 RUH;仍保持向后兼容
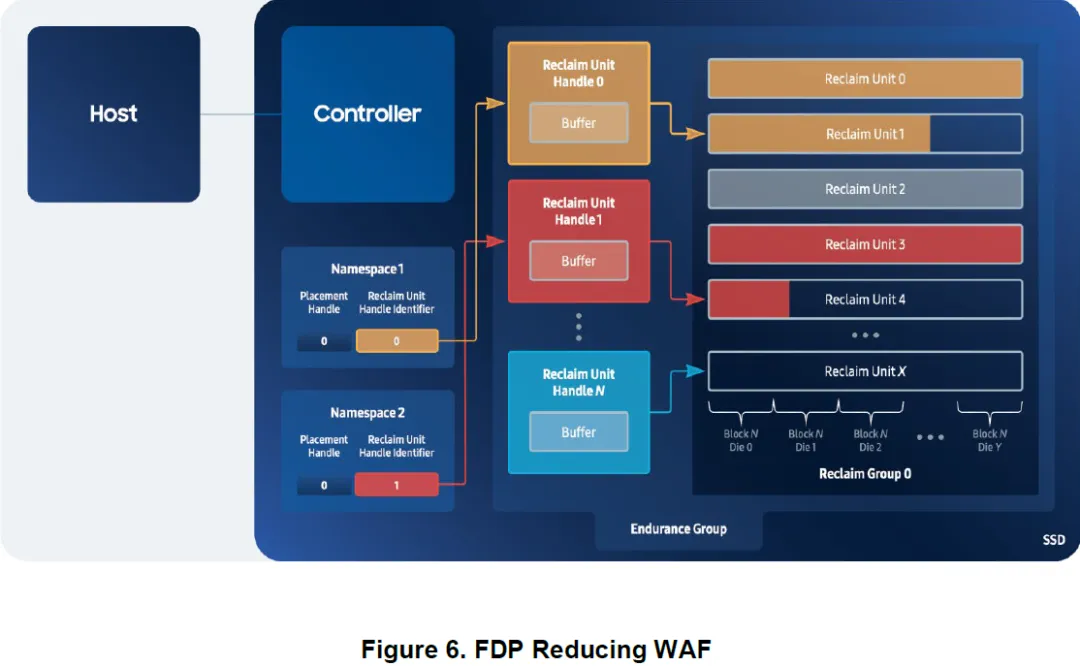
五、FDP 如何降低 WAF
白皮书用一个典型例子来说明 FDP 的效果:
Namespace 1 的数据始终写入 RUH 0
Namespace 2 的数据始终写入 RUH 1
每个 RUH 依次消耗不同的 RU
当 Host 确保:
某个 RU 内的数据已经全部 overwrite 或 deallocate
那么:
SSD 在擦除该 RU 时,无需搬移任何有效数据
垃圾回收不再产生额外写入
该 RU 对应的 WAF ≈ 1
六、为什么说 FDP 等价于“用软件换 OP”
白皮书在后半部分给出了一个很现实的视角。
在传统 SSD 中,为了降低 WAF,系统常常只能:
提高 Over‑Provisioning(OP)
损失可用容量
而 FDP 提供了一种替代路径:
通过 Host 侧理解数据生命周期
主动配合 SSD 的回收单元
用软件复杂度,换取:
更低 WAF
更高耐久度
更好的随机写性能
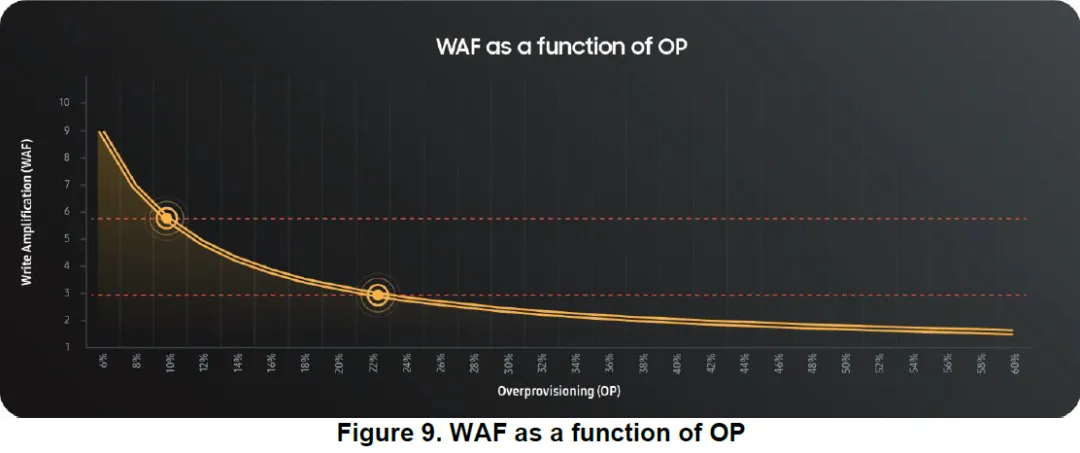
白皮书用模型说明:
将 WAF 从 ~5.7 降到 ~2.8
等价于把 OP 从 10% 提高到 23%
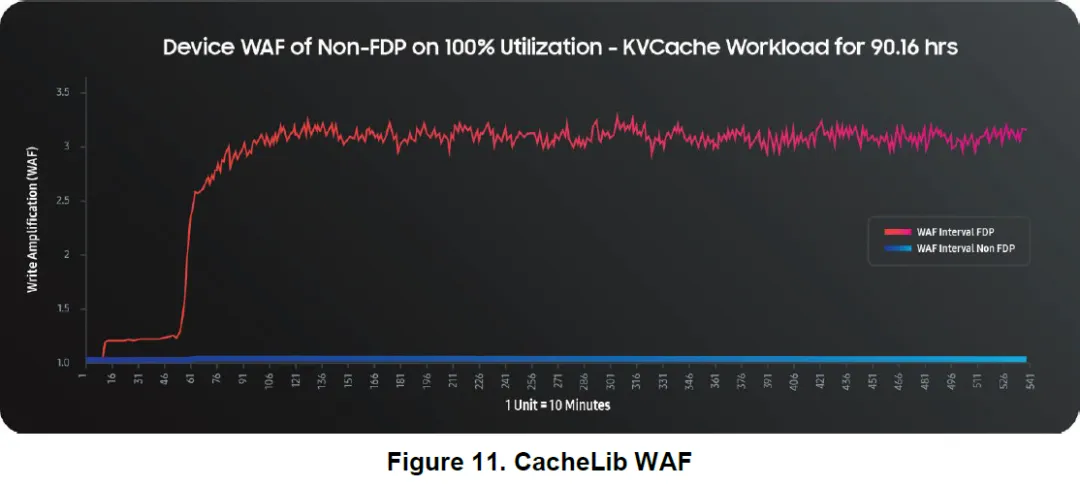
七、实际验证:CacheLib 的 FDP 改造案例
白皮书选择 CacheLib 作为示例,原因很直接:
metadata:小而随机
user data:大且顺序、可覆写
改造方式很简单:
metadata → 一个 RUH
user data → 另一个 RUH
无需修改上层应用逻辑。
结果:
SSD WAF 从 ~3 降至 ~1
在读多写少场景下,性能和寿命都有显著改善
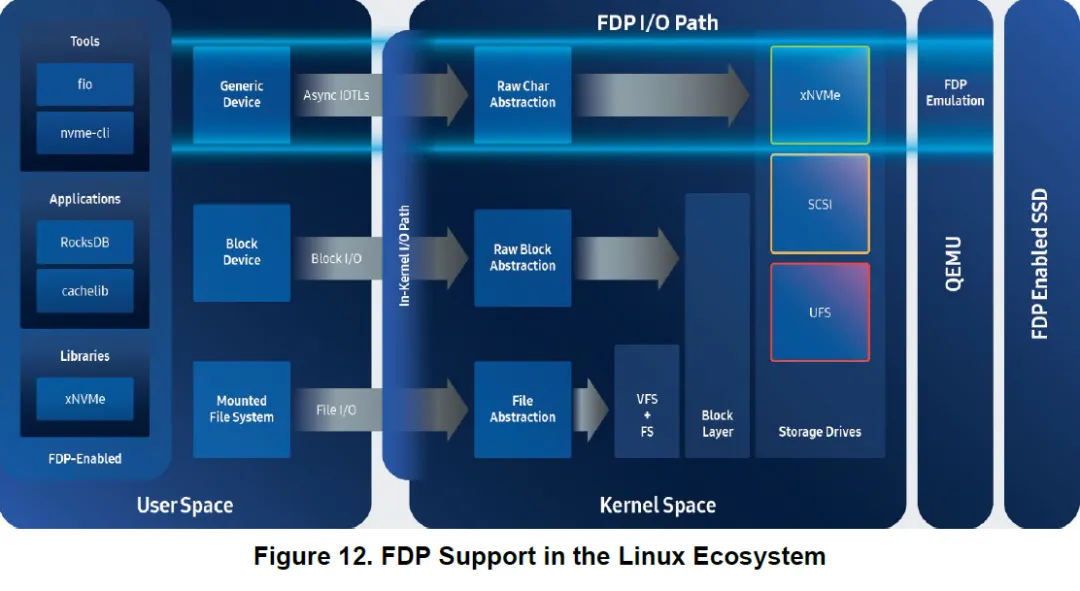
八、FDP 在 Linux 软件栈中的位置
白皮书明确给出 FDP 的软件支持现状:
1. Linux kernel ≥ 6.2
通过 io_uring + NVMe passthru
2. User space:
SPDK
xNVMe
fio / nvme‑cli
3. 仿真:
QEMU ≥ 8.0
这意味着:FDP 已经不是未来设想,而是可被验证、可被部署的 NVMe 能力。
九、FDP 和 ZNS / Streams 的区别(白皮书的结论)
白皮书最后给出了一个清晰判断:
1. Streams:提示(hint),SSD 可不采用
2. ZNS:Host 必须严格遵循写入规则,否则命令失败
3. FDP:
Host 提供数据放置“意图”
SSD 仍负责物理映射和并行优化
同时保持向后兼容
这也是为什么 FDP 更适合改造现有系统,而不是要求整个软件栈重写。
小结
白皮书的核心观点:FDP 并不是让 Host 接管 SSD,而是把 Host 已经知道、但过去无法表达的数据生命周期信息,变成 SSD 可以执行的输入,从而降低写放大。
如果说 ZNS 更像一种重构型方案,那 FDP 更像是 在不推翻现有 NVMe 模型的前提下,引入一层更可控的数据放置机制。
编者注:从 Controller / Firmware 视角看 FDP 的真实成本
从白皮书的表述可以看出,SNIA 在介绍 FDP 时刻意保持了克制:FDP 被描述为一种“帮助 Host 降低 WAF 的机制”,而不是“更先进的 SSD 架构”。但如果从 Controller / Firmware 的实现视角来看,FDP 并不是一个几乎零成本的功能开关。
首先,FDP 要求 SSD 在内部显式维护 Reclaim Unit(RU)这一回收单元抽象。在传统 NVMe SSD 中,superblock 的分配、关闭和回收完全由控制器私有逻辑决定;而在 FDP 模型下,RU 成为了对 Host 语义可见、行为可预期的管理单元。这意味着 FTL 必须引入新的元数据结构,用于跟踪 RU 的状态(open、full、reclaimable),并且在垃圾回收决策中严格以 RU 为边界,而不是在全盘范围内自由选择最优回收目标。
其次,FDP 在写入路径上引入了 多 Reclaim Unit Handle(RUH)的并行资源模型。在工程上,这等价于在控制器中维护多条逻辑独立的写入管线:每条 RUH 都需要独立的缓冲、独立的 open RU,以及相对独立的进度管理。RUH 的数量直接受到控制器 SRAM/DRAM、写缓冲深度以及 NAND program 时序约束的限制,这也是为什么白皮书中推荐的 RUH 数量通常落在 8–32 这一现实区间。对于 QLC NAND,这一约束往往更加严苛。
第三,FDP 实际上压缩了控制器在垃圾回收和 wear leveling 上的自由度。在传统 SSD 中,控制器可以跨 namespace、跨数据流动态打散写入,以实现长期的磨损均衡;而在 FDP 模型下,Host 有意把具有相似生命周期的数据集中写入特定 RU。如果 Host 的数据放置策略不均衡,Controller 能做的往往只剩下“跨时间”的平滑,而很难在不破坏 FDP 语义的前提下进行即时重分配。这一点在理论上是用 Host 侧“数据语义”换来的好处,但在实现上确实增加了固件层面的复杂度和风险管理难度。
还有一个容易被忽略的成本在于可观测性和可解释性。FDP 启用后,SSD 的写放大、寿命消耗和性能表现,不再完全是 Controller 自身算法的结果,而与 Host 的 placement 行为强相关。因此,控制器与固件层面通常需要提供更细粒度的统计与事件记录,例如 RU / RUH 维度的写入量、回收次数以及 FDP 相关的异常日志,否则在大规模部署环境中很难进行容量规划和问题定位。
从这个角度看,FDP 并不是让 Host “接管” SSD,而是要求 Controller 放弃部分原本完全私有的优化自由度,换取一个结果——写放大更可预测、数据生命周期更可控。这也是为什么白皮书反复强调 FDP 是“incremental adoption”的能力:只有当 Host 确实能够理解并善用数据生命周期信息时,Controller 在这条交换中付出的成本,才会转化为真实可见的系统收益。
推荐阅读:
高容量 SSD 真的耐用吗?从写放大、IU 到系统写行为(FDP)
面向 AI 工作负载的存储架构:SSD 的瓶颈,到底在哪里?
Mixed Mode SSD:把 SLC 和 QLC 用在同一块盘上,为什么?
合集/系列: