


最近国产AI芯片迎来史诗级增长。4月DeepSeek等国产大模型与国产芯片适配加速,带动上游算力芯片需求激增;行业头部企业寒武纪、芯原股份、品高股份、沐曦股份、壁仞科技等多家公司的新款AI芯片也将于今年下半年量产。
海外方面,美国微软、谷歌、亚马逊、Meta四大科技巨头公布的2026年AI支出预计高达7250亿美元;黄仁勋也确认,英伟达先进芯片对华限制,国产GPU因此迎来历史性替代窗口。
今天重点拆解一下 AI芯片。
近期热门行业文章
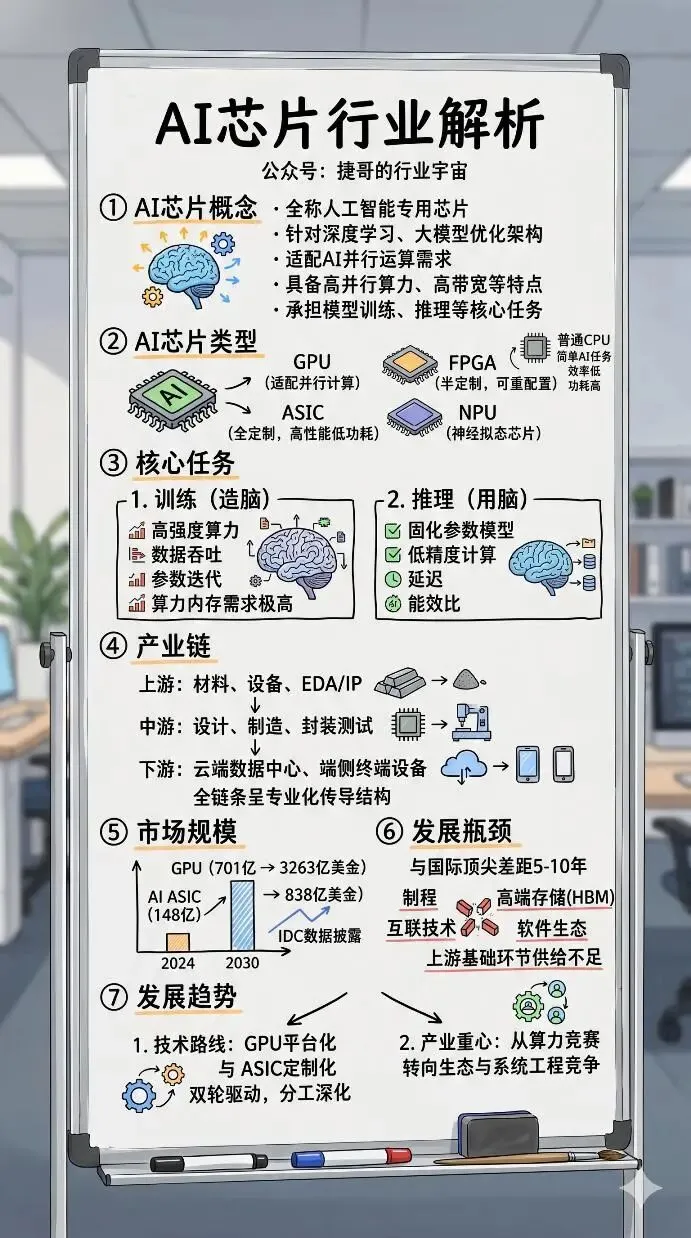
AI芯片介绍
AI芯片的概念
AI芯片全称人工智能专用芯片,是专门针对深度学习、神经网络、大模型运算做架构优化、算力加速的专用集成电路。
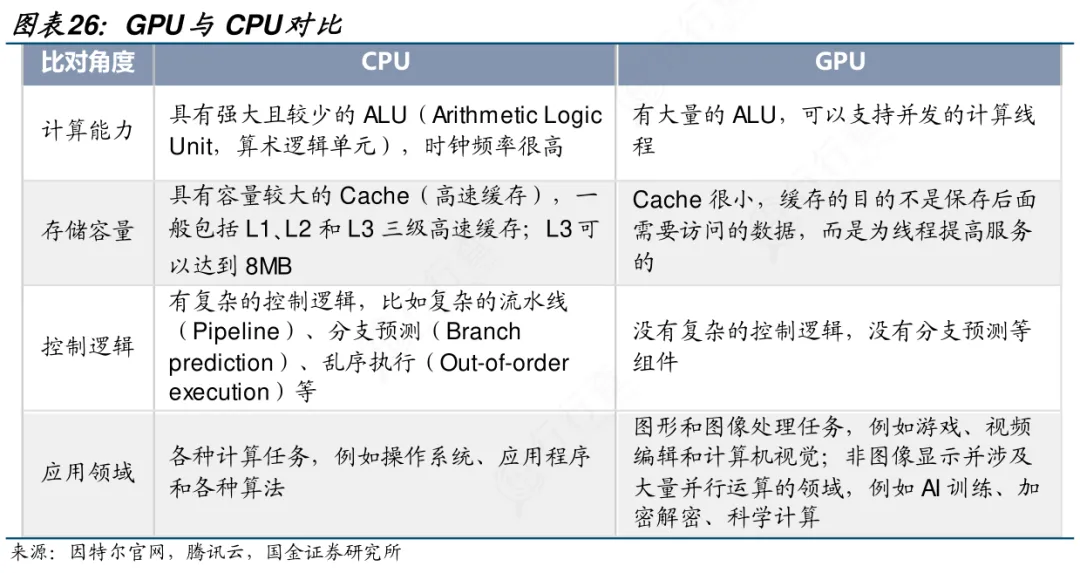
区别于传统通用CPU,CPU只擅长复杂逻辑串行计算,不适合AI海量矩阵、并行运算。而AI芯片天生适配AI算法,具备超高并行算力、高带宽、低时延、高能效比,专门承担AI的模型训练、逻辑推理、智能感知等核心任务。
AI芯片的类型
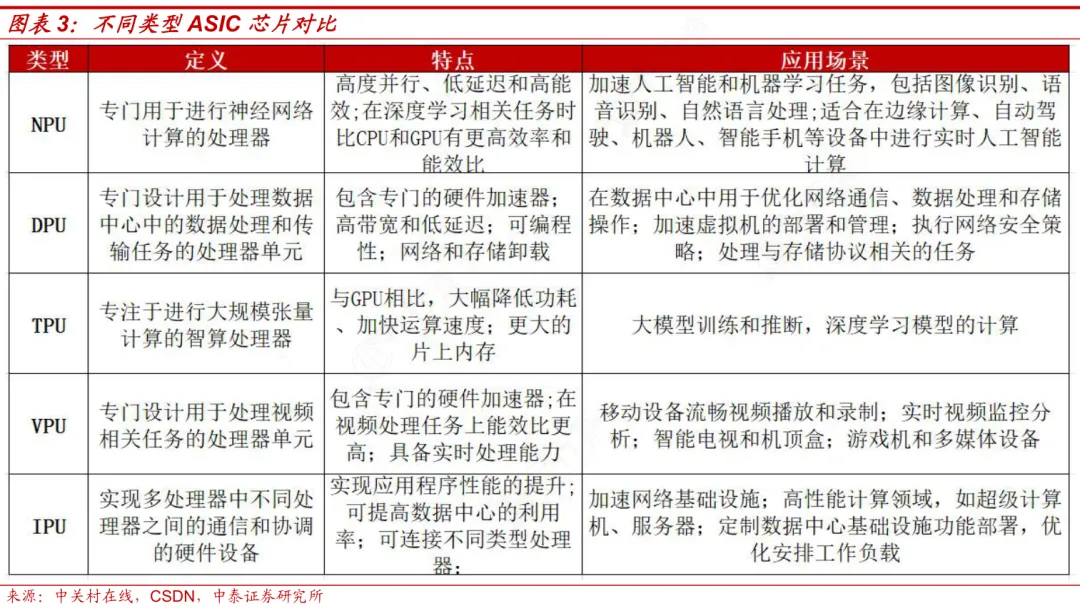
AI芯片是所有为深度学习、神经网络做加速计算的芯片统称。业内主流认为AI芯片主要包括图形处理器(GPU)、现场可编程门阵列(FPGA)、专用集成电路(ASIC)等。
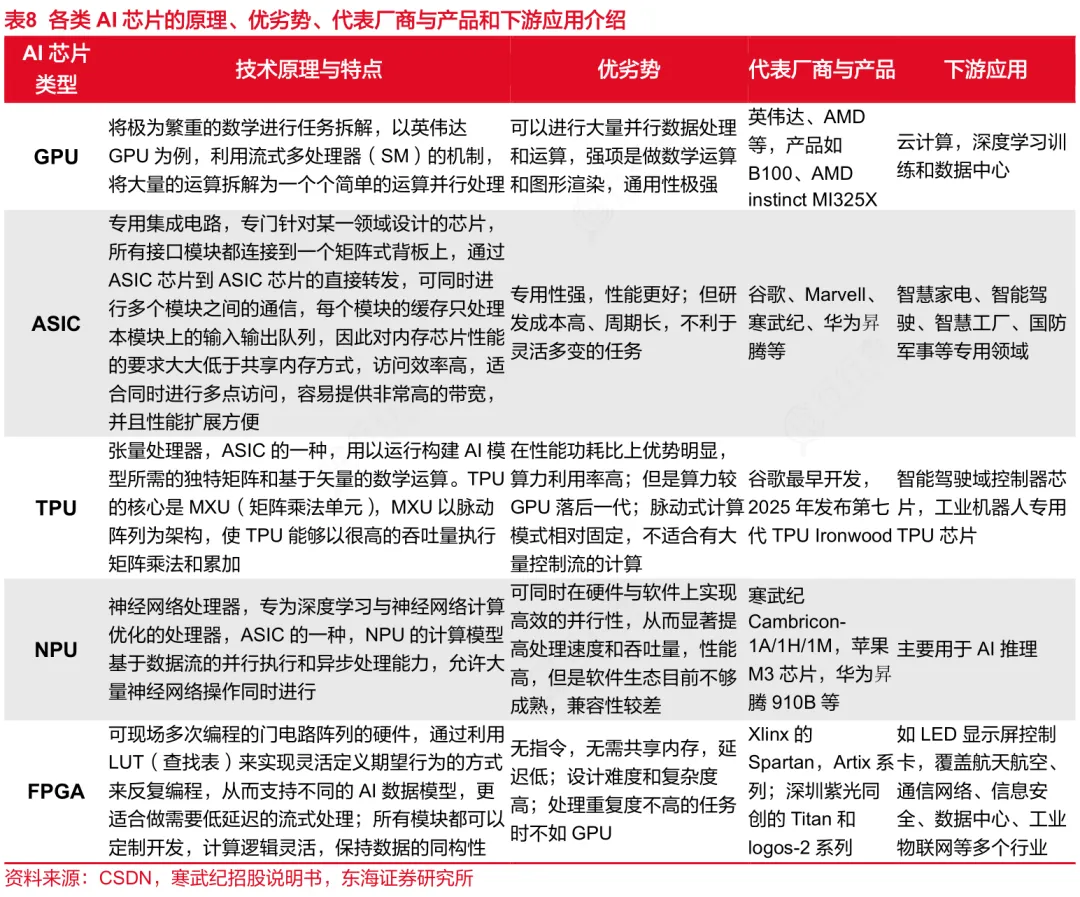
GPU(图形处理器)是一种通用型芯片,用于处理复杂的图形渲染任务和并行计算需求;FPGA(现场可编程门阵列)是一种半定制芯片,可通过编程重新配置硬件逻辑以适应多种应用场景;ASIC(专用集成电路)是为特定用户需求或场景设计的全定制芯片,具备针对特定任务优化的高性能和低功耗特点。
普通CPU也能执行简单的AI任务,但速度慢、功耗高、效率较差。
每天更多热点赛道更新,会发布在行业情报站 ( 每天拆解2-5个热点行业 ),包含 图文+视频+报告(限时福利:下单赠送产业图册)。
AI芯片支撑人工智能落地的两大核心任务,是训练与推理。二者并非同一过程的简单延伸,而是逻辑闭环中截然不同的工程阶段——训练是“造脑”,推理是“用脑”。
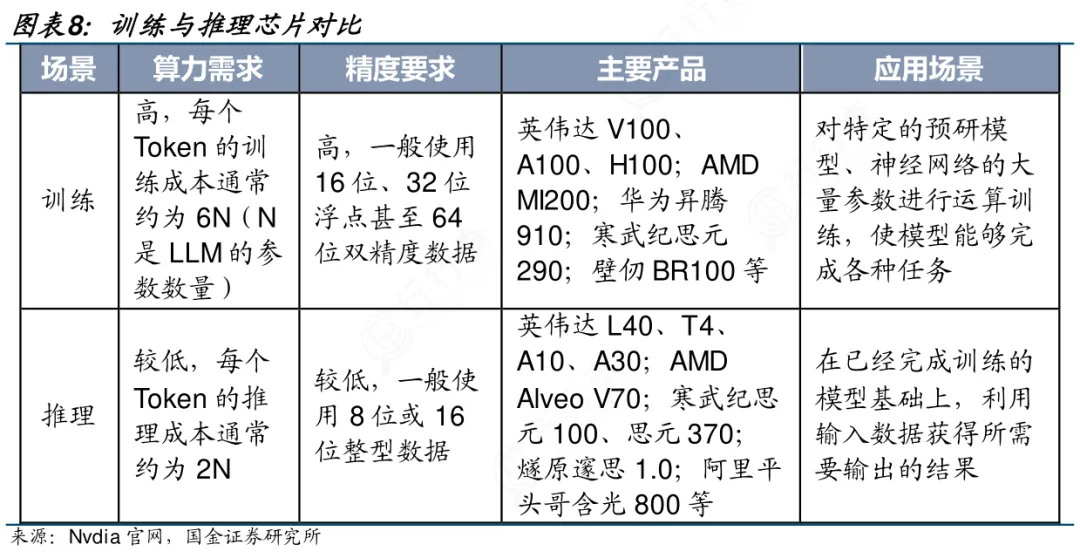
训练芯片聚焦于模型诞生前的高强度算力攻坚。它需在数周甚至数月内吞吐PB级标注数据,反复迭代百亿至万亿参数,因此对绝对算力(如FP16/FP32高精度浮点性能)、内存带宽(HBM容量与速率)和集群互联能力提出极致要求;功耗虽高,但因部署于数据中心,可接受千瓦级散热设计。
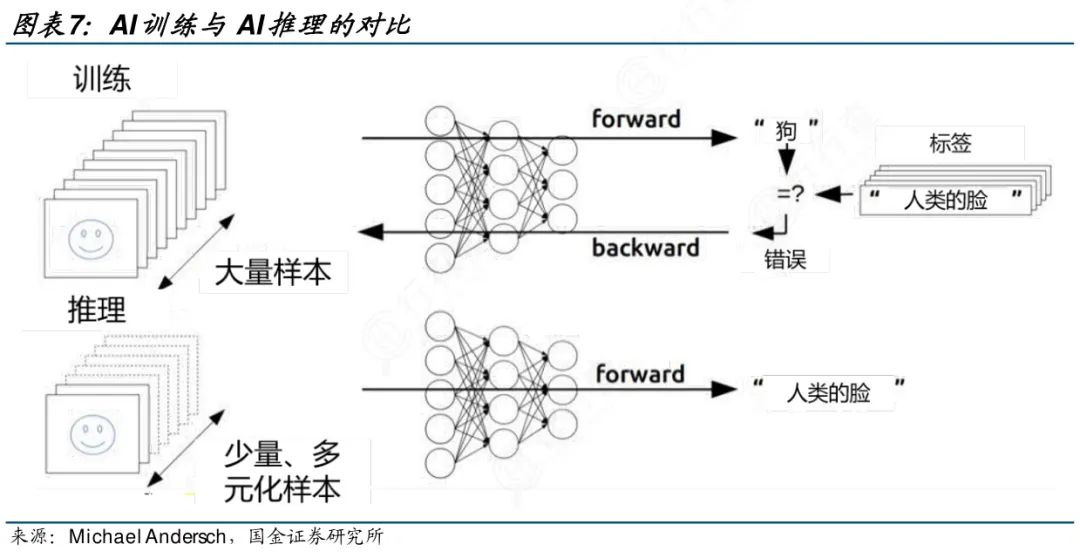
推理芯片则直面真实世界——毫秒级响应、电池续航、成本敏感、隐私刚性。它运行的是已固化参数的轻量化模型,不再追求高精度浮点,而是以INT4/INT8低精度计算为主,核心指标转向延迟(<10ms)、单位功耗算力(TOPS/W)和每秒查询数(QPS)。
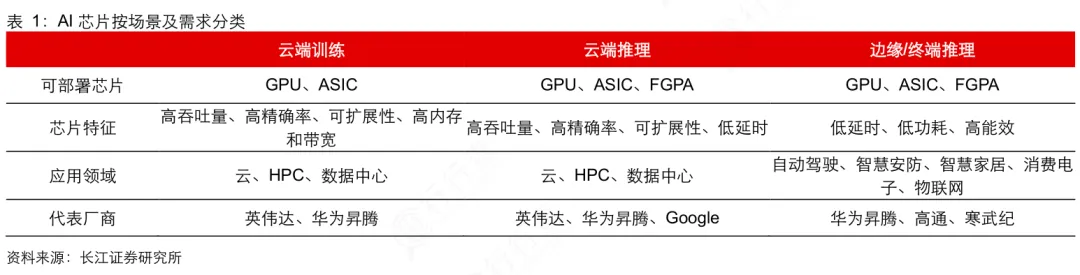
AI芯片产业链
上游:产业根基,支撑核心研发与生产
上游是AI芯片产业的基础支撑环节,核心涵盖三大板块。
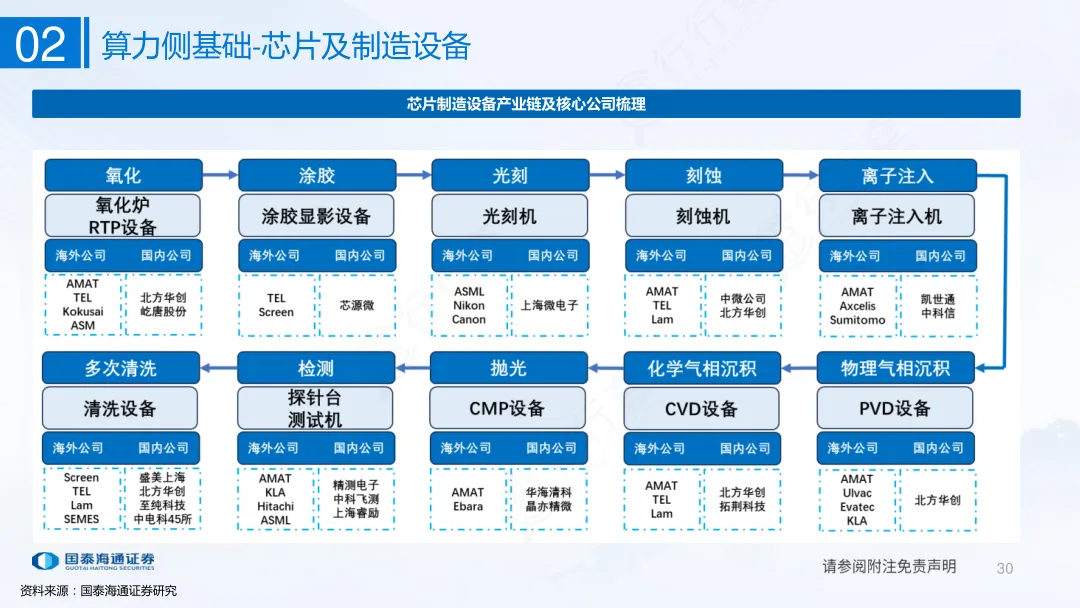
一是半导体材料,作为芯片制造的“粮食”,包括硅片、光刻胶、电子特气等,其纯度与性能直接影响芯片良率;二是半导体设备,涵盖光刻机、刻蚀机等核心设备,是芯片制造的核心硬件支撑;三是EDA工具与IP核,前者是芯片设计的“利器”,简化设计流程、提升研发效率,后者是可重复使用的标准化电路模块,缩短研发周期、降低研发难度。
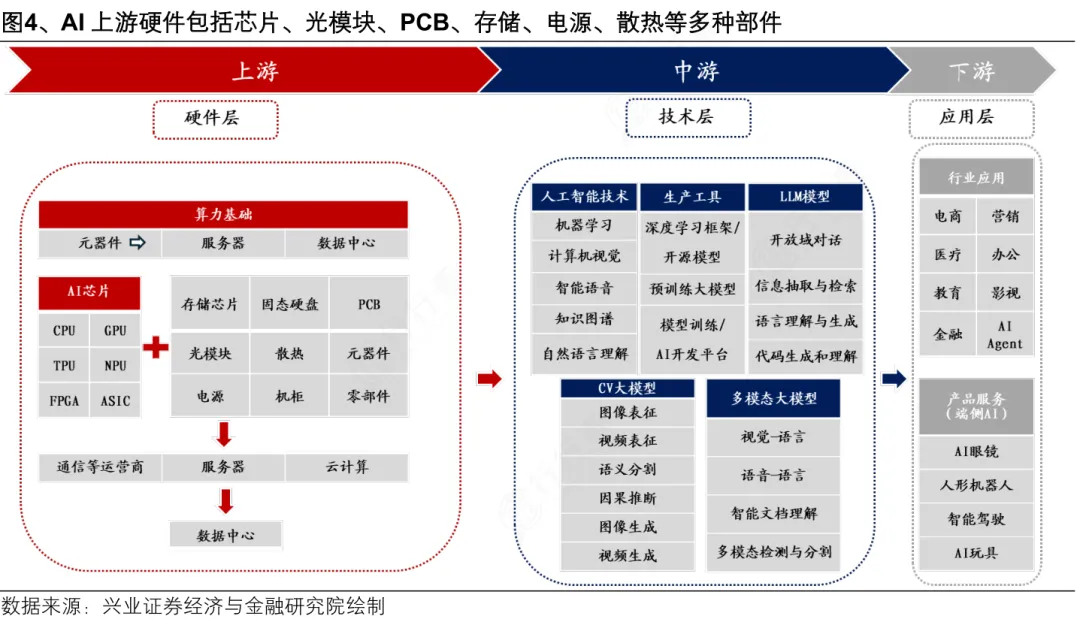
中游:核心枢纽,实现芯片从设计到成品
中游是AI芯片产业链的核心环节,包括从设计、制造、再到封装测试的全流程转化。芯片设计环节,聚焦AI算法特性优化架构,确定芯片功能与性能指标,是芯片研发的核心。
晶圆制造则将设计方案通过光刻、刻蚀等工艺在硅片上实现,是芯片落地的关键一步;最后是封装测试,对制造完成的芯片进行封装保护,并检测其性能、功耗等指标,确保芯片符合使用要求,为下游应用提供合格产品。
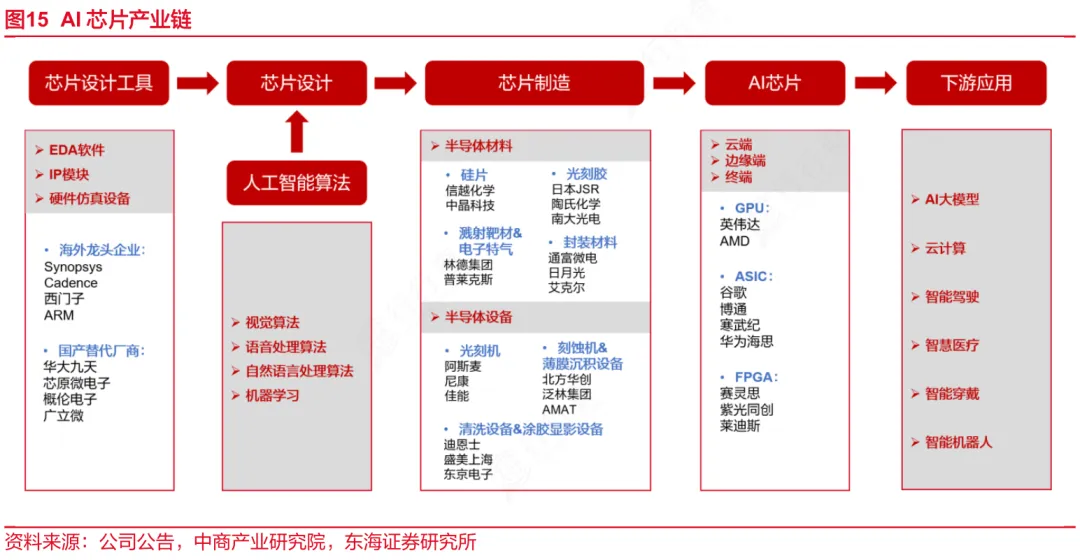
下游:应用落地,释放产业核心价值
下游是AI芯片的商业化落地场景,主要分为云端与端侧两大领域。云端场景以数据中心为主,芯片用于大模型训练、AI推理等高强度算力需求,支撑互联网、政务等领域的AI应用。
端侧场景涵盖智能手机、自动驾驶、智能家居等终端设备,芯片以低功耗、轻量化为特点,实现终端设备的智能感知、决策等功能,让AI技术真正融入日常生活与各行业场景。

AI芯片市场规模
根据IDC披露数据,2024年GPU、AI ASIC芯片市场规模分别为701、148亿美金,预计2030年分别增长至3263、838亿美金,对应2024-2030年CAGR分别为29.2%、33.5%。
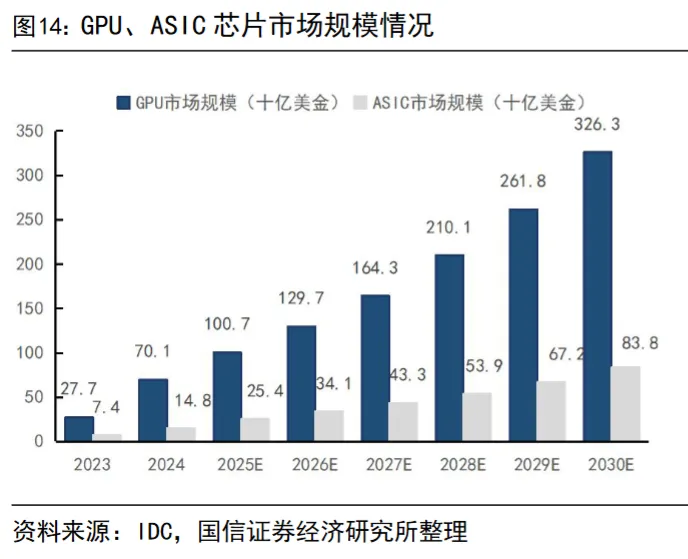 (数据时间:2025-10)
(数据时间:2025-10)
摩尔线程招股说明书显示,过去五年,中国GPU产业呈现快速增长态势,市场规模从2020年的384.77亿元快速增长到2024年的1,638.17亿元,预计到2029年中国GPU市场规模将增长到13,635.78亿元,其中AI智算GPU市场规模将达到10,333.40亿元,期间年均复合增长率为56.7%。
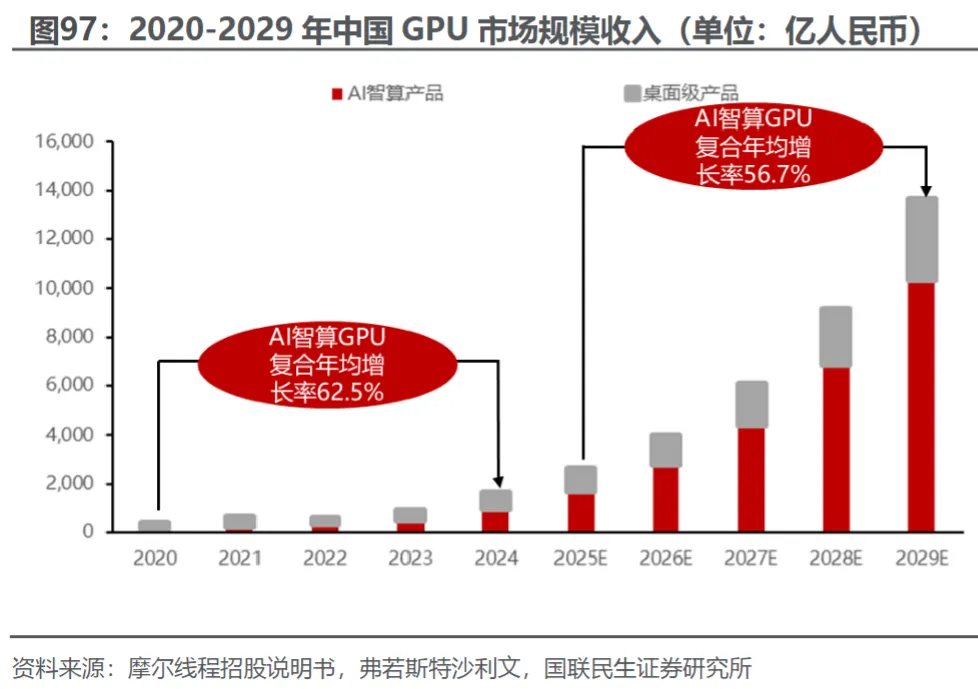
(数据时间:2026-2)
AI芯片观点分析
国产AI芯片的发展瓶颈
技术代差:1.5代是实情,但“5-10年”更戳中要害
2026年,国产AI芯片与国际顶尖水平的差距,不能只看参数表上的“1.5代”——那是设计能力的落差;真正卡脖子的,是背后整条链路的系统性滞后。
根据上海SEMICON China 2026论坛上,多位业内专家判断,中国在AI数据中心级芯片领域的综合差距已达5到10年。这不是夸张,而是对代际迭代节奏、制造响应速度与生态沉淀厚度的冷静估算。
英伟达每12–18个月推一代旗舰,5年就是3–4轮技术跃迁;而我国目前连7nm良率稳定量产都尚未完全跨越,3nm及以下制程仍无自主产能,HBM3内存、CoWoS先进封装、NVLink万卡互联等关键环节,全靠外部技术授权或逆向适配。
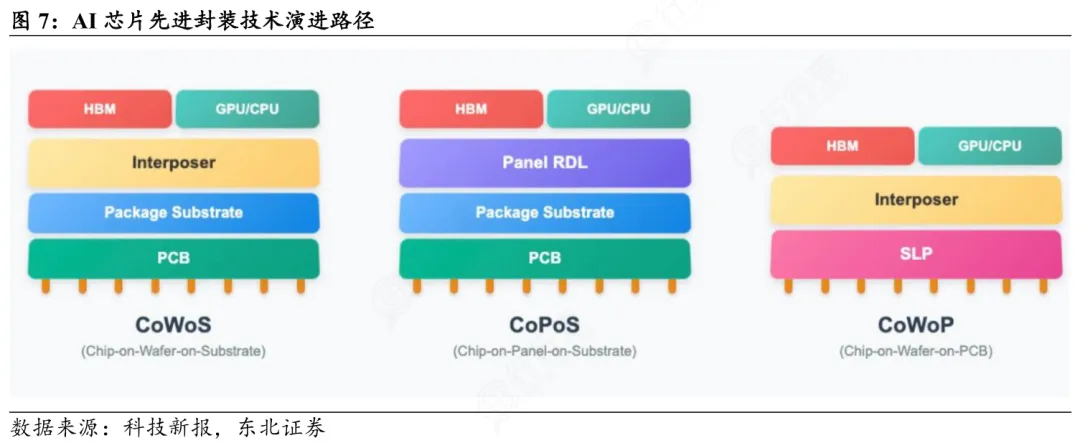
“卡脖子”四重门:制程、存储、互联、生态
第一重难点是在制造端:中芯国际7nm需DUV多重曝光,成本高、良率低,无法支撑B200级芯片的能效比要求;第二重难点是高端存储:HBM3e国产化尚在冲刺,主流方案仍停留在HBM2e。
单颗粒带宽的代际差,导致国产芯片总显存带宽通常在1.2TB/s–2TB/s徘徊,远低于B200高达8TB/s的吞吐量。大模型训推时,海量数据“堵在门口”。
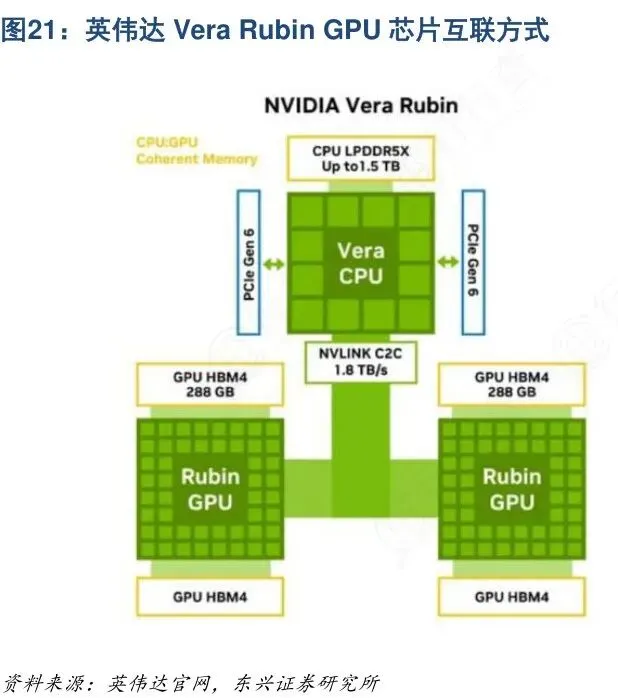
第三重难点是互联能力:自研互联技术(如HCCS、BLink)带宽多在200–400GB/s,而NVLink 5已跨入1.8TB/s时代。这直接导致万卡集群在扩展时,由于通信损耗造成算力利用率(MFU)断崖式领先优势丧失。
第四重难点是软件生态:开发者习惯CUDA,迁移至MindSpore或Cambricon需重写算子、调优模型,中小企业宁可多花钱买英伟达,也不愿承担生态切换的隐性成本。
更隐蔽的瓶颈还在上游——MLCC电容短缺、光刻胶依赖进口、EDA工具链不闭环,这些“螺丝钉级”的断供,比光刻机更难预警、更易导致产线停摆。
AI芯片行业的发展趋势
技术路线:GPU平台化与ASIC定制化双轮驱动
当前,AI芯片不再只是“加速器”,而是演进为系统级算力基础设施。GPU正从单芯片向整柜级“AI工厂”跃迁——NVL72架构实现72卡统一计算域与130TB/s互联带宽,液冷、供电、HBM带宽已被纳入芯片定义范畴。
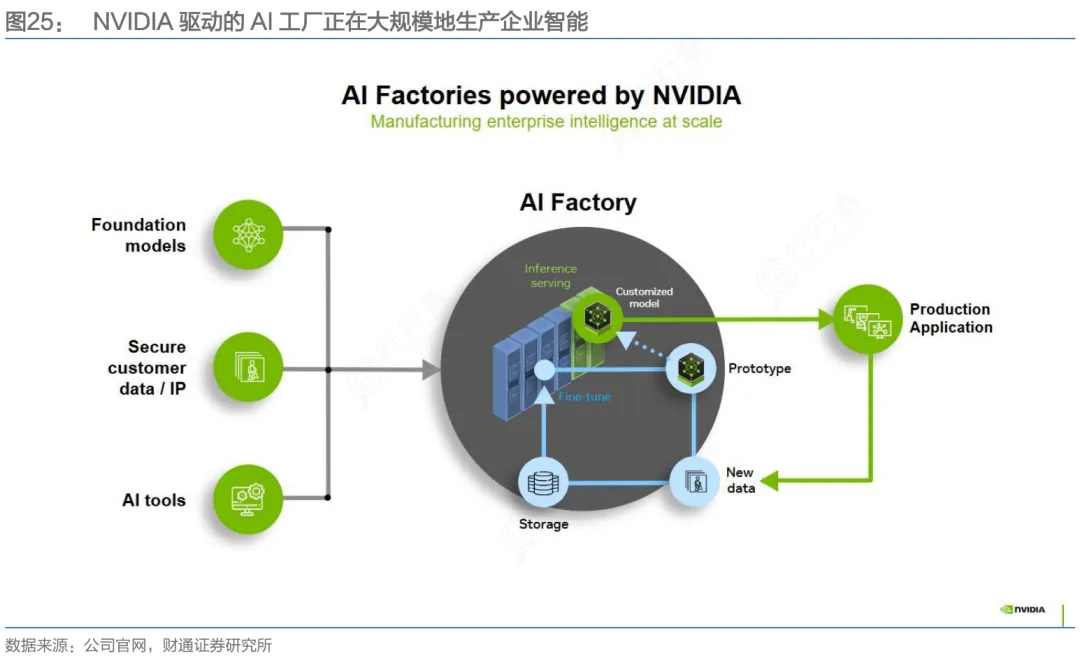
与此同时,云厂商主导的ASIC定制化加速爆发:Google第八代TPU、AWS Trainium3、微软Maia均以FP8/FP4低精度推理、高能效比和软硬协同为锚点,不远的将来,ASIC与GPU或将平分AI芯片市场。这背后不是产品替代,而是芯片分工的深化。
产业重心:从“算力竞赛”转向“生态与系统工程竞争”
行行查数据显示,全球大模型训练量2026年预计同比暴增300%,但推理需求增速更快,成本、延迟与部署效率成为关键胜负手。
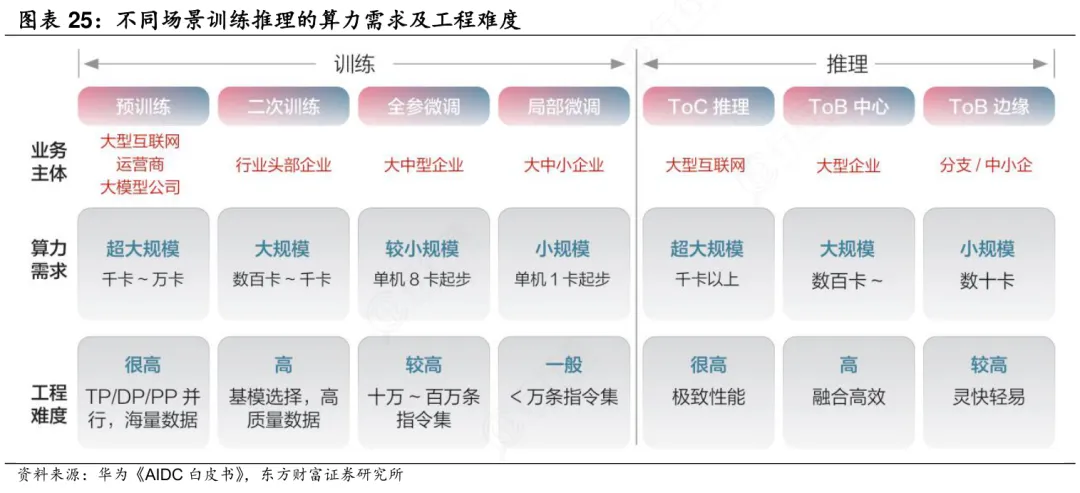
产业链也从芯片设计延伸至“硅到机柜”:头部企业如英伟达、AMD开始整合GPU、网络与机柜等环节,完善算力生态。
CoWoS封装与HBM供应,逐渐成为产能瓶颈;而下游客户(云厂、车企、工业设备商)开始反向定义芯片规格。AI芯片产业已不单是纯硬件的生意,而是高壁垒的系统工程。

AI芯片代表性企业
海外代表性企业:
NVIDIA(美国,高端AI训练芯片霸主)
AMD(美国,高性价比AI算力芯片)
Intel(美国,CPU+AI加速芯片融合)
Google(美国,TPU专用AI芯片生态)
Qualcomm(美国,移动AI芯片领导者)
Graphcore(英国,智能推理芯片创新者)
Cerebras(美国,超大芯片AI计算方案)
国内代表性企业:
华为昇腾(深圳,国产高端AI算力龙头)
寒武纪(北京,全场景通用AI芯片)
海光信息(天津,x86架构AI加速芯片)
摩尔线程(北京,全功能GPU芯片量产)
沐曦股份(上海,高端通用GPU芯片)
壁仞科技(上海,全栈自研GPGPU芯片)
阿里平头哥(杭州,云端边缘AI芯片)
地平线(北京,自动驾驶AI芯片标杆)
百度昆仑芯(北京,大模型适配AI芯片)
天数智芯(上海,训推一体AI芯片)
(公开资料整理,行业研究分享,勿做投资建议)
(END)

捷哥的行业宇宙
《图解100个产业链》作者
《图解100个商业模式》作者